 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
Phenotyping OSA: a time series analysis using fuzzy clustering and persistent homology
Apr 27, 2021
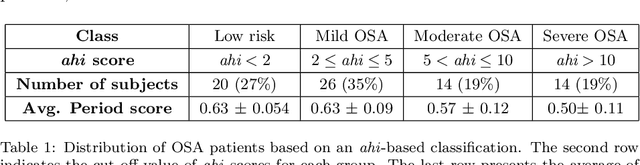
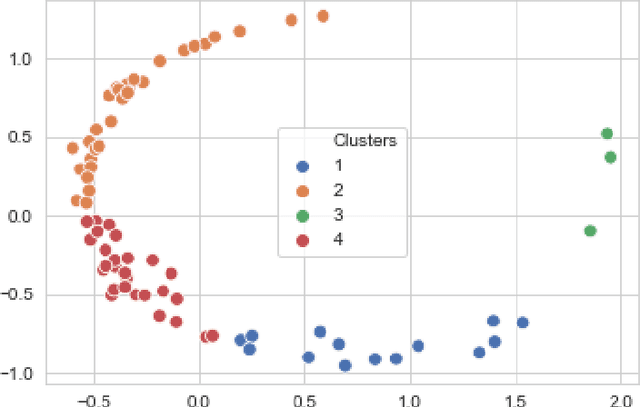
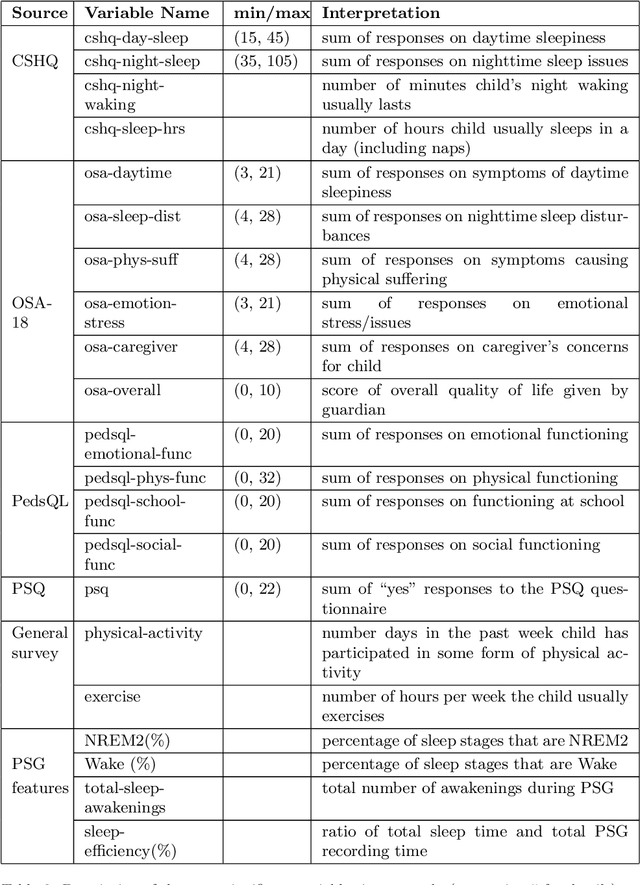
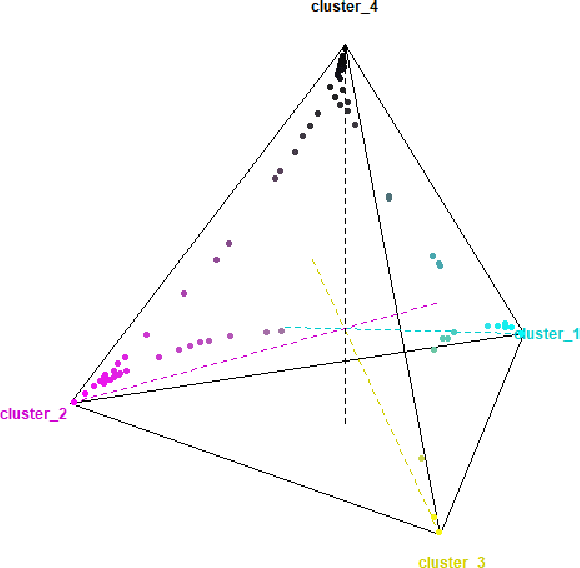
Sleep apnea is a disorder that has serious consequences for the pediatric population. There has been recent concern that traditional diagnosis of the disorder using the apnea-hypopnea index may be ineffective in capturing its multi-faceted outcomes. In this work, we take a first step in addressing this issue by phenotyping patients using a clustering analysis of airflow time series. This is approached in three ways: using feature-based fuzzy clustering in the time and frequency domains, and using persistent homology to study the signal from a topological perspective. The fuzzy clusters are analyzed in a novel manner using a Dirichlet regression analysis, while the topological approach leverages Takens embedding theorem to study the periodicity properties of the signals.
