 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Real-Time Semantic Segmentation of Aphid Clusters in the Wild
Jul 17, 2023

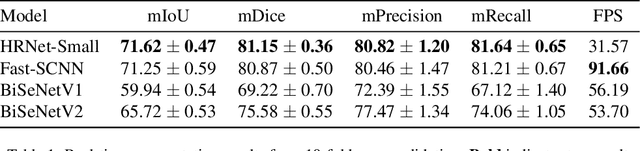

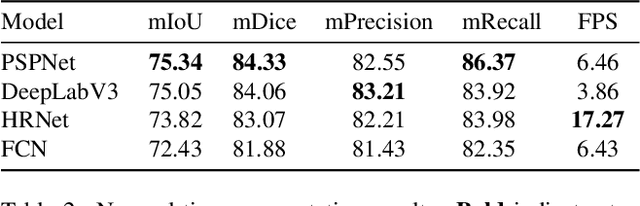
Aphid infestations can cause extensive damage to wheat and sorghum fields and spread plant viruses, resulting in significant yield losses in agriculture. To address this issue, farmers often rely on chemical pesticides, which are inefficiently applied over large areas of fields. As a result, a considerable amount of pesticide is wasted on areas without pests, while inadequate amounts are applied to areas with severe infestations. The paper focuses on the urgent need for an intelligent autonomous system that can locate and spray infestations within complex crop canopies, reducing pesticide use and environmental impact. We have collected and labeled a large aphid image dataset in the field, and propose the use of real-time semantic segmentation models to segment clusters of aphids. A multiscale dataset is generated to allow for learning the clusters at different scales. We compare the segmentation speeds and accuracy of four state-of-the-art real-time semantic segmentation models on the aphid cluster dataset, benchmarking them against nonreal-time models. The study results show the effectiveness of a real-time solution, which can reduce inefficient pesticide use and increase crop yields, paving the way towards an autonomous pest detection system.
Beamforming Design for RIS-Aided THz Wideband Communication Systems
Sep 21, 2023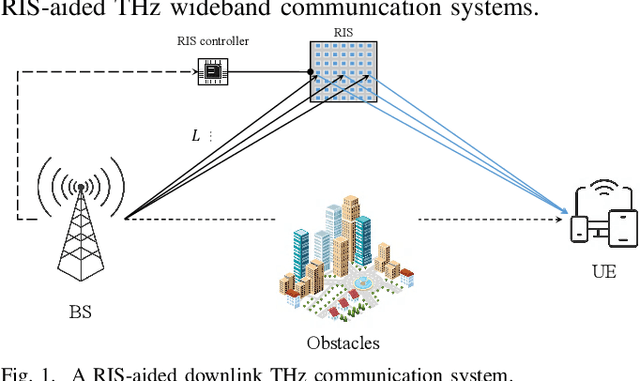
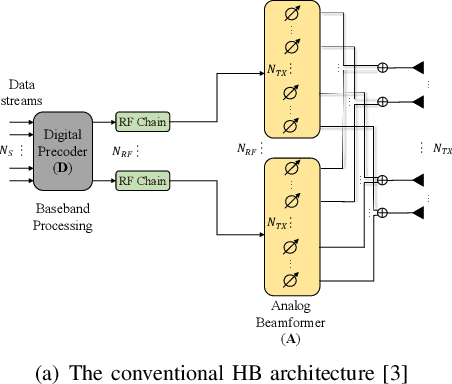
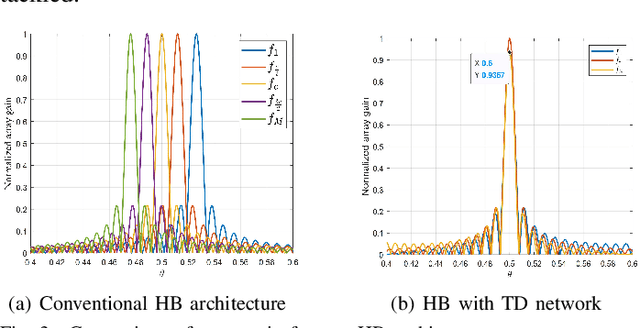
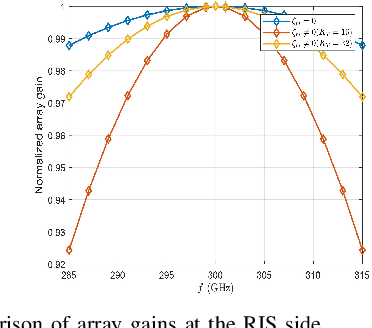
Benefiting from tens of GHz of bandwidth, terahertz (THz) communications has become a promising technology for future 6G networks. However, the conventional hybrid beamforming architecture based on frequency-independent phase-shifters is not able to cope with the beam split effect (BSE) in THz massive multiple-input multiple-output (MIMO) systems. Despite some work introducing the frequency-dependent phase shifts via the time delay network to mitigate the beam splitting in THz wideband communications, the corresponding issue in reconfigurable intelligent surface (RIS)-aided communications has not been well investigated. In this paper, the BSE in THz massive MIMO is quantified by analyzing the array gain loss. A new beamforming architecture has been proposed to mitigate this effect under RIS-aided communications scenarios. Simulations are performed to evaluate the effectiveness of the proposed system architecture in combating the array gain loss.
