 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Object Detection": models, code, and papers
MTP: Advancing Remote Sensing Foundation Model via Multi-Task Pretraining
Mar 20, 2024
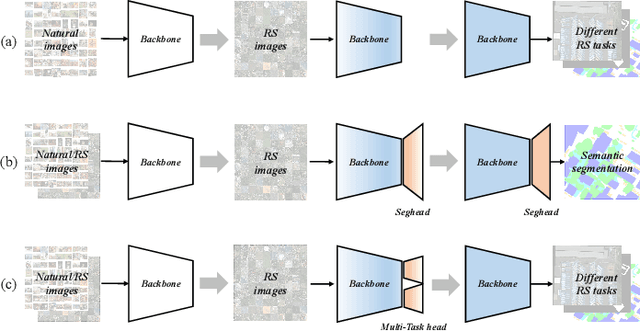
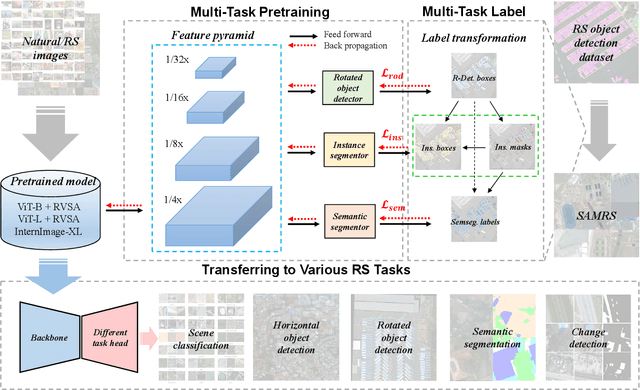
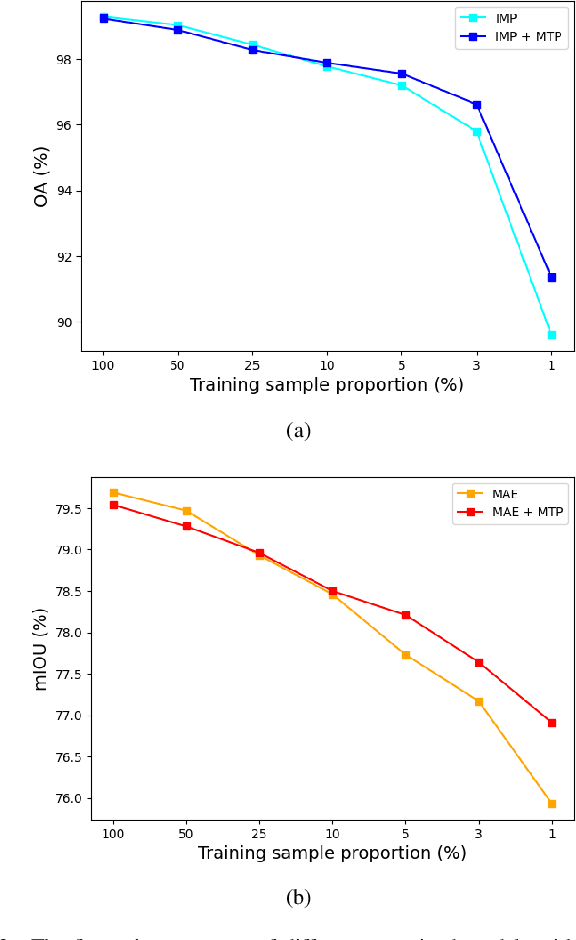

Foundation models have reshaped the landscape of Remote Sensing (RS) by enhancing various image interpretation tasks. Pretraining is an active research topic, encompassing supervised and self-supervised learning methods to initialize model weights effectively. However, transferring the pretrained models to downstream tasks may encounter task discrepancy due to their formulation of pretraining as image classification or object discrimination tasks. In this study, we explore the Multi-Task Pretraining (MTP) paradigm for RS foundation models to address this issue. Using a shared encoder and task-specific decoder architecture, we conduct multi-task supervised pretraining on the SAMRS dataset, encompassing semantic segmentation, instance segmentation, and rotated object detection. MTP supports both convolutional neural networks and vision transformer foundation models with over 300 million parameters. The pretrained models are finetuned on various RS downstream tasks, such as scene classification, horizontal and rotated object detection, semantic segmentation, and change detection. Extensive experiments across 14 datasets demonstrate the superiority of our models over existing ones of similar size and their competitive performance compared to larger state-of-the-art models, thus validating the effectiveness of MTP.
