 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
A text-dependent speaker verification application framework based on Chinese numerical string corpus
Dec 04, 2023
Researches indicate that text-dependent speaker verification (TD-SV) often outperforms text-independent verification (TI-SV) in short speech scenarios. However, collecting large-scale fixed text speech data is challenging, and as speech length increases, factors like sentence rhythm and pauses affect TDSV's sensitivity to text sequence. Based on these factors, We propose the hypothesis that strategies such as more fine-grained pooling methods on time scales and decoupled representations of speech speaker embedding and text embedding are more suitable for TD-SV. We have introduced an end-to-end TD-SV system based on a dataset comprising longer Chinese numerical string texts. It contains a text embedding network, a speaker embedding network, and back-end fusion. First, we recorded a dataset consisting of long Chinese numerical text named SHAL, which is publicly available on the Open-SLR website. We addressed the issue of dataset scarcity by augmenting it using Tacotron2 and HiFi-GAN. Next, we introduced a dual representation of speech with text embedding and speaker embedding. In the text embedding network, we employed an enhanced Transformer and introduced a triple loss that includes text classification loss, CTC loss, and decoder loss. For the speaker embedding network, we enhanced a sliding window attentive statistics pooling (SWASP), combined with attentive statistics pooling (ASP) to create a multi-scale pooling method. Finally, we fused text embedding and speaker embedding. Our pooling methods achieved an equal error rate (EER) performance improvement of 49.2% on Hi-Mia and 75.0% on SHAL, respectively.
BERT Goes Off-Topic: Investigating the Domain Transfer Challenge using Genre Classification
Nov 27, 2023While performance of many text classification tasks has been recently improved due to Pre-trained Language Models (PLMs), in this paper we show that they still suffer from a performance gap when the underlying distribution of topics changes. For example, a genre classifier trained on \textit{political} topics often fails when tested on documents about \textit{sport} or \textit{medicine}. In this work, we quantify this phenomenon empirically with a large corpus and a large set of topics. Consequently, we verify that domain transfer remains challenging both for classic PLMs, such as BERT, and for modern large models, such as GPT-3. We also suggest and successfully test a possible remedy: after augmenting the training dataset with topically-controlled synthetic texts, the F1 score improves by up to 50\% for some topics, nearing on-topic training results, while others show little to no improvement. While our empirical results focus on genre classification, our methodology is applicable to other classification tasks such as gender, authorship, or sentiment classification. The code and data to replicate the experiments are available at https://github.com/dminus1/genre
Dialogue Quality and Emotion Annotations for Customer Support Conversations
Nov 23, 2023Task-oriented conversational datasets often lack topic variability and linguistic diversity. However, with the advent of Large Language Models (LLMs) pretrained on extensive, multilingual and diverse text data, these limitations seem overcome. Nevertheless, their generalisability to different languages and domains in dialogue applications remains uncertain without benchmarking datasets. This paper presents a holistic annotation approach for emotion and conversational quality in the context of bilingual customer support conversations. By performing annotations that take into consideration the complete instances that compose a conversation, one can form a broader perspective of the dialogue as a whole. Furthermore, it provides a unique and valuable resource for the development of text classification models. To this end, we present benchmarks for Emotion Recognition and Dialogue Quality Estimation and show that further research is needed to leverage these models in a production setting.
Gzip versus bag-of-words for text classification with KNN
Aug 03, 2023
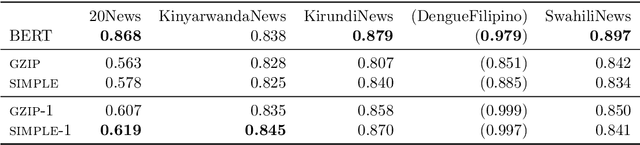
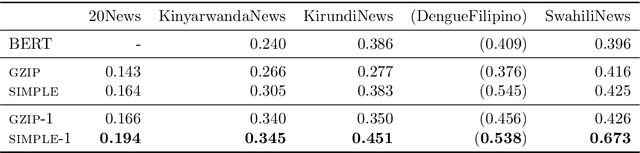
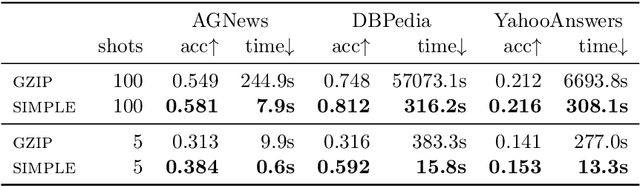
The effectiveness of compression distance in KNN-based text classification ('gzip') has recently garnered lots of attention. In this note we show that simpler means can also be effective, and compression may not be needed. Indeed, a 'bag-of-words' matching can achieve similar or better results, and is more efficient.