Folding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition
Sep 21, 2023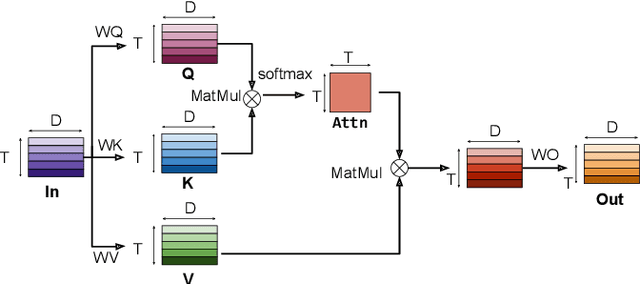
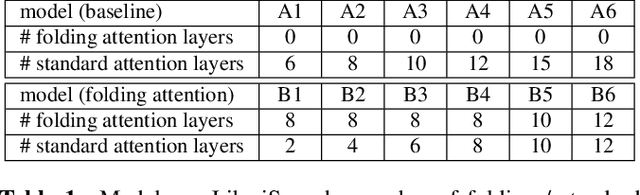
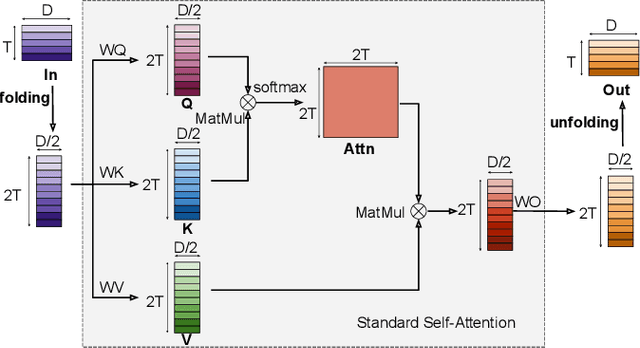
Transformer-based models excel in speech recognition. Existing efforts to optimize Transformer inference, typically for long-context applications, center on simplifying attention score calculations. However, streaming speech recognition models usually process a limited number of tokens each time, making attention score calculation less of a bottleneck. Instead, the bottleneck lies in the linear projection layers of multi-head attention and feedforward networks, constituting a substantial portion of the model size and contributing significantly to computation, memory, and power usage. To address this bottleneck, we propose folding attention, a technique targeting these linear layers, significantly reducing model size and improving memory and power efficiency. Experiments on on-device Transformer-based streaming speech recognition models show that folding attention reduces model size (and corresponding memory consumption) by up to 24% and power consumption by up to 23%, all without compromising model accuracy or computation overhead.
