 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Apr 02, 2024
Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific positions in a sequence, optimising the allocation along the sequence for different layers across the model depth. Our method enforces a total compute budget by capping the number of tokens ($k$) that can participate in the self-attention and MLP computations at a given layer. The tokens to be processed are determined by the network using a top-$k$ routing mechanism. Since $k$ is defined a priori, this simple procedure uses a static computation graph with known tensor sizes, unlike other conditional computation techniques. Nevertheless, since the identities of the $k$ tokens are fluid, this method can expend FLOPs non-uniformly across the time and model depth dimensions. Thus, compute expenditure is entirely predictable in sum total, but dynamic and context-sensitive at the token-level. Not only do models trained in this way learn to dynamically allocate compute, they do so efficiently. These models match baseline performance for equivalent FLOPS and wall-clock times to train, but require a fraction of the FLOPs per forward pass, and can be upwards of 50\% faster to step during post-training sampling.
NeRFCodec: Neural Feature Compression Meets Neural Radiance Fields for Memory-Efficient Scene Representation
Apr 02, 2024The emergence of Neural Radiance Fields (NeRF) has greatly impacted 3D scene modeling and novel-view synthesis. As a kind of visual media for 3D scene representation, compression with high rate-distortion performance is an eternal target. Motivated by advances in neural compression and neural field representation, we propose NeRFCodec, an end-to-end NeRF compression framework that integrates non-linear transform, quantization, and entropy coding for memory-efficient scene representation. Since training a non-linear transform directly on a large scale of NeRF feature planes is impractical, we discover that pre-trained neural 2D image codec can be utilized for compressing the features when adding content-specific parameters. Specifically, we reuse neural 2D image codec but modify its encoder and decoder heads, while keeping the other parts of the pre-trained decoder frozen. This allows us to train the full pipeline via supervision of rendering loss and entropy loss, yielding the rate-distortion balance by updating the content-specific parameters. At test time, the bitstreams containing latent code, feature decoder head, and other side information are transmitted for communication. Experimental results demonstrate our method outperforms existing NeRF compression methods, enabling high-quality novel view synthesis with a memory budget of 0.5 MB.
PRISM-TopoMap: Online Topological Mapping with Place Recognition and Scan Matching
Apr 02, 2024Mapping is one of the crucial tasks enabling autonomous navigation of a mobile robot. Conventional mapping methods output dense geometric map representation, e.g. an occupancy grid, which is not trivial to keep consistent for the prolonged runs covering large environments. Meanwhile, capturing the topological structure of the workspace enables fast path planning, is less prone to odometry error accumulation and does not consume much memory. Following this idea, this paper introduces PRISM-TopoMap -- a topological mapping method that maintains a graph of locally aligned locations not relying on global metric coordinates. The proposed method involves learnable multimodal place recognition paired with the scan matching pipeline for localization and loop closure in the graph of locations. The latter is updated online and the robot is localized in a proper node at each time step. We conduct a broad experimental evaluation of the suggested approach in a range of photo-realistic environments and on a real robot (wheeled differential driven Husky robot), and compare it to state of the art. The results of the empirical evaluation confirm that PRISM-Topomap consistently outperforms competitors across several measures of mapping and navigation efficiency and performs well on a real robot. The code of PRISM-Topomap is open-sourced and available at https://github.com/kirillMouraviev/prism-topomap.
Supporting Mitosis Detection AI Training with Inter-Observer Eye-Gaze Consistencies
Apr 02, 2024The expansion of artificial intelligence (AI) in pathology tasks has intensified the demand for doctors' annotations in AI development. However, collecting high-quality annotations from doctors is costly and time-consuming, creating a bottleneck in AI progress. This study investigates eye-tracking as a cost-effective technology to collect doctors' behavioral data for AI training with a focus on the pathology task of mitosis detection. One major challenge in using eye-gaze data is the low signal-to-noise ratio, which hinders the extraction of meaningful information. We tackled this by levering the properties of inter-observer eye-gaze consistencies and creating eye-gaze labels from consistent eye-fixations shared by a group of observers. Our study involved 14 non-medical participants, from whom we collected eye-gaze data and generated eye-gaze labels based on varying group sizes. We assessed the efficacy of such eye-gaze labels by training Convolutional Neural Networks (CNNs) and comparing their performance to those trained with ground truth annotations and a heuristic-based baseline. Results indicated that CNNs trained with our eye-gaze labels closely followed the performance of ground-truth-based CNNs, and significantly outperformed the baseline. Although primarily focused on mitosis, we envision that insights from this study can be generalized to other medical imaging tasks.