A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models
Mar 18, 2023
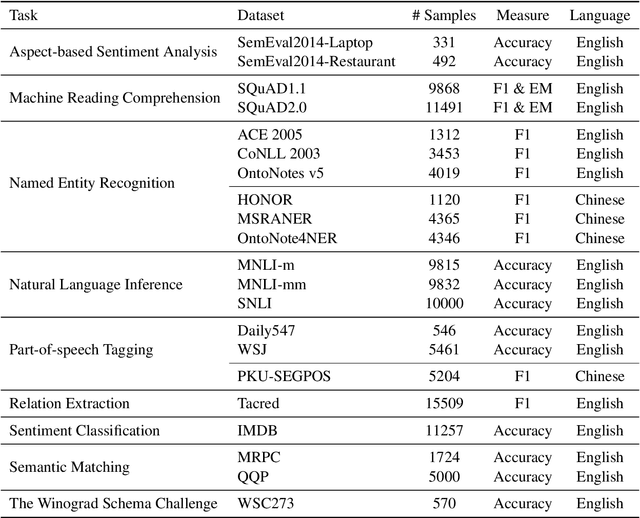
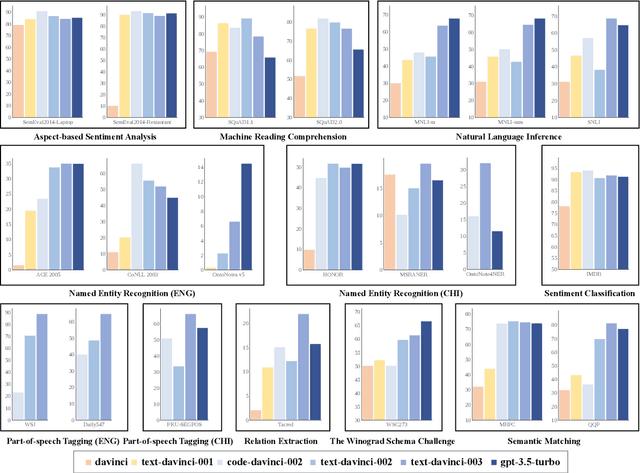
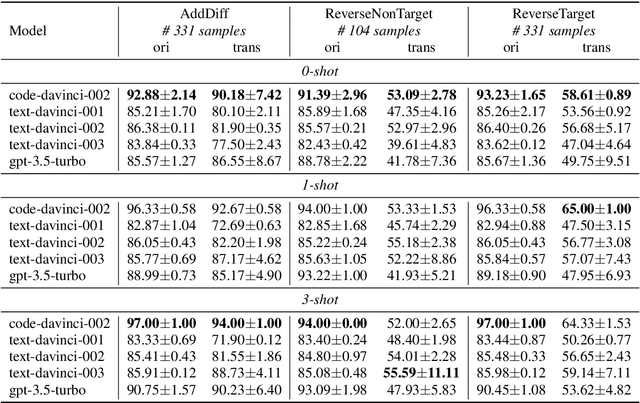
GPT series models, such as GPT-3, CodeX, InstructGPT, ChatGPT, and so on, have gained considerable attention due to their exceptional natural language processing capabilities. However, despite the abundance of research on the difference in capabilities between GPT series models and fine-tuned models, there has been limited attention given to the evolution of GPT series models' capabilities over time. To conduct a comprehensive analysis of the capabilities of GPT series models, we select six representative models, comprising two GPT-3 series models (i.e., davinci and text-davinci-001) and four GPT-3.5 series models (i.e., code-davinci-002, text-davinci-002, text-davinci-003, and gpt-3.5-turbo). We evaluate their performance on nine natural language understanding (NLU) tasks using 21 datasets. In particular, we compare the performance and robustness of different models for each task under zero-shot and few-shot scenarios. Our extensive experiments reveal that the overall ability of GPT series models on NLU tasks does not increase gradually as the models evolve, especially with the introduction of the RLHF training strategy. While this strategy enhances the models' ability to generate human-like responses, it also compromises their ability to solve some tasks. Furthermore, our findings indicate that there is still room for improvement in areas such as model robustness.
