 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TransReg: Cross-transformer as auto-registration module for multi-view mammogram mass detection
Nov 09, 2023
Screening mammography is the most widely used method for early breast cancer detection, significantly reducing mortality rates. The integration of information from multi-view mammograms enhances radiologists' confidence and diminishes false-positive rates since they can examine on dual-view of the same breast to cross-reference the existence and location of the lesion. Inspired by this, we present TransReg, a Computer-Aided Detection (CAD) system designed to exploit the relationship between craniocaudal (CC), and mediolateral oblique (MLO) views. The system includes cross-transformer to model the relationship between the region of interest (RoIs) extracted by siamese Faster RCNN network for mass detection problems. Our work is the first time cross-transformer has been integrated into an object detection framework to model the relation between ipsilateral views. Our experimental evaluation on DDSM and VinDr-Mammo datasets shows that our TransReg, equipped with SwinT as a feature extractor achieves state-of-the-art performance. Specifically, at the false positive rate per image at 0.5, TransReg using SwinT gets a recall at 83.3% for DDSM dataset and 79.7% for VinDr-Mammo dataset. Furthermore, we conduct a comprehensive analysis to demonstrate that cross-transformer can function as an auto-registration module, aligning the masses in dual-view and utilizing this information to inform final predictions. It is a replication diagnostic workflow of expert radiologists
Multiscale Neural Operators for Solving Time-Independent PDEs
Nov 10, 2023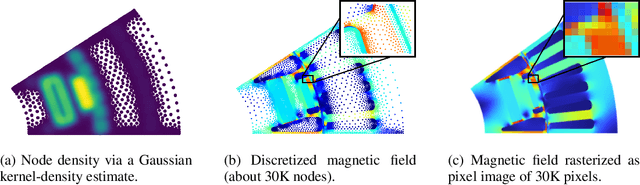
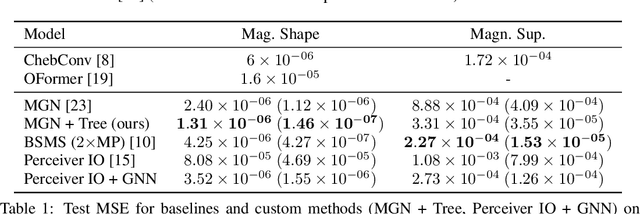
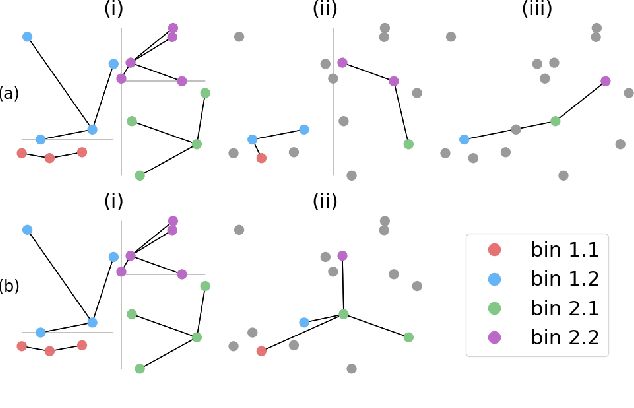

Time-independent Partial Differential Equations (PDEs) on large meshes pose significant challenges for data-driven neural PDE solvers. We introduce a novel graph rewiring technique to tackle some of these challenges, such as aggregating information across scales and on irregular meshes. Our proposed approach bridges distant nodes, enhancing the global interaction capabilities of GNNs. Our experiments on three datasets reveal that GNN-based methods set new performance standards for time-independent PDEs on irregular meshes. Finally, we show that our graph rewiring strategy boosts the performance of baseline methods, achieving state-of-the-art results in one of the tasks.
Multi-task Deep Convolutional Network to Predict Sea Ice Concentration and Drift in the Arctic Ocean
Oct 31, 2023Forecasting sea ice concentration (SIC) and sea ice drift (SID) in the Arctic Ocean is of great significance as the Arctic environment has been changed by the recent warming climate. Given that physical sea ice models require high computational costs with complex parameterization, deep learning techniques can effectively replace the physical model and improve the performance of sea ice prediction. This study proposes a novel multi-task fully conventional network architecture named hierarchical information-sharing U-net (HIS-Unet) to predict daily SIC and SID. Instead of learning SIC and SID separately at each branch, we allow the SIC and SID layers to share their information and assist each other's prediction through the weighting attention modules (WAMs). Consequently, our HIS-Unet outperforms other statistical approaches, sea ice physical models, and neural networks without such information-sharing units. The improvement of HIS-Unet is obvious both for SIC and SID prediction when and where sea ice conditions change seasonally, which implies that the information sharing through WAMs allows the model to learn the sudden changes of SIC and SID. The weight values of the WAMs imply that SIC information plays a more critical role in SID prediction, compared to that of SID information in SIC prediction, and information sharing is more active in sea ice edges (seasonal sea ice) than in the central Arctic (multi-year sea ice).
