 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
EMONA: Event-level Moral Opinions in News Articles
Apr 02, 2024
Most previous research on moral frames has focused on social media short texts, little work has explored moral sentiment within news articles. In news articles, authors often express their opinions or political stance through moral judgment towards events, specifically whether the event is right or wrong according to social moral rules. This paper initiates a new task to understand moral opinions towards events in news articles. We have created a new dataset, EMONA, and annotated event-level moral opinions in news articles. This dataset consists of 400 news articles containing over 10k sentences and 45k events, among which 9,613 events received moral foundation labels. Extracting event morality is a challenging task, as moral judgment towards events can be very implicit. Baseline models were built for event moral identification and classification. In addition, we also conduct extrinsic evaluations to integrate event-level moral opinions into three downstream tasks. The statistical analysis and experiments show that moral opinions of events can serve as informative features for identifying ideological bias or subjective events.
Self-supervised Regularization for Text Classification
Mar 24, 2021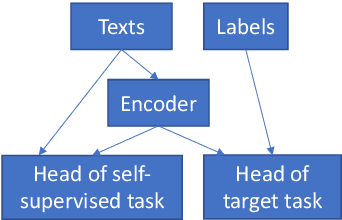
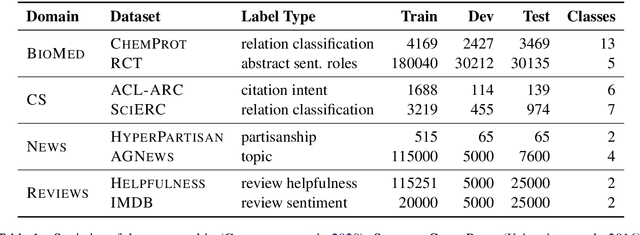

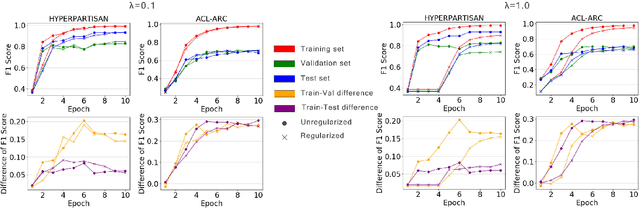
Text classification is a widely studied problem and has broad applications. In many real-world problems, the number of texts for training classification models is limited, which renders these models prone to overfitting. To address this problem, we propose SSL-Reg, a data-dependent regularization approach based on self-supervised learning (SSL). SSL is an unsupervised learning approach which defines auxiliary tasks on input data without using any human-provided labels and learns data representations by solving these auxiliary tasks. In SSL-Reg, a supervised classification task and an unsupervised SSL task are performed simultaneously. The SSL task is unsupervised, which is defined purely on input texts without using any human-provided labels. Training a model using an SSL task can prevent the model from being overfitted to a limited number of class labels in the classification task. Experiments on 17 text classification datasets demonstrate the effectiveness of our proposed method.
