 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text": models, code, and papers
A Marker-based Neural Network System for Extracting Social Determinants of Health
Dec 24, 2022
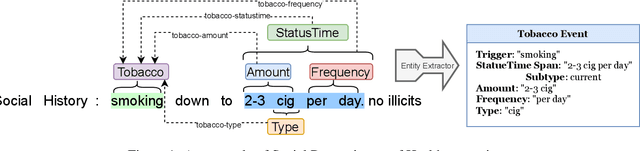
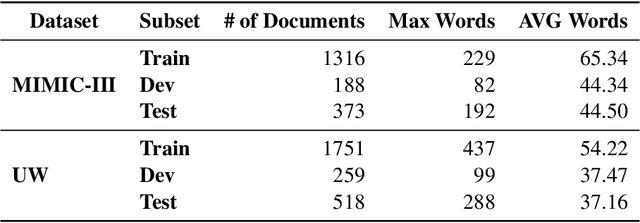
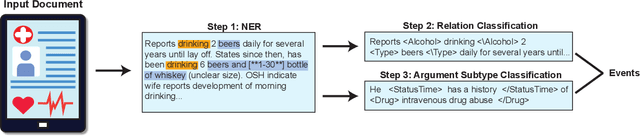
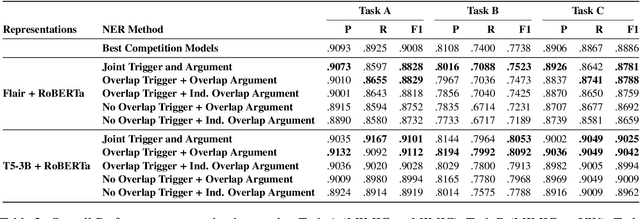
Objective. The impact of social determinants of health (SDoH) on patients' healthcare quality and the disparity is well-known. Many SDoH items are not coded in structured forms in electronic health records. These items are often captured in free-text clinical notes, but there are limited methods for automatically extracting them. We explore a multi-stage pipeline involving named entity recognition (NER), relation classification (RC), and text classification methods to extract SDoH information from clinical notes automatically. Materials and Methods. The study uses the N2C2 Shared Task data, which was collected from two sources of clinical notes: MIMIC-III and University of Washington Harborview Medical Centers. It contains 4480 social history sections with full annotation for twelve SDoHs. In order to handle the issue of overlapping entities, we developed a novel marker-based NER model. We used it in a multi-stage pipeline to extract SDoH information from clinical notes. Results. Our marker-based system outperformed the state-of-the-art span-based models at handling overlapping entities based on the overall Micro-F1 score performance. It also achieved state-of-the-art performance compared to the shared task methods. Conclusion. The major finding of this study is that the multi-stage pipeline effectively extracts SDoH information from clinical notes. This approach can potentially improve the understanding and tracking of SDoHs in clinical settings. However, error propagation may be an issue, and further research is needed to improve the extraction of entities with complex semantic meanings and low-resource entities using external knowledge.