Interpretable and Efficient Beamforming-Based Deep Learning for Single Snapshot DOA Estimation
Sep 14, 2023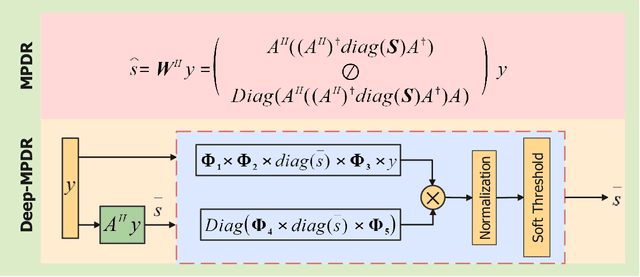
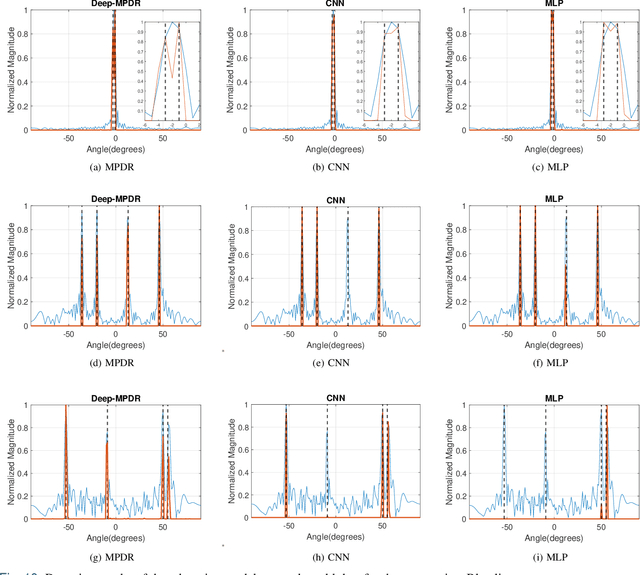
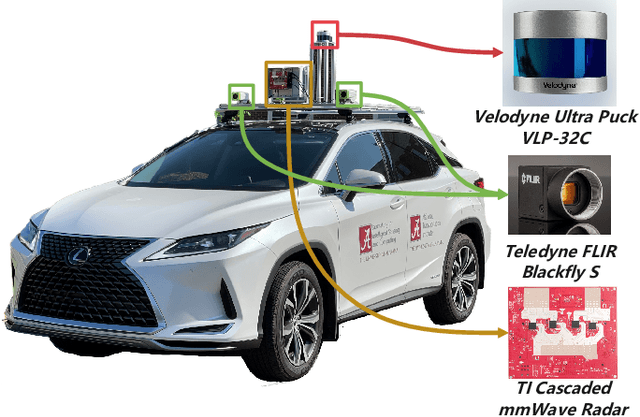
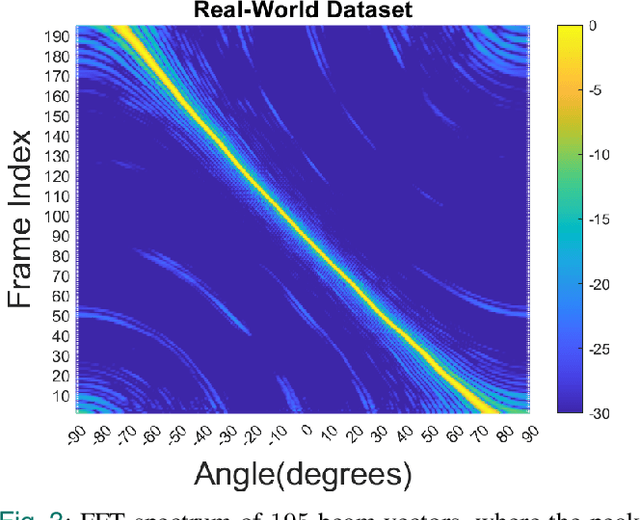
We introduce an interpretable deep learning approach for direction of arrival (DOA) estimation with a single snapshot. Classical subspace-based methods like MUSIC and ESPRIT use spatial smoothing on uniform linear arrays for single snapshot DOA estimation but face drawbacks in reduced array aperture and inapplicability to sparse arrays. Single-snapshot methods such as compressive sensing and iterative adaptation approach (IAA) encounter challenges with high computational costs and slow convergence, hampering real-time use. Recent deep learning DOA methods offer promising accuracy and speed. However, the practical deployment of deep networks is hindered by their black-box nature. To address this, we propose a deep-MPDR network translating minimum power distortionless response (MPDR)-type beamformer into deep learning, enhancing generalization and efficiency. Comprehensive experiments conducted using both simulated and real-world datasets substantiate its dominance in terms of inference time and accuracy in comparison to conventional methods. Moreover, it excels in terms of efficiency, generalizability, and interpretability when contrasted with other deep learning DOA estimation networks.