EcoSense: Energy-Efficient Intelligent Sensing for In-Shore Ship Detection through Edge-Cloud Collaboration
Mar 26, 2024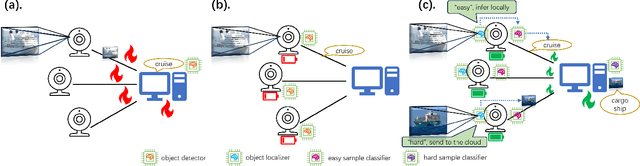

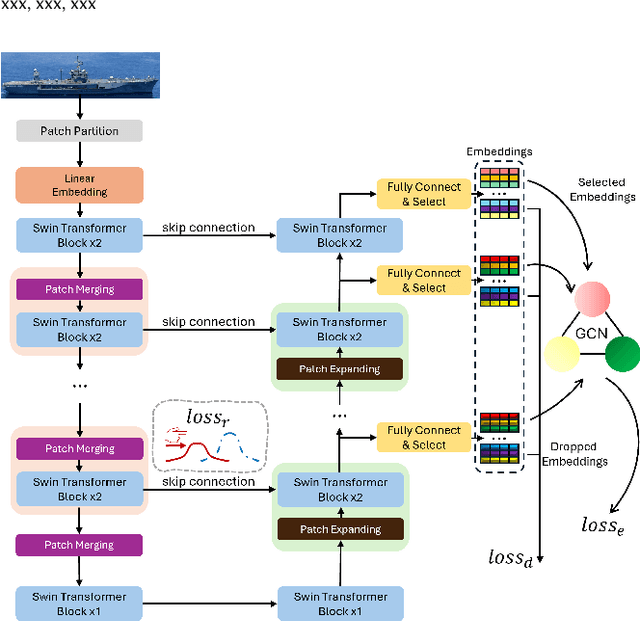
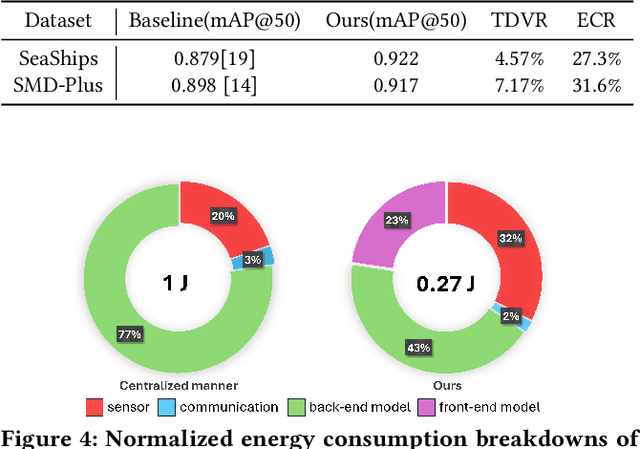
Detecting marine objects inshore presents challenges owing to algorithmic intricacies and complexities in system deployment. We propose a difficulty-aware edge-cloud collaborative sensing system that splits the task into object localization and fine-grained classification. Objects are classified either at the edge or within the cloud, based on their estimated difficulty. The framework comprises a low-power device-tailored front-end model for object localization, classification, and difficulty estimation, along with a transformer-graph convolutional network-based back-end model for fine-grained classification. Our system demonstrates superior performance (mAP@0.5 +4.3%}) on widely used marine object detection datasets, significantly reducing both data transmission volume (by 95.43%) and energy consumption (by 72.7%}) at the system level. We validate the proposed system across various embedded system platforms and in real-world scenarios involving drone deployment.
