 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Peeking Inside the Schufa Blackbox: Explaining the German Housing Scoring System
Nov 22, 2023
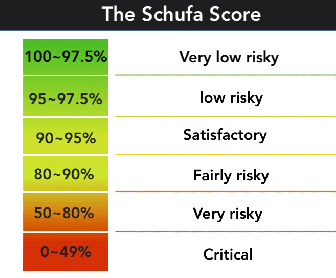

Explainable Artificial Intelligence is a concept aimed at making complex algorithms transparent to users through a uniform solution. Researchers have highlighted the importance of integrating domain specific contexts to develop explanations tailored to end users. In this study, we focus on the Schufa housing scoring system in Germany and investigate how users information needs and expectations for explanations vary based on their roles. Using the speculative design approach, we asked business information students to imagine user interfaces that provide housing credit score explanations from the perspectives of both tenants and landlords. Our preliminary findings suggest that although there are general needs that apply to all users, there are also conflicting needs that depend on the practical realities of their roles and how credit scores affect them. We contribute to Human centered XAI research by proposing future research directions that examine users explanatory needs considering their roles and agencies.
Explanatory Argument Extraction of Correct Answers in Resident Medical Exams
Dec 01, 2023Developing the required technology to assist medical experts in their everyday activities is currently a hot topic in the Artificial Intelligence research field. Thus, a number of large language models (LLMs) and automated benchmarks have recently been proposed with the aim of facilitating information extraction in Evidence-Based Medicine (EBM) using natural language as a tool for mediating in human-AI interaction. The most representative benchmarks are limited to either multiple-choice or long-form answers and are available only in English. In order to address these shortcomings, in this paper we present a new dataset which, unlike previous work: (i) includes not only explanatory arguments for the correct answer, but also arguments to reason why the incorrect answers are not correct; (ii) the explanations are written originally by medical doctors to answer questions from the Spanish Residency Medical Exams. Furthermore, this new benchmark allows us to setup a novel extractive task which consists of identifying the explanation of the correct answer written by medical doctors. An additional benefit of our setting is that we can leverage the extractive QA paradigm to automatically evaluate performance of LLMs without resorting to costly manual evaluation by medical experts. Comprehensive experimentation with language models for Spanish shows that sometimes multilingual models fare better than monolingual ones, even outperforming models which have been adapted to the medical domain. Furthermore, results across the monolingual models are mixed, with supposedly smaller and inferior models performing competitively. In any case, the obtained results show that our novel dataset and approach can be an effective technique to help medical practitioners in identifying relevant evidence-based explanations for medical questions.
Abstract Syntax Tree for Programming Language Understanding and Representation: How Far Are We?
Dec 01, 2023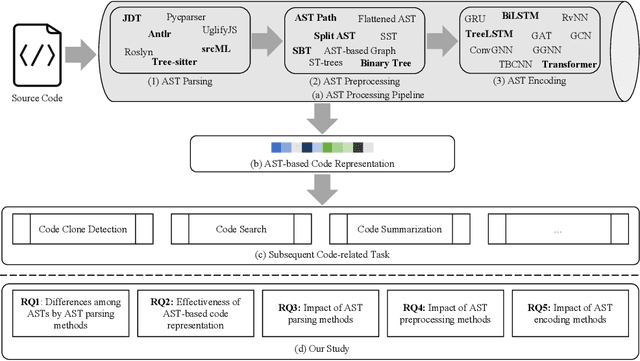


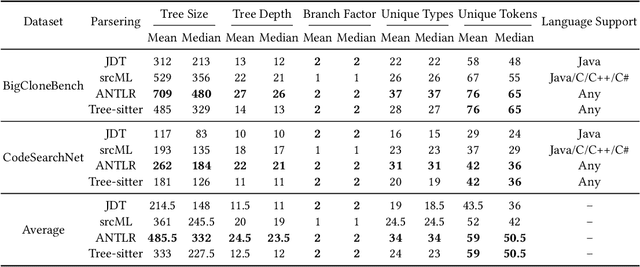
Programming language understanding and representation (a.k.a code representation learning) has always been a hot and challenging task in software engineering. It aims to apply deep learning techniques to produce numerical representations of the source code features while preserving its semantics. These representations can be used for facilitating subsequent code-related tasks. The abstract syntax tree (AST), a fundamental code feature, illustrates the syntactic information of the source code and has been widely used in code representation learning. However, there is still a lack of systematic and quantitative evaluation of how well AST-based code representation facilitates subsequent code-related tasks. In this paper, we first conduct a comprehensive empirical study to explore the effectiveness of the AST-based code representation in facilitating follow-up code-related tasks. To do so, we compare the performance of models trained with code token sequence (Token for short) based code representation and AST-based code representation on three popular types of code-related tasks. Surprisingly, the overall quantitative statistical results demonstrate that models trained with AST-based code representation consistently perform worse across all three tasks compared to models trained with Token-based code representation. Our further quantitative analysis reveals that models trained with AST-based code representation outperform models trained with Token-based code representation in certain subsets of samples across all three tasks. We also conduct comprehensive experiments to evaluate and reveal the impact of the choice of AST parsing/preprocessing/encoding methods on AST-based code representation and subsequent code-related tasks. Our study provides future researchers with detailed guidance on how to select solutions at each stage to fully exploit AST.
