 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Weakly-Supervised Semantic Segmentation with Image-Level Labels: from Traditional Models to Foundation Models
Oct 19, 2023
The rapid development of deep learning has driven significant progress in the field of image semantic segmentation - a fundamental task in computer vision. Semantic segmentation algorithms often depend on the availability of pixel-level labels (i.e., masks of objects), which are expensive, time-consuming, and labor-intensive. Weakly-supervised semantic segmentation (WSSS) is an effective solution to avoid such labeling. It utilizes only partial or incomplete annotations and provides a cost-effective alternative to fully-supervised semantic segmentation. In this paper, we focus on the WSSS with image-level labels, which is the most challenging form of WSSS. Our work has two parts. First, we conduct a comprehensive survey on traditional methods, primarily focusing on those presented at premier research conferences. We categorize them into four groups based on where their methods operate: pixel-wise, image-wise, cross-image, and external data. Second, we investigate the applicability of visual foundation models, such as the Segment Anything Model (SAM), in the context of WSSS. We scrutinize SAM in two intriguing scenarios: text prompting and zero-shot learning. We provide insights into the potential and challenges associated with deploying visual foundational models for WSSS, facilitating future developments in this exciting research area.
Affine Frequency Division Multiplexing With Index Modulation
Oct 19, 2023Affine frequency division multiplexing (AFDM) is a new multicarrier technique based on chirp signals tailored for high-mobility communications, which can achieve full diversity. In this paper, we propose an index modulation (IM) scheme based on the framework of AFDM systems, named AFDM-IM. In the proposed AFDM-IM scheme, the information bits are carried by the activation state of the subsymbols in discrete affine Fourier (DAF) domain in addition to the conventional constellation symbols. To efficiently perform IM, we divide the subsymbols in DAF domain into several groups and consider both the localized and distributed strategies. An asymptotically tight upper bound on the average bit error rate (BER) of the maximum-likelihood detection in the existence of channel estimation errors is derived in closed-form. Computer simulations are carried out to evaluate the performance of the proposed AFDM-IM scheme, whose results corroborate its superiority over the benchmark schemes in the linear time-varying channels. We also evaluate the BER performance of the index and modulated bits for the AFDM-IM scheme with and without satisfying the full diversity condition of AFDM. The results show that the index bits have a stronger diversity protection than the modulated bits even when the full diversity condition of AFDM is not satisfied.
Jaeger: A Concatenation-Based Multi-Transformer VQA Model
Oct 19, 2023Document-based Visual Question Answering poses a challenging task between linguistic sense disambiguation and fine-grained multimodal retrieval. Although there has been encouraging progress in document-based question answering due to the utilization of large language and open-world prior models\cite{1}, several challenges persist, including prolonged response times, extended inference durations, and imprecision in matching. In order to overcome these challenges, we propose Jaegar, a concatenation-based multi-transformer VQA model. To derive question features, we leverage the exceptional capabilities of RoBERTa large\cite{2} and GPT2-xl\cite{3} as feature extractors. Subsequently, we subject the outputs from both models to a concatenation process. This operation allows the model to consider information from diverse sources concurrently, strengthening its representational capability. By leveraging pre-trained models for feature extraction, our approach has the potential to amplify the performance of these models through concatenation. After concatenation, we apply dimensionality reduction to the output features, reducing the model's computational effectiveness and inference time. Empirical results demonstrate that our proposed model achieves competitive performance on Task C of the PDF-VQA Dataset. If the user adds any new data, they should make sure to style it as per the instructions provided in previous sections.
CAT: Closed-loop Adversarial Training for Safe End-to-End Driving
Oct 19, 2023Driving safety is a top priority for autonomous vehicles. Orthogonal to prior work handling accident-prone traffic events by algorithm designs at the policy level, we investigate a Closed-loop Adversarial Training (CAT) framework for safe end-to-end driving in this paper through the lens of environment augmentation. CAT aims to continuously improve the safety of driving agents by training the agent on safety-critical scenarios that are dynamically generated over time. A novel resampling technique is developed to turn log-replay real-world driving scenarios into safety-critical ones via probabilistic factorization, where the adversarial traffic generation is modeled as the multiplication of standard motion prediction sub-problems. Consequently, CAT can launch more efficient physical attacks compared to existing safety-critical scenario generation methods and yields a significantly less computational cost in the iterative learning pipeline. We incorporate CAT into the MetaDrive simulator and validate our approach on hundreds of driving scenarios imported from real-world driving datasets. Experimental results demonstrate that CAT can effectively generate adversarial scenarios countering the agent being trained. After training, the agent can achieve superior driving safety in both log-replay and safety-critical traffic scenarios on the held-out test set. Code and data are available at https://metadriverse.github.io/cat.