DiffusER: Discrete Diffusion via Edit-based Reconstruction
Oct 30, 2022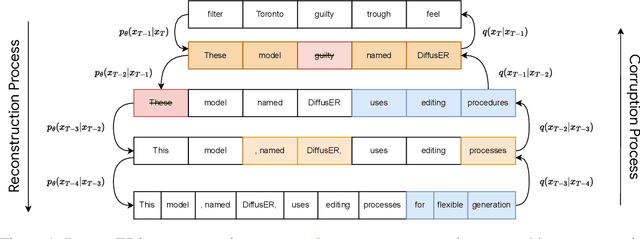

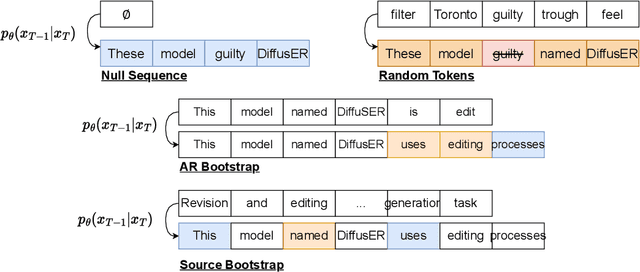
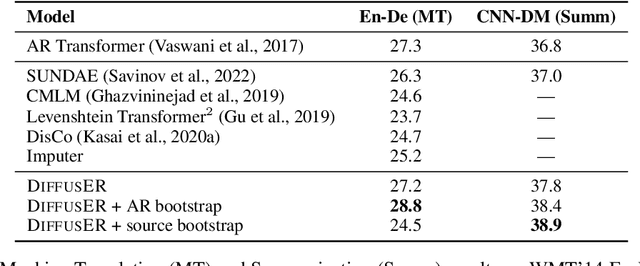
In text generation, models that generate text from scratch one token at a time are currently the dominant paradigm. Despite being performant, these models lack the ability to revise existing text, which limits their usability in many practical scenarios. We look to address this, with DiffusER (Diffusion via Edit-based Reconstruction), a new edit-based generative model for text based on denoising diffusion models -- a class of models that use a Markov chain of denoising steps to incrementally generate data. DiffusER is not only a strong generative model in general, rivalling autoregressive models on several tasks spanning machine translation, summarization, and style transfer; it can also perform other varieties of generation that standard autoregressive models are not well-suited for. For instance, we demonstrate that DiffusER makes it possible for a user to condition generation on a prototype, or an incomplete sequence, and continue revising based on previous edit steps.
Annotated History of Modern AI and Deep Learning
Dec 21, 2022Machine learning is the science of credit assignment: finding patterns in observations that predict consequences of actions and help to improve future performance. Credit assignment is also required for human understanding of how the world works, not only for individuals navigating daily life, but also for academic professionals like historians who interpret the present in light of past events. Here I focus on the history of modern artificial intelligence (AI) which is dominated by artificial neural networks (NNs) and deep learning, both conceptually closer to the old field of cybernetics than to what's been called AI since 1956 (e.g., expert systems and logic programming). A modern history of AI will emphasize breakthroughs outside of the focus of traditional AI text books, in particular, mathematical foundations of today's NNs such as the chain rule (1676), the first NNs (linear regression, circa 1800), and the first working deep learners (1965-). From the perspective of 2022, I provide a timeline of the -- in hindsight -- most important relevant events in the history of NNs, deep learning, AI, computer science, and mathematics in general, crediting those who laid foundations of the field. The text contains numerous hyperlinks to relevant overview sites from my AI Blog. It supplements my previous deep learning survey (2015) which provides hundreds of additional references. Finally, to round it off, I'll put things in a broader historic context spanning the time since the Big Bang until when the universe will be many times older than it is now.
Back-Translation-Style Data Augmentation for Mandarin Chinese Polyphone Disambiguation