Manipulating the Label Space for In-Context Classification
Dec 01, 2023After pre-training by generating the next word conditional on previous words, the Language Model (LM) acquires the ability of In-Context Learning (ICL) that can learn a new task conditional on the context of the given in-context examples (ICEs). Similarly, visually-conditioned Language Modelling is also used to train Vision-Language Models (VLMs) with ICL ability. However, such VLMs typically exhibit weaker classification abilities compared to contrastive learning-based models like CLIP, since the Language Modelling objective does not directly contrast whether an object is paired with a text. To improve the ICL of classification, using more ICEs to provide more knowledge is a straightforward way. However, this may largely increase the selection time, and more importantly, the inclusion of additional in-context images tends to extend the length of the in-context sequence beyond the processing capacity of a VLM. To alleviate these limitations, we propose to manipulate the label space of each ICE to increase its knowledge density, allowing for fewer ICEs to convey as much information as a larger set would. Specifically, we propose two strategies which are Label Distribution Enhancement and Visual Descriptions Enhancement to improve In-context classification performance on diverse datasets, including the classic ImageNet and more fine-grained datasets like CUB-200. Specifically, using our approach on ImageNet, we increase accuracy from 74.70\% in a 4-shot setting to 76.21\% with just 2 shots. surpassing CLIP by 0.67\%. On CUB-200, our method raises 1-shot accuracy from 48.86\% to 69.05\%, 12.15\% higher than CLIP. The code is given in https://anonymous.4open.science/r/MLS_ICC.
General-Purpose vs. Domain-Adapted Large Language Models for Extraction of Data from Thoracic Radiology Reports
Dec 01, 2023Radiologists produce unstructured data that could be valuable for clinical care when consumed by information systems. However, variability in style limits usage. Study compares performance of system using domain-adapted language model (RadLing) and general-purpose large language model (GPT-4) in extracting common data elements (CDE) from thoracic radiology reports. Three radiologists annotated a retrospective dataset of 1300 thoracic reports (900 training, 400 test) and mapped to 21 pre-selected relevant CDEs. RadLing was used to generate embeddings for sentences and identify CDEs using cosine-similarity, which were mapped to values using light-weight mapper. GPT-4 system used OpenAI's general-purpose embeddings to identify relevant CDEs and used GPT-4 to map to values. The output CDE:value pairs were compared to the reference standard; an identical match was considered true positive. Precision (positive predictive value) was 96% (2700/2824) for RadLing and 99% (2034/2047) for GPT-4. Recall (sensitivity) was 94% (2700/2876) for RadLing and 70% (2034/2887) for GPT-4; the difference was statistically significant (P<.001). RadLing's domain-adapted embeddings were more sensitive in CDE identification (95% vs 71%) and its light-weight mapper had comparable precision in value assignment (95.4% vs 95.0%). RadLing system exhibited higher performance than GPT-4 system in extracting CDEs from radiology reports. RadLing system's domain-adapted embeddings outperform general-purpose embeddings from OpenAI in CDE identification and its light-weight value mapper achieves comparable precision to large GPT-4. RadLing system offers operational advantages including local deployment and reduced runtime costs. Domain-adapted RadLing system surpasses GPT-4 system in extracting common data elements from radiology reports, while providing benefits of local deployment and lower costs.
