 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier Pooling for Modern Ordinal Classification
Mar 18, 2026Ordinal data is widely prevalent in clinical and other domains, yet there is a lack of both modern, machine-learning based methods and publicly available software to address it. In this paper, we present a model-agnostic method of ordinal classification, which can apply any non-ordinal classification method in an ordinal fashion. We also provide an open-source implementation of these algorithms, in the form of a Python package. We apply these models on multiple real-world datasets to show their performance across domains. We show that they often outperform non-ordinal classification methods, especially when the number of datapoints is relatively small or when there are many classes of outcomes. This work, including the developed software, facilitates the use of modern, more powerful machine learning algorithms to handle ordinal data.
Adaptive Label Error Detection: A Bayesian Approach to Mislabeled Data Detection
Jan 15, 2026Machine learning classification systems are susceptible to poor performance when trained with incorrect ground truth labels, even when data is well-curated by expert annotators. As machine learning becomes more widespread, it is increasingly imperative to identify and correct mislabeling to develop more powerful models. In this work, we motivate and describe Adaptive Label Error Detection (ALED), a novel method of detecting mislabeling. ALED extracts an intermediate feature space from a deep convolutional neural network, denoises the features, models the reduced manifold of each class with a multidimensional Gaussian distribution, and performs a simple likelihood ratio test to identify mislabeled samples. We show that ALED has markedly increased sensitivity, without compromising precision, compared to established label error detection methods, on multiple medical imaging datasets. We demonstrate an example where fine-tuning a neural network on corrected data results in a 33.8% decrease in test set errors, providing strong benefits to end users. The ALED detector is deployed in the Python package statlab.
Evidential Uncertainty Quantification: A Variance-Based Perspective
Nov 19, 2023



Uncertainty quantification of deep neural networks has become an active field of research and plays a crucial role in various downstream tasks such as active learning. Recent advances in evidential deep learning shed light on the direct quantification of aleatoric and epistemic uncertainties with a single forward pass of the model. Most traditional approaches adopt an entropy-based method to derive evidential uncertainty in classification, quantifying uncertainty at the sample level. However, the variance-based method that has been widely applied in regression problems is seldom used in the classification setting. In this work, we adapt the variance-based approach from regression to classification, quantifying classification uncertainty at the class level. The variance decomposition technique in regression is extended to class covariance decomposition in classification based on the law of total covariance, and the class correlation is also derived from the covariance. Experiments on cross-domain datasets are conducted to illustrate that the variance-based approach not only results in similar accuracy as the entropy-based one in active domain adaptation but also brings information about class-wise uncertainties as well as between-class correlations. The code is available at https://github.com/KerryDRX/EvidentialADA. This alternative means of evidential uncertainty quantification will give researchers more options when class uncertainties and correlations are important in their applications.
Applications of Sequential Learning for Medical Image Classification
Sep 26, 2023



Purpose: The aim of this work is to develop a neural network training framework for continual training of small amounts of medical imaging data and create heuristics to assess training in the absence of a hold-out validation or test set. Materials and Methods: We formulated a retrospective sequential learning approach that would train and consistently update a model on mini-batches of medical images over time. We address problems that impede sequential learning such as overfitting, catastrophic forgetting, and concept drift through PyTorch convolutional neural networks (CNN) and publicly available Medical MNIST and NIH Chest X-Ray imaging datasets. We begin by comparing two methods for a sequentially trained CNN with and without base pre-training. We then transition to two methods of unique training and validation data recruitment to estimate full information extraction without overfitting. Lastly, we consider an example of real-life data that shows how our approach would see mainstream research implementation. Results: For the first experiment, both approaches successfully reach a ~95% accuracy threshold, although the short pre-training step enables sequential accuracy to plateau in fewer steps. The second experiment comparing two methods showed better performance with the second method which crosses the ~90% accuracy threshold much sooner. The final experiment showed a slight advantage with a pre-training step that allows the CNN to cross ~60% threshold much sooner than without pre-training. Conclusion: We have displayed sequential learning as a serviceable multi-classification technique statistically comparable to traditional CNNs that can acquire data in small increments feasible for clinically realistic scenarios.
