 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Concept Drift Handling for Batch Android Malware Detection Models
Sep 18, 2023
The rapidly evolving nature of Android apps poses a significant challenge to static batch machine learning algorithms employed in malware detection systems, as they quickly become obsolete. Despite this challenge, the existing literature pays limited attention to addressing this issue, with many advanced Android malware detection approaches, such as Drebin, DroidDet and MaMaDroid, relying on static models. In this work, we show how retraining techniques are able to maintain detector capabilities over time. Particularly, we analyze the effect of two aspects in the efficiency and performance of the detectors: 1) the frequency with which the models are retrained, and 2) the data used for retraining. In the first experiment, we compare periodic retraining with a more advanced concept drift detection method that triggers retraining only when necessary. In the second experiment, we analyze sampling methods to reduce the amount of data used to retrain models. Specifically, we compare fixed sized windows of recent data and state-of-the-art active learning methods that select those apps that help keep the training dataset small but diverse. Our experiments show that concept drift detection and sample selection mechanisms result in very efficient retraining strategies which can be successfully used to maintain the performance of the static Android malware state-of-the-art detectors in changing environments.
Single and Few-step Diffusion for Generative Speech Enhancement
Sep 18, 2023Diffusion models have shown promising results in speech enhancement, using a task-adapted diffusion process for the conditional generation of clean speech given a noisy mixture. However, at test time, the neural network used for score estimation is called multiple times to solve the iterative reverse process. This results in a slow inference process and causes discretization errors that accumulate over the sampling trajectory. In this paper, we address these limitations through a two-stage training approach. In the first stage, we train the diffusion model the usual way using the generative denoising score matching loss. In the second stage, we compute the enhanced signal by solving the reverse process and compare the resulting estimate to the clean speech target using a predictive loss. We show that using this second training stage enables achieving the same performance as the baseline model using only 5 function evaluations instead of 60 function evaluations. While the performance of usual generative diffusion algorithms drops dramatically when lowering the number of function evaluations (NFEs) to obtain single-step diffusion, we show that our proposed method keeps a steady performance and therefore largely outperforms the diffusion baseline in this setting and also generalizes better than its predictive counterpart.
Bayesian Time-Series Classifier for Decoding Simple Visual Stimuli from Intracranial Neural Activity
Jul 28, 2023Understanding how external stimuli are encoded in distributed neural activity is of significant interest in clinical and basic neuroscience. To address this need, it is essential to develop analytical tools capable of handling limited data and the intrinsic stochasticity present in neural data. In this study, we propose a straightforward Bayesian time series classifier (BTsC) model that tackles these challenges whilst maintaining a high level of interpretability. We demonstrate the classification capabilities of this approach by utilizing neural data to decode colors in a visual task. The model exhibits consistent and reliable average performance of 75.55% on 4 patients' dataset, improving upon state-of-the-art machine learning techniques by about 3.0 percent. In addition to its high classification accuracy, the proposed BTsC model provides interpretable results, making the technique a valuable tool to study neural activity in various tasks and categories. The proposed solution can be applied to neural data recorded in various tasks, where there is a need for interpretable results and accurate classification accuracy.