Nov 17, 2022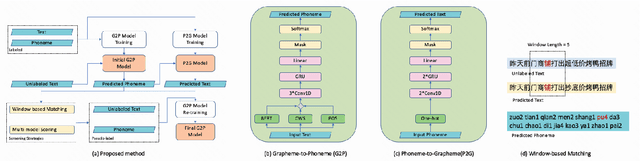
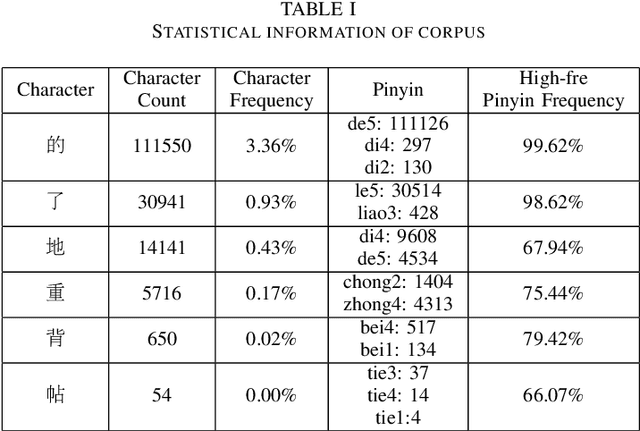
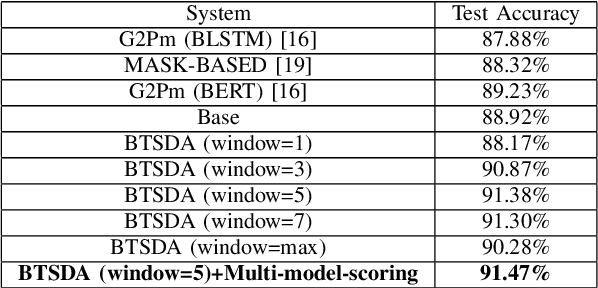
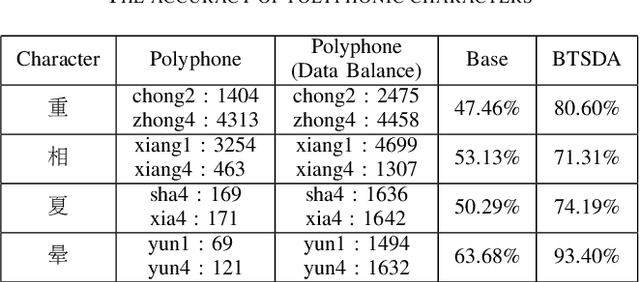
Conversion of Chinese Grapheme-to-Phoneme (G2P) plays an important role in Mandarin Chinese Text-To-Speech (TTS) systems, where one of the biggest challenges is the task of polyphone disambiguation. Most of the previous polyphone disambiguation models are trained on manually annotated datasets, and publicly available datasets for polyphone disambiguation are scarce. In this paper we propose a simple back-translation-style data augmentation method for mandarin Chinese polyphone disambiguation, utilizing a large amount of unlabeled text data. Inspired by the back-translation technique proposed in the field of machine translation, we build a Grapheme-to-Phoneme (G2P) model to predict the pronunciation of polyphonic character, and a Phoneme-to-Grapheme (P2G) model to predict pronunciation into text. Meanwhile, a window-based matching strategy and a multi-model scoring strategy are proposed to judge the correctness of the pseudo-label. We design a data balance strategy to improve the accuracy of some typical polyphonic characters in the training set with imbalanced distribution or data scarcity. The experimental result shows the effectiveness of the proposed back-translation-style data augmentation method.
Task-Adaptive Pre-Training for Boosting Learning With Noisy Labels: A Study on Text Classification for African Languages
Jun 03, 2022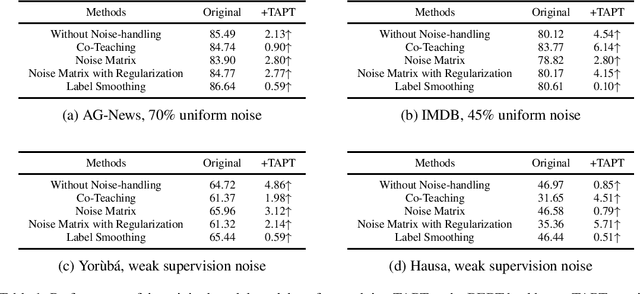
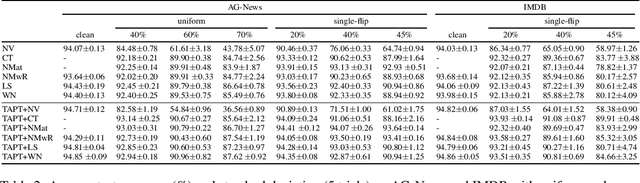
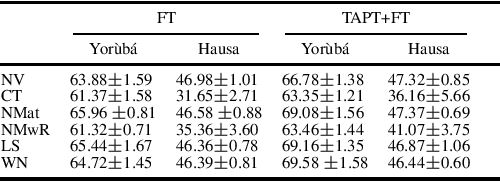
For high-resource languages like English, text classification is a well-studied task. The performance of modern NLP models easily achieves an accuracy of more than 90% in many standard datasets for text classification in English (Xie et al., 2019; Yang et al., 2019; Zaheer et al., 2020). However, text classification in low-resource languages is still challenging due to the lack of annotated data. Although methods like weak supervision and crowdsourcing can help ease the annotation bottleneck, the annotations obtained by these methods contain label noise. Models trained with label noise may not generalize well. To this end, a variety of noise-handling techniques have been proposed to alleviate the negative impact caused by the errors in the annotations (for extensive surveys see (Hedderich et al., 2021; Algan & Ulusoy, 2021)). In this work, we experiment with a group of standard noisy-handling methods on text classification tasks with noisy labels. We study both simulated noise and realistic noise induced by weak supervision. Moreover, we find task-adaptive pre-training techniques (Gururangan et al., 2020) are beneficial for learning with noisy labels.
