 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the WMT 2024 Shared Task on Chat Translation
Oct 15, 2024



This paper presents the findings from the third edition of the Chat Translation Shared Task. As with previous editions, the task involved translating bilingual customer support conversations, specifically focusing on the impact of conversation context in translation quality and evaluation. We also include two new language pairs: English-Korean and English-Dutch, in addition to the set of language pairs from previous editions: English-German, English-French, and English-Brazilian Portuguese. We received 22 primary submissions and 32 contrastive submissions from eight teams, with each language pair having participation from at least three teams. We evaluated the systems comprehensively using both automatic metrics and human judgments via a direct assessment framework. The official rankings for each language pair were determined based on human evaluation scores, considering performance in both translation directions--agent and customer. Our analysis shows that while the systems excelled at translating individual turns, there is room for improvement in overall conversation-level translation quality.
Dialogue Quality and Emotion Annotations for Customer Support Conversations
Nov 23, 2023



Task-oriented conversational datasets often lack topic variability and linguistic diversity. However, with the advent of Large Language Models (LLMs) pretrained on extensive, multilingual and diverse text data, these limitations seem overcome. Nevertheless, their generalisability to different languages and domains in dialogue applications remains uncertain without benchmarking datasets. This paper presents a holistic annotation approach for emotion and conversational quality in the context of bilingual customer support conversations. By performing annotations that take into consideration the complete instances that compose a conversation, one can form a broader perspective of the dialogue as a whole. Furthermore, it provides a unique and valuable resource for the development of text classification models. To this end, we present benchmarks for Emotion Recognition and Dialogue Quality Estimation and show that further research is needed to leverage these models in a production setting.
CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task
Sep 13, 2022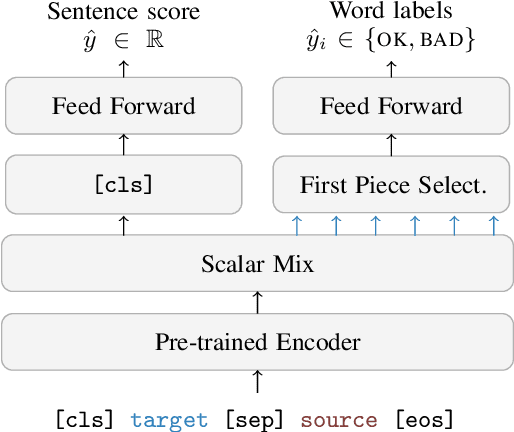
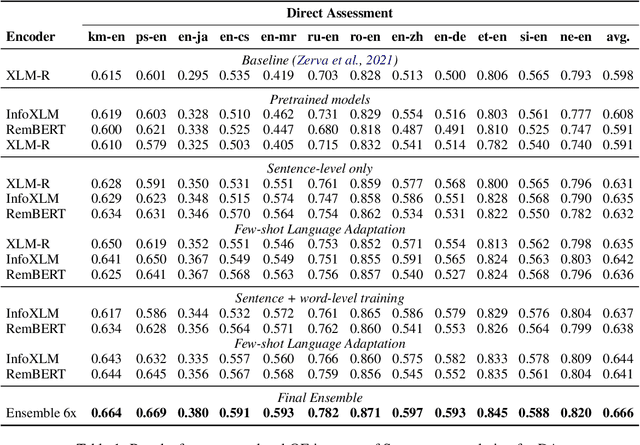
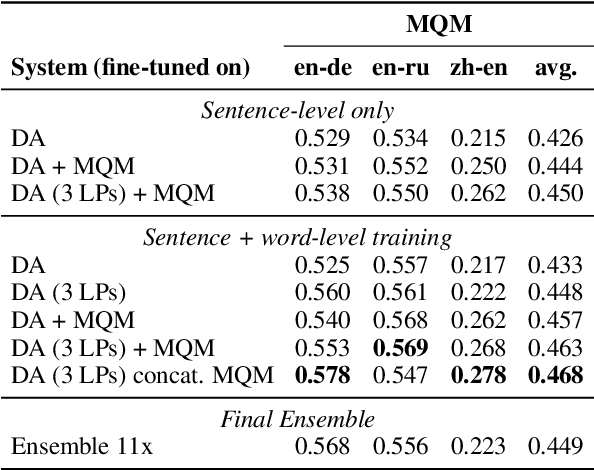
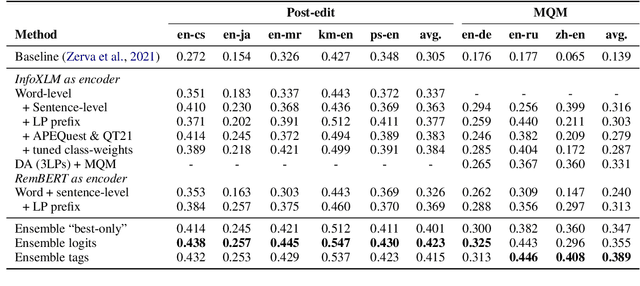
We present the joint contribution of IST and Unbabel to the WMT 2022 Shared Task on Quality Estimation (QE). Our team participated on all three subtasks: (i) Sentence and Word-level Quality Prediction; (ii) Explainable QE; and (iii) Critical Error Detection. For all tasks we build on top of the COMET framework, connecting it with the predictor-estimator architecture of OpenKiwi, and equipping it with a word-level sequence tagger and an explanation extractor. Our results suggest that incorporating references during pretraining improves performance across several language pairs on downstream tasks, and that jointly training with sentence and word-level objectives yields a further boost. Furthermore, combining attention and gradient information proved to be the top strategy for extracting good explanations of sentence-level QE models. Overall, our submissions achieved the best results for all three tasks for almost all language pairs by a considerable margin.