Universality and diversity in word patterns
Aug 23, 2022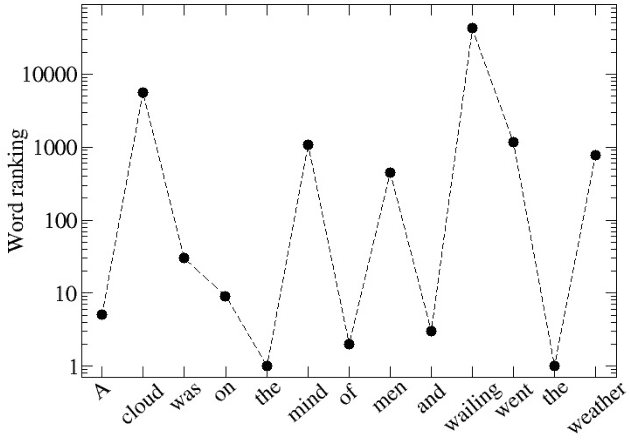
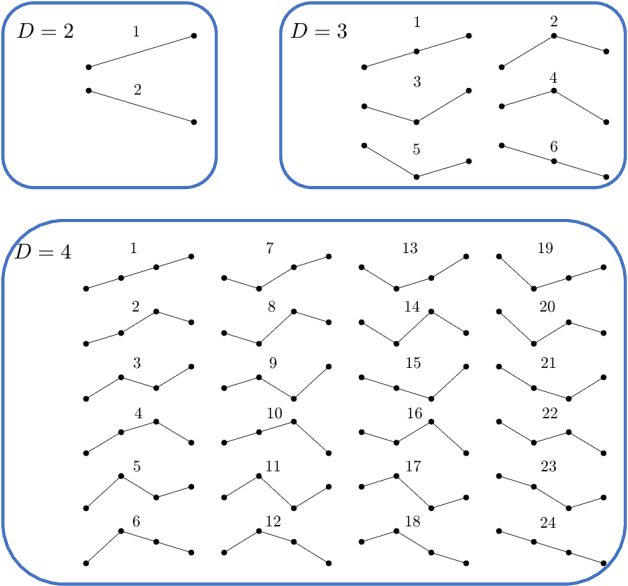
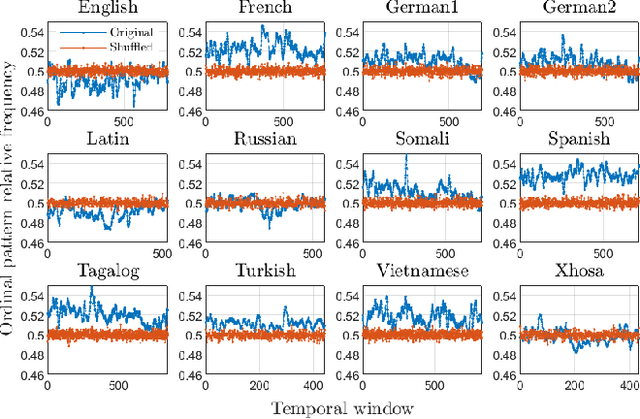
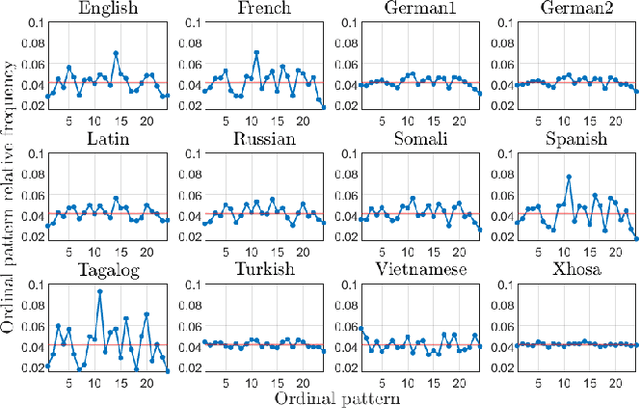
Words are fundamental linguistic units that connect thoughts and things through meaning. However, words do not appear independently in a text sequence. The existence of syntactic rules induce correlations among neighboring words. Further, words are not evenly distributed but approximately follow a power law since terms with a pure semantic content appear much less often than terms that specify grammar relations. Using an ordinal pattern approach, we present an analysis of lexical statistical connections for eleven major languages. We find that the diverse manners that languages utilize to express word relations give rise to unique pattern distributions. Remarkably, we find that these relations can be modeled with a Markov model of order 2 and that this result is universally valid for all the studied languages. Furthermore, fluctuations of the pattern distributions can allow us to determine the historical period when the text was written and its author. Taken together, these results emphasize the relevance of time series analysis and information-theoretic methods for the understanding of statistical correlations in natural languages.