DenseNets Reloaded: Paradigm Shift Beyond ResNets and ViTs
Mar 28, 2024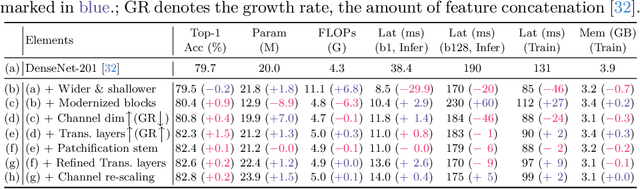
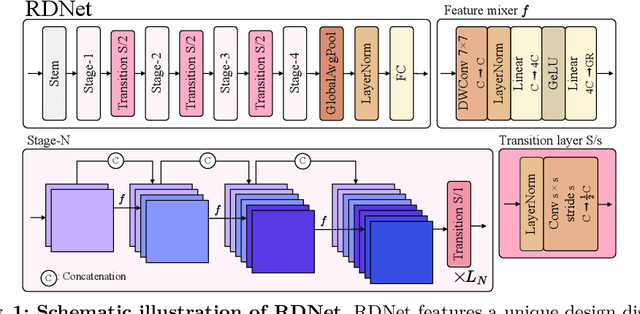
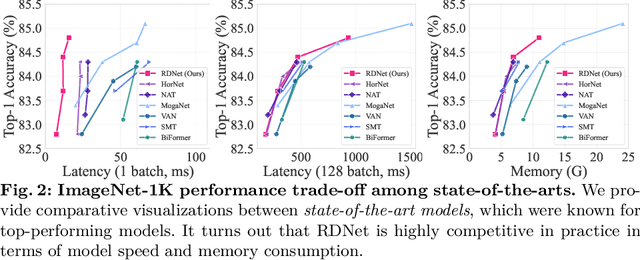
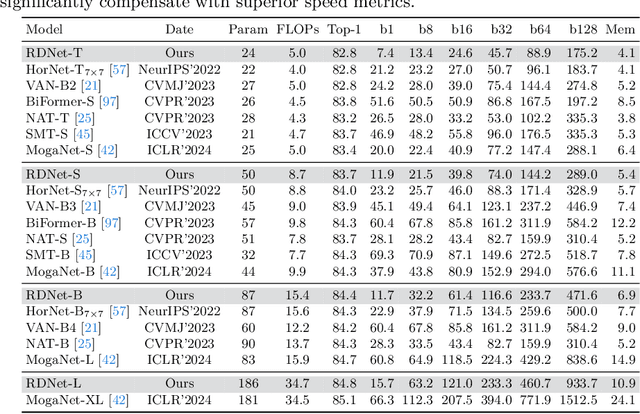
This paper revives Densely Connected Convolutional Networks (DenseNets) and reveals the underrated effectiveness over predominant ResNet-style architectures. We believe DenseNets' potential was overlooked due to untouched training methods and traditional design elements not fully revealing their capabilities. Our pilot study shows dense connections through concatenation are strong, demonstrating that DenseNets can be revitalized to compete with modern architectures. We methodically refine suboptimal components - architectural adjustments, block redesign, and improved training recipes towards widening DenseNets and boosting memory efficiency while keeping concatenation shortcuts. Our models, employing simple architectural elements, ultimately surpass Swin Transformer, ConvNeXt, and DeiT-III - key architectures in the residual learning lineage. Furthermore, our models exhibit near state-of-the-art performance on ImageNet-1K, competing with the very recent models and downstream tasks, ADE20k semantic segmentation, and COCO object detection/instance segmentation. Finally, we provide empirical analyses that uncover the merits of the concatenation over additive shortcuts, steering a renewed preference towards DenseNet-style designs. Our code is available at https://github.com/naver-ai/rdnet.
