 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Generative Model for Accelerated Inverse Modelling Using a Novel Embedding for Continuous Variables
Nov 19, 2023

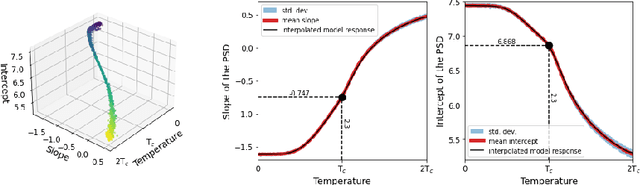
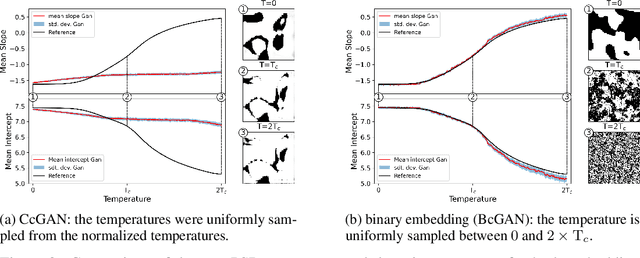
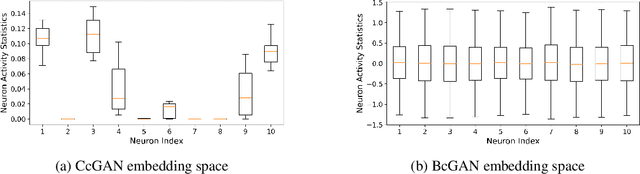
In materials science, the challenge of rapid prototyping materials with desired properties often involves extensive experimentation to find suitable microstructures. Additionally, finding microstructures for given properties is typically an ill-posed problem where multiple solutions may exist. Using generative machine learning models can be a viable solution which also reduces the computational cost. This comes with new challenges because, e.g., a continuous property variable as conditioning input to the model is required. We investigate the shortcomings of an existing method and compare this to a novel embedding strategy for generative models that is based on the binary representation of floating point numbers. This eliminates the need for normalization, preserves information, and creates a versatile embedding space for conditioning the generative model. This technique can be applied to condition a network on any number, to provide fine control over generated microstructure images, thereby contributing to accelerated materials design.
ShareGPT4V: Improving Large Multi-Modal Models with Better Captions
Nov 21, 2023In the realm of large multi-modal models (LMMs), efficient modality alignment is crucial yet often constrained by the scarcity of high-quality image-text data. To address this bottleneck, we introduce the ShareGPT4V dataset, a pioneering large-scale resource featuring 1.2 million highly descriptive captions, which surpasses existing datasets in diversity and information content, covering world knowledge, object properties, spatial relationships, and aesthetic evaluations. Specifically, ShareGPT4V originates from a curated 100K high-quality captions collected from advanced GPT4-Vision and has been expanded to 1.2M with a superb caption model trained on this subset. ShareGPT4V first demonstrates its effectiveness for the Supervised Fine-Tuning (SFT) phase, by substituting an equivalent quantity of detailed captions in existing SFT datasets with a subset of our high-quality captions, significantly enhancing the LMMs like LLaVA-7B, LLaVA-1.5-13B, and Qwen-VL-Chat-7B on the MME and MMBench benchmarks, with respective gains of 222.8/22.0/22.3 and 2.7/1.3/1.5. We further incorporate ShareGPT4V data into both the pre-training and SFT phases, obtaining ShareGPT4V-7B, a superior LMM based on a simple architecture that has remarkable performance across a majority of the multi-modal benchmarks. This project is available at https://ShareGPT4V.github.io to serve as a pivotal resource for advancing the LMMs community.