Learning sources of variability from high-dimensional observational studies
Jul 26, 2023Causal inference studies whether the presence of a variable influences an observed outcome. As measured by quantities such as the "average treatment effect," this paradigm is employed across numerous biological fields, from vaccine and drug development to policy interventions. Unfortunately, the majority of these methods are often limited to univariate outcomes. Our work generalizes causal estimands to outcomes with any number of dimensions or any measurable space, and formulates traditional causal estimands for nominal variables as causal discrepancy tests. We propose a simple technique for adjusting universally consistent conditional independence tests and prove that these tests are universally consistent causal discrepancy tests. Numerical experiments illustrate that our method, Causal CDcorr, leads to improvements in both finite sample validity and power when compared to existing strategies. Our methods are all open source and available at github.com/ebridge2/cdcorr.
The Multiple Subnetwork Hypothesis: Enabling Multidomain Learning by Isolating Task-Specific Subnetworks in Feedforward Neural Networks
Jul 18, 2022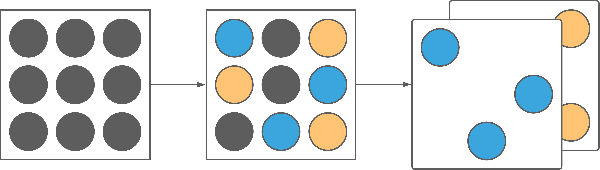
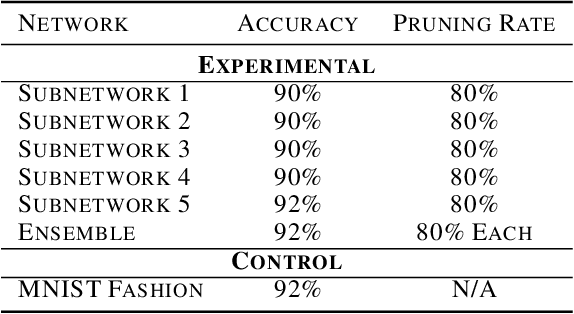
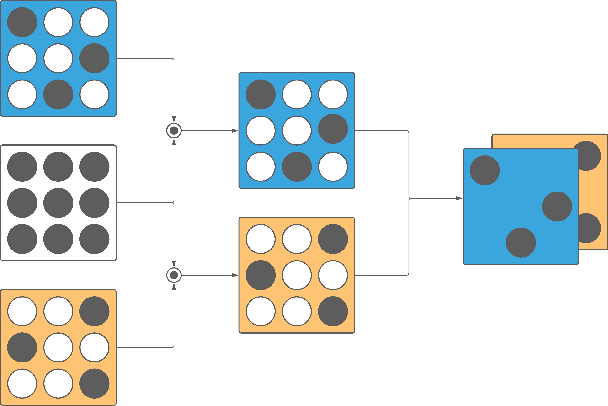

Neural networks have seen an explosion of usage and research in the past decade, particularly within the domains of computer vision and natural language processing. However, only recently have advancements in neural networks yielded performance improvements beyond narrow applications and translated to expanded multitask models capable of generalizing across multiple data types and modalities. Simultaneously, it has been shown that neural networks are overparameterized to a high degree, and pruning techniques have proved capable of significantly reducing the number of active weights within the network while largely preserving performance. In this work, we identify a methodology and network representational structure which allows a pruned network to employ previously unused weights to learn subsequent tasks. We employ these methodologies on well-known benchmarking datasets for testing purposes and show that networks trained using our approaches are able to learn multiple tasks, which may be related or unrelated, in parallel or in sequence without sacrificing performance on any task or exhibiting catastrophic forgetting.
