 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMENTO: Teaching LLMs to Manage Their Own Context
Apr 10, 2026Reasoning models think in long, unstructured streams with no mechanism for compressing or organizing their own intermediate state. We introduce MEMENTO: a method that teaches models to segment reasoning into blocks, compress each block into a memento, i.e., a dense state summary, and reason forward by attending only to mementos, reducing context, KV cache, and compute. To train MEMENTO models, we release OpenMementos, a public dataset of 228K reasoning traces derived from OpenThoughts-v3, segmented and annotated with intermediate summaries. We show that a two-stage SFT recipe on OpenMementos is effective across different model families (Qwen3, Phi-4, Olmo 3) and scales (8B--32B parameters). Trained models maintain strong accuracy on math, science, and coding benchmarks while achieving ${\sim}2.5\times$ peak KV cache reduction. We extend vLLM to support our inference method, achieving ${\sim}1.75\times$ throughput improvement while also enabling us to perform RL and further improve accuracy. Finally, we identify a dual information stream: information from each reasoning block is carried both by the memento text and by the corresponding KV states, which retain implicit information from the original block. Removing this channel drops accuracy by 15\,pp on AIME24.
Wait, Wait, Wait... Why Do Reasoning Models Loop?
Dec 15, 2025Reasoning models (e.g., DeepSeek-R1) generate long chains of thought to solve harder problems, but they often loop, repeating the same text at low temperatures or with greedy decoding. We study why this happens and what role temperature plays. With open reasoning models, we find that looping is common at low temperature. Larger models tend to loop less, and distilled students loop significantly even when their teachers rarely do. This points to mismatches between the training distribution and the learned model, which we refer to as errors in learning, as a key cause. To understand how such errors cause loops, we introduce a synthetic graph reasoning task and demonstrate two mechanisms. First, risk aversion caused by hardness of learning: when the correct progress-making action is hard to learn but an easy cyclic action is available, the model puts relatively more probability on the cyclic action and gets stuck. Second, even when there is no hardness, Transformers show an inductive bias toward temporally correlated errors, so the same few actions keep being chosen and loops appear. Higher temperature reduces looping by promoting exploration, but it does not fix the errors in learning, so generations remain much longer than necessary at high temperature; in this sense, temperature is a stopgap rather than a holistic solution. We end with a discussion of training-time interventions aimed at directly reducing errors in learning.
Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions
Feb 10, 2025In recent years, masked diffusion models (MDMs) have emerged as a promising alternative approach for generative modeling over discrete domains. Compared to autoregressive models (ARMs), MDMs trade off complexity at training time with flexibility at inference time. At training time, they must learn to solve an exponentially large number of infilling problems, but at inference time, they can decode tokens in essentially arbitrary order. In this work, we closely examine these two competing effects. On the training front, we theoretically and empirically demonstrate that MDMs indeed train on computationally intractable subproblems compared to their autoregressive counterparts. On the inference front, we show that a suitable strategy for adaptively choosing the token decoding order significantly enhances the capabilities of MDMs, allowing them to sidestep hard subproblems. On logic puzzles like Sudoku, we show that adaptive inference can boost solving accuracy in pretrained MDMs from $<7$% to $\approx 90$%, even outperforming ARMs with $7\times$ as many parameters and that were explicitly trained via teacher forcing to learn the right order of decoding.
Smoothed Analysis for Learning Concepts with Low Intrinsic Dimension
Jul 01, 2024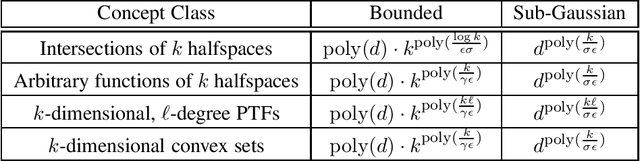
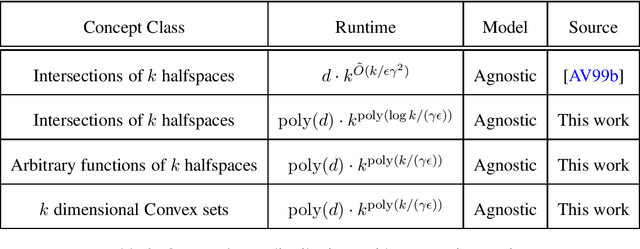

In traditional models of supervised learning, the goal of a learner -- given examples from an arbitrary joint distribution on $\mathbb{R}^d \times \{\pm 1\}$ -- is to output a hypothesis that is competitive (to within $\epsilon$) of the best fitting concept from some class. In order to escape strong hardness results for learning even simple concept classes, we introduce a smoothed-analysis framework that requires a learner to compete only with the best classifier that is robust to small random Gaussian perturbation. This subtle change allows us to give a wide array of learning results for any concept that (1) depends on a low-dimensional subspace (aka multi-index model) and (2) has a bounded Gaussian surface area. This class includes functions of halfspaces and (low-dimensional) convex sets, cases that are only known to be learnable in non-smoothed settings with respect to highly structured distributions such as Gaussians. Surprisingly, our analysis also yields new results for traditional non-smoothed frameworks such as learning with margin. In particular, we obtain the first algorithm for agnostically learning intersections of $k$-halfspaces in time $k^{poly(\frac{\log k}{\epsilon \gamma}) }$ where $\gamma$ is the margin parameter. Before our work, the best-known runtime was exponential in $k$ (Arriaga and Vempala, 1999).