A unified consensus-based parallel ADMM algorithm for high-dimensional regression with combined regularizations
Nov 21, 2023
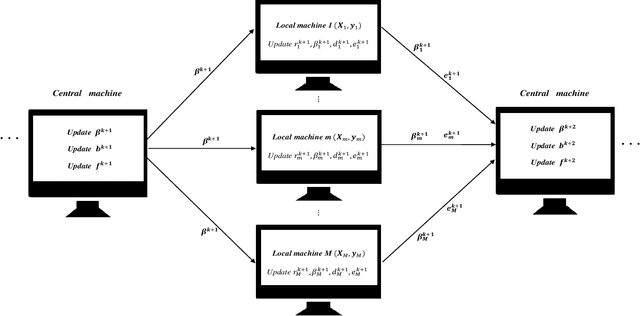

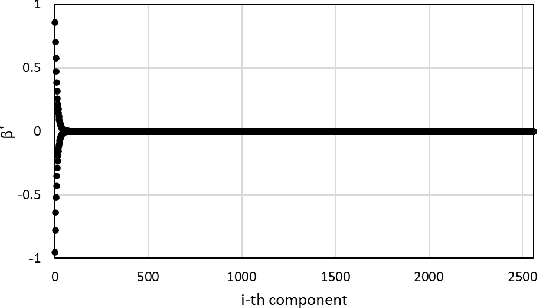
The parallel alternating direction method of multipliers (ADMM) algorithm is widely recognized for its effectiveness in handling large-scale datasets stored in a distributed manner, making it a popular choice for solving statistical learning models. However, there is currently limited research on parallel algorithms specifically designed for high-dimensional regression with combined (composite) regularization terms. These terms, such as elastic-net, sparse group lasso, sparse fused lasso, and their nonconvex variants, have gained significant attention in various fields due to their ability to incorporate prior information and promote sparsity within specific groups or fused variables. The scarcity of parallel algorithms for combined regularizations can be attributed to the inherent nonsmoothness and complexity of these terms, as well as the absence of closed-form solutions for certain proximal operators associated with them. In this paper, we propose a unified constrained optimization formulation based on the consensus problem for these types of convex and nonconvex regression problems and derive the corresponding parallel ADMM algorithms. Furthermore, we prove that the proposed algorithm not only has global convergence but also exhibits linear convergence rate. Extensive simulation experiments, along with a financial example, serve to demonstrate the reliability, stability, and scalability of our algorithm. The R package for implementing the proposed algorithms can be obtained at https://github.com/xfwu1016/CPADMM.
KNVQA: A Benchmark for evaluation knowledge-based VQA
Nov 21, 2023Within the multimodal field, large vision-language models (LVLMs) have made significant progress due to their strong perception and reasoning capabilities in the visual and language systems. However, LVLMs are still plagued by the two critical issues of object hallucination and factual accuracy, which limit the practicality of LVLMs in different scenarios. Furthermore, previous evaluation methods focus more on the comprehension and reasoning of language content but lack a comprehensive evaluation of multimodal interactions, thereby resulting in potential limitations. To this end, we propose a novel KNVQA-Eval, which is devoted to knowledge-based VQA task evaluation to reflect the factuality of multimodal LVLMs. To ensure the robustness and scalability of the evaluation, we develop a new KNVQA dataset by incorporating human judgment and perception, aiming to evaluate the accuracy of standard answers relative to AI-generated answers in knowledge-based VQA. This work not only comprehensively evaluates the contextual information of LVLMs using reliable human annotations, but also further analyzes the fine-grained capabilities of current methods to reveal potential avenues for subsequent optimization of LVLMs-based estimators. Our proposed VQA-Eval and corresponding dataset KNVQA will facilitate the development of automatic evaluation tools with the advantages of low cost, privacy protection, and reproducibility. Our code will be released upon publication.