Monitoring the risk of a tailings dam collapse through spectral analysis of satellite InSAR time-series data
Feb 03, 2023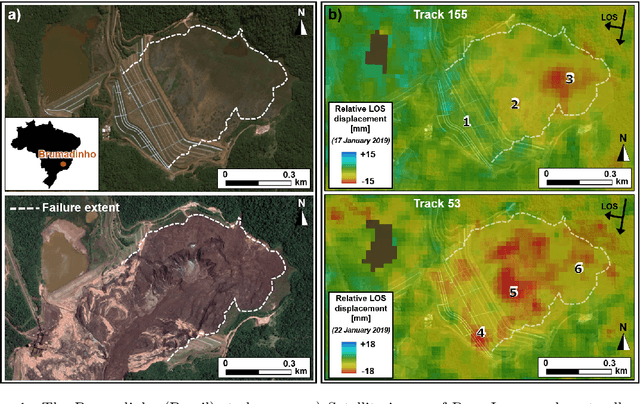
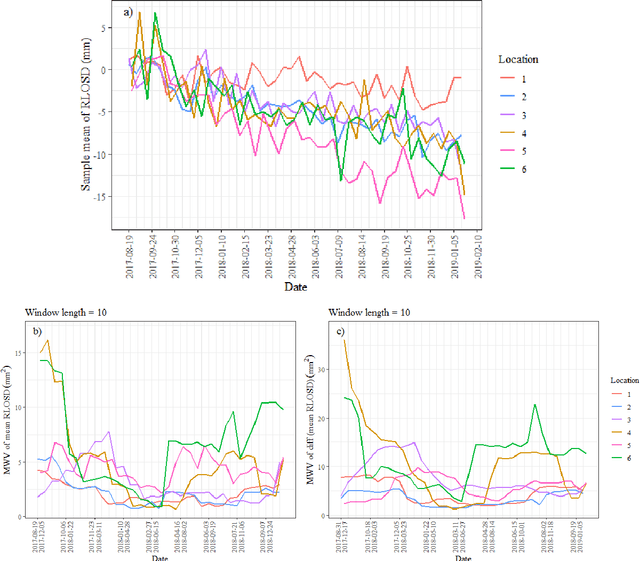
Slope failures possess destructive power that can cause significant damage to both life and infrastructure. Monitoring slopes prone to instabilities is therefore critical in mitigating the risk posed by their failure. The purpose of slope monitoring is to detect precursory signs of stability issues, such as changes in the rate of displacement with which a slope is deforming. This information can then be used to predict the timing or probability of an imminent failure in order to provide an early warning. In this study, a more objective, statistical-learning algorithm is proposed to detect and characterise the risk of a slope failure, based on spectral analysis of serially correlated displacement time series data. The algorithm is applied to satellite-based interferometric synthetic radar (InSAR) displacement time series data to retrospectively analyse the risk of the 2019 Brumadinho tailings dam collapse in Brazil. Two potential risk milestones are identified and signs of a definitive but emergent risk (27 February 2018 to 26 August 2018) and imminent risk of collapse of the tailings dam (27 June 2018 to 24 December 2018) are detected by the algorithm. Importantly, this precursory indication of risk of failure is detected as early as at least five months prior to the dam collapse on 25 January 2019. The results of this study demonstrate that the combination of spectral methods and second order statistical properties of InSAR displacement time series data can reveal signs of a transition into an unstable deformation regime, and that this algorithm can provide sufficient early warning that could help mitigate catastrophic slope failures.
EgPDE-Net: Building Continuous Neural Networks for Time Series Prediction with Exogenous Variables
Aug 03, 2022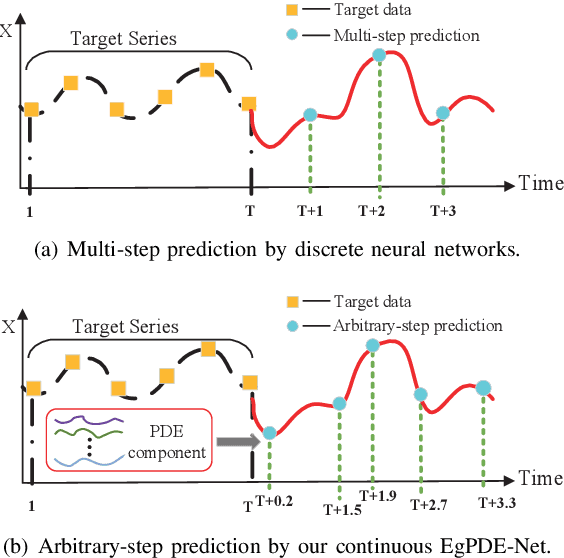
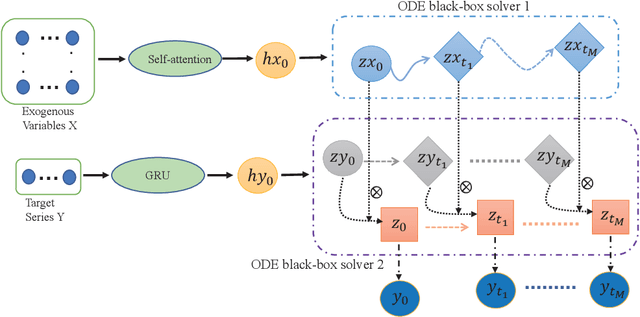
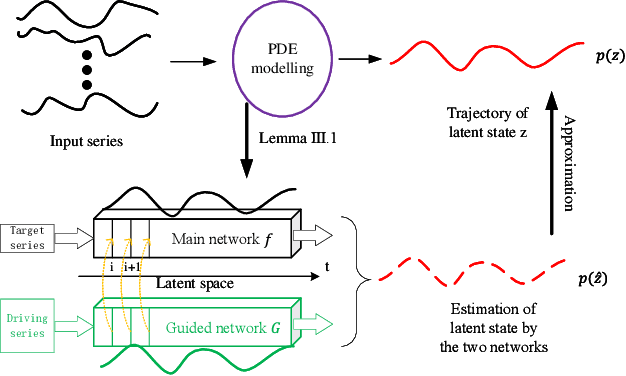
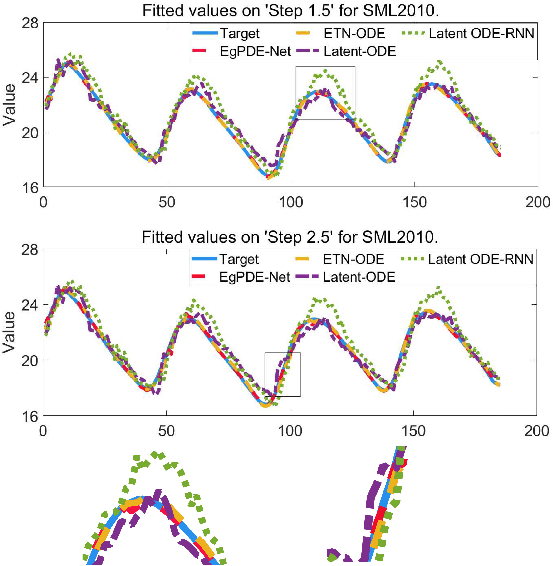
While exogenous variables have a major impact on performance improvement in time series analysis, inter-series correlation and time dependence among them are rarely considered in the present continuous methods. The dynamical systems of multivariate time series could be modelled with complex unknown partial differential equations (PDEs) which play a prominent role in many disciplines of science and