Classifying Graphemes in English Words Through the Application of a Fuzzy Inference System
Apr 02, 2024In Linguistics, a grapheme is a written unit of a writing system corresponding to a phonological sound. In Natural Language Processing tasks, written language is analysed through two different mediums, word analysis, and character analysis. This paper focuses on a third approach, the analysis of graphemes. Graphemes have advantages over word and character analysis by being self-contained representations of phonetic sounds. Due to the nature of splitting a word into graphemes being based on complex, non-binary rules, the application of fuzzy logic would provide a suitable medium upon which to predict the number of graphemes in a word. This paper proposes the application of a Fuzzy Inference System to split words into their graphemes. This Fuzzy Inference System results in a correct prediction of the number of graphemes in a word 50.18% of the time, with 93.51% being within a margin of +- 1 from the correct classification. Given the variety in language, graphemes are tied with pronunciation and therefore can change depending on a regional accent/dialect, the +- 1 accuracy represents the impreciseness of grapheme classification when regional variances are accounted for. To give a baseline of comparison, a second method involving a recursive IPA mapping exercise using a pronunciation dictionary was developed to allow for comparisons to be made.
Satellite Federated Edge Learning: Architecture Design and Convergence Analysis
Apr 02, 2024The proliferation of low-earth-orbit (LEO) satellite networks leads to the generation of vast volumes of remote sensing data which is traditionally transferred to the ground server for centralized processing, raising privacy and bandwidth concerns. Federated edge learning (FEEL), as a distributed machine learning approach, has the potential to address these challenges by sharing only model parameters instead of raw data. Although promising, the dynamics of LEO networks, characterized by the high mobility of satellites and short ground-to-satellite link (GSL) duration, pose unique challenges for FEEL. Notably, frequent model transmission between the satellites and ground incurs prolonged waiting time and large transmission latency. This paper introduces a novel FEEL algorithm, named FEDMEGA, tailored to LEO mega-constellation networks. By integrating inter-satellite links (ISL) for intra-orbit model aggregation, the proposed algorithm significantly reduces the usage of low data rate and intermittent GSL. Our proposed method includes a ring all-reduce based intra-orbit aggregation mechanism, coupled with a network flow-based transmission scheme for global model aggregation, which enhances transmission efficiency. Theoretical convergence analysis is provided to characterize the algorithm performance. Extensive simulations show that our FEDMEGA algorithm outperforms existing satellite FEEL algorithms, exhibiting an approximate 30% improvement in convergence rate.
Unifying Qualitative and Quantitative Safety Verification of DNN-Controlled Systems
Apr 02, 2024The rapid advance of deep reinforcement learning techniques enables the oversight of safety-critical systems through the utilization of Deep Neural Networks (DNNs). This underscores the pressing need to promptly establish certified safety guarantees for such DNN-controlled systems. Most of the existing verification approaches rely on qualitative approaches, predominantly employing reachability analysis. However, qualitative verification proves inadequate for DNN-controlled systems as their behaviors exhibit stochastic tendencies when operating in open and adversarial environments. In this paper, we propose a novel framework for unifying both qualitative and quantitative safety verification problems of DNN-controlled systems. This is achieved by formulating the verification tasks as the synthesis of valid neural barrier certificates (NBCs). Initially, the framework seeks to establish almost-sure safety guarantees through qualitative verification. In cases where qualitative verification fails, our quantitative verification method is invoked, yielding precise lower and upper bounds on probabilistic safety across both infinite and finite time horizons. To facilitate the synthesis of NBCs, we introduce their $k$-inductive variants. We also devise a simulation-guided approach for training NBCs, aiming to achieve tightness in computing precise certified lower and upper bounds. We prototype our approach into a tool called $\textsf{UniQQ}$ and showcase its efficacy on four classic DNN-controlled systems.