Emotional Intelligence Through Artificial Intelligence : NLP and Deep Learning in the Analysis of Healthcare Texts
Mar 14, 2024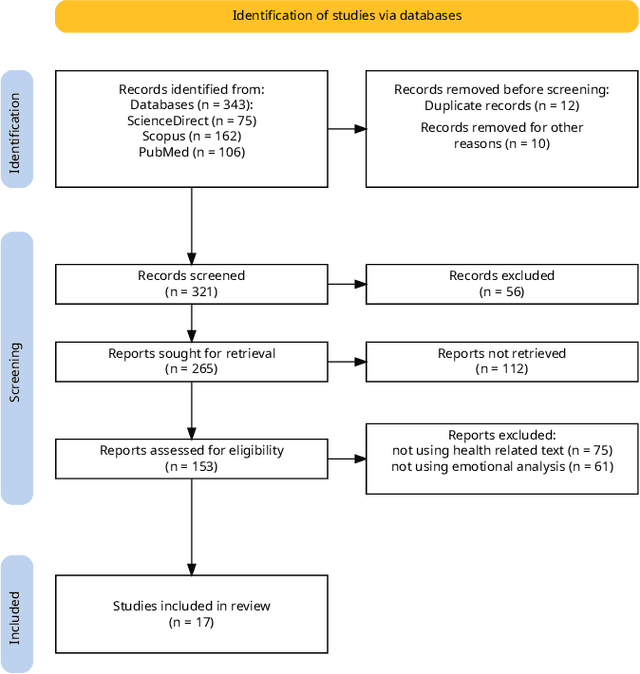
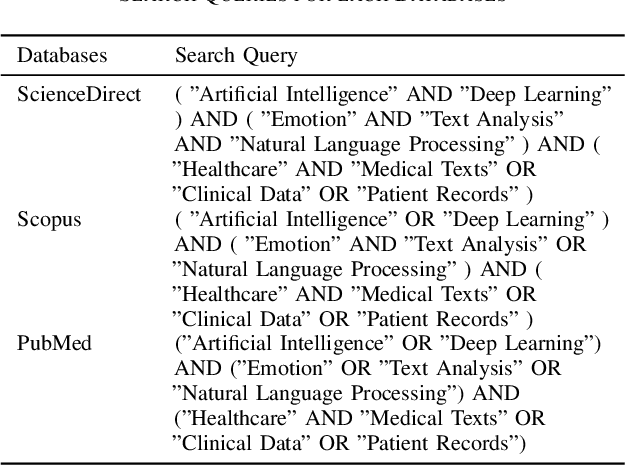
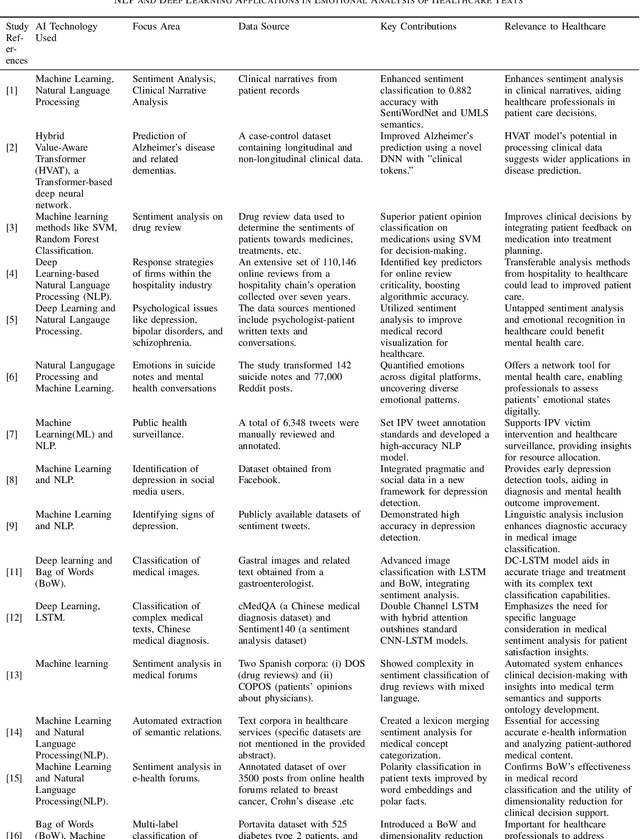
This manuscript presents a methodical examination of the utilization of Artificial Intelligence in the assessment of emotions in texts related to healthcare, with a particular focus on the incorporation of Natural Language Processing and deep learning technologies. We scrutinize numerous research studies that employ AI to augment sentiment analysis, categorize emotions, and forecast patient outcomes based on textual information derived from clinical narratives, patient feedback on medications, and online health discussions. The review demonstrates noteworthy progress in the precision of algorithms used for sentiment classification, the prognostic capabilities of AI models for neurodegenerative diseases, and the creation of AI-powered systems that offer support in clinical decision-making. Remarkably, the utilization of AI applications has exhibited an enhancement in personalized therapy plans by integrating patient sentiment and contributing to the early identification of mental health disorders. There persist challenges, which encompass ensuring the ethical application of AI, safeguarding patient confidentiality, and addressing potential biases in algorithmic procedures. Nevertheless, the potential of AI to revolutionize healthcare practices is unmistakable, offering a future where healthcare is not only more knowledgeable and efficient but also more empathetic and centered around the needs of patients. This investigation underscores the transformative influence of AI on healthcare, delivering a comprehensive comprehension of its role in examining emotional content in healthcare texts and highlighting the trajectory towards a more compassionate approach to patient care. The findings advocate for a harmonious synergy between AI's analytical capabilities and the human aspects of healthcare.