C-RITNet: Set Infrared and Visible Image Fusion Free from Complementary Information Mining
Sep 13, 2023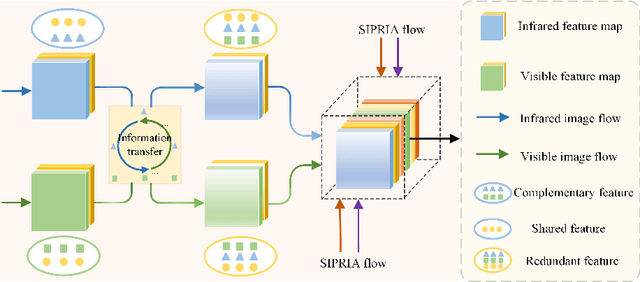

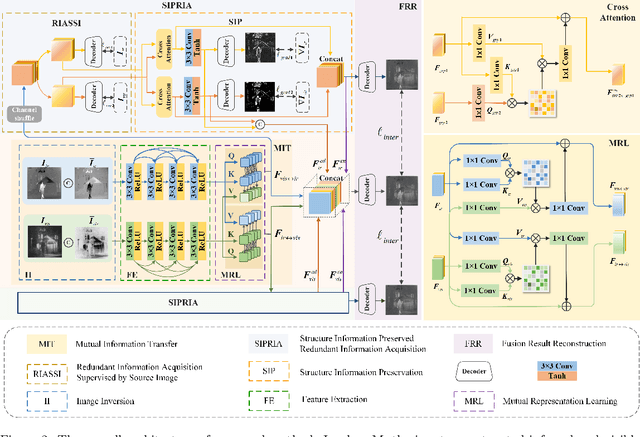
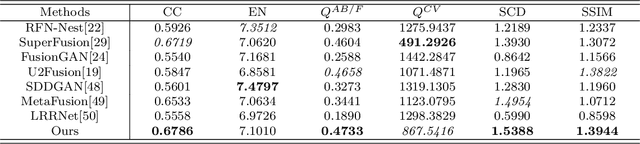
Infrared and visible image fusion (IVIF) aims to extract and integrate the complementary information in two different modalities to generate high-quality fused images with salient targets and abundant texture details. However, current image fusion methods go to great lengths to excavate complementary features, which is generally achieved through two efforts. On the one hand, the feature extraction network is expected to have excellent performance in extracting complementary information. On the other hand, complex fusion strategies are often designed to aggregate the complementary information. In other words, enabling the network to perceive and extract complementary information is extremely challenging. Complicated fusion strategies, while effective, still run the risk of losing weak edge details. To this end, this paper rethinks the IVIF outside the box, proposing a complementary-redundant information transfer network (C-RITNet). It reasonably transfers complementary information into redundant one, which integrates both the shared and complementary features from two modalities. Hence, the proposed method is able to alleviate the challenges posed by the complementary information extraction and reduce the reliance on sophisticated fusion strategies. Specifically, to skillfully sidestep aggregating complementary information in IVIF, we first design the mutual information transfer (MIT) module to mutually represent features from two modalities, roughly transferring complementary information into redundant one. Then, a redundant information acquisition supervised by source image (RIASSI) module is devised to further ensure the complementary-redundant information transfer after MIT. Meanwhile, we also propose a structure information preservation (SIP) module to guarantee that the edge structure information of the source images can be transferred to the fusion results.
Goal-Oriented Wireless Communication Resource Allocation for Cyber-Physical Systems
Nov 06, 2023The proliferation of novel industrial applications at the wireless edge, such as smart grids and vehicle networks, demands the advancement of cyber-physical systems. The performance of CPSs is closely linked to the last-mile wireless communication networks, which often become bottlenecks due to their inherent limited resources. Current CPS operations often treat wireless communication networks as unpredictable and uncontrollable variables, ignoring the potential adaptability of wireless networks, which results in inefficient and overly conservative CPS operations. Meanwhile, current wireless communications often focus more on throughput and other transmission-related metrics instead of CPS goals. In this study, we introduce the framework of goal-oriented wireless communication resource allocations, accounting for the semantics and significance of data for CPS operation goals. This guarantees optimal CPS performance from a cybernetic standpoint. We formulate a bandwidth allocation problem aimed at maximizing the information utility gain of transmitted data brought to CPS operation goals. Since the goal-oriented bandwidth allocation problem is a large-scale combinational problem, we propose a divide-and-conquer and greedy solution algorithm. The information utility gain is first approximately decomposed into marginal utility information gains and computed in a parallel manner. Subsequently, the bandwidth allocation problem is reformulated as a knapsack problem, which can be further solved greedily with a guaranteed sub-optimality gap. We further demonstrate how our proposed goal-oriented bandwidth allocation algorithm can be applied in four potential CPS applications, including data-driven decision-making, edge learning, federated learning, and distributed optimization.