Ego-Motion Aware Target Prediction Module for Robust Multi-Object Tracking
Apr 03, 2024Multi-object tracking (MOT) is a prominent task in computer vision with application in autonomous driving, responsible for the simultaneous tracking of multiple object trajectories. Detection-based multi-object tracking (DBT) algorithms detect objects using an independent object detector and predict the imminent location of each target. Conventional prediction methods in DBT utilize Kalman Filter(KF) to extrapolate the target location in the upcoming frames by supposing a constant velocity motion model. These methods are especially hindered in autonomous driving applications due to dramatic camera motion or unavailable detections. Such limitations lead to tracking failures manifested by numerous identity switches and disrupted trajectories. In this paper, we introduce a novel KF-based prediction module called the Ego-motion Aware Target Prediction (EMAP) module by focusing on the integration of camera motion and depth information with object motion models. Our proposed method decouples the impact of camera rotational and translational velocity from the object trajectories by reformulating the Kalman Filter. This reformulation enables us to reject the disturbances caused by camera motion and maximizes the reliability of the object motion model. We integrate our module with four state-of-the-art base MOT algorithms, namely OC-SORT, Deep OC-SORT, ByteTrack, and BoT-SORT. In particular, our evaluation on the KITTI MOT dataset demonstrates that EMAP remarkably drops the number of identity switches (IDSW) of OC-SORT and Deep OC-SORT by 73% and 21%, respectively. At the same time, it elevates other performance metrics such as HOTA by more than 5%. Our source code is available at https://github.com/noyzzz/EMAP.
Edge Detection Quantumized: A Novel Quantum Algorithm For Image Processing
Apr 10, 2024Quantum image processing is a research field that explores the use of quantum computing and algorithms for image processing tasks such as image encoding and edge detection. Although classical edge detection algorithms perform reasonably well and are quite efficient, they become outright slower when it comes to large datasets with high-resolution images. Quantum computing promises to deliver a significant performance boost and breakthroughs in various sectors. Quantum Hadamard Edge Detection (QHED) algorithm, for example, works at constant time complexity, and thus detects edges much faster than any classical algorithm. However, the original QHED algorithm is designed for Quantum Probability Image Encoding (QPIE) and mainly works for binary images. This paper presents a novel protocol by combining the Flexible Representation of Quantum Images (FRQI) encoding and a modified QHED algorithm. An improved edge outline method has been proposed in this work resulting in a better object outline output and more accurate edge detection than the traditional QHED algorithm.
V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions
Mar 21, 2024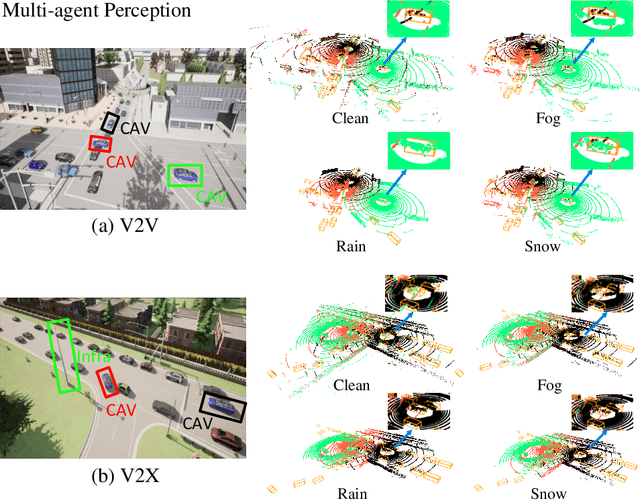
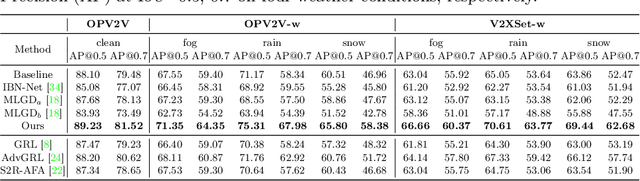
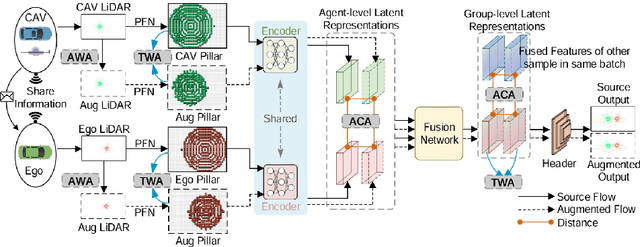
