 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhom to Query for What: Adaptive Group Elicitation via Multi-Turn LLM Interactions
Feb 15, 2026Eliciting information to reduce uncertainty about latent group-level properties from surveys and other collective assessments requires allocating limited questioning effort under real costs and missing data. Although large language models enable adaptive, multi-turn interactions in natural language, most existing elicitation methods optimize what to ask with a fixed respondent pool, and do not adapt respondent selection or leverage population structure when responses are partial or incomplete. To address this gap, we study adaptive group elicitation, a multi-round setting where an agent adaptively selects both questions and respondents under explicit query and participation budgets. We propose a theoretically grounded framework that combines (i) an LLM-based expected information gain objective for scoring candidate questions with (ii) heterogeneous graph neural network propagation that aggregates observed responses and participant attributes to impute missing responses and guide per-round respondent selection. This closed-loop procedure queries a small, informative subset of individuals while inferring population-level responses via structured similarity. Across three real-world opinion datasets, our method consistently improves population-level response prediction under constrained budgets, including a >12% relative gain on CES at a 10% respondent budget.
Rubrics as an Attack Surface: Stealthy Preference Drift in LLM Judges
Feb 14, 2026Evaluation and alignment pipelines for large language models increasingly rely on LLM-based judges, whose behavior is guided by natural-language rubrics and validated on benchmarks. We identify a previously under-recognized vulnerability in this workflow, which we term Rubric-Induced Preference Drift (RIPD). Even when rubric edits pass benchmark validation, they can still produce systematic and directional shifts in a judge's preferences on target domains. Because rubrics serve as a high-level decision interface, such drift can emerge from seemingly natural, criterion-preserving edits and remain difficult to detect through aggregate benchmark metrics or limited spot-checking. We further show this vulnerability can be exploited through rubric-based preference attacks, in which benchmark-compliant rubric edits steer judgments away from a fixed human or trusted reference on target domains, systematically inducing RIPD and reducing target-domain accuracy up to 9.5% (helpfulness) and 27.9% (harmlessness). When these judgments are used to generate preference labels for downstream post-training, the induced bias propagates through alignment pipelines and becomes internalized in trained policies. This leads to persistent and systematic drift in model behavior. Overall, our findings highlight evaluation rubrics as a sensitive and manipulable control interface, revealing a system-level alignment risk that extends beyond evaluator reliability alone. The code is available at: https://github.com/ZDCSlab/Rubrics-as-an-Attack-Surface. Warning: Certain sections may contain potentially harmful content that may not be appropriate for all readers.
SkillGen: Learning Domain Skills for In-Context Sequential Decision Making
Nov 18, 2025Large language models (LLMs) are increasingly applied to sequential decision-making through in-context learning (ICL), yet their effectiveness is highly sensitive to prompt quality. Effective prompts should meet three principles: focus on decision-critical information, provide step-level granularity, and minimize reliance on expert annotations through label efficiency. However, existing ICL methods often fail to satisfy all three criteria simultaneously. Motivated by these challenges, we introduce SkillGen, a skill-based ICL framework for structured sequential reasoning. It constructs an action-centric, domain-level graph from sampled trajectories, identifies high-utility actions via temporal-difference credit assignment, and retrieves step-wise skills to generate fine-grained, context-aware prompts. We further present a theoretical analysis showing that focusing on high-utility segments supports task identifiability and informs more effective ICL prompt design. Experiments on ALFWorld, BabyAI, and ScienceWorld, using both open-source and proprietary LLMs, show that SkillGen achieves consistent gains, improving progress rate by 5.9%-16.5% on average across models.
Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs
Jun 14, 2024



Reward models trained on human preference data have been proven to be effective for aligning Large Language Models (LLMs) with human intent within the reinforcement learning from human feedback (RLHF) framework. However, the generalization capabilities of current reward models to unseen prompts and responses are limited. This limitation can lead to an unexpected phenomenon known as reward over-optimization, where excessive optimization of rewards results in a decline in actual performance. While previous research has advocated for constraining policy optimization, our study proposes a novel approach to enhance the reward model's generalization ability against distribution shifts by regularizing the hidden states. Specifically, we retain the base model's language model head and incorporate a suite of text-generation losses to preserve the hidden states' text generation capabilities, while concurrently learning a reward head behind the same hidden states. Our experimental results demonstrate that the introduced regularization technique markedly improves the accuracy of learned reward models across a variety of out-of-distribution (OOD) tasks and effectively alleviate the over-optimization issue in RLHF, offering a more reliable and robust preference learning paradigm.
Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation
Nov 12, 2023