TEMPO: Efficient Multi-View Pose Estimation, Tracking, and Forecasting
Sep 14, 2023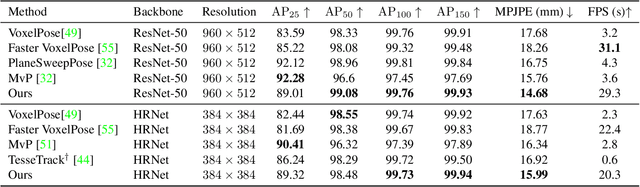
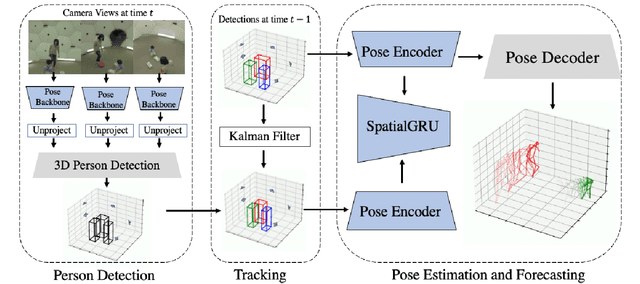
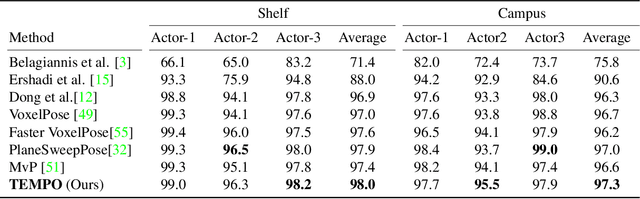
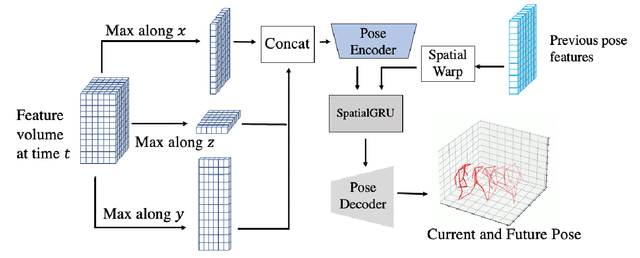
Existing volumetric methods for predicting 3D human pose estimation are accurate, but computationally expensive and optimized for single time-step prediction. We present TEMPO, an efficient multi-view pose estimation model that learns a robust spatiotemporal representation, improving pose accuracy while also tracking and forecasting human pose. We significantly reduce computation compared to the state-of-the-art by recurrently computing per-person 2D pose features, fusing both spatial and temporal information into a single representation. In doing so, our model is able to use spatiotemporal context to predict more accurate human poses without sacrificing efficiency. We further use this representation to track human poses over time as well as predict future poses. Finally, we demonstrate that our model is able to generalize across datasets without scene-specific fine-tuning. TEMPO achieves 10$\%$ better MPJPE with a 33$\times$ improvement in FPS compared to TesseTrack on the challenging CMU Panoptic Studio dataset.
Zero-Shot Constrained Motion Planning Transformers Using Learned Sampling Dictionaries
Sep 26, 2023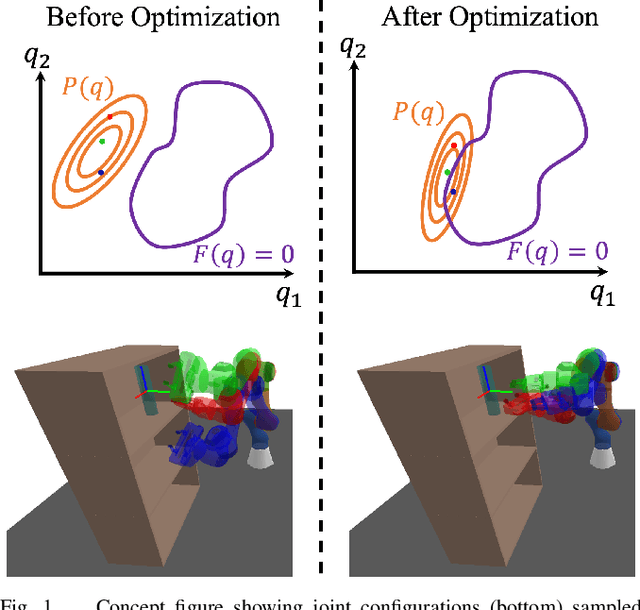
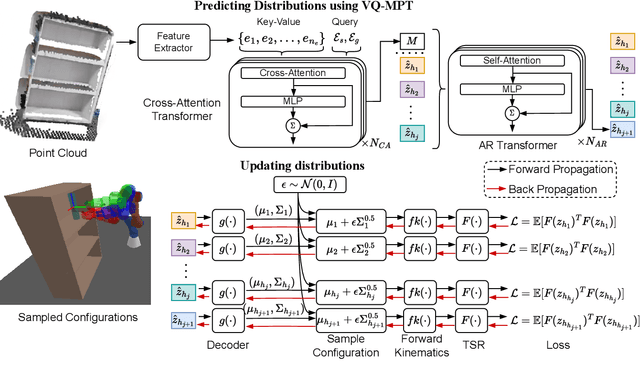
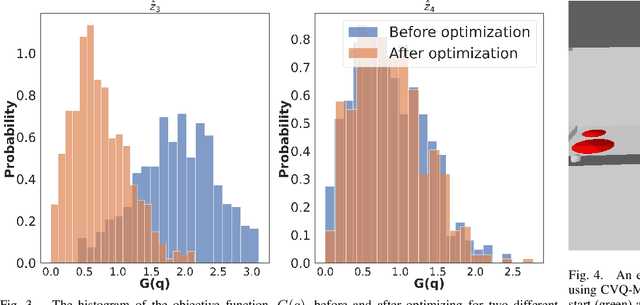

Constrained robot motion planning is a ubiquitous need for robots interacting with everyday environments, but it is a notoriously difficult problem to solve. Many sampled points in a sample-based planner need to be rejected as they fall outside the constraint manifold, or require significant iterative effort to correct. Given this, few solutions exist that present a constraint-satisfying trajectory for robots, in reasonable time and of low path cost. In this work, we present a transformer-based model for motion planning with task space constraints for manipulation systems. Vector Quantized-Motion Planning Transformer (VQ-MPT) is a recent learning-based model that reduces the search space for unconstrained planning for sampling-based motion planners. We propose to adapt a pre-trained VQ-MPT model to reduce the search space for constraint planning without retraining or finetuning the model. We also propose to update the neural network output to move sampling regions closer to the constraint