GroupViT: Semantic Segmentation Emerges from Text Supervision
Feb 22, 2022
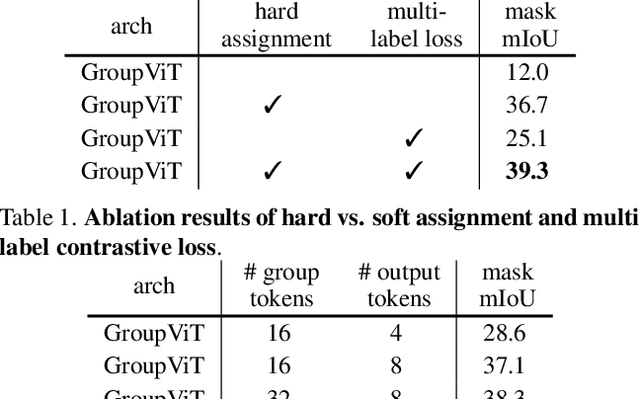
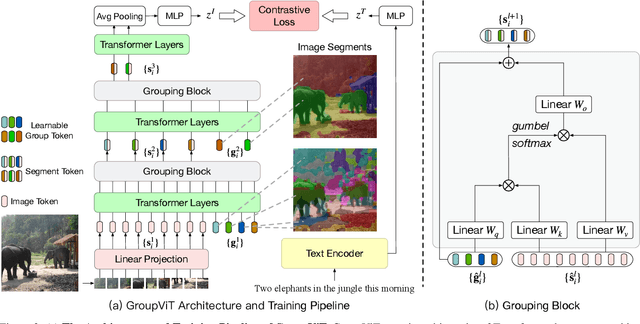
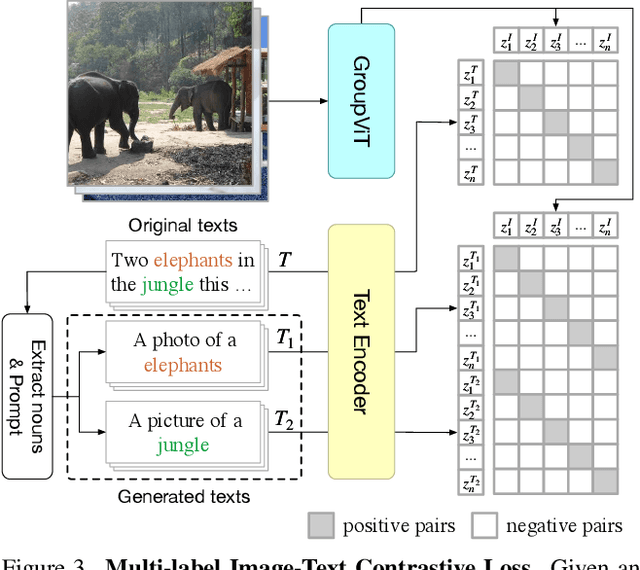
Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 51.2% mIoU on the PASCAL VOC 2012 and 22.3% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision. Project page is available at https://jerryxu.net/GroupViT.