Efficient Discrepancy Testing for Learning with Distribution Shift
Jun 13, 2024



A fundamental notion of distance between train and test distributions from the field of domain adaptation is discrepancy distance. While in general hard to compute, here we provide the first set of provably efficient algorithms for testing localized discrepancy distance, where discrepancy is computed with respect to a fixed output classifier. These results imply a broad set of new, efficient learning algorithms in the recently introduced model of Testable Learning with Distribution Shift (TDS learning) due to Klivans et al. (2023). Our approach generalizes and improves all prior work on TDS learning: (1) we obtain universal learners that succeed simultaneously for large classes of test distributions, (2) achieve near-optimal error rates, and (3) give exponential improvements for constant depth circuits. Our methods further extend to semi-parametric settings and imply the first positive results for low-dimensional convex sets. Additionally, we separate learning and testing phases and obtain algorithms that run in fully polynomial time at test time.
Online Learning of Halfspaces with Massart Noise
May 21, 2024We study the task of online learning in the presence of Massart noise. Instead of assuming that the online adversary chooses an arbitrary sequence of labels, we assume that the context $\mathbf{x}$ is selected adversarially but the label $y$ presented to the learner disagrees with the ground-truth label of $\mathbf{x}$ with unknown probability at most $\eta$. We study the fundamental class of $\gamma$-margin linear classifiers and present a computationally efficient algorithm that achieves mistake bound $\eta T + o(T)$. Our mistake bound is qualitatively tight for efficient algorithms: it is known that even in the offline setting achieving classification error better than $\eta$ requires super-polynomial time in the SQ model. We extend our online learning model to a $k$-arm contextual bandit setting where the rewards -- instead of satisfying commonly used realizability assumptions -- are consistent (in expectation) with some linear ranking function with weight vector $\mathbf{w}^\ast$. Given a list of contexts $\mathbf{x}_1,\ldots \mathbf{x}_k$, if $\mathbf{w}^*\cdot \mathbf{x}_i > \mathbf{w}^* \cdot \mathbf{x}_j$, the expected reward of action $i$ must be larger than that of $j$ by at least $\Delta$. We use our Massart online learner to design an efficient bandit algorithm that obtains expected reward at least $(1-1/k)~ \Delta T - o(T)$ bigger than choosing a random action at every round.