Graph Neural Ordinary Differential Equations-based method for Collaborative Filtering
Nov 21, 2023Graph Convolution Networks (GCNs) are widely considered state-of-the-art for collaborative filtering. Although several GCN-based methods have been proposed and achieved state-of-the-art performance in various tasks, they can be computationally expensive and time-consuming to train if too many layers are created. However, since the linear GCN model can be interpreted as a differential equation, it is possible to transfer it to an ODE problem. This inspired us to address the computational limitations of GCN-based models by designing a simple and efficient NODE-based model that can skip some GCN layers to reach the final state, thus avoiding the need to create many layers. In this work, we propose a Graph Neural Ordinary Differential Equation-based method for Collaborative Filtering (GODE-CF). This method estimates the final embedding by utilizing the information captured by one or two GCN layers. To validate our approach, we conducted experiments on multiple datasets. The results demonstrate that our model outperforms competitive baselines, including GCN-based models and other state-of-the-art CF methods. Notably, our proposed GODE-CF model has several advantages over traditional GCN-based models. It is simple, efficient, and has a fast training time, making it a practical choice for real-world situations.
TouchSDF: A DeepSDF Approach for 3D Shape Reconstruction using Vision-Based Tactile Sensing
Nov 21, 2023Humans rely on their visual and tactile senses to develop a comprehensive 3D understanding of their physical environment. Recently, there has been a growing interest in exploring and manipulating objects using data-driven approaches that utilise high-resolution vision-based tactile sensors. However, 3D shape reconstruction using tactile sensing has lagged behind visual shape reconstruction because of limitations in existing techniques, including the inability to generalise over unseen shapes, the absence of real-world testing, and limited expressive capacity imposed by discrete representations. To address these challenges, we propose TouchSDF, a Deep Learning approach for tactile 3D shape reconstruction that leverages the rich information provided by a vision-based tactile sensor and the expressivity of the implicit neural representation DeepSDF. Our technique consists of two components: (1) a Convolutional Neural Network that maps tactile images into local meshes representing the surface at the touch location, and (2) an implicit neural function that predicts a signed distance function to extract the desired 3D shape. This combination allows TouchSDF to reconstruct smooth and continuous 3D shapes from tactile inputs in simulation and real-world settings, opening up research avenues for robust 3D-aware representations and improved multimodal perception in robotics. Code and supplementary material are available at: https://touchsdf.github.io/
HCA-Net: Hierarchical Context Attention Network for Intervertebral Disc Semantic Labeling
Nov 21, 2023Accurate and automated segmentation of intervertebral discs (IVDs) in medical images is crucial for assessing spine-related disorders, such as osteoporosis, vertebral fractures, or IVD herniation. We present HCA-Net, a novel contextual attention network architecture for semantic labeling of IVDs, with a special focus on exploiting prior geometric information. Our approach excels at processing features across different scales and effectively consolidating them to capture the intricate spatial relationships within the spinal cord. To achieve this, HCA-Net models IVD labeling as a pose estimation problem, aiming to minimize the discrepancy between each predicted IVD location and its corresponding actual joint location. In addition, we introduce a skeletal loss term to reinforce the model's geometric dependence on the spine. This loss function is designed to constrain the model's predictions to a range that matches the general structure of the human vertebral skeleton. As a result, the network learns to reduce the occurrence of false predictions and adaptively improves the accuracy of IVD location estimation. Through extensive experimental evaluation on multi-center spine datasets, our approach consistently outperforms previous state-of-the-art methods on both MRI T1w and T2w modalities. The codebase is accessible to the public on \href{https://github.com/xmindflow/HCA-Net}{GitHub}.
Wearable Technologies for Monitoring Upper Extremity Functions During Daily Life in Neurologically Impaired Individuals
Nov 21, 2023Neurological disorders, including stroke, spinal cord injuries, multiple sclerosis, and Parkinson's disease, generally lead to diminished upper extremity (UE) function, impacting individuals' independence and quality of life. Traditional assessments predominantly focus on standardized clinical tasks, offering limited insights into real-life UE performance. In this context, this review focuses on wearable technologies as a promising solution to monitor UE function in neurologically impaired individuals during daily life activities. Our primary objective is to categorize the different sensors, data collection and data processing approaches employed. What comes to light is that the majority of studies involved stroke survivors, and predominantly employed inertial measurement units and accelerometers to collect kinematics. Most analyses in these studies were performed offline, focusing on activity duration and frequency as key metrics. Although wearable technology shows potential in monitoring UE function in real-life scenarios, an ideal solution that combines non-intrusiveness, lightweight design, detailed hand and finger movement capture, contextual information, extended recording duration, ease of use, and privacy protection remains an elusive goal. Furthermore, it stands out a growing necessity for a multimodal approach in capturing comprehensive data on UE function during real-life activities to enhance the personalization of rehabilitation strategies and ultimately improve outcomes for these individuals.