A Bilingual, OpenWorld Video Text Dataset and End-to-end Video Text Spotter with Transformer
Dec 09, 2021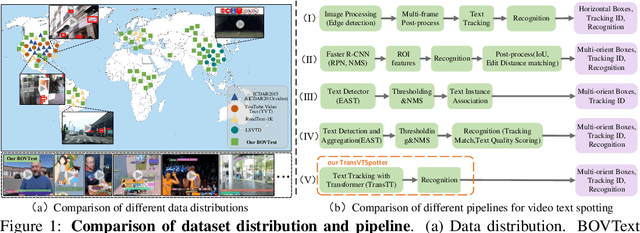
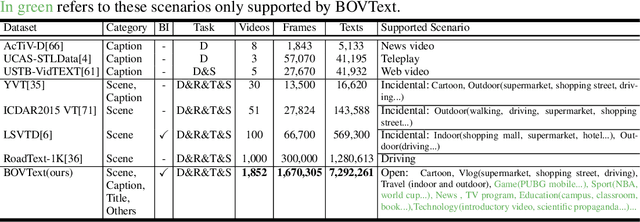

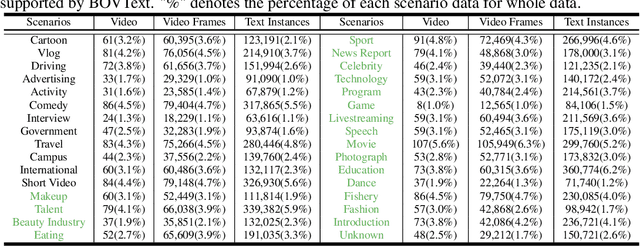
Most existing video text spotting benchmarks focus on evaluating a single language and scenario with limited data. In this work, we introduce a large-scale, Bilingual, Open World Video text benchmark dataset(BOVText). There are four features for BOVText. Firstly, we provide 2,000+ videos with more than 1,750,000+ frames, 25 times larger than the existing largest dataset with incidental text in videos. Secondly, our dataset covers 30+ open categories with a wide selection of various scenarios, e.g., Life Vlog, Driving, Movie, etc. Thirdly, abundant text types annotation (i.e., title, caption or scene text) are provided for the different representational meanings in video. Fourthly, the BOVText provides bilingual text annotation to promote multiple cultures live and communication. Besides, we propose an end-to-end video text spotting framework with Transformer, termed TransVTSpotter, which solves the multi-orient text spotting in video with a simple, but efficient attention-based query-key mechanism. It applies object features from the previous frame as a tracking query for the current frame and introduces a rotation angle prediction to fit the multiorient text instance. On ICDAR2015(video), TransVTSpotter achieves the state-of-the-art performance with 44.1% MOTA, 9 fps. The dataset and code of TransVTSpotter can be found at github:com=weijiawu=BOVText and github:com=weijiawu=TransVTSpotter, respectively.
* 20 pages, 6 figures
A Late Multi-Modal Fusion Model for Detecting Hybrid Spam E-mail
Oct 26, 2022
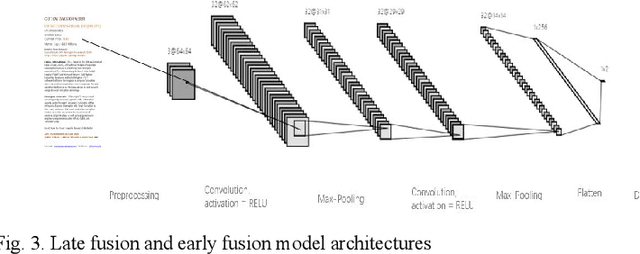
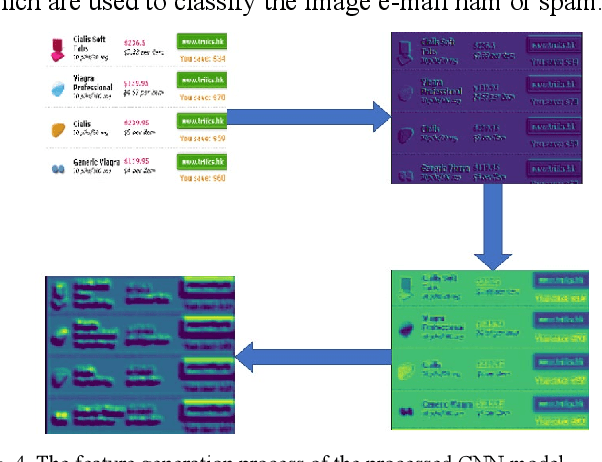

In recent years, spammers are now trying to obfuscate their intents by introducing hybrid spam e-mail combining both image and text parts, which is more challenging to detect in comparison to e-mails containing text or image only. The motivation behind this research is to design an effective approach filtering out hybrid spam e-mails to avoid situations where traditional text-based or image-baesd only filters fail to detect hybrid spam e-mails. To the best of our knowledge, a few studies have been conducted with the goal of detecting hybrid spam e-mails. Ordinarily, Optical Character Recognition (OCR) technology is used to eliminate the image parts of spam by transforming images into text. However, the research questions are that although OCR scanning is a very successful technique in processing text-and-image hybrid spam, it is not an effective solution for dealing with huge quantities due to the CPU power required and the execution time it takes to scan e-mail files. And the OCR techniques are not always reliable in the transformation processes. To address such problems, we propose new late multi-modal fusion training frameworks for a text-and-image hybrid spam e-mail filtering system compared to the classical early fusion detection frameworks based on the OCR method. Convolutional Neural Network (CNN) and Continuous Bag of Words were implemented to extract features from image and text parts of hybrid spam respectively, whereas generated features were fed to sigmoid layer and Machine Learning based classifiers including Random Forest (RF), Decision Tree (DT), Naive Bayes (NB) and Support Vector Machine (SVM) to determine the e-mail ham or spam.