Prospective Learning: Back to the Future
Jan 19, 2022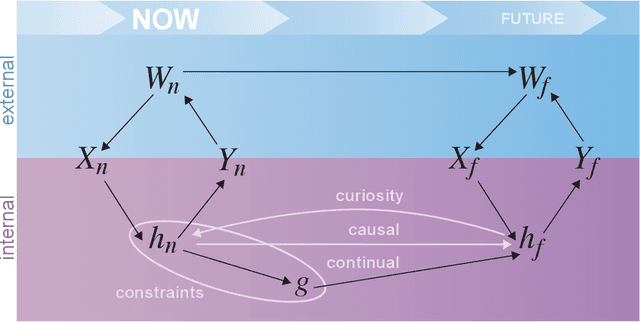

Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Joint Estimation of Multiple Graphical Models from High Dimensional Time Series
Oct 08, 2014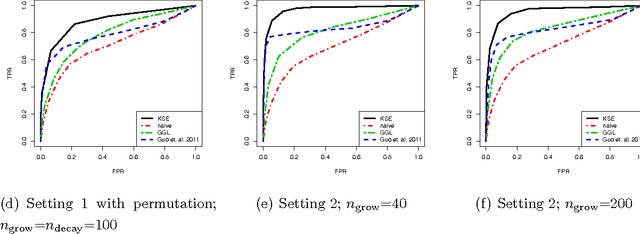
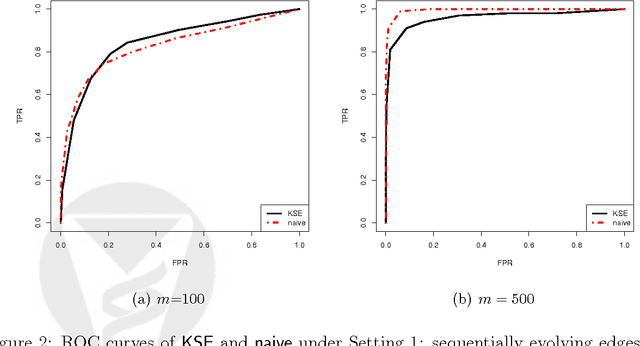
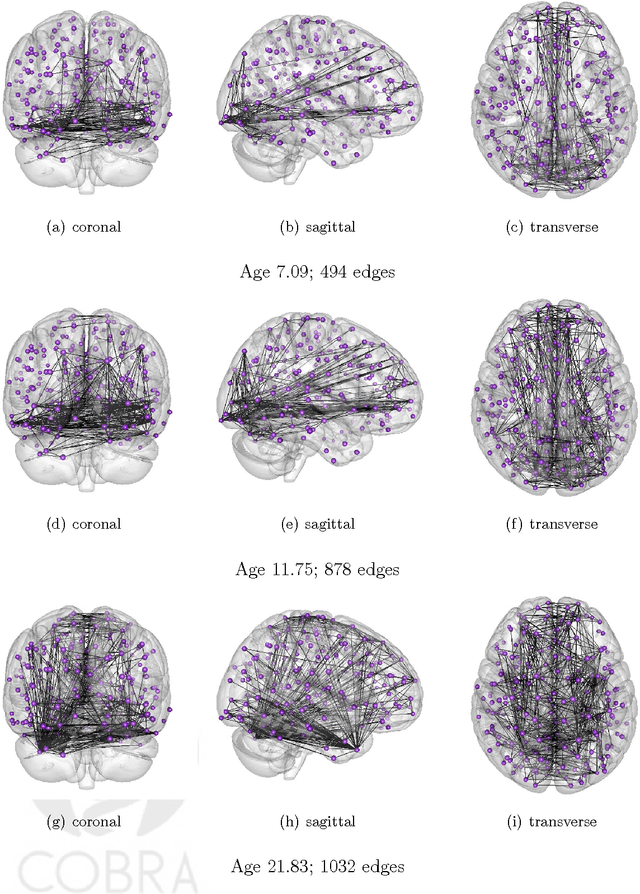
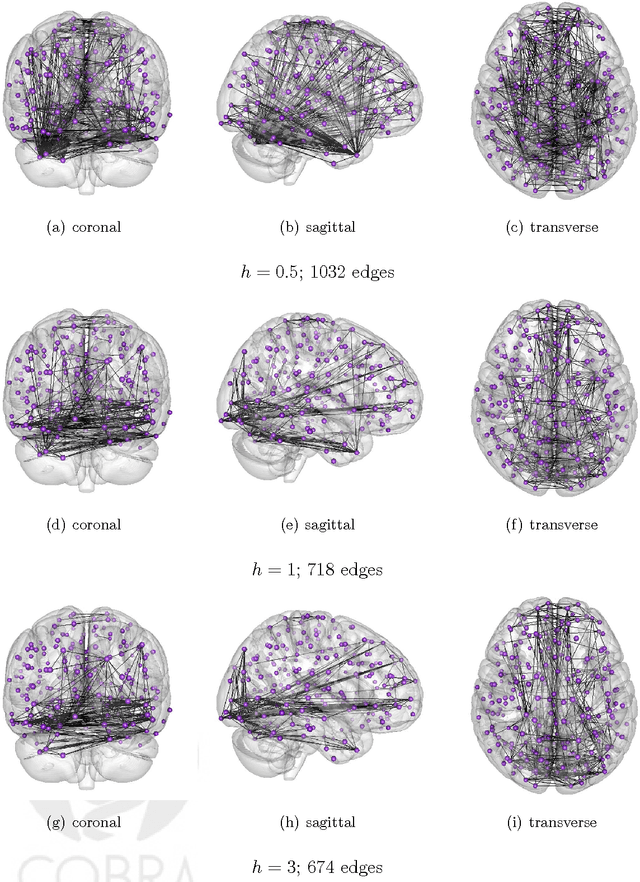
In this manuscript we consider the problem of jointly estimating multiple graphical models in high dimensions. We assume that the data are collected from n subjects, each of which consists of T possibly dependent observations. The graphical models of subjects vary, but are assumed to change smoothly corresponding to a measure of closeness between subjects. We propose a kernel based method for jointly estimating all graphical models. Theoretically, under a double asymptotic framework, where both (T,n) and the dimension d can increase, we provide the explicit rate of convergence in parameter estimation. It characterizes the strength one can borrow across different