Improving Adversarial Robustness of Masked Autoencoders via Test-time Frequency-domain Prompting
Aug 22, 2023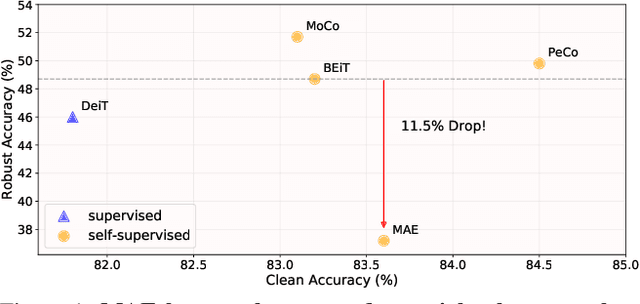
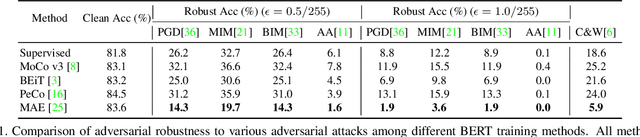
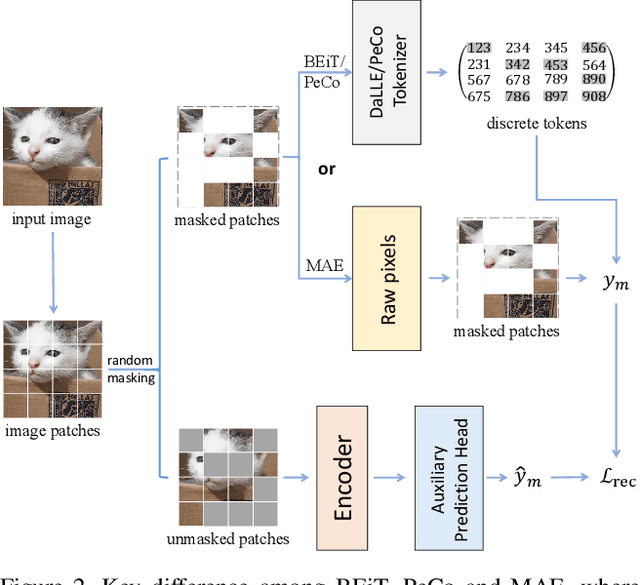

In this paper, we investigate the adversarial robustness of vision transformers that are equipped with BERT pretraining (e.g., BEiT, MAE). A surprising observation is that MAE has significantly worse adversarial robustness than other BERT pretraining methods. This observation drives us to rethink the basic differences between these BERT pretraining methods and how these differences affect the robustness against adversarial perturbations. Our empirical analysis reveals that the adversarial robustness of BERT pretraining is highly related to the reconstruction target, i.e., predicting the raw pixels of masked image patches will degrade more adversarial robustness of the model than predicting the semantic context, since it guides the model to concentrate more on medium-/high-frequency components of images. Based on our analysis, we provide a simple yet effective way to boost the adversarial robustness of MAE. The basic idea is using the dataset-extracted domain knowledge to occupy the medium-/high-frequency of images, thus narrowing the optimization space of adversarial perturbations. Specifically, we group the distribution of pretraining data and optimize a set of cluster-specific visual prompts on frequency domain. These prompts are incorporated with input images through prototype-based prompt selection during test period. Extensive evaluation shows that our method clearly boost MAE's adversarial robustness while maintaining its clean performance on ImageNet-1k classification. Our code is available at: https://github.com/shikiw/RobustMAE.
RR-CP: Reliable-Region-Based Conformal Prediction for Trustworthy Medical Image Classification
Sep 09, 2023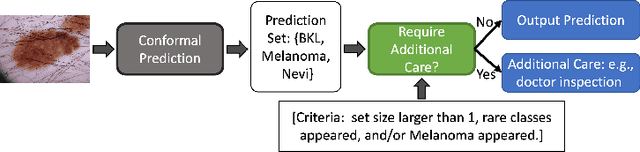
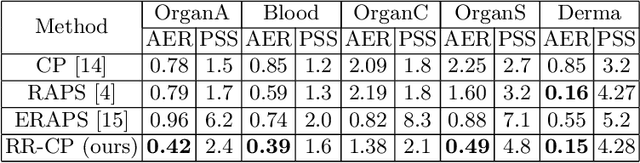
Conformal prediction (CP) generates a set of predictions for a given test sample such that the prediction set almost always contains the true label (e.g., 99.5\% of the time). CP provides comprehensive predictions on possible labels of a given test sample, and the size of the set indicates how certain the predictions are (e.g., a set larger than one is `uncertain'). Such distinct properties of CP enable effective collaborations between human experts and medical AI models, allowing efficient intervention and quality check in clinical decision-making. In this paper, we propose a new method called Reliable-Region-Based Conformal Prediction (RR-CP), which aims to impose a stronger statistical guarantee so that the user-specified error rate (e.g., 0.5\%) can be achieved in the test time, and under this constraint, the size of the prediction set is optimized (to be small). We consider a small prediction set size an important measure only when the user-specified error rate is achieved. Experiments on five public datasets show that our RR-CP performs well: with a reasonably small-sized prediction set, it achieves the user-specified error rate (e.g., 0.5\%) significantly more frequently than exiting CP methods.