Recent advancements in Large Language Models (LLMs) have revolutionized decision-making by breaking down complex problems into more manageable language sequences referred to as ``thoughts''. An effective thought design should consider three key perspectives: performance, efficiency, and flexibility. However, existing thought can at most exhibit two of these attributes. To address these limitations, we introduce a novel thought prompting approach called ``Everything of Thoughts'' (XoT) to defy the law of ``Penrose triangle of existing thought paradigms. XoT leverages pretrained reinforcement learning and Monte Carlo Tree Search (MCTS) to incorporate external domain knowledge into thoughts, thereby enhancing LLMs' capabilities and enabling them to generalize to unseen problems efficiently. Through the utilization of the MCTS-LLM collaborative thought revision framework, this approach autonomously produces high-quality comprehensive cognitive mappings with minimal LLM interactions. Additionally, XoT empowers LLMs to engage in unconstrained thinking, allowing for flexible cognitive mappings for problems with multiple solutions. We evaluate XoT on several challenging multi-solution problem-solving tasks, including Game of 24, 8-Puzzle, and Pocket Cube. Our results demonstrate that XoT significantly outperforms existing approaches. Notably, XoT can yield multiple solutions with just one LLM call, showcasing its remarkable proficiency in addressing complex problems across diverse domains.
ImDiffusion: Imputed Diffusion Models for Multivariate Time Series Anomaly Detection
Jul 03, 2023



Anomaly detection in multivariate time series data is of paramount importance for ensuring the efficient operation of large-scale systems across diverse domains. However, accurately detecting anomalies in such data poses significant challenges. Existing approaches, including forecasting and reconstruction-based methods, struggle to address these challenges effectively. To overcome these limitations, we propose a novel anomaly detection framework named ImDiffusion, which combines time series imputation and diffusion models to achieve accurate and robust anomaly detection. The imputation-based approach employed by ImDiffusion leverages the information from neighboring values in the time series, enabling precise modeling of temporal and inter-correlated dependencies, reducing uncertainty in the data, thereby enhancing the robustness of the anomaly detection process. ImDiffusion further leverages diffusion models as time series imputers to accurately capturing complex dependencies. We leverage the step-by-step denoised outputs generated during the inference process to serve as valuable signals for anomaly prediction, resulting in improved accuracy and robustness of the detection process. We evaluate the performance of ImDiffusion via extensive experiments on benchmark datasets. The results demonstrate that our proposed framework significantly outperforms state-of-the-art approaches in terms of detection accuracy and timeliness. ImDiffusion is further integrated into the real production system in Microsoft and observe a remarkable 11.4% increase in detection F1 score compared to the legacy approach. To the best of our knowledge, ImDiffusion represents a pioneering approach that combines imputation-based techniques with time series anomaly detection, while introducing the novel use of diffusion models to the field.
Action Unit Detection with Joint Adaptive Attention and Graph Relation
Jul 09, 2021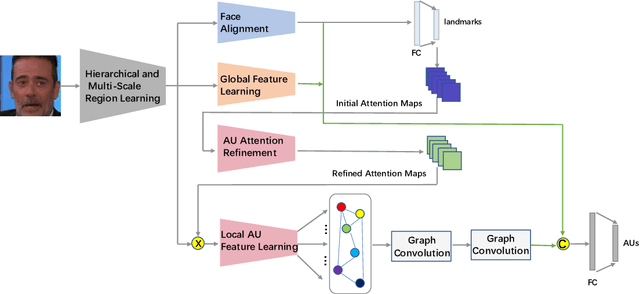
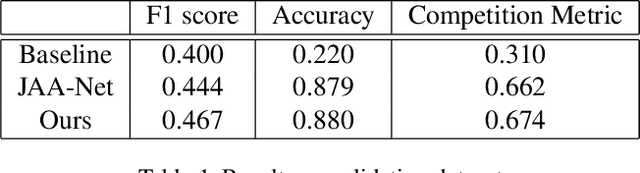
This paper describes an approach to the facial action unit (AU) detection. In this work, we present our submission to the Field Affective Behavior Analysis (ABAW) 2021 competition. The proposed method uses the pre-trained JAA model as the feature extractor, and extracts global features, face alignment features and AU local features on the basis of multi-scale features. We take the AU local features as the input of the graph convolution to further consider the correlation between AU, and finally use the fused features to classify AU. The detected accuracy was evaluated by 0.5*accuracy + 0.5*F1. Our model achieves 0.674 on the challenging Aff-Wild2 database.