Towards Open-Set Text Recognition via Label-to-Prototype Learning
Apr 09, 2022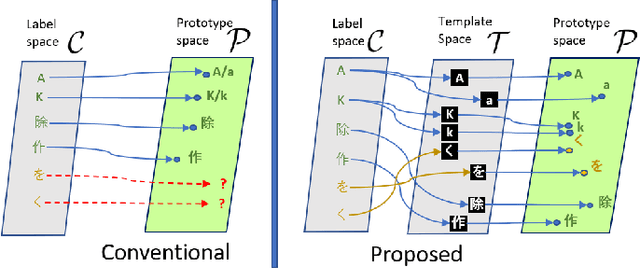
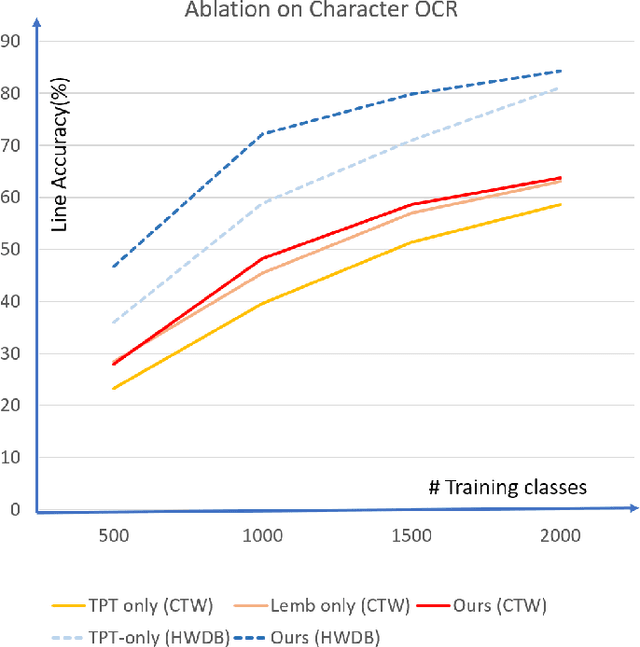
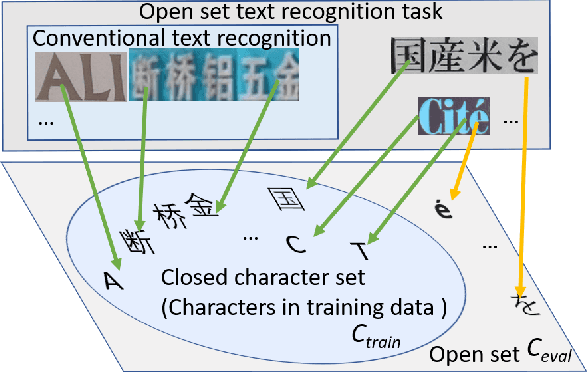
Scene text recognition is a popular topic and extensively used in the industry. Although many methods have achieved satisfactory performance for the close-set text recognition challenges, these methods lose feasibility in open-set scenarios, where collecting data or retraining models for novel characters is too expensive. E.g., annotating samples for foreign languages can be expensive, whereas retraining the model each time a "novel" character is discovered from historical documents also costs time and resources. In this paper, we introduce and formulate a new task, i.e., the open-set text recognition task, which demands the capability to spot and cognize novel characters without retraining. Here, we propose a label-to-prototype learning framework that fulfills the new requirements in the proposed task. Specifically, novel characters are mapped to their corresponding prototypes with a Label-to-Prototype Learning module. The module is trained on seen labels and holds generalization capability for generating class centers for novel characters without retraining. The framework also implements rejection capability over out-of-set characters, which allows spotting unknown characters during the evaluation process. Extensive experiments show that our method achieves promising performance on a variety of zero-shot, close-set, and open-set text recognition datasets.