Native Language Identification with Big Bird Embeddings
Sep 13, 2023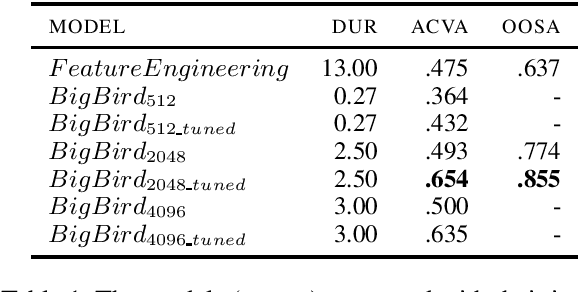
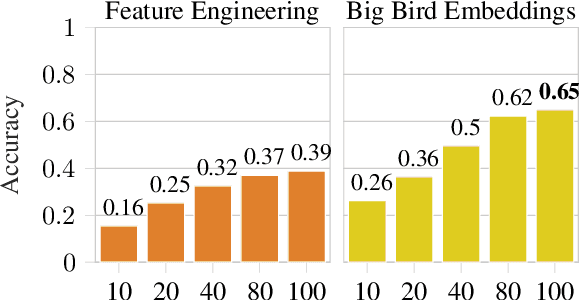
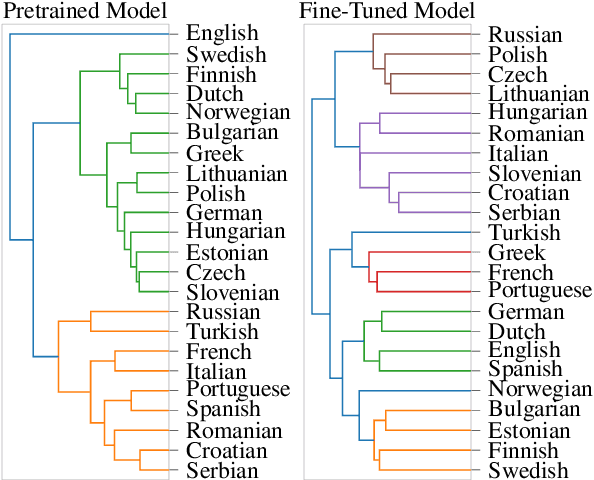
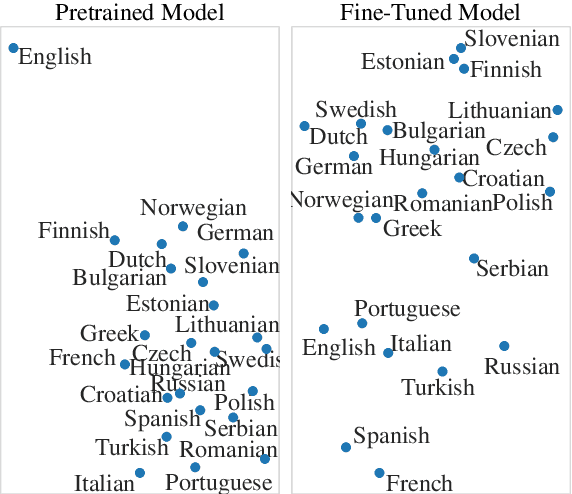
Native Language Identification (NLI) intends to classify an author's native language based on their writing in another language. Historically, the task has heavily relied on time-consuming linguistic feature engineering, and transformer-based NLI models have thus far failed to offer effective, practical alternatives. The current work investigates if input size is a limiting factor, and shows that classifiers trained using Big Bird embeddings outperform linguistic feature engineering models by a large margin on the Reddit-L2 dataset. Additionally, we provide further insight into input length dependencies, show consistent out-of-sample performance, and qualitatively analyze the embedding space. Given the effectiveness and computational efficiency of this method, we believe it offers a promising avenue for future NLI work.