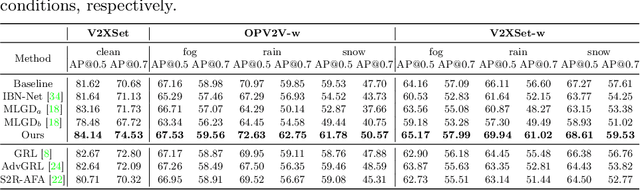
Current LiDAR-based Vehicle-to-Everything (V2X) multi-agent perception systems have shown the significant success on 3D object detection. While these models perform well in the trained clean weather, they struggle in unseen adverse weather conditions with the real-world domain gap. In this paper, we propose a domain generalization approach, named V2X-DGW, for LiDAR-based 3D object detection on multi-agent perception system under adverse weather conditions. Not only in the clean weather does our research aim to ensure favorable multi-agent performance, but also in the unseen adverse weather conditions by learning only on the clean weather data. To advance research in this area, we have simulated the impact of three prevalent adverse weather conditions on two widely-used multi-agent datasets, resulting in the creation of two novel benchmark datasets: OPV2V-w and V2XSet-w. To this end, we first introduce the Adaptive Weather Augmentation (AWA) to mimic the unseen adverse weather conditions, and then propose two alignments for generalizable representation learning: Trust-region Weather-invariant Alignment (TWA) and Agent-aware Contrastive Alignment (ACA). Extensive experimental results demonstrate that our V2X-DGW achieved improvements in the unseen adverse weather conditions.
A Simple yet Effective Network based on Vision Transformer for Camouflaged Object and Salient Object Detection
Feb 29, 2024Camouflaged object detection (COD) and salient object detection (SOD) are two distinct yet closely-related computer vision tasks widely studied during the past decades. Though sharing the same purpose of segmenting an image into binary foreground and background regions, their distinction lies in the fact that COD focuses on concealed objects hidden in the image, while SOD concentrates on the most prominent objects in the image. Previous works achieved good performance by stacking various hand-designed modules and multi-scale features. However, these carefully-designed complex networks often performed well on one task but not on another. In this work, we propose a simple yet effective network (SENet) based on vision Transformer (ViT), by employing a simple design of an asymmetric ViT-based encoder-decoder structure, we yield competitive results on both tasks, exhibiting greater versatility than meticulously crafted ones. Furthermore, to enhance the Transformer's ability to model local information, which is important for pixel-level binary segmentation tasks, we propose a local information capture module (LICM). We also propose a dynamic weighted loss (DW loss) based on Binary Cross-Entropy (BCE) and Intersection over Union (IoU) loss, which guides the network to pay more attention to those smaller and more difficult-to-find target objects according to their size. Moreover, we explore the issue of joint training of SOD and COD, and propose a preliminary solution to the conflict in joint training, further improving the performance of SOD. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of our method. The code is available at https://github.com/linuxsino/SENet.