Target-Free Compound Activity Prediction via Few-Shot Learning
Nov 27, 2023Predicting the activities of compounds against protein-based or phenotypic assays using only a few known compounds and their activities is a common task in target-free drug discovery. Existing few-shot learning approaches are limited to predicting binary labels (active/inactive). However, in real-world drug discovery, degrees of compound activity are highly relevant. We study Few-Shot Compound Activity Prediction (FS-CAP) and design a novel neural architecture to meta-learn continuous compound activities across large bioactivity datasets. Our model aggregates encodings generated from the known compounds and their activities to capture assay information. We also introduce a separate encoder for the unknown compound. We show that FS-CAP surpasses traditional similarity-based techniques as well as other state of the art few-shot learning methods on a variety of target-free drug discovery settings and datasets.
Over-Squashing in Riemannian Graph Neural Networks
Nov 27, 2023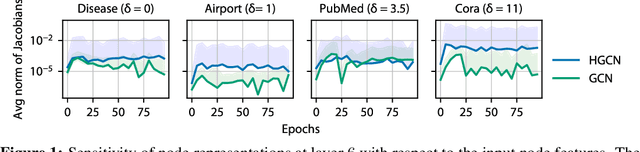
Most graph neural networks (GNNs) are prone to the phenomenon of over-squashing in which node features become insensitive to information from distant nodes in the graph. Recent works have shown that the topology of the graph has the greatest impact on over-squashing, suggesting graph rewiring approaches as a suitable solution. In this work, we explore whether over-squashing can be mitigated through the embedding space of the GNN. In particular, we consider the generalization of Hyperbolic GNNs (HGNNs) to Riemannian manifolds of variable curvature in which the geometry of the embedding space is faithful to the graph's topology. We derive bounds on the sensitivity of the node features in these Riemannian GNNs as the number of layers increases, which yield promising theoretical and empirical results for alleviating over-squashing in graphs with negative curvature.
Research on Joint Representation Learning Methods for Entity Neighborhood Information and Description Information
Sep 15, 2023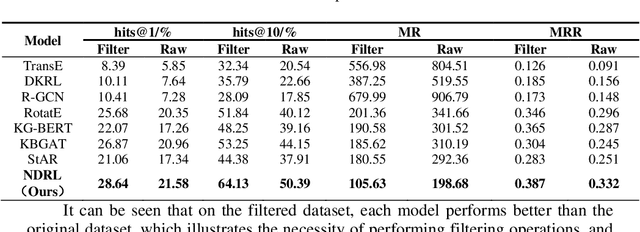
To address the issue of poor embedding performance in the knowledge graph of a programming design course, a joint represen-tation learning model that combines entity neighborhood infor-mation and description information is proposed. Firstly, a graph at-tention network is employed to obtain the features of entity neigh-boring nodes, incorporating relationship features to enrich the structural information. Next, the BERT-WWM model is utilized in conjunction with attention mechanisms to obtain the representation of entity description information. Finally, the final entity vector representation is obtained by combining the vector representations of entity neighborhood information and description information. Experimental results demonstrate that the proposed model achieves favorable performance on the knowledge graph dataset of the pro-gramming design course, outperforming other baseline models.