Message Passing-Based Joint Channel Estimation and Signal Detection for OTFS with Superimposed Pilots
Sep 15, 2023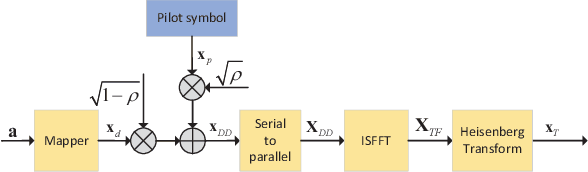
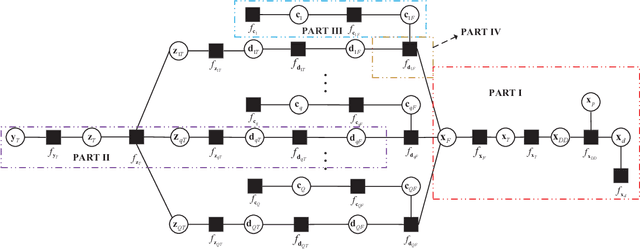
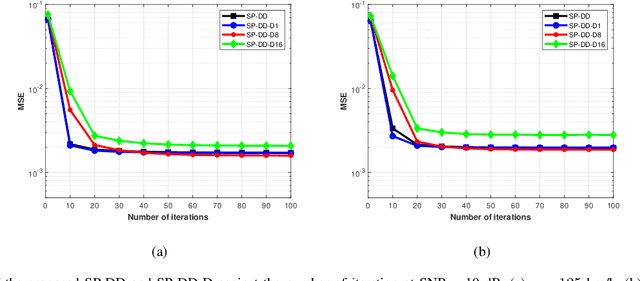
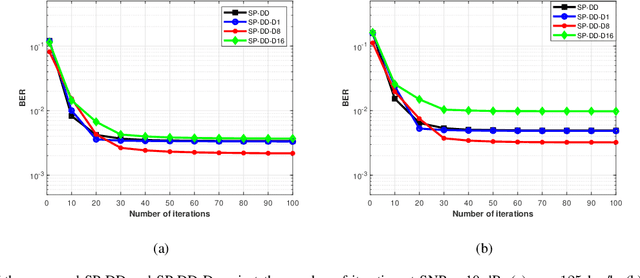
Receivers with joint channel estimation and signal detection using superimposed pilots (SP) can achieve high transmission efficiency in orthogonal time frequency space (OTFS) systems. However, existing receivers have high computational complexity, hindering their practical applications. In this work, with SP in the delay-Doppler (DD) domain and the generalized complex exponential (GCE) basis expansion modeling (BEM) for channels, a message passing-based SP-DD iterative receiver is proposed, which drastically reduces the computational complexity while with marginal performance loss, compared to existing ones. To facilitate channel estimation (CE) in the proposed receiver, we design pilot signal to achieve pilot power concentration in the frequency domain, thereby developing an SP-DD-D receiver that can effectively reduce the power of the pilot signal and almost no loss of CE accuracy. Extensive simulation results are provided to demonstrate the superiority of the proposed SP-DD-D receiver.
ImDiffusion: Imputed Diffusion Models for Multivariate Time Series Anomaly Detection
Jul 03, 2023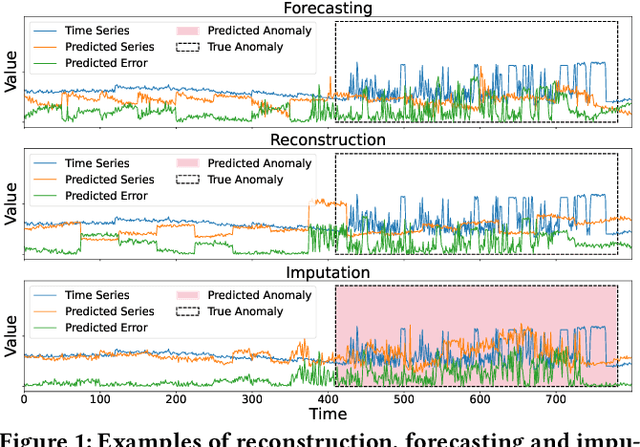
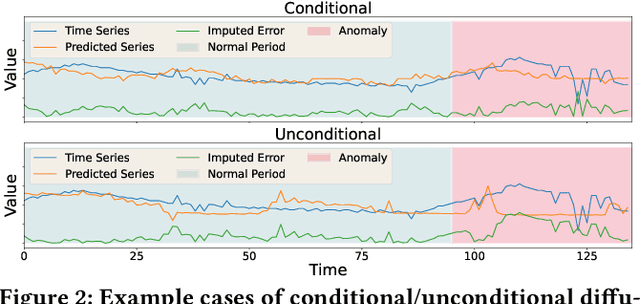
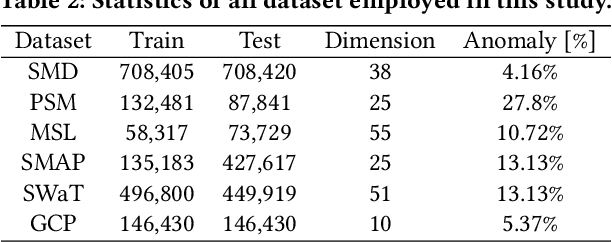
Anomaly detection in multivariate time series data is of paramount importance for ensuring the efficient operation of large-scale systems across diverse domains. However, accurately detecting anomalies in such data poses significant challenges. Existing approaches, including forecasting and reconstruction-based methods, struggle to address these challenges effectively. To overcome these limitations, we propose a novel anomaly detection framework named ImDiffusion, which combines time series imputation and diffusion models to achieve accurate and robust anomaly detection. The imputation-based approach employed by ImDiffusion leverages the information from neighboring values in the time series, enabling precise modeling of temporal and inter-correlated dependencies, reducing uncertainty in the data, thereby enhancing the robustness of the anomaly detection process. ImDiffusion further leverages diffusion models as time series imputers to accurately capturing complex dependencies. We leverage the step-by-step denoised outputs generated during the inference process to serve as valuable signals for anomaly prediction, resulting in improved accuracy and robustness of the detection process. We evaluate the performance of ImDiffusion via extensive experiments on benchmark datasets. The results demonstrate that our proposed framework significantly outperforms state-of-the-art approaches in terms of detection accuracy and timeliness. ImDiffusion is further integrated into the real production system in Microsoft and observe a remarkable 11.4% increase in detection F1 score compared to the legacy approach. To the best of our knowledge, ImDiffusion represents a pioneering approach that combines imputation-based techniques with time series anomaly detection, while introducing the novel use of diffusion models to the field.