VisionGPT: LLM-Assisted Real-Time Anomaly Detection for Safe Visual Navigation
Mar 19, 2024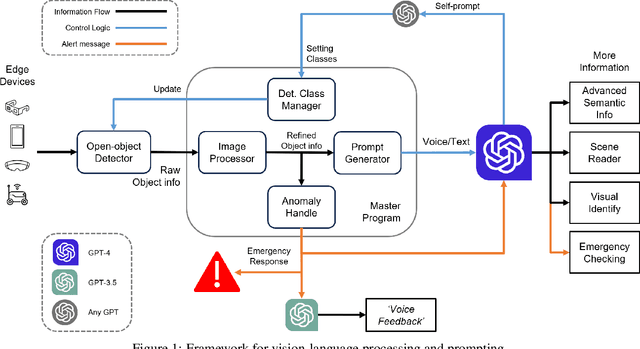
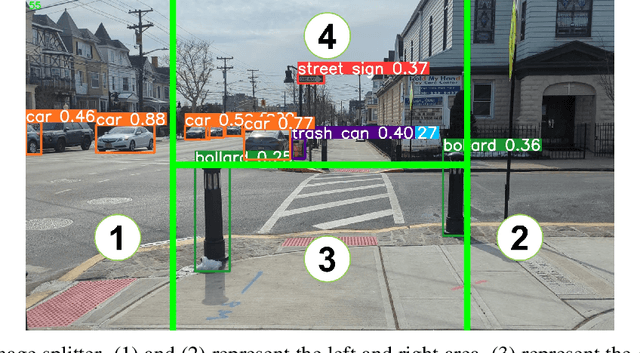

This paper explores the potential of Large Language Models(LLMs) in zero-shot anomaly detection for safe visual navigation. With the assistance of the state-of-the-art real-time open-world object detection model Yolo-World and specialized prompts, the proposed framework can identify anomalies within camera-captured frames that include any possible obstacles, then generate concise, audio-delivered descriptions emphasizing abnormalities, assist in safe visual navigation in complex circumstances. Moreover, our proposed framework leverages the advantages of LLMs and the open-vocabulary object detection model to achieve the dynamic scenario switch, which allows users to transition smoothly from scene to scene, which addresses the limitation of traditional visual navigation. Furthermore, this paper explored the performance contribution of different prompt components, provided the vision for future improvement in visual accessibility, and paved the way for LLMs in video anomaly detection and vision-language understanding.
Prototipo de un Contador Bidireccional Automático de Personas basado en sensores de visión 3D
Mar 18, 20243D sensors, also known as RGB-D sensors, utilize depth images where each pixel measures the distance from the camera to objects, using principles like structured light or time-of-flight. Advances in artificial vision have led to affordable 3D cameras capable of real-time object detection without object movement, surpassing 2D cameras in information depth. These cameras can identify objects of varying colors and reflectivities and are less affected by lighting changes. The described prototype uses RGB-D sensors for bidirectional people counting in venues, aiding security and surveillance in spaces like stadiums or airports. It determines real-time occupancy and checks against maximum capacity, crucial during emergencies. The system includes a RealSense D415 depth camera and a mini-computer running object detection algorithms to count people and a 2D camera for identity verification. The system supports statistical analysis and uses C++, Python, and PHP with OpenCV for image processing, demonstrating a comprehensive approach to monitoring venue occupancy.
State of the art applications of deep learning within tracking and detecting marine debris: A survey
Mar 26, 2024Deep learning techniques have been explored within the marine litter problem for approximately 20 years but the majority of the research has developed rapidly in the last five years. We provide an in-depth, up to date, summary and analysis of 28 of the most recent and significant contributions of deep learning in marine debris. From cross referencing the research paper results, the YOLO family significantly outperforms all other methods of object detection but there are many respected contributions to this field that have categorically agreed that a comprehensive database of underwater debris is not currently available for machine learning. Using a small dataset curated and labelled by us, we tested YOLOv5 on a binary classification task and found the accuracy was low and the rate of false positives was high; highlighting the importance of a comprehensive database. We conclude this survey with over 40 future research recommendations and open challenges.