An Analysis of Human Alignment of Latent Diffusion Models
Mar 13, 2024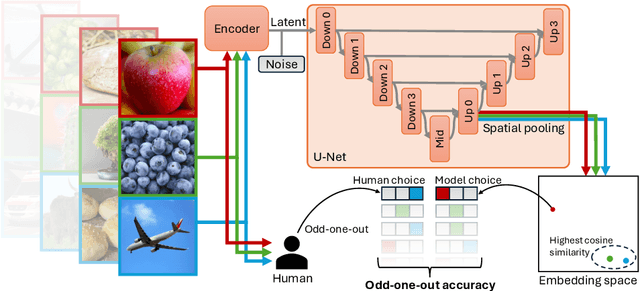
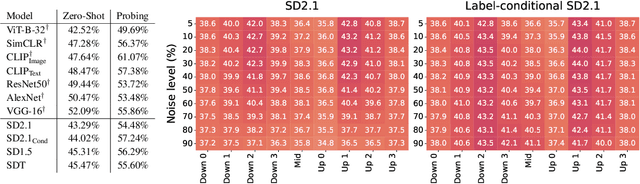
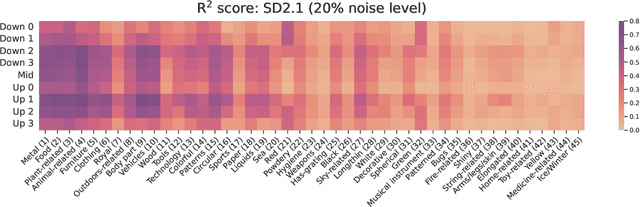
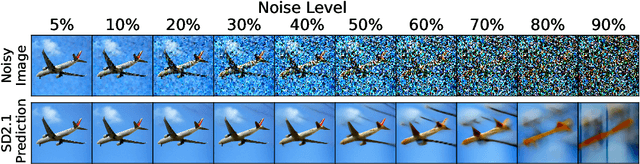
Diffusion models, trained on large amounts of data, showed remarkable performance for image synthesis. They have high error consistency with humans and low texture bias when used for classification. Furthermore, prior work demonstrated the decomposability of their bottleneck layer representations into semantic directions. In this work, we analyze how well such representations are aligned to human responses on a triplet odd-one-out task. We find that despite the aforementioned observations: I) The representational alignment with humans is comparable to that of models trained only on ImageNet-1k. II) The most aligned layers of the denoiser U-Net are intermediate layers and not the bottleneck. III) Text conditioning greatly improves alignment at high noise levels, hinting at the importance of abstract textual information, especially in the early stage of generation.
BioT5+: Towards Generalized Biological Understanding with IUPAC Integration and Multi-task Tuning
Feb 27, 2024Recent research trends in computational biology have increasingly focused on integrating text and bio-entity modeling, especially in the context of molecules and proteins. However, previous efforts like BioT5 faced challenges in generalizing across diverse tasks and lacked a nuanced understanding of molecular structures, particularly in their textual representations (e.g., IUPAC). This paper introduces BioT5+, an extension of the BioT5 framework, tailored to enhance biological research and drug discovery. BioT5+ incorporates several novel features: integration of IUPAC names for molecular understanding, inclusion of extensive bio-text and molecule data from sources like bioRxiv and PubChem, the multi-task instruction tuning for generality across tasks, and a novel numerical tokenization technique for improved processing of numerical data. These enhancements allow BioT5+ to bridge the gap between molecular representations and their textual descriptions, providing a more holistic understanding of biological entities, and largely improving the grounded reasoning of bio-text and bio-sequences. The model is pre-trained and fine-tuned with a large number of experiments, including \emph{3 types of problems (classification, regression, generation), 15 kinds of tasks, and 21 total benchmark datasets}, demonstrating the remarkable performance and state-of-the-art results in most cases. BioT5+ stands out for its ability to capture intricate relationships in biological data, thereby contributing significantly to bioinformatics and computational biology. Our code is available at \url{https://github.com/QizhiPei/BioT5}.