Multi-view learning for automatic classification of multi-wavelength auroral images
Nov 06, 2023Auroral classification plays a crucial role in polar research. However, current auroral classification studies are predominantly based on images taken at a single wavelength, typically 557.7 nm. Images obtained at other wavelengths have been comparatively overlooked, and the integration of information from multiple wavelengths remains an underexplored area. This limitation results in low classification rates for complex auroral patterns. Furthermore, these studies, whether employing traditional machine learning or deep learning approaches, have not achieved a satisfactory trade-off between accuracy and speed. To address these challenges, this paper proposes a lightweight auroral multi-wavelength fusion classification network, MLCNet, based on a multi-view approach. Firstly, we develop a lightweight feature extraction backbone, called LCTNet, to improve the classification rate and cope with the increasing amount of auroral observation data. Secondly, considering the existence of multi-scale spatial structures in auroras, we design a novel multi-scale reconstructed feature module named MSRM. Finally, to highlight the discriminative information between auroral classes, we propose a lightweight attention feature enhancement module called LAFE. The proposed method is validated using observational data from the Arctic Yellow River Station during 2003-2004. Experimental results demonstrate that the fusion of multi-wavelength information effectively improves the auroral classification performance. In particular, our approach achieves state-of-the-art classification accuracy compared to previous auroral classification studies, and superior results in terms of accuracy and computational efficiency compared to existing multi-view methods.
Privacy-Aware Joint Source-Channel Coding for image transmission based on Disentangled Information Bottleneck
Sep 15, 2023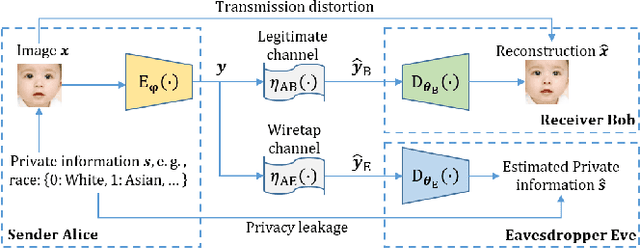
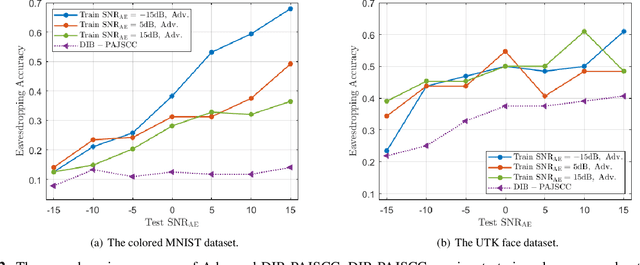

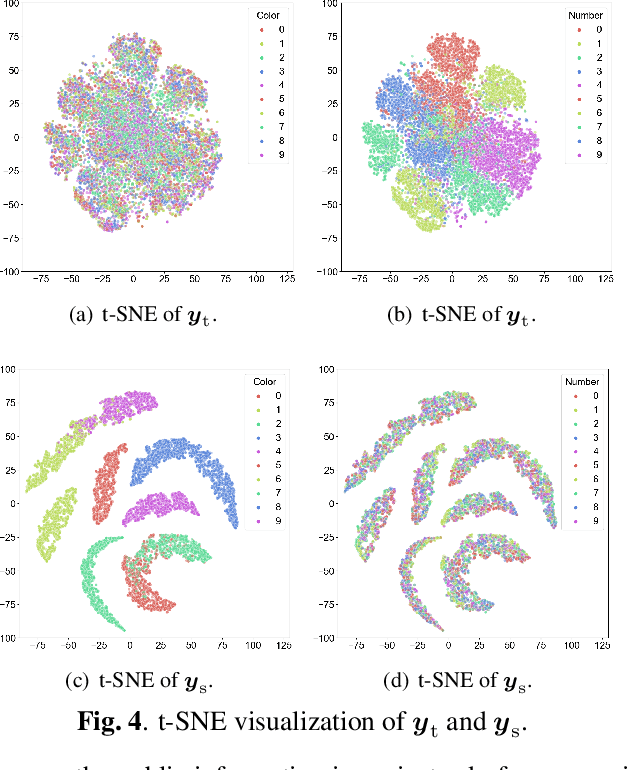
Current privacy-aware joint source-channel coding (JSCC) works aim at avoiding private information transmission by adversarially training the JSCC encoder and decoder under specific signal-to-noise ratios (SNRs) of eavesdroppers. However, these approaches incur additional computational and storage requirements as multiple neural networks must be trained for various eavesdroppers' SNRs to determine the transmitted information. To overcome this challenge, we propose a novel privacy-aware JSCC for image transmission based on disentangled information bottleneck (DIB-PAJSCC). In particular, we derive a novel disentangled information bottleneck objective to disentangle private and public information. Given the separate information, the transmitter can transmit only public information to the receiver while minimizing reconstruction distortion. Since DIB-PAJSCC transmits only public information regardless of the eavesdroppers' SNRs, it can eliminate additional training adapted to eavesdroppers' SNRs. Experimental results show that DIB-PAJSCC can reduce the eavesdropping accuracy on private information by up to 20\% compared to existing methods.