TurkishBERTweet: Fast and Reliable Large Language Model for Social Media Analysis
Nov 29, 2023
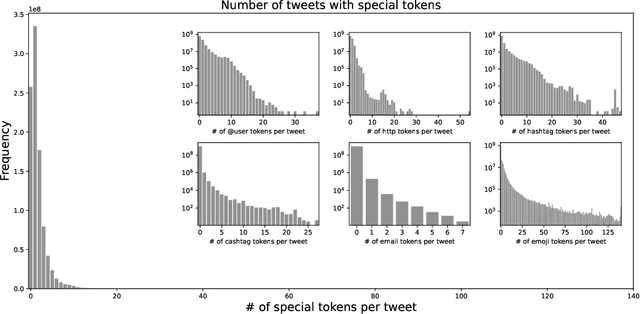
Turkish is one of the most popular languages in the world. Wide us of this language on social media platforms such as Twitter, Instagram, or Tiktok and strategic position of the country in the world politics makes it appealing for the social network researchers and industry. To address this need, we introduce TurkishBERTweet, the first large scale pre-trained language model for Turkish social media built using almost 900 million tweets. The model shares the same architecture as base BERT model with smaller input length, making TurkishBERTweet lighter than BERTurk and can have significantly lower inference time. We trained our model using the same approach for RoBERTa model and evaluated on two text classification tasks: Sentiment Classification and Hate Speech Detection. We demonstrate that TurkishBERTweet outperforms the other available alternatives on generalizability and its lower inference time gives significant advantage to process large-scale datasets. We also compared our models with the commercial OpenAI solutions in terms of cost and performance to demonstrate TurkishBERTweet is scalable and cost-effective solution. As part of our research, we released TurkishBERTweet and fine-tuned LoRA adapters for the mentioned tasks under the MIT License to facilitate future research and applications on Turkish social media. Our TurkishBERTweet model is available at: https://github.com/ViralLab/TurkishBERTweet
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Dec 26, 2023The exponential growth of large language models (LLMs) has opened up numerous possibilities for multimodal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the LLM, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on 32 generic visual-linguistic benchmarks including visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. It has powerful visual capabilities and can be a good alternative to the ViT-22B. We hope that our research could contribute to the development of multi-modal large models. Code and models are available at https://github.com/OpenGVLab/InternVL.
TagAlign: Improving Vision-Language Alignment with Multi-Tag Classification
Dec 26, 2023The crux of learning vision-language models is to extract semantically aligned information from visual and linguistic data. Existing attempts usually face the problem of coarse alignment, e.g., the vision encoder struggles in localizing an attribute-specified object. In this work, we propose an embarrassingly simple approach to better align image and text features with no need of additional data formats other than image-text pairs. Concretely, given an image and its paired text, we manage to parse objects (e.g., cat) and attributes (e.g., black) from the description, which are highly likely to exist in the image. It is noteworthy that the parsing pipeline is fully automatic and thus enjoys good scalability. With these parsed semantics as supervision signals, we can complement the commonly used image-text contrastive loss with the multi-tag classification loss. Extensive experimental results on a broad suite of semantic segmentation datasets substantiate the average 3.65\% improvement of our framework over existing alternatives. Furthermore, the visualization results indicate that attribute supervision makes vision-language models accurately localize attribute-specified objects. Project page and code can be found at https://qinying-liu.github.io/Tag-Align.