Active Learning with Simple Questions
May 13, 2024

We consider an active learning setting where a learner is presented with a pool S of n unlabeled examples belonging to a domain X and asks queries to find the underlying labeling that agrees with a target concept h^* \in H. In contrast to traditional active learning that queries a single example for its label, we study more general region queries that allow the learner to pick a subset of the domain T \subset X and a target label y and ask a labeler whether h^*(x) = y for every example in the set T \cap S. Such more powerful queries allow us to bypass the limitations of traditional active learning and use significantly fewer rounds of interactions to learn but can potentially lead to a significantly more complex query language. Our main contribution is quantifying the trade-off between the number of queries and the complexity of the query language used by the learner. We measure the complexity of the region queries via the VC dimension of the family of regions. We show that given any hypothesis class H with VC dimension d, one can design a region query family Q with VC dimension O(d) such that for every set of n examples S \subset X and every h^* \in H, a learner can submit O(d log n) queries from Q to a labeler and perfectly label S. We show a matching lower bound by designing a hypothesis class H with VC dimension d and a dataset S \subset X of size n such that any learning algorithm using any query class with VC dimension O(d) must make poly(n) queries to label S perfectly. Finally, we focus on well-studied hypothesis classes including unions of intervals, high-dimensional boxes, and d-dimensional halfspaces, and obtain stronger results. In particular, we design learning algorithms that (i) are computationally efficient and (ii) work even when the queries are not answered based on the learner's pool of examples S but on some unknown superset L of S
Learning general Gaussian mixtures with efficient score matching
Apr 29, 2024
We study the problem of learning mixtures of $k$ Gaussians in $d$ dimensions. We make no separation assumptions on the underlying mixture components: we only require that the covariance matrices have bounded condition number and that the means and covariances lie in a ball of bounded radius. We give an algorithm that draws $d^{\mathrm{poly}(k/\varepsilon)}$ samples from the target mixture, runs in sample-polynomial time, and constructs a sampler whose output distribution is $\varepsilon$-far from the unknown mixture in total variation. Prior works for this problem either (i) required exponential runtime in the dimension $d$, (ii) placed strong assumptions on the instance (e.g., spherical covariances or clusterability), or (iii) had doubly exponential dependence on the number of components $k$. Our approach departs from commonly used techniques for this problem like the method of moments. Instead, we leverage a recently developed reduction, based on diffusion models, from distribution learning to a supervised learning task called score matching. We give an algorithm for the latter by proving a structural result showing that the score function of a Gaussian mixture can be approximated by a piecewise-polynomial function, and there is an efficient algorithm for finding it. To our knowledge, this is the first example of diffusion models achieving a state-of-the-art theoretical guarantee for an unsupervised learning task.
Super Non-singular Decompositions of Polynomials and their Application to Robustly Learning Low-degree PTFs
Mar 31, 2024
We study the efficient learnability of low-degree polynomial threshold functions (PTFs) in the presence of a constant fraction of adversarial corruptions. Our main algorithmic result is a polynomial-time PAC learning algorithm for this concept class in the strong contamination model under the Gaussian distribution with error guarantee $O_{d, c}(\text{opt}^{1-c})$, for any desired constant $c>0$, where $\text{opt}$ is the fraction of corruptions. In the strong contamination model, an omniscient adversary can arbitrarily corrupt an $\text{opt}$-fraction of the data points and their labels. This model generalizes the malicious noise model and the adversarial label noise model. Prior to our work, known polynomial-time algorithms in this corruption model (or even in the weaker adversarial label noise model) achieved error $\tilde{O}_d(\text{opt}^{1/(d+1)})$, which deteriorates significantly as a function of the degree $d$. Our algorithm employs an iterative approach inspired by localization techniques previously used in the context of learning linear threshold functions. Specifically, we use a robust perceptron algorithm to compute a good partial classifier and then iterate on the unclassified points. In order to achieve this, we need to take a set defined by a number of polynomial inequalities and partition it into several well-behaved subsets. To this end, we develop new polynomial decomposition techniques that may be of independent interest.
Agnostically Learning Multi-index Models with Queries
Dec 27, 2023


We study the power of query access for the task of agnostic learning under the Gaussian distribution. In the agnostic model, no assumptions are made on the labels and the goal is to compute a hypothesis that is competitive with the {\em best-fit} function in a known class, i.e., it achieves error $\mathrm{opt}+\epsilon$, where $\mathrm{opt}$ is the error of the best function in the class. We focus on a general family of Multi-Index Models (MIMs), which are $d$-variate functions that depend only on few relevant directions, i.e., have the form $g(\mathbf{W} \mathbf{x})$ for an unknown link function $g$ and a $k \times d$ matrix $\mathbf{W}$. Multi-index models cover a wide range of commonly studied function classes, including constant-depth neural networks with ReLU activations, and intersections of halfspaces. Our main result shows that query access gives significant runtime improvements over random examples for agnostically learning MIMs. Under standard regularity assumptions for the link function (namely, bounded variation or surface area), we give an agnostic query learner for MIMs with complexity $O(k)^{\mathrm{poly}(1/\epsilon)} \; \mathrm{poly}(d) $. In contrast, algorithms that rely only on random examples inherently require $d^{\mathrm{poly}(1/\epsilon)}$ samples and runtime, even for the basic problem of agnostically learning a single ReLU or a halfspace. Our algorithmic result establishes a strong computational separation between the agnostic PAC and the agnostic PAC+Query models under the Gaussian distribution. Prior to our work, no such separation was known -- even for the special case of agnostically learning a single halfspace, for which it was an open problem first posed by Feldman. Our results are enabled by a general dimension-reduction technique that leverages query access to estimate gradients of (a smoothed version of) the underlying label function.