 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Debugging Failures in N-Gram-Based Generative Retrieval
Jun 16, 2026Generative Retrieval (GR) is an emerging Information Retrieval (IR) paradigm that is motivated by increasingly capable language models. In GR, a model directly generates identifiers for relevant documents. While these systems offer unique advantages, they also introduce distinct failure mechanisms. We explore these failure modes in three contributions: (1) We present a taxonomy of GR failure modes based on GR literature. (2) We empirically investigate failure in a subset of GR: ngram-based methods, more specifically, SEAL and MINDER. Our analysis reveals common issues, such as ambiguous docids, low identifier diversity, and the disproportionate impact of specific identifiers. (3) We introduce a new web-based tool that helps the IR community analyze generated ngrams and their respective contribution to the final ranking, providing an intuitive interface to identify where such GR methods go wrong.
Generative Retrieval Overcomes Limitations of Dense Retrieval but Struggles with Identifier Ambiguity
Apr 07, 2026While dense retrieval models, which embed queries and documents into a shared low-dimensional space, have gained widespread popu- larity, they were shown to exhibit important theoretical limitations and considerably lag behind traditional sparse retrieval models in certain settings. Generative retrieval has emerged as an alternative approach to dense retrieval by using a language model to predict query-document relevance directly. In this paper, we demonstrate strengths and weaknesses of generative retrieval approaches us- ing a simple synthetic dataset, called LIMIT, that was previously introduced to empirically demonstrate the theoretical limitations of embedding-based retrieval but was not used to evaluate genera- tive retrieval. We close this research gap and show that generative retrieval achieves the best performance on this dataset without any additional training required (0.92 and 0.99 R@2 for SEAL and MINDER, respectively), compared to dense approaches (< 0.03 Re- call@2) and BM25 (0.86 R@2). However, we then proceed to extend the original LIMIT dataset by adding simple hard negative samples and observe the performance degrading for all the models including the generative retrieval models (0.51 R@2) as well as BM25 (0.21 R@2). Error analysis identifies a failure in the decoding mechanism, caused by the inability to produce identifiers that are unique to relevant documents. Future generative retrieval must address these issues, either by designing identifiers that are more suitable to the decoding process or by adapting decoding and scoring algorithms to preserve relevance signals.
Orcheo: A Modular Full-Stack Platform for Conversational Search
Feb 16, 2026Conversational search (CS) requires a complex software engineering pipeline that integrates query reformulation, ranking, and response generation. CS researchers currently face two barriers: the lack of a unified framework for efficiently sharing contributions with the community, and the difficulty of deploying end-to-end prototypes needed for user evaluation. We introduce Orcheo, an open-source platform designed to bridge this gap. Orcheo offers three key advantages: (i) A modular architecture promotes component reuse through single-file node modules, facilitating sharing and reproducibility in CS research; (ii) Production-ready infrastructure bridges the prototype-to-system gap via dual execution modes, secure credential management, and execution telemetry, with built-in AI coding support that lowers the learning curve; (iii) Starter-kit assets include 50+ off-the-shelf components for query understanding, ranking, and response generation, enabling the rapid bootstrapping of complete CS pipelines. We describe the framework architecture and validate Orcheo's utility through case studies that highlight modularity and ease of use. Orcheo is released as open source under the MIT License at https://github.com/ShaojieJiang/orcheo.
Retrieving Contextual Information for Long-Form Question Answering using Weak Supervision
Oct 11, 2024Long-form question answering (LFQA) aims at generating in-depth answers to end-user questions, providing relevant information beyond the direct answer. However, existing retrievers are typically optimized towards information that directly targets the question, missing out on such contextual information. Furthermore, there is a lack of training data for relevant context. To this end, we propose and compare different weak supervision techniques to optimize retrieval for contextual information. Experiments demonstrate improvements on the end-to-end QA performance on ASQA, a dataset for long-form question answering. Importantly, as more contextual information is retrieved, we improve the relevant page recall for LFQA by 14.7% and the groundedness of generated long-form answers by 12.5%. Finally, we show that long-form answers often anticipate likely follow-up questions, via experiments on a conversational QA dataset.