Learning under Label Proportions for Text Classification
Oct 18, 2023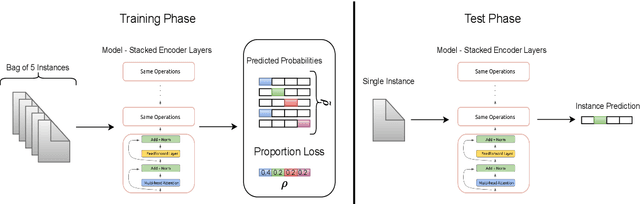
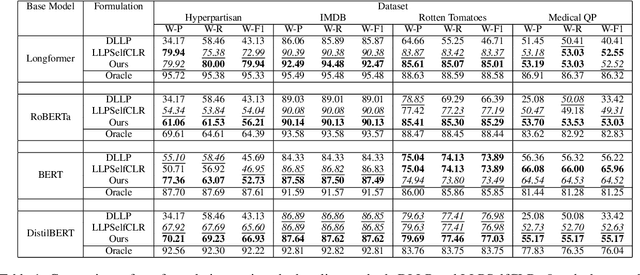
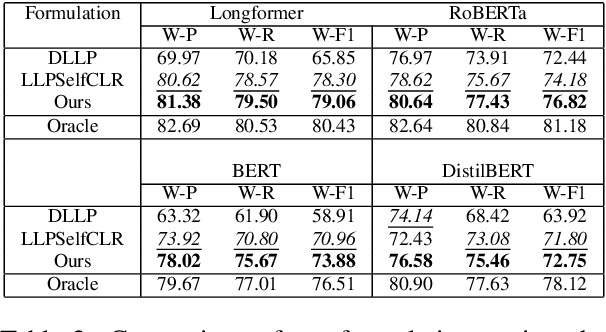
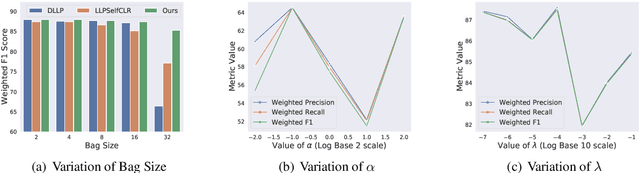
We present one of the preliminary NLP works under the challenging setup of Learning from Label Proportions (LLP), where the data is provided in an aggregate form called bags and only the proportion of samples in each class as the ground truth. This setup is inline with the desired characteristics of training models under Privacy settings and Weakly supervision. By characterizing some irregularities of the most widely used baseline technique DLLP, we propose a novel formulation that is also robust. This is accompanied with a learnability result that provides a generalization bound under LLP. Combining this formulation with a self-supervised objective, our method achieves better results as compared to the baselines in almost 87% of the experimental configurations which include large scale models for both long and short range texts across multiple metrics.
USA: Universal Sentiment Analysis Model & Construction of Japanese Sentiment Text Classification and Part of Speech Dataset
Sep 07, 2023

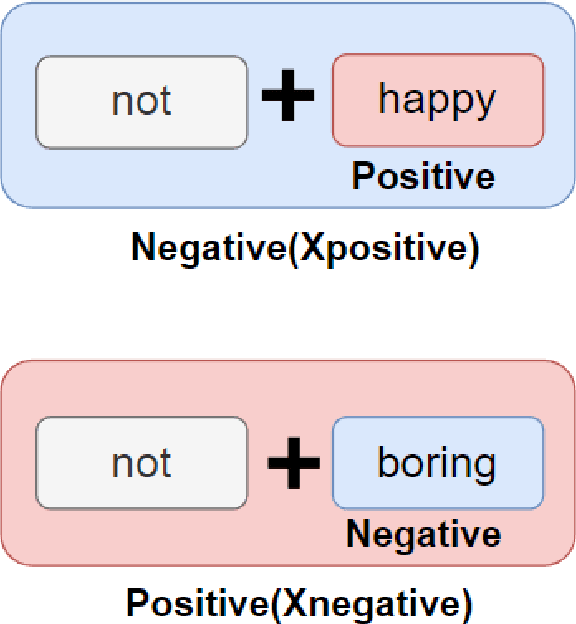
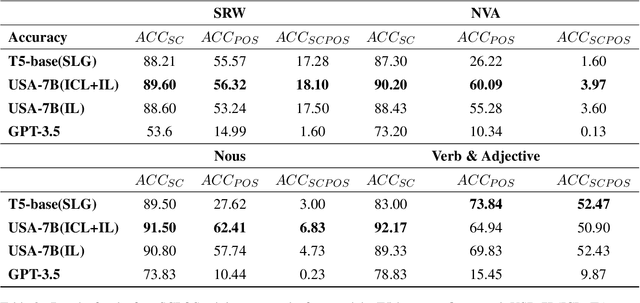
Sentiment analysis is a pivotal task in the domain of natural language processing. It encompasses both text-level sentiment polarity classification and word-level Part of Speech(POS) sentiment polarity determination. Such analysis challenges models to understand text holistically while also extracting nuanced information. With the rise of Large Language Models(LLMs), new avenues for sentiment analysis have opened. This paper proposes enhancing performance by leveraging the Mutual Reinforcement Effect(MRE) between individual words and the overall text. It delves into how word polarity influences the overarching sentiment of a passage. To support our research, we annotated four novel Sentiment Text Classification and Part of Speech(SCPOS) datasets, building upon existing sentiment classification datasets. Furthermore, we developed a Universal Sentiment Analysis(USA) model, with a 7-billion parameter size. Experimental results revealed that our model surpassed the performance of gpt-3.5-turbo across all four datasets, underscoring the significance of MRE in sentiment analysis.