engineering. In this paper, we propose a continuous-time model for arbitrary-step prediction to learn an unknown PDE system in multivariate time series whose governing equations are parameterised by self-attention and gated recurrent neural networks. The proposed model, \underline{E}xogenous-\underline{g}uided \underline{P}artial \underline{D}ifferential \underline{E}quation Network (EgPDE-Net), takes account of the relationships among the exogenous variables and their effects on the target series. Importantly, the model can be reduced into a regularised ordinary differential equation (ODE) problem with special designed regularisation guidance, which makes the PDE problem tractable to obtain numerical solutions and feasible to predict multiple future values of the target series at arbitrary time points. Extensive experiments demonstrate that our proposed model could achieve competitive accuracy over strong baselines: on average, it outperforms the best baseline by reducing $9.85\%$ on RMSE and $13.98\%$ on MAE for arbitrary-step prediction.
Estimating Treatment Effects from Irregular Time Series Observations with Hidden Confounders
Mar 04, 2023

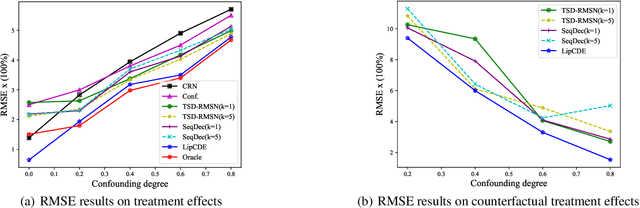

Causal analysis for time series data, in particular estimating individualized treatment effect (ITE), is a key task in many real-world applications, such as finance, retail, healthcare, etc. Real-world time series can include large-scale, irregular, and intermittent time series observations, raising significant challenges to existing work attempting to estimate treatment effects. Specifically, the existence of hidden confounders can lead to biased treatment estimates and complicate the causal inference process. In particular, anomaly hidden confounders which exceed the typical range can lead to high variance estimates. Moreover, in continuous time settings with irregular samples, it is challenging to directly handle the dynamics of causality. In this paper, we leverage recent advances in Lipschitz regularization and neural controlled differential equations (CDE) to develop an effective and scalable solution, namely LipCDE, to address the above challenges. LipCDE can directly model the dynamic causal relationships between historical data and outcomes with irregular samples by considering the boundary of hidden confounders given by Lipschitz-constrained neural networks. Furthermore, we conduct extensive experiments on both synthetic and real-world datasets to demonstrate the effectiveness and scalability of LipCDE.