A Simple Contrastive Learning Objective for Alleviating Neural Text Degeneration
May 19, 2022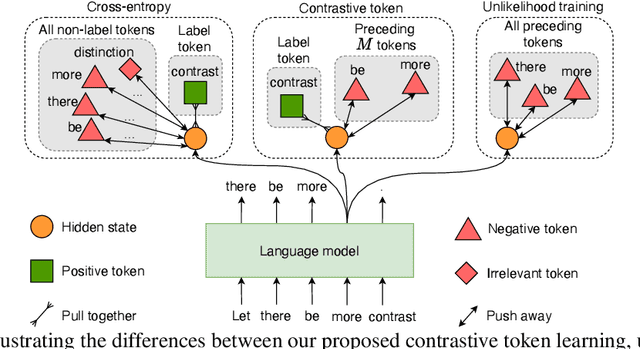
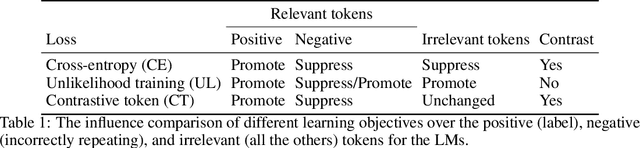
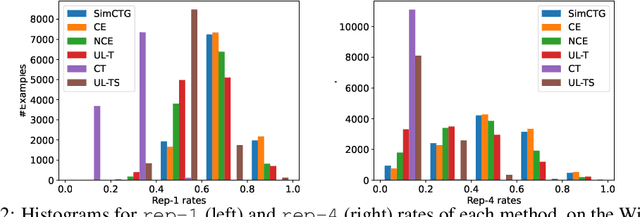
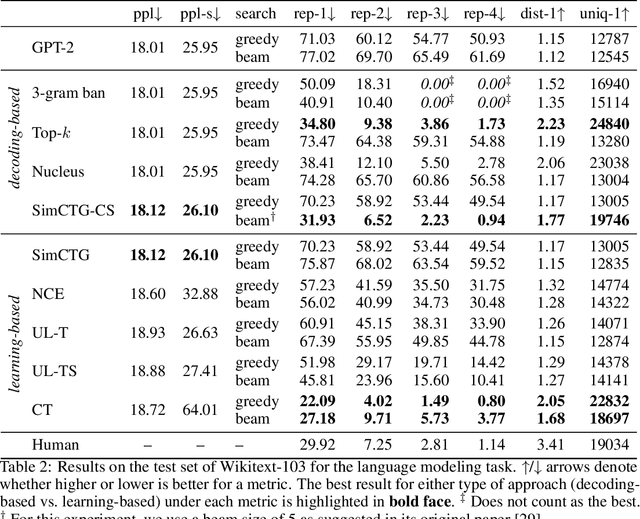
The cross-entropy objective has proved to be an all-purpose training objective for autoregressive language models (LMs). However, without considering the penalization of problematic tokens, LMs trained using cross-entropy exhibit text degeneration. To address this, unlikelihood training has been proposed to reduce the probability of unlikely tokens predicted by LMs. But unlikelihood does not consider the relationship between the label tokens and unlikely token candidates, thus showing marginal improvements in degeneration. We propose a new contrastive token learning objective that inherits the advantages of cross-entropy and unlikelihood training and avoids their limitations. The key idea is to teach a LM to generate high probabilities for label tokens and low probabilities of negative candidates. Comprehensive experiments on language modeling and open-domain dialogue generation tasks show that the proposed contrastive token objective yields much less repetitive texts, with a higher generation quality than baseline approaches, achieving the new state-of-the-art performance on text degeneration.