Improving Cross-dataset Deepfake Detection with Deep Information Decomposition
Sep 30, 2023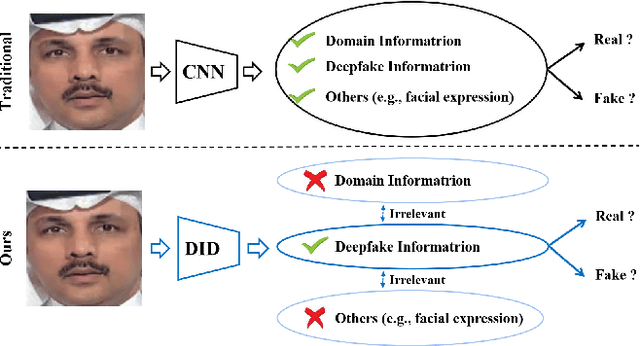
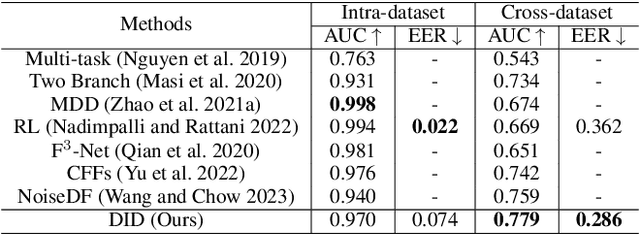
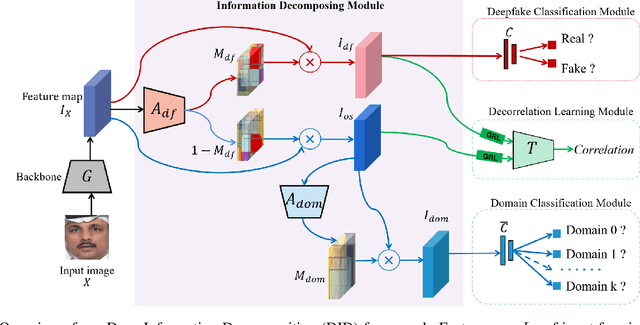
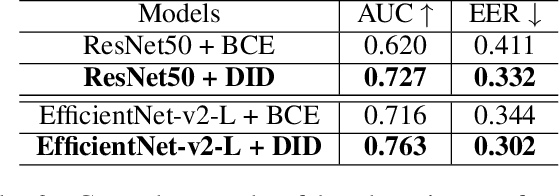
Deepfake technology poses a significant threat to security and social trust. Although existing detection methods have demonstrated high performance in identifying forgeries within datasets using the same techniques for training and testing, they suffer from sharp performance degradation when faced with cross-dataset scenarios where unseen deepfake techniques are tested. To address this challenge, we propose a deep information decomposition (DID) framework in this paper. Unlike most existing deepfake detection methods, our framework prioritizes high-level semantic features over visual artifacts. Specifically, it decomposes facial features into deepfake-related and irrelevant information and optimizes the deepfake information for real/fake discrimination to be independent of other factors. Our approach improves the robustness of deepfake detection against various irrelevant information changes and enhances the generalization ability of the framework to detect unseen forgery methods. Extensive experimental comparisons with existing state-of-the-art detection methods validate the effectiveness and superiority of the DID framework on cross-dataset deepfake detection.
Performance Analysis of Integrated Sensing and Communications Under Gain-Phase Imperfections
Nov 30, 2023This paper evaluates the performance of uplink integrated sensing and communication systems in the presence of gain and phase imperfections. Specifically, we consider multiple unmanned aerial vehicles (UAVs) transmitting data to a multiple-input-multiple-output base-station (BS) that is responsible for estimating the transmitted information in addition to localising the transmitting UAVs. The signal processing at the BS is divided into two consecutive stages: localisation and communication. A maximum likelihood (ML) algorithm is introduced for the localisation stage to jointly estimate the azimuth-elevation angles and Doppler frequency of the UAVs under gain-phase defects, which are then compared to the estimation of signal parameters via rotational invariance techniques (ESPRIT) and multiple signal classification (MUSIC). Furthermore, the Cramer-Rao lower bound (CRLB) is derived to evaluate the asymptotic performance and quantify the influence of the gain-phase imperfections which are modelled using Rician and von Mises distributions, respectively. Thereafter, in the communication stage, the location parameters estimated in the first stage are employed to estimate the communication channels which are fed into a maximum ratio combiner to preprocess the received communication signal. An accurate closed-form approximation of the achievable average sum data rate (SDR) for all UAVs is derived. The obtained results show that gain-phase imperfections have a significant influence on both localisation and communication, however, the proposed ML is less sensitive when compared to other algorithms. The derived analysis is concurred with simulations.