Benchmarking Large Language Models for Molecule Prediction Tasks
Mar 08, 2024
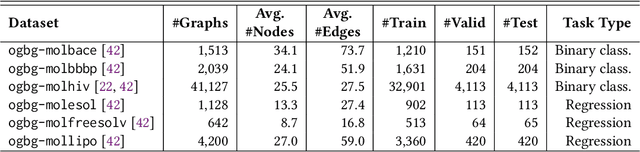
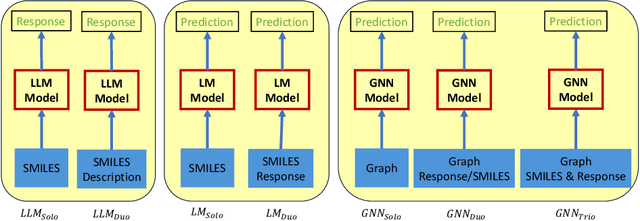
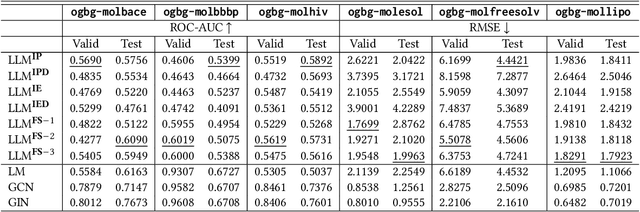
Large Language Models (LLMs) stand at the forefront of a number of Natural Language Processing (NLP) tasks. Despite the widespread adoption of LLMs in NLP, much of their potential in broader fields remains largely unexplored, and significant limitations persist in their design and implementation. Notably, LLMs struggle with structured data, such as graphs, and often falter when tasked with answering domain-specific questions requiring deep expertise, such as those in biology and chemistry. In this paper, we explore a fundamental question: Can LLMs effectively handle molecule prediction tasks? Rather than pursuing top-tier performance, our goal is to assess how LLMs can contribute to diverse molecule tasks. We identify several classification and regression prediction tasks across six standard molecule datasets. Subsequently, we carefully design a set of prompts to query LLMs on these tasks and compare their performance with existing Machine Learning (ML) models, which include text-based models and those specifically designed for analysing the geometric structure of molecules. Our investigation reveals several key insights: Firstly, LLMs generally lag behind ML models in achieving competitive performance on molecule tasks, particularly when compared to models adept at capturing the geometric structure of molecules, highlighting the constrained ability of LLMs to comprehend graph data. Secondly, LLMs show promise in enhancing the performance of ML models when used collaboratively. Lastly, we engage in a discourse regarding the challenges and promising avenues to harness LLMs for molecule prediction tasks. The code and models are available at https://github.com/zhiqiangzhongddu/LLMaMol.
Scaling on-chip photonic neural processors using arbitrarily programmable wave propagation
Feb 27, 2024On-chip photonic processors for neural networks have potential benefits in both speed and energy efficiency but have not yet reached the scale at which they can outperform electronic processors. The dominant paradigm for designing on-chip photonics is to make networks of relatively bulky discrete components connected by one-dimensional waveguides. A far more compact alternative is to avoid explicitly defining any components and instead sculpt the continuous substrate of the photonic processor to directly perform the computation using waves freely propagating in two dimensions. We propose and demonstrate a device whose refractive index as a function of space, $n(x,z)$, can be rapidly reprogrammed, allowing arbitrary control over the wave propagation in the device. Our device, a 2D-programmable waveguide, combines photoconductive gain with the electro-optic effect to achieve massively parallel modulation of the refractive index of a slab waveguide, with an index modulation depth of $10^{-3}$ and approximately $10^4$ programmable degrees of freedom. We used a prototype device with a functional area of $12\,\text{mm}^2$ to perform neural-network inference with up to 49-dimensional input vectors in a single pass, achieving 96% accuracy on vowel classification and 86% accuracy on $7 \times 7$-pixel MNIST handwritten-digit classification. This is a scale beyond that of previous photonic chips relying on discrete components, illustrating the benefit of the continuous-waves paradigm. In principle, with large enough chip area, the reprogrammability of the device's refractive index distribution enables the reconfigurable realization of any passive, linear photonic circuit or device. This promises the development of more compact and versatile photonic systems for a wide range of applications, including optical processing, smart sensing, spectroscopy, and optical communications.