Beyond Relevant Documents: A Knowledge-Intensive Approach for Query-Focused Summarization using Large Language Models
Aug 19, 2024Query-focused summarization (QFS) is a fundamental task in natural language processing with broad applications, including search engines and report generation. However, traditional approaches assume the availability of relevant documents, which may not always hold in practical scenarios, especially in highly specialized topics. To address this limitation, we propose a novel knowledge-intensive approach that reframes QFS as a knowledge-intensive task setup. This approach comprises two main components: a retrieval module and a summarization controller. The retrieval module efficiently retrieves potentially relevant documents from a large-scale knowledge corpus based on the given textual query, eliminating the dependence on pre-existing document sets. The summarization controller seamlessly integrates a powerful large language model (LLM)-based summarizer with a carefully tailored prompt, ensuring the generated summary is comprehensive and relevant to the query. To assess the effectiveness of our approach, we create a new dataset, along with human-annotated relevance labels, to facilitate comprehensive evaluation covering both retrieval and summarization performance. Extensive experiments demonstrate the superior performance of our approach, particularly its ability to generate accurate summaries without relying on the availability of relevant documents initially. This underscores our method's versatility and practical applicability across diverse query scenarios.
Scene-centric vs. Object-centric Image-Text Cross-modal Retrieval: A Reproducibility Study
Jan 12, 2023Most approaches to cross-modal retrieval (CMR) focus either on object-centric datasets, meaning that each document depicts or describes a single object, or on scene-centric datasets, meaning that each image depicts or describes a complex scene that involves multiple objects and relations between them. We posit that a robust CMR model should generalize well across both dataset types. Despite recent advances in CMR, the reproducibility of the results and their generalizability across different dataset types has not been studied before. We address this gap and focus on the reproducibility of the state-of-the-art CMR results when evaluated on object-centric and scene-centric datasets. We select two state-of-the-art CMR models with different architectures: (i) CLIP; and (ii) X-VLM. Additionally, we select two scene-centric datasets, and three object-centric datasets, and determine the relative performance of the selected models on these datasets. We focus on reproducibility, replicability, and generalizability of the outcomes of previously published CMR experiments. We discover that the experiments are not fully reproducible and replicable. Besides, the relative performance results partially generalize across object-centric and scene-centric datasets. On top of that, the scores obtained on object-centric datasets are much lower than the scores obtained on scene-centric datasets. For reproducibility and transparency we make our source code and the trained models publicly available.
Focusing on Context is NICE: Improving Overshadowed Entity Disambiguation
Oct 12, 2022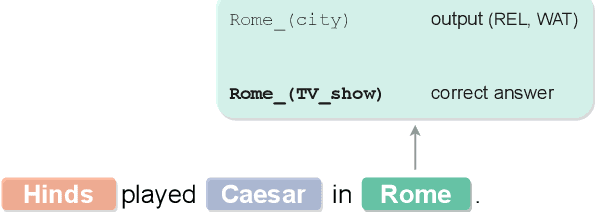
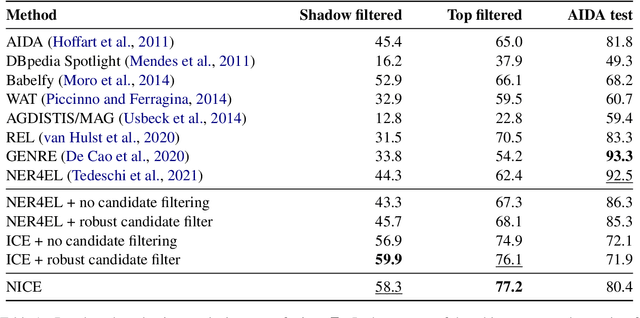
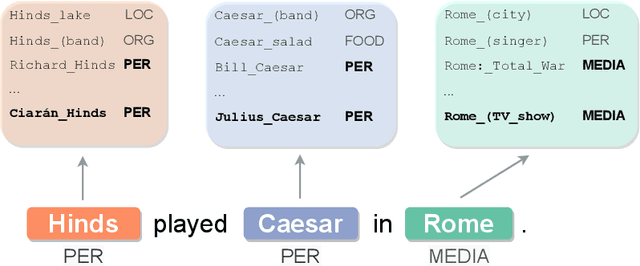
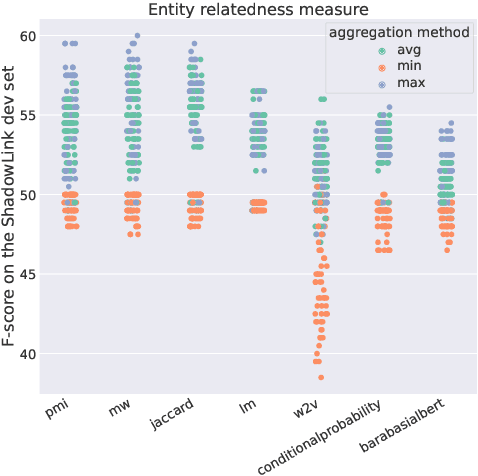
Entity disambiguation (ED) is the task of mapping an ambiguous entity mention to the corresponding entry in a structured knowledge base. Previous research showed that entity overshadowing is a significant challenge for existing ED models: when presented with an ambiguous entity mention, the models are much more likely to rank a more frequent yet less contextually relevant entity at the top. Here, we present NICE, an iterative approach that uses entity type information to leverage context and avoid over-relying on the frequency-based prior. Our experiments show that NICE achieves the best performance results on the overshadowed entities while still performing competitively on the frequent entities.