manifold. Our experiments show how VQ-MPT improves planning times and accuracy compared to traditional planners in simulated and real-world environments. Unlike previous learning methods, which require task-related data, our method uses pre-trained neural network models and requires no additional data for training and finetuning the model making this a \textit{one-shot} process. We also tested our method on a physical Franka Panda robot with real-world sensor data, demonstrating the generalizability of our algorithm. We anticipate this approach to be an accessible and broadly useful for transferring learned neural planners to various robotic-environment interaction scenarios.
Applications of Sequential Learning for Medical Image Classification
Sep 26, 2023Purpose: The aim of this work is to develop a neural network training framework for continual training of small amounts of medical imaging data and create heuristics to assess training in the absence of a hold-out validation or test set. Materials and Methods: We formulated a retrospective sequential learning approach that would train and consistently update a model on mini-batches of medical images over time. We address problems that impede sequential learning such as overfitting, catastrophic forgetting, and concept drift through PyTorch convolutional neural networks (CNN) and publicly available Medical MNIST and NIH Chest X-Ray imaging datasets. We begin by comparing two methods for a sequentially trained CNN with and without base pre-training. We then transition to two methods of unique training and validation data recruitment to estimate full information extraction without overfitting. Lastly, we consider an example of real-life data that shows how our approach would see mainstream research implementation. Results: For the first experiment, both approaches successfully reach a ~95% accuracy threshold, although the short pre-training step enables sequential accuracy to plateau in fewer steps. The second experiment comparing two methods showed better performance with the second method which crosses the ~90% accuracy threshold much sooner. The final experiment showed a slight advantage with a pre-training step that allows the CNN to cross ~60% threshold much sooner than without pre-training. Conclusion: We have displayed sequential learning as a serviceable multi-classification technique statistically comparable to traditional CNNs that can acquire data in small increments feasible for clinically realistic scenarios.