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Apr 02, 2024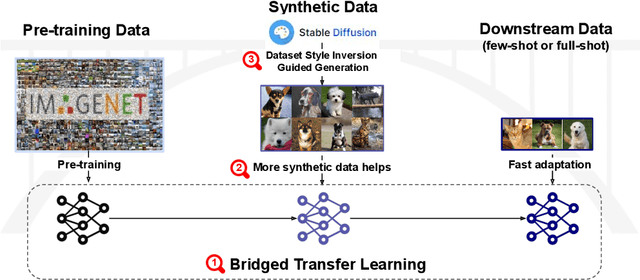
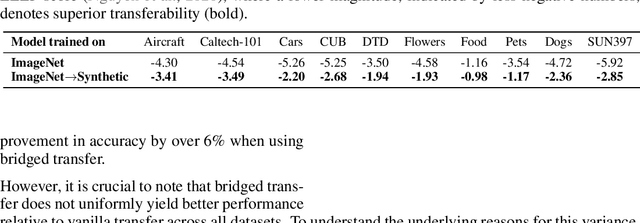
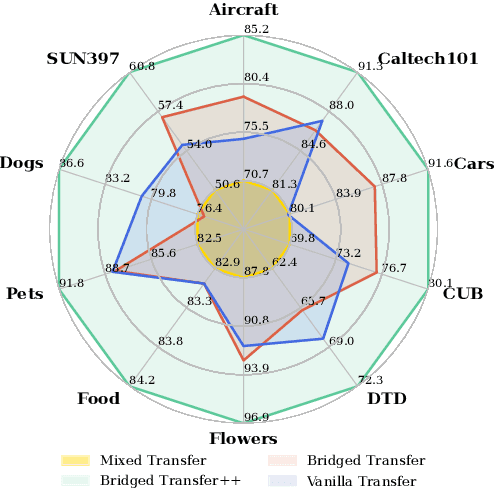

Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
Exploiting Adaptive Contextual Masking for Aspect-Based Sentiment Analysis
Feb 21, 2024Aspect-Based Sentiment Analysis (ABSA) is a fine-grained linguistics problem that entails the extraction of multifaceted aspects, opinions, and sentiments from the given text. Both standalone and compound ABSA tasks have been extensively used in the literature to examine the nuanced information present in online reviews and social media posts. Current ABSA methods often rely on static hyperparameters for attention-masking mechanisms, which can struggle with context adaptation and may overlook the unique relevance of words in varied situations. This leads to challenges in accurately analyzing complex sentences containing multiple aspects with differing sentiments. In this work, we present adaptive masking methods that remove irrelevant tokens based on context to assist in Aspect Term Extraction and Aspect Sentiment Classification subtasks of ABSA. We show with our experiments that the proposed methods outperform the baseline methods in terms of accuracy and F1 scores on four benchmark online review datasets. Further, we show that the proposed methods can be extended with multiple adaptations and demonstrate a qualitative analysis of the proposed approach using sample text for aspect term extraction.
A Hybrid Approach To Aspect Based Sentiment Analysis Using Transfer Learning
Mar 25, 2024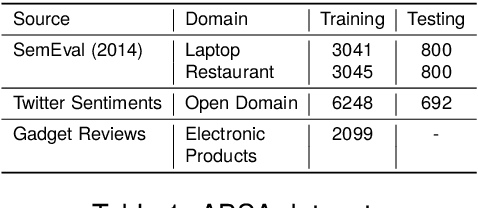
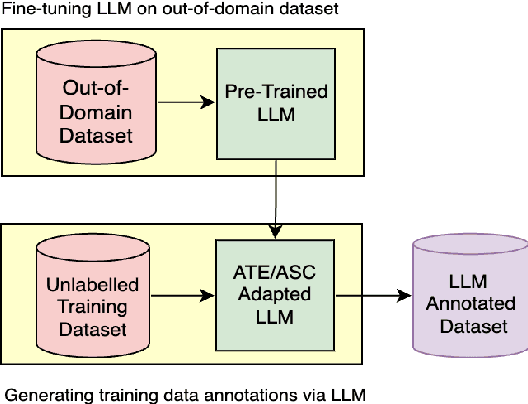
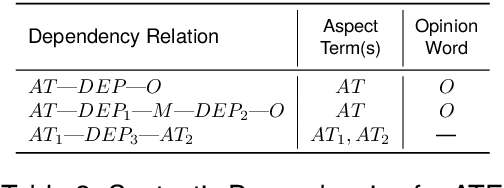
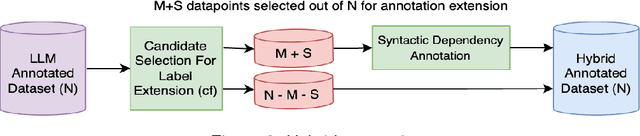
Aspect-Based Sentiment Analysis (ABSA) aims to identify terms or multiword expressions (MWEs) on which sentiments are expressed and the sentiment polarities associated with them. The development of supervised models has been at the forefront of research in this area. However, training these models requires the availability of manually annotated datasets which is both expensive and time-consuming. Furthermore, the available annotated datasets are tailored to a specific domain, language, and text type. In this work, we address this notable challenge in current state-of-the-art ABSA research. We propose a hybrid approach for Aspect Based Sentiment Analysis using transfer learning. The approach focuses on generating weakly-supervised annotations by exploiting the strengths of both large language models (LLM) and traditional syntactic dependencies. We utilise syntactic dependency structures of sentences to complement the annotations generated by LLMs, as they may overlook domain-specific aspect terms. Extensive experimentation on multiple datasets is performed to demonstrate the efficacy of our hybrid method for the tasks of aspect term extraction and aspect sentiment classification. Keywords: Aspect Based Sentiment Analysis, Syntactic Parsing, large language model (LLM)