In Search of Deep Learning Architectures for Load Forecasting: A Comparative Analysis and the Impact of the Covid-19 Pandemic on Model Performance
Feb 25, 2023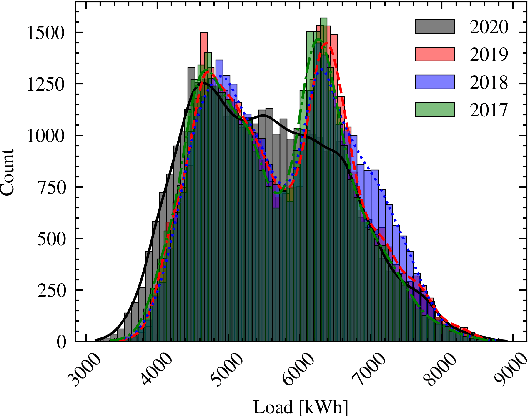
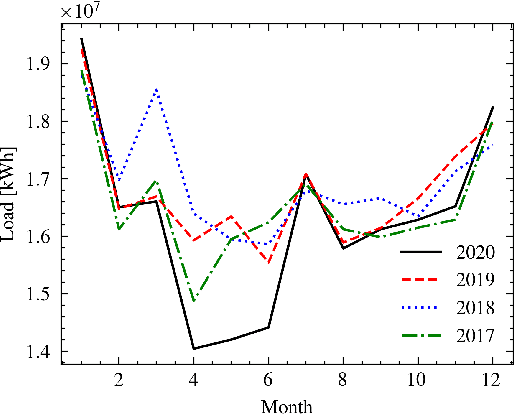
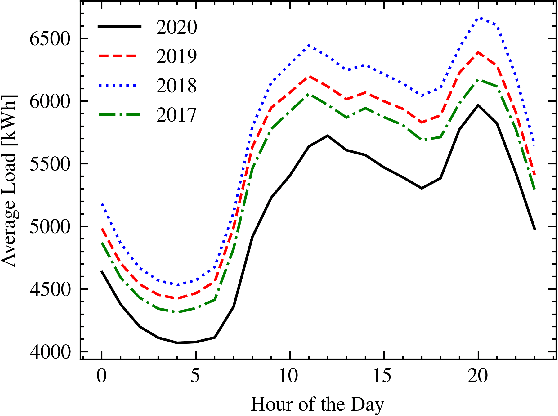
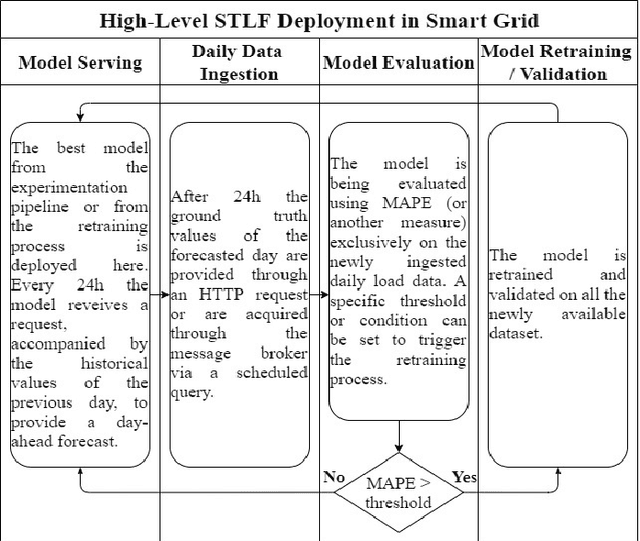
In power grids, short-term load forecasting (STLF) is crucial as it contributes to the optimization of their reliability, emissions, and costs, while it enables the participation of energy companies in the energy market. STLF is a challenging task, due to the complex demand of active and reactive power from multiple types of electrical loads and their dependence on numerous exogenous variables. Amongst them, special circumstances, such as the COVID-19 pandemic, can often be the reason behind distribution shifts of load series. This work conducts a comparative study of Deep Learning (DL) architectures, namely Neural Basis Expansion Analysis Time Series Forecasting (N-BEATS), Long Short-Term Memory (LSTM), and Temporal Convolutional Networks (TCN), with respect to forecasting accuracy and training sustainability, meanwhile examining their out-of-distribution generalization capabilities during the COVID-19 pandemic era. A Pattern Sequence Forecasting (PSF) model is used as baseline. The case study focuses on day-ahead forecasts for the Portuguese national 15-minute resolution net load time series. The results can be leveraged by energy companies and network operators (i) to reinforce their forecasting toolkit with state-of-the-art DL models; (ii) to become aware of the serious consequences of crisis events on model performance; (iii) as a high-level model evaluation, deployment, and sustainability guide within a smart grid context.