On the Impact of Speech Recognition Errors in Passage Retrieval for Spoken Question Answering
Sep 26, 2022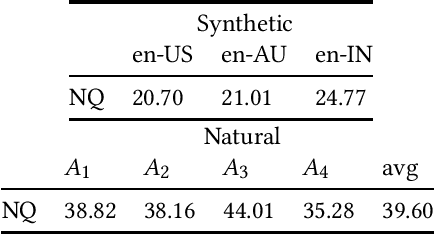

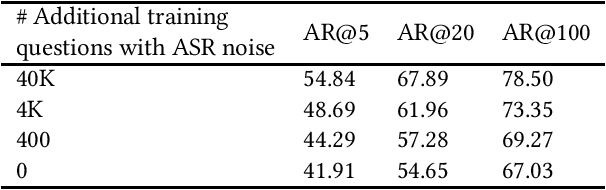
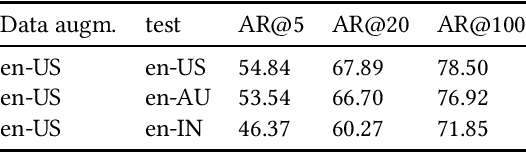
Interacting with a speech interface to query a Question Answering (QA) system is becoming increasingly popular. Typically, QA systems rely on passage retrieval to select candidate contexts and reading comprehension to extract the final answer. While there has been some attention to improving the reading comprehension part of QA systems against errors that automatic speech recognition (ASR) models introduce, the passage retrieval part remains unexplored. However, such errors can affect the performance of passage retrieval, leading to inferior end-to-end performance. To address this gap, we augment two existing large-scale passage ranking and open domain QA datasets with synthetic ASR noise and study the robustness of lexical and dense retrievers against questions with ASR noise. Furthermore, we study the generalizability of data augmentation techniques across different domains; with each domain being a different language dialect or accent. Finally, we create a new dataset with questions voiced by human users and use their transcriptions to show that the retrieval performance can further degrade when dealing with natural ASR noise instead of synthetic ASR noise.
Low-Resource Dense Retrieval for Open-Domain Question Answering: A Comprehensive Survey
Aug 05, 2022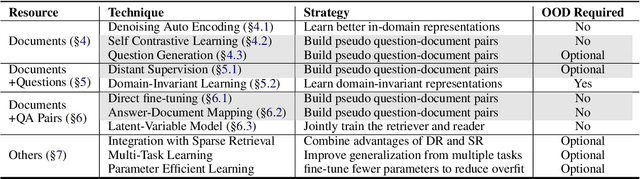
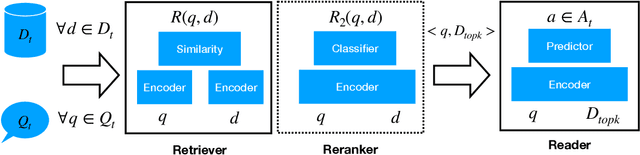

Dense retrieval (DR) approaches based on powerful pre-trained language models (PLMs) achieved significant advances and have become a key component for modern open-domain question-answering systems. However, they require large amounts of manual annotations to perform competitively, which is infeasible to scale. To address this, a growing body of research works have recently focused on improving DR performance under low-resource scenarios. These works differ in what resources they require for training and employ a diverse set of techniques. Understanding such differences is crucial for choosing the right technique under a specific low-resource scenario. To facilitate this understanding, we provide a thorough structured overview of mainstream techniques for low-resource DR. Based on their required resources, we divide the techniques into three main categories: (1) only documents are needed; (2) documents and questions are needed; and (3) documents and question-answer pairs are needed. For every technique, we introduce its general-form algorithm, highlight the open issues and pros and cons. Promising directions are outlined for future research.