Contrastive Deep Nonnegative Matrix Factorization for Community Detection
Nov 04, 2023Recently, nonnegative matrix factorization (NMF) has been widely adopted for community detection, because of its better interpretability. However, the existing NMF-based methods have the following three problems: 1) they directly transform the original network into community membership space, so it is difficult for them to capture the hierarchical information; 2) they often only pay attention to the topology of the network and ignore its node attributes; 3) it is hard for them to learn the global structure information necessary for community detection. Therefore, we propose a new community detection algorithm, named Contrastive Deep Nonnegative Matrix Factorization (CDNMF). Firstly, we deepen NMF to strengthen its capacity for information extraction. Subsequently, inspired by contrastive learning, our algorithm creatively constructs network topology and node attributes as two contrasting views. Furthermore, we utilize a debiased negative sampling layer and learn node similarity at the community level, thereby enhancing the suitability of our model for community detection. We conduct experiments on three public real graph datasets and the proposed model has achieved better results than state-of-the-art methods. Code available at https://github.com/6lyc/CDNMF.git.
FloodBrain: Flood Disaster Reporting by Web-based Retrieval Augmented Generation with an LLM
Nov 05, 2023


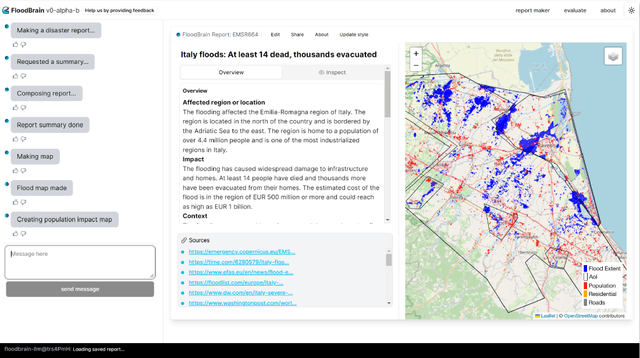
Fast disaster impact reporting is crucial in planning humanitarian assistance. Large Language Models (LLMs) are well known for their ability to write coherent text and fulfill a variety of tasks relevant to impact reporting, such as question answering or text summarization. However, LLMs are constrained by the knowledge within their training data and are prone to generating inaccurate, or "hallucinated", information. To address this, we introduce a sophisticated pipeline embodied in our tool FloodBrain (floodbrain.com), specialized in generating flood disaster impact reports by extracting and curating information from the web. Our pipeline assimilates information from web search results to produce detailed and accurate reports on flood events. We test different LLMs as backbones in our tool and compare their generated reports to human-written reports on different metrics. Similar to other studies, we find a notable correlation between the scores assigned by GPT-4 and the scores given by human evaluators when comparing our generated reports to human-authored ones. Additionally, we conduct an ablation study to test our single pipeline components and their relevancy for the final reports. With our tool, we aim to advance the use of LLMs for disaster impact reporting and reduce the time for coordination of humanitarian efforts in the wake of flood disasters.
Blending Reward Functions via Few Expert Demonstrations for Faithful and Accurate Knowledge-Grounded Dialogue Generation
Nov 02, 2023The development of trustworthy conversational information-seeking systems relies on dialogue models that can generate faithful and accurate responses based on relevant knowledge texts. However, two main challenges hinder this task. Firstly, language models may generate hallucinations due to data biases present in their pretraining corpus. Secondly, knowledge texts often contain redundant and irrelevant information that distracts the model's attention from the relevant text span. Previous works use additional data annotations on the knowledge texts to learn a knowledge identification module in order to bypass irrelevant information, but collecting such high-quality span annotations can be costly. In this work, we leverage reinforcement learning algorithms to overcome the above challenges by introducing a novel reward function. Our reward function combines an accuracy metric and a faithfulness metric to provide a balanced quality judgment of generated responses, which can be used as a cost-effective approximation to a human preference reward model when only a few preference annotations are available. Empirical experiments on two conversational information-seeking datasets demonstrate that our method can compete with other strong supervised learning baselines.