DrugCLIP: Contrastive Protein-Molecule Representation Learning for Virtual Screening
Oct 10, 2023Virtual screening, which identifies potential drugs from vast compound databases to bind with a particular protein pocket, is a critical step in AI-assisted drug discovery. Traditional docking methods are highly time-consuming, and can only work with a restricted search library in real-life applications. Recent supervised learning approaches using scoring functions for binding-affinity prediction, although promising, have not yet surpassed docking methods due to their strong dependency on limited data with reliable binding-affinity labels. In this paper, we propose a novel contrastive learning framework, DrugCLIP, by reformulating virtual screening as a dense retrieval task and employing contrastive learning to align representations of binding protein pockets and molecules from a large quantity of pairwise data without explicit binding-affinity scores. We also introduce a biological-knowledge inspired data augmentation strategy to learn better protein-molecule representations. Extensive experiments show that DrugCLIP significantly outperforms traditional docking and supervised learning methods on diverse virtual screening benchmarks with highly reduced computation time, especially in zero-shot setting.
Detection and prediction of clopidogrel treatment failures using longitudinal structured electronic health records
Oct 12, 2023We propose machine learning algorithms to automatically detect and predict clopidogrel treatment failure using longitudinal structured electronic health records (EHR). By drawing analogies between natural language and structured EHR, we introduce various machine learning algorithms used in natural language processing (NLP) applications to build models for treatment failure detection and prediction. In this regard, we generated a cohort of patients with clopidogrel prescriptions from UK Biobank and annotated if the patients had treatment failure events within one year of the first clopidogrel prescription; out of 502,527 patients, 1,824 patients were identified as treatment failure cases, and 6,859 patients were considered as control cases. From the dataset, we gathered diagnoses, prescriptions, and procedure records together per patient and organized them into visits with the same date to build models. The models were built for two different tasks, i.e., detection and prediction, and the experimental results showed that time series models outperform bag-of-words approaches in both tasks. In particular, a Transformer-based model, namely BERT, could reach 0.928 AUC in detection tasks and 0.729 AUC in prediction tasks. BERT also showed competence over other time series models when there is not enough training data, because it leverages the pre-training procedure using large unlabeled data.
Predicting Financial Market Trends using Time Series Analysis and Natural Language Processing
Aug 31, 2023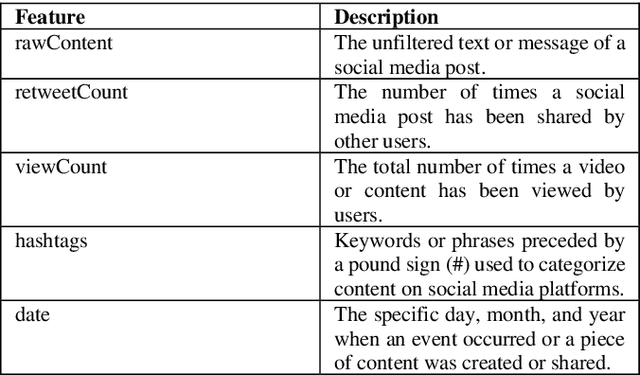
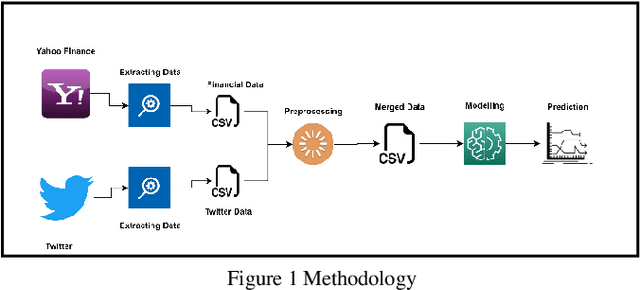
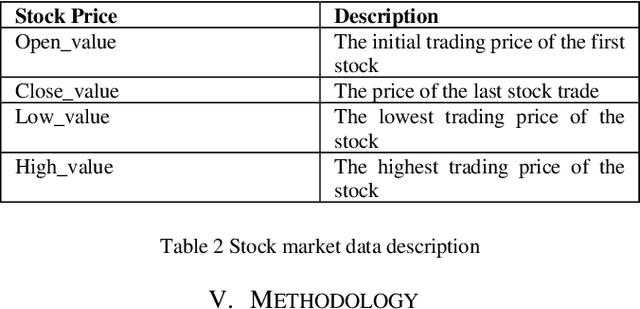
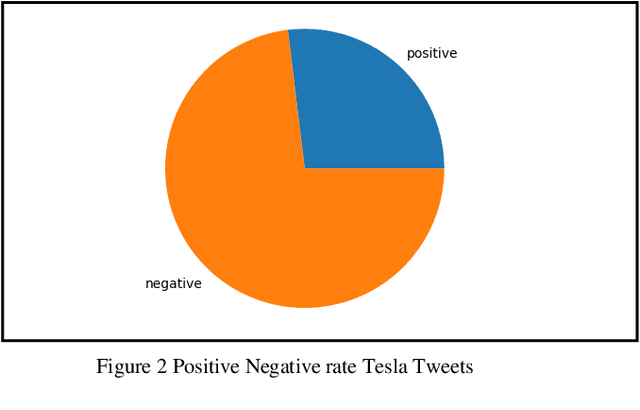