HalluciDet: Hallucinating RGB Modality for Person Detection Through Privileged Information
Oct 07, 2023
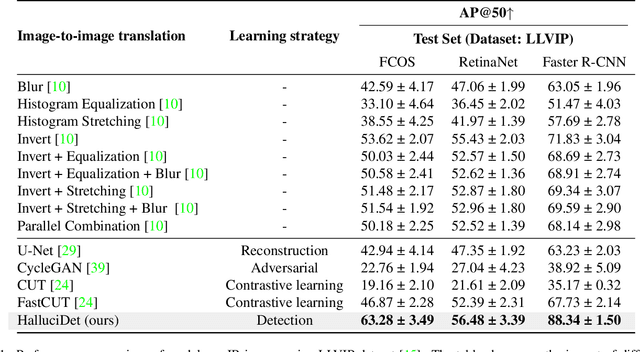
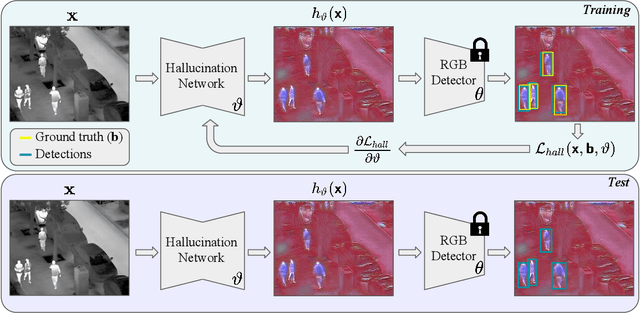
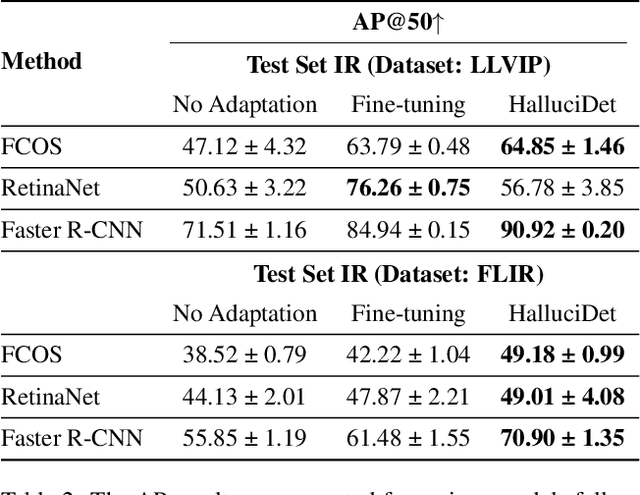
A powerful way to adapt a visual recognition model to a new domain is through image translation. However, common image translation approaches only focus on generating data from the same distribution of the target domain. In visual recognition tasks with complex images, such as pedestrian detection on aerial images with a large cross-modal shift in data distribution from Infrared (IR) to RGB images, a translation focused on generation might lead to poor performance as the loss focuses on irrelevant details for the task. In this paper, we propose HalluciDet, an IR-RGB image translation model for object detection that, instead of focusing on reconstructing the original image on the IR modality, is guided directly on reducing the detection loss of an RGB detector, and therefore avoids the need to access RGB data. This model produces a new image representation that enhances the object of interest in the scene and greatly improves detection performance. We empirically compare our approach against state-of-the-art image translation methods as well as with the commonly used fine-tuning on IR, and show that our method improves detection accuracy in most cases, by exploiting the privileged information encoded in a pre-trained RGB detector.