On the Fine-Grained Hardness of Inverting Generative Models
Sep 11, 2023The objective of generative model inversion is to identify a size-$n$ latent vector that produces a generative model output that closely matches a given target. This operation is a core computational primitive in numerous modern applications involving computer vision and NLP. However, the problem is known to be computationally challenging and NP-hard in the worst case. This paper aims to provide a fine-grained view of the landscape of computational hardness for this problem. We establish several new hardness lower bounds for both exact and approximate model inversion. In exact inversion, the goal is to determine whether a target is contained within the range of a given generative model. Under the strong exponential time hypothesis (SETH), we demonstrate that the computational complexity of exact inversion is lower bounded by $\Omega(2^n)$ via a reduction from $k$-SAT; this is a strengthening of known results. For the more practically relevant problem of approximate inversion, the goal is to determine whether a point in the model range is close to a given target with respect to the $\ell_p$-norm. When $p$ is a positive odd integer, under SETH, we provide an $\Omega(2^n)$ complexity lower bound via a reduction from the closest vectors problem (CVP). Finally, when $p$ is even, under the exponential time hypothesis (ETH), we provide a lower bound of $2^{\Omega (n)}$ via a reduction from Half-Clique and Vertex-Cover.
Learning the Geodesic Embedding with Graph Neural Networks
Sep 11, 2023We present GeGnn, a learning-based method for computing the approximate geodesic distance between two arbitrary points on discrete polyhedra surfaces with constant time complexity after fast precomputation. Previous relevant methods either focus on computing the geodesic distance between a single source and all destinations, which has linear complexity at least or require a long precomputation time. Our key idea is to train a graph neural network to embed an input mesh into a high-dimensional embedding space and compute the geodesic distance between a pair of points using the corresponding embedding vectors and a lightweight decoding function. To facilitate the learning of the embedding, we propose novel graph convolution and graph pooling modules that incorporate local geodesic information and are verified to be much more effective than previous designs. After training, our method requires only one forward pass of the network per mesh as precomputation. Then, we can compute the geodesic distance between a pair of points using our decoding function, which requires only several matrix multiplications and can be massively parallelized on GPUs. We verify the efficiency and effectiveness of our method on ShapeNet and demonstrate that our method is faster than existing methods by orders of magnitude while achieving comparable or better accuracy. Additionally, our method exhibits robustness on noisy and incomplete meshes and strong generalization ability on out-of-distribution meshes. The code and pretrained model can be found on https://github.com/IntelligentGeometry/GeGnn.