Forecasting financial market trends through time series analysis and natural language processing poses a complex and demanding undertaking, owing to the numerous variables that can influence stock prices. These variables encompass a spectrum of economic and political occurrences, as well as prevailing public attitudes. Recent research has indicated that the expression of public sentiments on social media platforms such as Twitter may have a noteworthy impact on the determination of stock prices. The objective of this study was to assess the viability of Twitter sentiments as a tool for predicting stock prices of major corporations such as Tesla, Apple. Our study has revealed a robust association between the emotions conveyed in tweets and fluctuations in stock prices. Our findings indicate that positivity, negativity, and subjectivity are the primary determinants of fluctuations in stock prices. The data was analyzed utilizing the Long-Short Term Memory neural network (LSTM) model, which is currently recognized as the leading methodology for predicting stock prices by incorporating Twitter sentiments and historical stock prices data. The models utilized in our study demonstrated a high degree of reliability and yielded precise outcomes for the designated corporations. In summary, this research emphasizes the significance of incorporating public opinions into the prediction of stock prices. The application of Time Series Analysis and Natural Language Processing methodologies can yield significant scientific findings regarding financial market patterns, thereby facilitating informed decision-making among investors. The results of our study indicate that the utilization of Twitter sentiments can serve as a potent instrument for forecasting stock prices, and ought to be factored in when formulating investment strategies.
Fast Multipole Attention: A Divide-and-Conquer Attention Mechanism for Long Sequences
Oct 21, 2023Transformer-based models have achieved state-of-the-art performance in many areas. However, the quadratic complexity of self-attention with respect to the input length hinders the applicability of Transformer-based models to long sequences. To address this, we present Fast Multipole Attention, a new attention mechanism that uses a divide-and-conquer strategy to reduce the time and memory complexity of attention for sequences of length $n$ from $\mathcal{O}(n^2)$ to $\mathcal{O}(n \log n)$ or $O(n)$, while retaining a global receptive field. The hierarchical approach groups queries, keys, and values into $\mathcal{O}( \log n)$ levels of resolution, where groups at greater distances are increasingly larger in size and the weights to compute group quantities are learned. As such, the interaction between tokens far from each other is considered in lower resolution in an efficient hierarchical manner. The overall complexity of Fast Multipole Attention is $\mathcal{O}(n)$ or $\mathcal{O}(n \log n)$, depending on whether the queries are down-sampled or not. This multi-level divide-and-conquer strategy is inspired by fast summation methods from $n$-body physics and the Fast Multipole Method. We perform evaluation on autoregressive and bidirectional language modeling tasks and compare our Fast Multipole Attention model with other efficient attention variants on medium-size datasets. We find empirically that the Fast Multipole Transformer performs much better than other efficient transformers in terms of memory size and accuracy. The Fast Multipole Attention mechanism has the potential to empower large language models with much greater sequence lengths, taking the full context into account in an efficient, naturally hierarchical manner during training and when generating long sequences.