On the Use of Dimension Reduction or Signal Separation Methods for Nitrogen River Pollution Source Identification
Apr 27, 2022
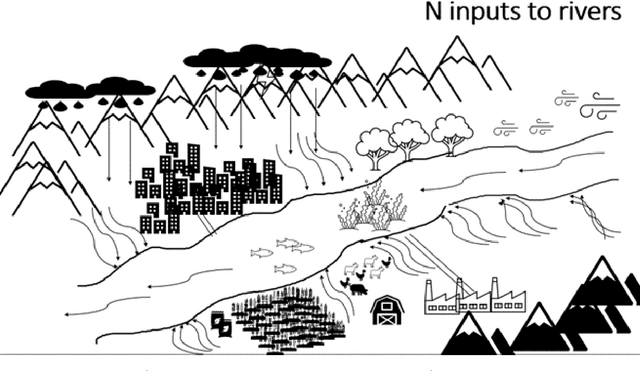
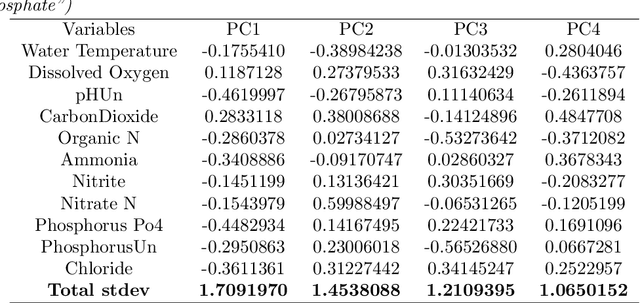
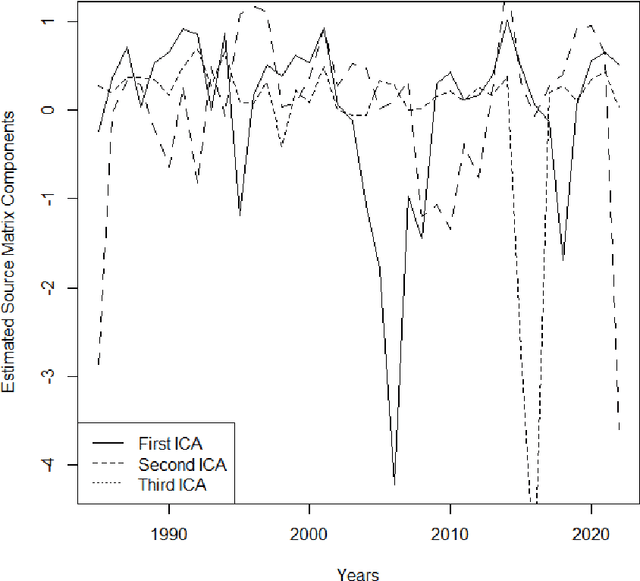
Identification of the current and expected future pollution sources to rivers is crucial for sound environmental management. For this purpose numerous approaches were proposed that can be clustered under physical based models, stable isotope analysis and mixing methods, mass balance methods, time series analysis, land cover analysis, and spatial statistics. Another extremely common method is Principal Component Analysis, as well as its modifications, such as Absolute Principal Component Score. they have been applied to the source identification problems for nitrogen entry to rivers. This manuscript is checking whether PCA can really be a powerful method to uncover nitrogen pollution sources considering its theoretical background and assumptions. Moreover, slightly similar techniques, Independent Component Analysis and Factor Analysis will also be considered.
Homological Time Series Analysis of Sensor Signals from Power Plants
Jun 03, 2021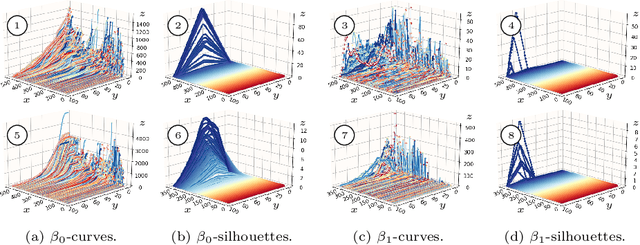
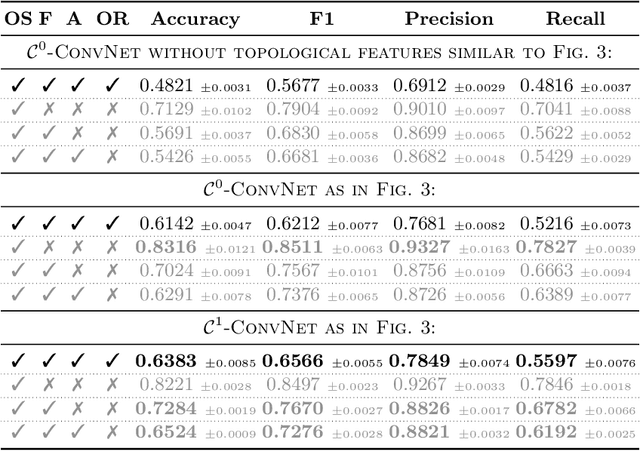
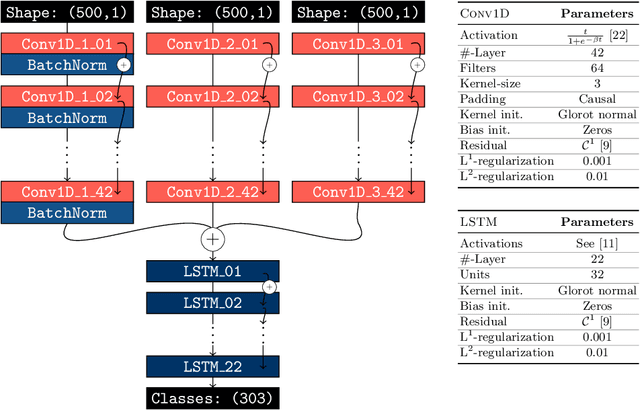
In this paper, we use topological data analysis techniques to construct a suitable neural network classifier for the task of learning sensor signals of entire power plants according to their reference designation system. We use representations of persistence diagrams to derive necessary preprocessing steps and visualize the large amounts of data. We derive architectures with deep one-dimensional convolutional layers combined with stacked