 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HiFi-Syn: Hierarchical Granularity Discrimination for High-Fidelity Synthesis of MR Images with Structure Preservation
Nov 21, 2023
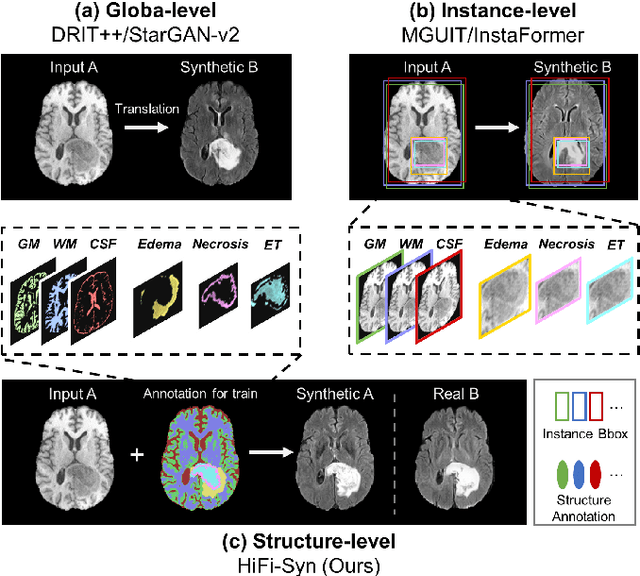

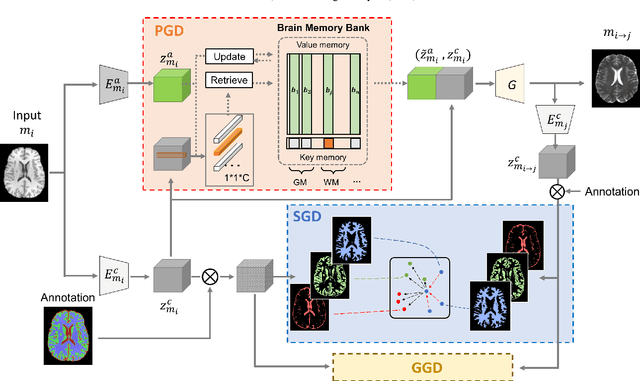

Synthesizing medical images while preserving their structural information is crucial in medical research. In such scenarios, the preservation of anatomical content becomes especially important. Although recent advances have been made by incorporating instance-level information to guide translation, these methods overlook the spatial coherence of structural-level representation and the anatomical invariance of content during translation. To address these issues, we introduce hierarchical granularity discrimination, which exploits various levels of semantic information present in medical images. Our strategy utilizes three levels of discrimination granularity: pixel-level discrimination using a Brain Memory Bank, structure-level discrimination on each brain structure with a re-weighting strategy to focus on hard samples, and global-level discrimination to ensure anatomical consistency during translation. The image translation performance of our strategy has been evaluated on three independent datasets (UK Biobank, IXI, and BraTS 2018), and it has outperformed state-of-the-art algorithms. Particularly, our model excels not only in synthesizing normal structures but also in handling abnormal (pathological) structures, such as brain tumors, despite the variations in contrast observed across different imaging modalities due to their pathological characteristics. The diagnostic value of synthesized MR images containing brain tumors has been evaluated by radiologists. This indicates that our model may offer an alternative solution in scenarios where specific MR modalities of patients are unavailable. Extensive experiments further demonstrate the versatility of our method, providing unique insights into medical image translation.
Attention: Large Multimodal Model is Watching your Geo-privacy
Nov 21, 2023Geographic privacy, a crucial aspect of personal security, often goes unnoticed in daily activities. This paper addresses the underestimation of this privacy in the context of increasing online data sharing and the advancements in information gathering technologies. With the surge in the use of Large Multimodal Models, such as GPT-4, for Open Source Intelligence (OSINT), the potential risks associated with geographic privacy breaches have intensified. This study highlights the criticality of these developments, focusing on their implications for individual privacy. The primary objective is to demonstrate the capabilities of advanced AI tools, specifically a GPT-4 based model named "Dr. Watson," in identifying and potentially compromising geographic privacy through online shared content. We developed "Dr. Watson" to analyze and extract geographic information from publicly available data sources. The study involved five experimental cases, each offering different perspectives on the tool's application in extracting precise location data from partial images and social media content. The experiments revealed that "Dr. Watson" could successfully identify specific geographic details, thereby exposing the vulnerabilities in current geo-privacy measures. These findings underscore the ease with which geographic information can be unintentionally disclosed. The paper concludes with a discussion on the broader implications of these findings for individuals and the community at large. It emphasizes the urgency for enhanced awareness and protective measures against geo-privacy leakage in the era of advanced AI and widespread social media usage.
LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models
Nov 30, 2023Large language models (LLMs) provide excellent text-generation capabilities, but standard prompting and generation methods generally do not lead to intentional or goal-directed agents and might necessitate considerable prompt tuning. This becomes particularly apparent in multi-turn conversations: even the best current LLMs rarely ask clarifying questions, engage in explicit information gathering, or take actions now that lead to better decisions after multiple turns. Reinforcement learning has the potential to leverage the powerful modeling capabilities of LLMs, as well as their internal representation of textual interactions, to create capable goal-directed language agents. This can enable intentional and temporally extended interactions, such as with humans, through coordinated persuasion and carefully crafted questions, or in goal-directed play through text games to bring about desired final outcomes. However, enabling this requires the community to develop stable and reliable reinforcement learning algorithms that can effectively train LLMs. Developing such algorithms requires tasks that can gauge progress on algorithm design, provide accessible and reproducible evaluations for multi-turn interactions, and cover a range of task properties and challenges in improving reinforcement learning algorithms. Our paper introduces the LMRL-Gym benchmark for evaluating multi-turn RL for LLMs, together with an open-source research framework containing a basic toolkit for getting started on multi-turn RL with offline value-based and policy-based RL methods. Our benchmark consists of 8 different language tasks, which require multiple rounds of language interaction and cover a range of tasks in open-ended dialogue and text games.
X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation
Nov 30, 2023In recent times, automatic text-to-3D content creation has made significant progress, driven by the development of pretrained 2D diffusion models. Existing text-to-3D methods typically optimize the 3D representation to ensure that the rendered image aligns well with the given text, as evaluated by the pretrained 2D diffusion model. Nevertheless, a substantial domain gap exists between 2D images and 3D assets, primarily attributed to variations in camera-related attributes and the exclusive presence of foreground objects. Consequently, employing 2D diffusion models directly for optimizing 3D representations may lead to suboptimal outcomes. To address this issue, we present X-Dreamer, a novel approach for high-quality text-to-3D content creation that effectively bridges the gap between text-to-2D and text-to-3D synthesis. The key components of X-Dreamer are two innovative designs: Camera-Guided Low-Rank Adaptation (CG-LoRA) and Attention-Mask Alignment (AMA) Loss. CG-LoRA dynamically incorporates camera information into the pretrained diffusion models by employing camera-dependent generation for trainable parameters. This integration enhances the alignment between the generated 3D assets and the camera's perspective. AMA loss guides the attention map of the pretrained diffusion model using the binary mask of the 3D object, prioritizing the creation of the foreground object. This module ensures that the model focuses on generating accurate and detailed foreground objects. Extensive evaluations demonstrate the effectiveness of our proposed method compared to existing text-to-3D approaches. Our project webpage: https://xmuxiaoma666.github.io/Projects/X-Dreamer .
Negotiated Representations to Prevent Forgetting in Machine Learning Applications
Nov 30, 2023Catastrophic forgetting is a significant challenge in the field of machine learning, particularly in neural networks. When a neural network learns to perform well on a new task, it often forgets its previously acquired knowledge or experiences. This phenomenon occurs because the network adjusts its weights and connections to minimize the loss on the new task, which can inadvertently overwrite or disrupt the representations that were crucial for the previous tasks. As a result, the the performance of the network on earlier tasks deteriorates, limiting its ability to learn and adapt to a sequence of tasks. In this paper, we propose a novel method for preventing catastrophic forgetting in machine learning applications, specifically focusing on neural networks. Our approach aims to preserve the knowledge of the network across multiple tasks while still allowing it to learn new information effectively. We demonstrate the effectiveness of our method by conducting experiments on various benchmark datasets, including Split MNIST, Split CIFAR10, Split Fashion MNIST, and Split CIFAR100. These datasets are created by dividing the original datasets into separate, non overlapping tasks, simulating a continual learning scenario where the model needs to learn multiple tasks sequentially without forgetting the previous ones. Our proposed method tackles the catastrophic forgetting problem by incorporating negotiated representations into the learning process, which allows the model to maintain a balance between retaining past experiences and adapting to new tasks. By evaluating our method on these challenging datasets, we aim to showcase its potential for addressing catastrophic forgetting and improving the performance of neural networks in continual learning settings.