MOELoRA: An MOE-based Parameter Efficient Fine-Tuning Method for Multi-task Medical Applications
Oct 21, 2023The recent surge in the field of Large Language Models (LLMs) has gained significant attention in numerous domains. In order to tailor an LLM to a specific domain such as a web-based healthcare system, fine-tuning with domain knowledge is necessary. However, two issues arise during fine-tuning LLMs for medical applications. The first is the problem of task variety, where there are numerous distinct tasks in real-world medical scenarios. This diversity often results in suboptimal fine-tuning due to data imbalance and seesawing problems. Additionally, the high cost of fine-tuning can be prohibitive, impeding the application of LLMs. The large number of parameters in LLMs results in enormous time and computational consumption during fine-tuning, which is difficult to justify. To address these two issues simultaneously, we propose a novel parameter-efficient fine-tuning framework for multi-task medical applications called MOELoRA. The framework aims to capitalize on the benefits of both MOE for multi-task learning and LoRA for parameter-efficient fine-tuning. To unify MOE and LoRA, we devise multiple experts as the trainable parameters, where each expert consists of a pair of low-rank matrices to maintain a small number of trainable parameters. Additionally, we propose a task-motivated gate function for all MOELoRA layers that can regulate the contributions of each expert and generate distinct parameters for various tasks. To validate the effectiveness and practicality of the proposed method, we conducted comprehensive experiments on a public multi-task Chinese medical dataset. The experimental results demonstrate that MOELoRA outperforms existing parameter-efficient fine-tuning methods. The implementation is available online for convenient reproduction of our experiments.
FLTracer: Accurate Poisoning Attack Provenance in Federated Learning
Oct 20, 2023
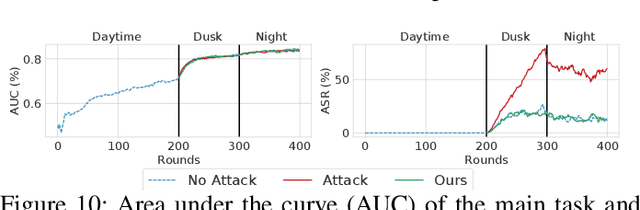
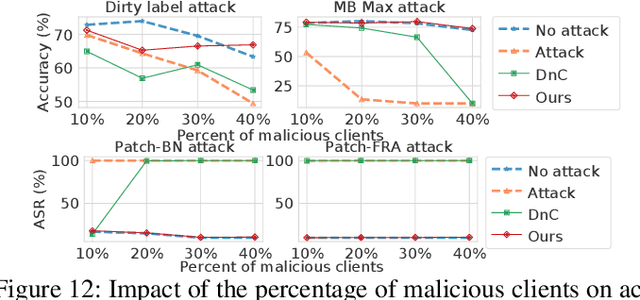
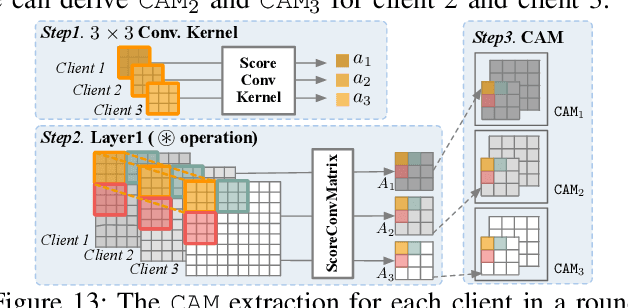
Federated Learning (FL) is a promising distributed learning approach that enables multiple clients to collaboratively train a shared global model. However, recent studies show that FL is vulnerable to various poisoning attacks, which can degrade the performance of global models or introduce backdoors into them. In this paper, we first conduct a comprehensive study on prior FL attacks and detection methods. The results show that all existing detection methods are only effective against limited and specific attacks. Most detection methods suffer from high false positives, which lead to significant performance degradation, especially in not independent and identically distributed (non-IID) settings. To address these issues, we propose FLTracer, the first FL attack provenance framework to accurately detect various attacks and trace the attack time, objective, type, and poisoned location of updates. Different from existing methodologies that rely solely on cross-client anomaly detection, we propose a Kalman filter-based cross-round detection to identify adversaries by seeking the behavior changes before and after the attack. Thus, this makes it resilient to data heterogeneity and is effective even in non-IID settings. To further improve the accuracy of our detection method, we employ four novel features and capture their anomalies with the joint decisions. Extensive evaluations show that FLTracer achieves an average true positive rate of over $96.88\%$ at an average false positive rate of less than $2.67\%$, significantly outperforming SOTA detection methods. \footnote{Code is available at \url{https://github.com/Eyr3/FLTracer}.}