Class-Incremental Few-Shot Event Detection
Apr 02, 2024Event detection is one of the fundamental tasks in information extraction and knowledge graph. However, a realistic event detection system often needs to deal with new event classes constantly. These new classes usually have only a few labeled instances as it is time-consuming and labor-intensive to annotate a large number of unlabeled instances. Therefore, this paper proposes a new task, called class-incremental few-shot event detection. Nevertheless, this task faces two problems, i.e., old knowledge forgetting and new class overfitting. To solve these problems, this paper further presents a novel knowledge distillation and prompt learning based method, called Prompt-KD. Specifically, to handle the forgetting problem about old knowledge, Prompt-KD develops an attention based multi-teacher knowledge distillation framework, where the ancestor teacher model pre-trained on base classes is reused in all learning sessions, and the father teacher model derives the current student model via adaptation. On the other hand, in order to cope with the few-shot learning scenario and alleviate the corresponding new class overfitting problem, Prompt-KD is also equipped with a prompt learning mechanism. Extensive experiments on two benchmark datasets, i.e., FewEvent and MAVEN, demonstrate the superior performance of Prompt-KD.
Super Non-singular Decompositions of Polynomials and their Application to Robustly Learning Low-degree PTFs
Mar 31, 2024We study the efficient learnability of low-degree polynomial threshold functions (PTFs) in the presence of a constant fraction of adversarial corruptions. Our main algorithmic result is a polynomial-time PAC learning algorithm for this concept class in the strong contamination model under the Gaussian distribution with error guarantee $O_{d, c}(\text{opt}^{1-c})$, for any desired constant $c>0$, where $\text{opt}$ is the fraction of corruptions. In the strong contamination model, an omniscient adversary can arbitrarily corrupt an $\text{opt}$-fraction of the data points and their labels. This model generalizes the malicious noise model and the adversarial label noise model. Prior to our work, known polynomial-time algorithms in this corruption model (or even in the weaker adversarial label noise model) achieved error $\tilde{O}_d(\text{opt}^{1/(d+1)})$, which deteriorates significantly as a function of the degree $d$. Our algorithm employs an iterative approach inspired by localization techniques previously used in the context of learning linear threshold functions. Specifically, we use a robust perceptron algorithm to compute a good partial classifier and then iterate on the unclassified points. In order to achieve this, we need to take a set defined by a number of polynomial inequalities and partition it into several well-behaved subsets. To this end, we develop new polynomial decomposition techniques that may be of independent interest.
Just Shift It: Test-Time Prototype Shifting for Zero-Shot Generalization with Vision-Language Models
Mar 19, 2024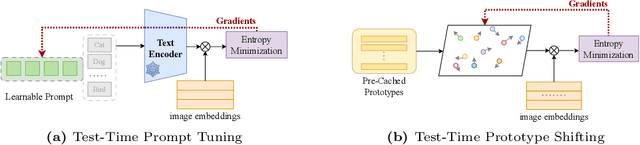
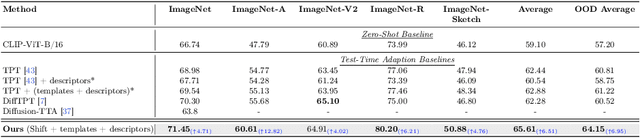
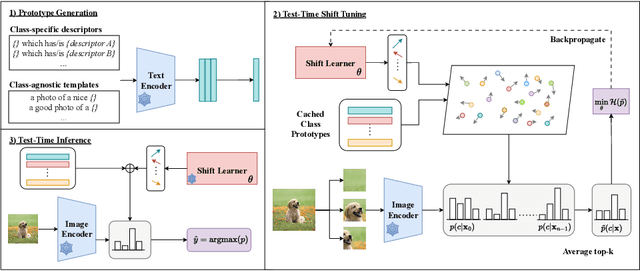

Advancements in vision-language models (VLMs) have propelled the field of computer vision, particularly in the zero-shot learning setting. Despite their promise, the effectiveness of these models often diminishes due to domain shifts in test environments. To address this, we introduce the Test-Time Prototype Shifting (TPS) framework, a pioneering approach designed to adapt VLMs to test datasets using unlabeled test inputs. Our method is based on the notion of modulating per-class prototypes in the shared embedding space. By pre-computing and caching prototypes generated with the pre-trained text encoder, TPS not only facilitates optimization-free prototype reuse for subsequent predictions but also enables seamless integration with current advancements in prompt engineering. At test-time, TPS dynamically learns shift vectors for each prototype based solely on the given test sample, effectively bridging the domain gap and enhancing classification accuracy. A notable aspect of our framework is its significantly reduced memory and computational demands when compared to conventional text-prompt tuning methods. Extensive evaluations across 15 datasets involving natural distribution shifts and cross-dataset generalization demonstrate TPS's superior performance, achieving state-of-the-art results while reducing resource requirements.