System 2 Attention (is something you might need too)
Nov 20, 2023Soft attention in Transformer-based Large Language Models (LLMs) is susceptible to incorporating irrelevant information from the context into its latent representations, which adversely affects next token generations. To help rectify these issues, we introduce System 2 Attention (S2A), which leverages the ability of LLMs to reason in natural language and follow instructions in order to decide what to attend to. S2A regenerates the input context to only include the relevant portions, before attending to the regenerated context to elicit the final response. In experiments, S2A outperforms standard attention-based LLMs on three tasks containing opinion or irrelevant information, QA, math word problems and longform generation, where S2A increases factuality and objectivity, and decreases sycophancy.
FakeWatch ElectionShield: A Benchmarking Framework to Detect Fake News for Credible US Elections
Nov 27, 2023In today's technologically driven world, the spread of fake news, particularly during crucial events such as elections, presents an increasing challenge to the integrity of information. To address this challenge, we introduce FakeWatch ElectionShield, an innovative framework carefully designed to detect fake news. We have created a novel dataset of North American election-related news articles through a blend of advanced language models (LMs) and thorough human verification, for precision and relevance. We propose a model hub of LMs for identifying fake news. Our goal is to provide the research community with adaptable and accurate classification models in recognizing the dynamic nature of misinformation. Extensive evaluation of fake news classifiers on our dataset and a benchmark dataset shows our that while state-of-the-art LMs slightly outperform the traditional ML models, classical models are still competitive with their balance of accuracy, explainability, and computational efficiency. This research sets the foundation for future studies to address misinformation related to elections.
RelVAE: Generative Pretraining for few-shot Visual Relationship Detection
Nov 27, 2023Visual relations are complex, multimodal concepts that play an important role in the way humans perceive the world. As a result of their complexity, high-quality, diverse and large scale datasets for visual relations are still absent. In an attempt to overcome this data barrier, we choose to focus on the problem of few-shot Visual Relationship Detection (VRD), a setting that has been so far neglected by the community. In this work we present the first pretraining method for few-shot predicate classification that does not require any annotated relations. We achieve this by introducing a generative model that is able to capture the variation of semantic, visual and spatial information of relations inside a latent space and later exploiting its representations in order to achieve efficient few-shot classification. We construct few-shot training splits and show quantitative experiments on VG200 and VRD datasets where our model outperforms the baselines. Lastly we attempt to interpret the decisions of the model by conducting various qualitative experiments.
SOAC: Spatio-Temporal Overlap-Aware Multi-Sensor Calibration using Neural Radiance Fields
Nov 27, 2023In rapidly-evolving domains such as autonomous driving, the use of multiple sensors with different modalities is crucial to ensure high operational precision and stability. To correctly exploit the provided information by each sensor in a single common frame, it is essential for these sensors to be accurately calibrated. In this paper, we leverage the ability of Neural Radiance Fields (NeRF) to represent different sensors modalities in a common volumetric representation to achieve robust and accurate spatio-temporal sensor calibration. By designing a partitioning approach based on the visible part of the scene for each sensor, we formulate the calibration problem using only the overlapping areas. This strategy results in a more robust and accurate calibration that is less prone to failure. We demonstrate that our approach works on outdoor urban scenes by validating it on multiple established driving datasets. Results show that our method is able to get better accuracy and robustness compared to existing methods.
Streaming Lossless Volumetric Compression of Medical Images Using Gated Recurrent Convolutional Neural Network
Nov 27, 2023Deep learning-based lossless compression methods offer substantial advantages in compressing medical volumetric images. Nevertheless, many learning-based algorithms encounter a trade-off between practicality and compression performance. This paper introduces a hardware-friendly streaming lossless volumetric compression framework, utilizing merely one-thousandth of the model weights compared to other learning-based compression frameworks. We propose a gated recurrent convolutional neural network that combines diverse convolutional structures and fusion gate mechanisms to capture the inter-slice dependencies in volumetric images. Based on such contextual information, we can predict the pixel-by-pixel distribution for entropy coding. Guided by hardware/software co-design principles, we implement the proposed framework on Field Programmable Gate Array to achieve enhanced real-time performance. Extensive experimental results indicate that our method outperforms traditional lossless volumetric compressors and state-of-the-art learning-based lossless compression methods across various medical image benchmarks. Additionally, our method exhibits robust generalization ability and competitive compression speed