Nuclear Morphometry using a Deep Learning-based Algorithm has Prognostic Relevance for Canine Cutaneous Mast Cell Tumors
Sep 26, 2023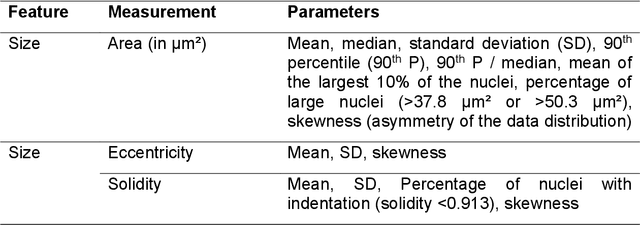
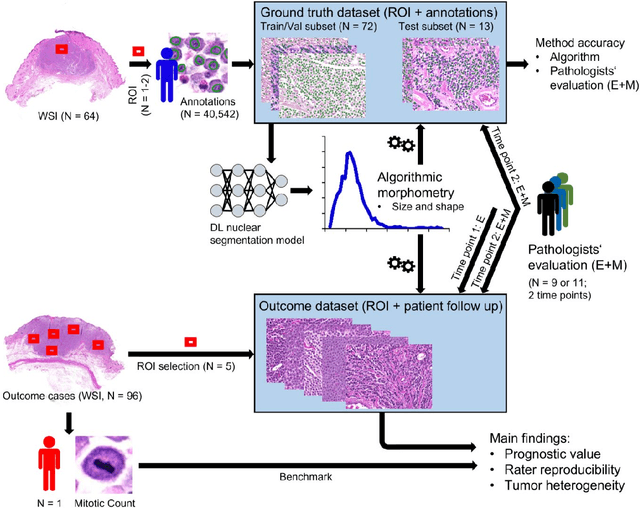
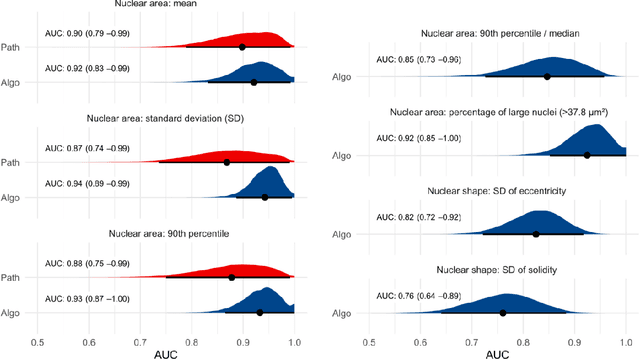
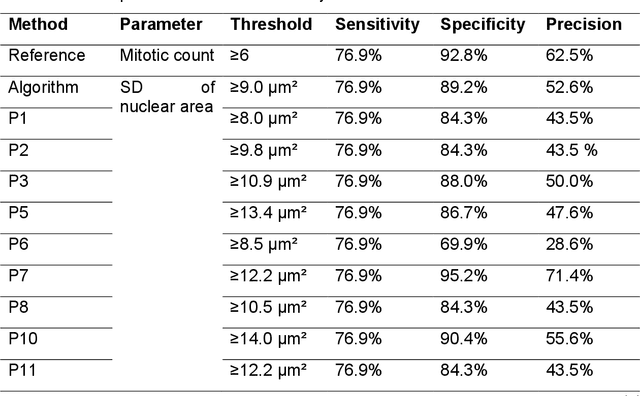
Variation in nuclear size and shape is an important criterion of malignancy for many tumor types; however, categorical estimates by pathologists have poor reproducibility. Measurements of nuclear characteristics (morphometry) can improve reproducibility, but manual methods are time consuming. In this study, we evaluated fully automated morphometry using a deep learning-based algorithm in 96 canine cutaneous mast cell tumors with information on patient survival. Algorithmic morphometry was compared with karyomegaly estimates by 11 pathologists, manual nuclear morphometry of 12 cells by 9 pathologists, and the mitotic count as a benchmark. The prognostic value of automated morphometry was high with an area under the ROC curve regarding the tumor-specific survival of 0.943 (95% CI: 0.889 - 0.996) for the standard deviation (SD) of nuclear area, which was higher than manual morphometry of all pathologists combined (0.868, 95% CI: 0.737 - 0.991) and the mitotic count (0.885, 95% CI: 0.765 - 1.00). At the proposed thresholds, the hazard ratio for algorithmic morphometry (SD of nuclear area $\geq 9.0 \mu m^2$) was 18.3 (95% CI: 5.0 - 67.1), for manual morphometry (SD of nuclear area $\geq 10.9 \mu m^2$) 9.0 (95% CI: 6.0 - 13.4), for karyomegaly estimates 7.6 (95% CI: 5.7 - 10.1), and for the mitotic count 30.5 (95% CI: 7.8 - 118.0). Inter-rater reproducibility for karyomegaly estimates was fair ($\kappa$ = 0.226) with highly variable sensitivity/specificity values for the individual pathologists. Reproducibility for manual morphometry (SD of nuclear area) was good (ICC = 0.654). This study supports the use of algorithmic morphometry as a prognostic test to overcome the limitations of estimates and manual measurements.