individuals and impact of data dependence on parameter estimation. Empirically, experiments on both synthetic and real resting state functional magnetic resonance imaging (rs-fMRI) data illustrate the effectiveness of the proposed method.
MONEYBaRL: Exploiting pitcher decision-making using Reinforcement Learning
Jul 31, 2014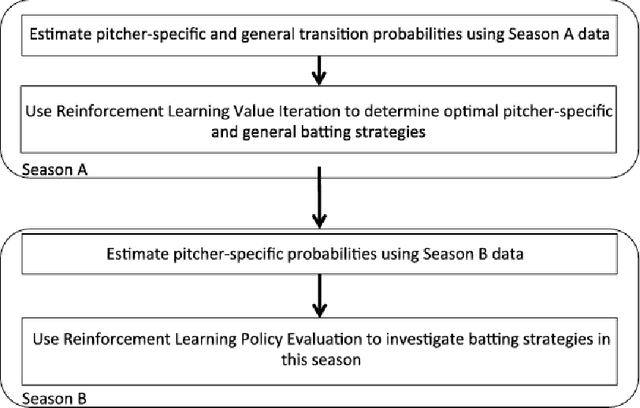
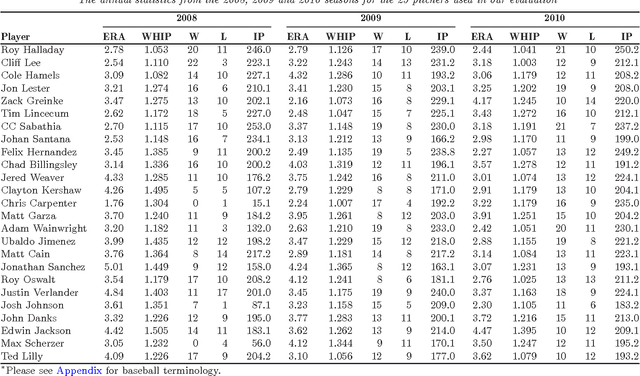
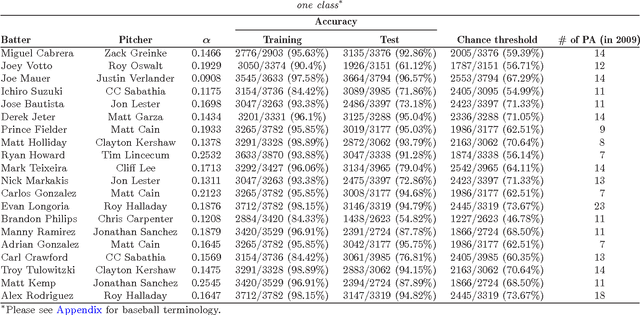
This manuscript uses machine learning techniques to exploit baseball pitchers' decision making, so-called "Baseball IQ," by modeling the at-bat information, pitch selection and counts, as a Markov Decision Process (MDP). Each state of the MDP models the pitcher's current pitch selection in a Markovian fashion, conditional on the information immediately prior to making the current pitch. This includes the count prior to the previous pitch, his ensuing pitch selection, the batter's ensuing action and the result of the pitch.
* Published in at http://dx.doi.org/10.1214/13-AOAS712 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)