A Simple Contrastive Learning Objective for Alleviating Neural Text Degeneration
May 19, 2022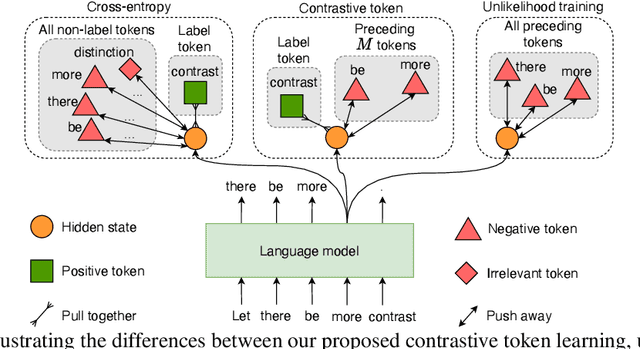
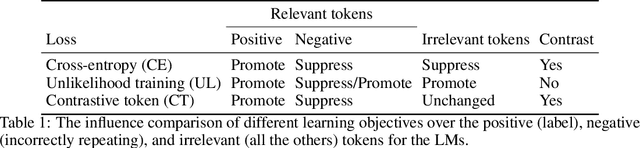
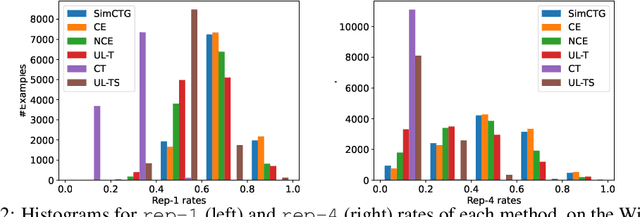
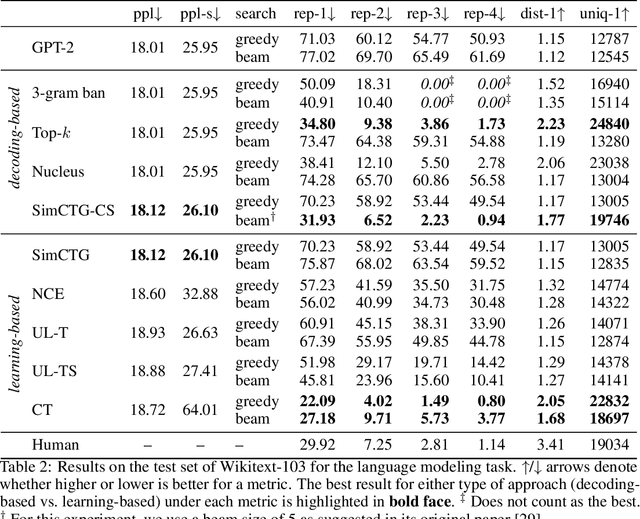
The cross-entropy objective has proved to be an all-purpose training objective for autoregressive language models (LMs). However, without considering the penalization of problematic tokens, LMs trained using cross-entropy exhibit text degeneration. To address this, unlikelihood training has been proposed to reduce the probability of unlikely tokens predicted by LMs. But unlikelihood does not consider the relationship between the label tokens and unlikely token candidates, thus showing marginal improvements in degeneration. We propose a new contrastive token learning objective that inherits the advantages of cross-entropy and unlikelihood training and avoids their limitations. The key idea is to teach a LM to generate high probabilities for label tokens and low probabilities of negative candidates. Comprehensive experiments on language modeling and open-domain dialogue generation tasks show that the proposed contrastive token objective yields much less repetitive texts, with a higher generation quality than baseline approaches, achieving the new state-of-the-art performance on text degeneration.