Unifying over-smoothing and over-squashing in graph neural networks: A physics informed approach and beyond
Sep 13, 2023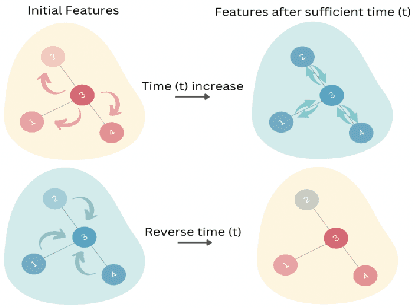
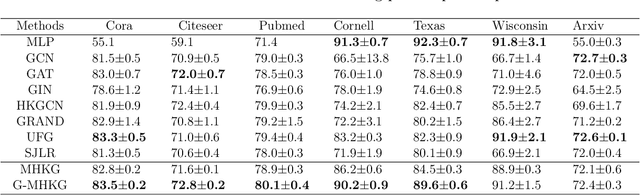
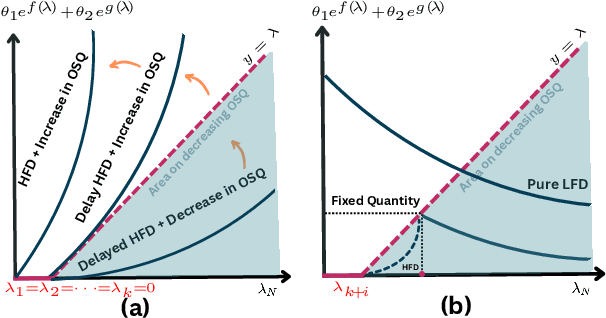
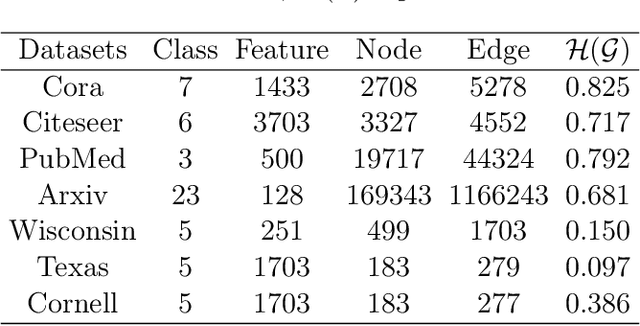
Graph Neural Networks (GNNs) have emerged as one of the leading approaches for machine learning on graph-structured data. Despite their great success, critical computational challenges such as over-smoothing, over-squashing, and limited expressive power continue to impact the performance of GNNs. In this study, inspired from the time-reversal principle commonly utilized in classical and quantum physics, we reverse the time direction of the graph heat equation. The resulted reversing process yields a class of high pass filtering functions that enhance the sharpness of graph node features. Leveraging this concept, we introduce the Multi-Scaled Heat Kernel based GNN (MHKG) by amalgamating diverse filtering functions' effects on node features. To explore more flexible filtering conditions, we further generalize MHKG into a model termed G-MHKG and thoroughly show the roles of each element in controlling over-smoothing, over-squashing and expressive power. Notably, we illustrate that all aforementioned issues can be characterized and analyzed via the properties of the filtering functions, and uncover a trade-off between over-smoothing and over-squashing: enhancing node feature sharpness will make model suffer more from over-squashing, and vice versa. Furthermore, we manipulate the time again to show how G-MHKG can handle both two issues under mild conditions. Our conclusive experiments highlight the effectiveness of proposed models. It surpasses several GNN baseline models in performance across graph datasets characterized by both homophily and heterophily.