long short-term memories as residual networks suitable for processing the persistence features. We combine three separate sub-networks, obtaining as input the time series itself and a representation of the persistent homology for the zeroth and first dimension. We give a mathematical derivation for most of the used hyper-parameters. For validation, numerical experiments were performed with sensor data from four power plants of the same construction type.
StockEmotions: Discover Investor Emotions for Financial Sentiment Analysis and Multivariate Time Series
Jan 23, 2023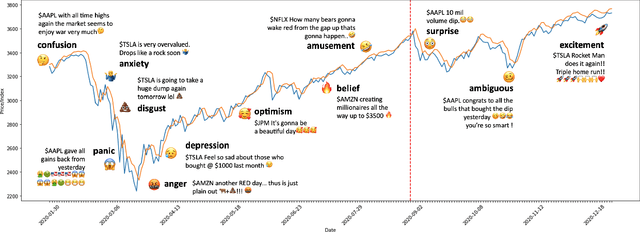
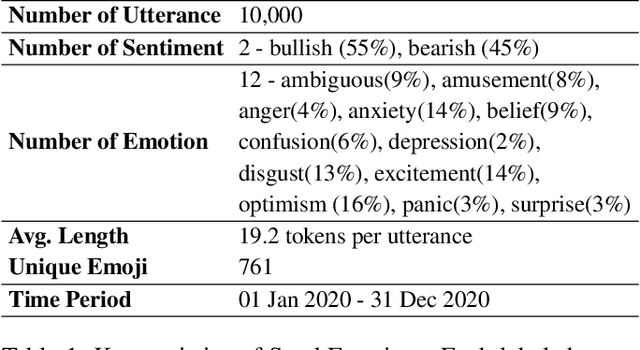
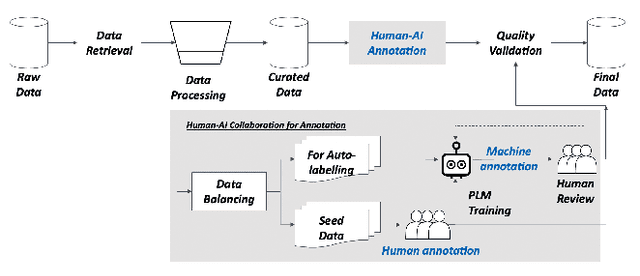
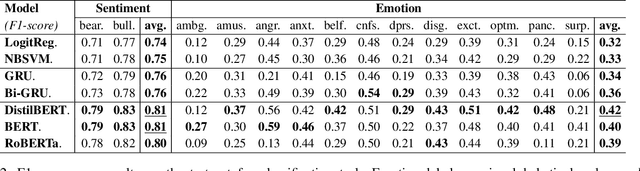
There has been growing interest in applying NLP techniques in the financial domain, however, resources are extremely limited. This paper introduces StockEmotions, a new dataset for detecting emotions in the stock market that consists of 10,000 English comments collected from StockTwits, a financial social media platform. Inspired by behavioral finance, it proposes 12 fine-grained emotion classes that span the roller coaster of investor emotion. Unlike existing financial sentiment datasets, StockEmotions presents granular features such as investor sentiment classes, fine-grained emotions, emojis, and time series data. To demonstrate the usability of the dataset, we perform a dataset analysis and conduct experimental downstream tasks. For financial sentiment/emotion classification tasks, DistilBERT outperforms other baselines, and for multivariate time series forecasting, a Temporal Attention LSTM model combining price index, text, and emotion features achieves the best performance than using a single feature.