LLMRec: Large Language Models with Graph Augmentation for Recommendation
Nov 17, 2023
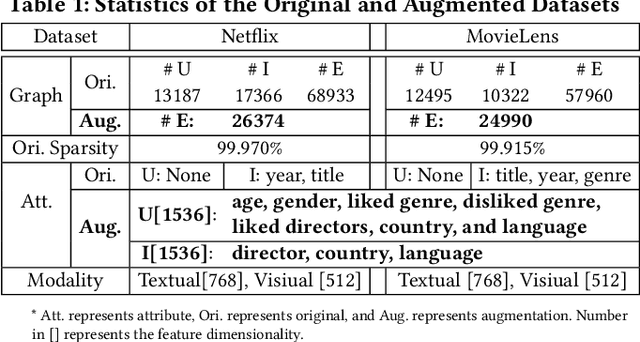
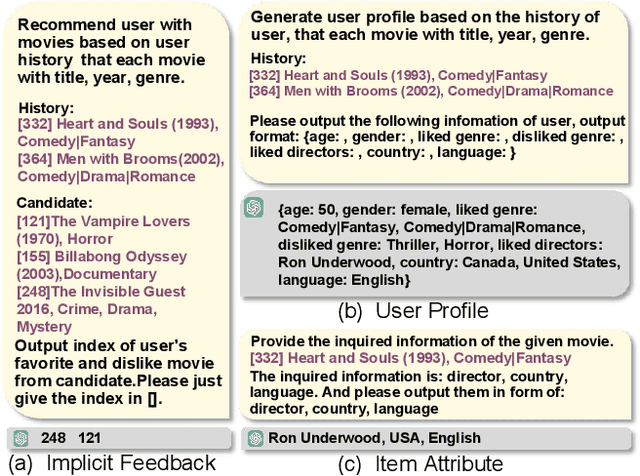
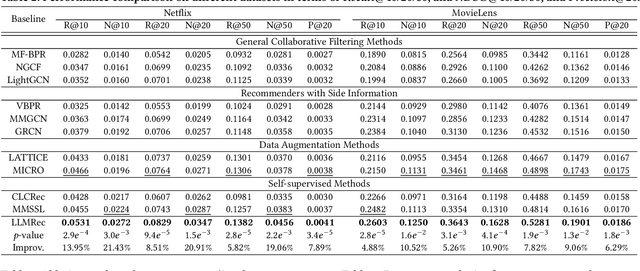
The problem of data sparsity has long been a challenge in recommendation systems, and previous studies have attempted to address this issue by incorporating side information. However, this approach often introduces side effects such as noise, availability issues, and low data quality, which in turn hinder the accurate modeling of user preferences and adversely impact recommendation performance. In light of the recent advancements in large language models (LLMs), which possess extensive knowledge bases and strong reasoning capabilities, we propose a novel framework called LLMRec that enhances recommender systems by employing three simple yet effective LLM-based graph augmentation strategies. Our approach leverages the rich content available within online platforms (e.g., Netflix, MovieLens) to augment the interaction graph in three ways: (i) reinforcing user-item interaction egde, (ii) enhancing the understanding of item node attributes, and (iii) conducting user node profiling, intuitively from the natural language perspective. By employing these strategies, we address the challenges posed by sparse implicit feedback and low-quality side information in recommenders. Besides, to ensure the quality of the augmentation, we develop a denoised data robustification mechanism that includes techniques of noisy implicit feedback pruning and MAE-based feature enhancement that help refine the augmented data and improve its reliability. Furthermore, we provide theoretical analysis to support the effectiveness of LLMRec and clarify the benefits of our method in facilitating model optimization. Experimental results on benchmark datasets demonstrate the superiority of our LLM-based augmentation approach over state-of-the-art techniques. To ensure reproducibility, we have made our code and augmented data publicly available at: https://github.com/HKUDS/LLMRec.git