Performance Analysis of OTSM under Hardware Impairments in Millimeter-Wave Vehicular Communication Networks
Sep 08, 2023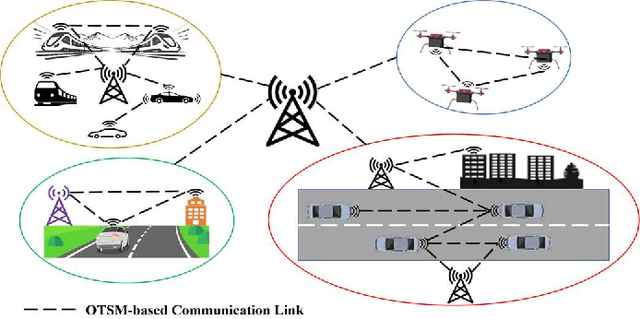
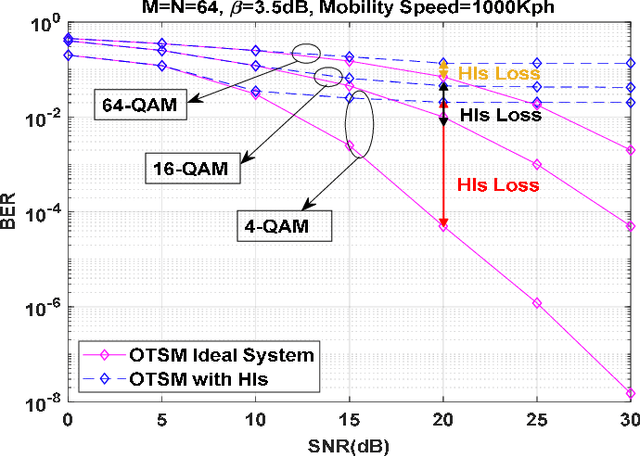
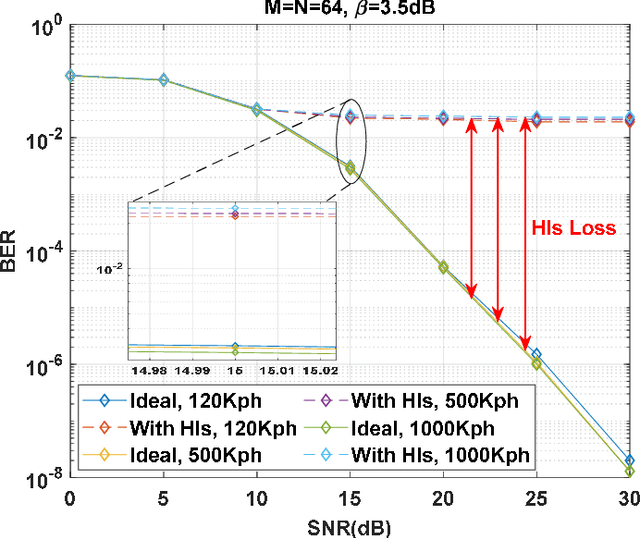
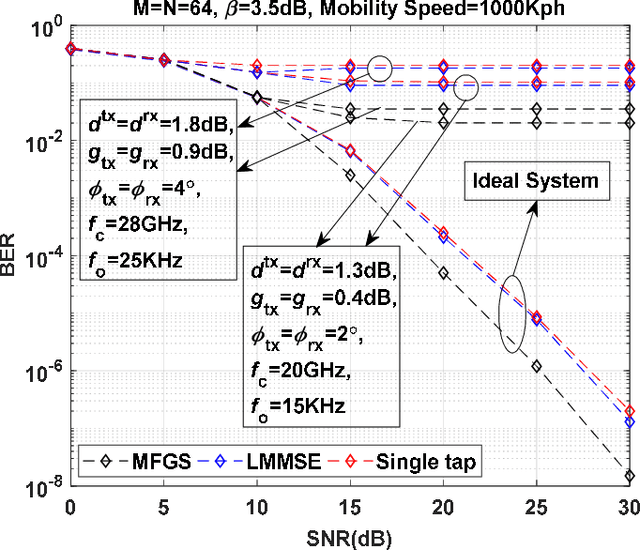
Orthogonal time sequency multiplexing (OTSM) has been recently proposed as a single-carrier (SC) waveform offering similar bit error rate (BER) to multi-carrier orthogonal time frequency space (OTFS) modulation in doubly-spread channels under high mobilities; however, with much lower complexity making OTSM a promising candidate for low-power millimeter-wave (mmWave) vehicular communications in 6G wireless networks. In this paper, the performance of OTSM-based homodyne transceiver is explored under hardware impairments (HIs) including in-phase and quadrature imbalance (IQI), direct current offset (DCO), phase noise, power amplifier non-linearity, carrier frequency offset, and synchronization timing offset. First, the discrete-time baseband signal model is obtained in vector form under the mentioned HIs. Then, the system input-output relations are derived in time, delay-time, and delay-sequency (DS) domains in which the parameters of HIs are incorporated. Analytical studies demonstrate that noise stays white Gaussian and effective channel matrix is sparse in the DS domain under HIs. Also, DCO appears as a DC signal at receiver interfering with only the zero sequency over all delay taps in the DS domain; however, IQI redounds to self-conjugated fully-overlapping sequency interference. Simulation results reveal the fact that with no HI compensation (HIC), not only OTSM outperforms plain SC waveform but it performs close to uncompensated OTFS system; however, HIC is essentially needed for OTSM systems operating in mmWave and beyond frequency bands.