 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Explanations: Towards Explainable Fake Review Detection Focusing on Transformers
Jul 24, 2024



Customers' reviews and feedback play crucial role on electronic commerce~(E-commerce) platforms like Amazon, Zalando, and eBay in influencing other customers' purchasing decisions. However, there is a prevailing concern that sellers often post fake or spam reviews to deceive potential customers and manipulate their opinions about a product. Over the past decade, there has been considerable interest in using machine learning (ML) and deep learning (DL) models to identify such fraudulent reviews. Unfortunately, the decisions made by complex ML and DL models - which often function as \emph{black-boxes} - can be surprising and difficult for general users to comprehend. In this paper, we propose an explainable framework for detecting fake reviews with high precision in identifying fraudulent content with explanations and investigate what information matters most for explaining particular decisions by conducting empirical user evaluation. Initially, we develop fake review detection models using DL and transformer models including XLNet and DistilBERT. We then introduce layer-wise relevance propagation (LRP) technique for generating explanations that can map the contributions of words toward the predicted class. The experimental results on two benchmark fake review detection datasets demonstrate that our predictive models achieve state-of-the-art performance and outperform several existing methods. Furthermore, the empirical user evaluation of the generated explanations concludes which important information needs to be considered in generating explanations in the context of fake review identification.
Explaining AI Decisions: Towards Achieving Human-Centered Explainability in Smart Home Environments
Apr 23, 2024Smart home systems are gaining popularity as homeowners strive to enhance their living and working environments while minimizing energy consumption. However, the adoption of artificial intelligence (AI)-enabled decision-making models in smart home systems faces challenges due to the complexity and black-box nature of these systems, leading to concerns about explainability, trust, transparency, accountability, and fairness. The emerging field of explainable artificial intelligence (XAI) addresses these issues by providing explanations for the models' decisions and actions. While state-of-the-art XAI methods are beneficial for AI developers and practitioners, they may not be easily understood by general users, particularly household members. This paper advocates for human-centered XAI methods, emphasizing the importance of delivering readily comprehensible explanations to enhance user satisfaction and drive the adoption of smart home systems. We review state-of-the-art XAI methods and prior studies focusing on human-centered explanations for general users in the context of smart home applications. Through experiments on two smart home application scenarios, we demonstrate that explanations generated by prominent XAI techniques might not be effective in helping users understand and make decisions. We thus argue for the necessity of a human-centric approach in representing explanations in smart home systems and highlight relevant human-computer interaction (HCI) methodologies, including user studies, prototyping, technology probes analysis, and heuristic evaluation, that can be employed to generate and present human-centered explanations to users.
Peeking Inside the Schufa Blackbox: Explaining the German Housing Scoring System
Nov 22, 2023

Explainable Artificial Intelligence is a concept aimed at making complex algorithms transparent to users through a uniform solution. Researchers have highlighted the importance of integrating domain specific contexts to develop explanations tailored to end users. In this study, we focus on the Schufa housing scoring system in Germany and investigate how users information needs and expectations for explanations vary based on their roles. Using the speculative design approach, we asked business information students to imagine user interfaces that provide housing credit score explanations from the perspectives of both tenants and landlords. Our preliminary findings suggest that although there are general needs that apply to all users, there are also conflicting needs that depend on the practical realities of their roles and how credit scores affect them. We contribute to Human centered XAI research by proposing future research directions that examine users explanatory needs considering their roles and agencies.
Unveiling Black-boxes: Explainable Deep Learning Models for Patent Classification
Oct 31, 2023Recent technological advancements have led to a large number of patents in a diverse range of domains, making it challenging for human experts to analyze and manage. State-of-the-art methods for multi-label patent classification rely on deep neural networks (DNNs), which are complex and often considered black-boxes due to their opaque decision-making processes. In this paper, we propose a novel deep explainable patent classification framework by introducing layer-wise relevance propagation (LRP) to provide human-understandable explanations for predictions. We train several DNN models, including Bi-LSTM, CNN, and CNN-BiLSTM, and propagate the predictions backward from the output layer up to the input layer of the model to identify the relevance of words for individual predictions. Considering the relevance score, we then generate explanations by visualizing relevant words for the predicted patent class. Experimental results on two datasets comprising two-million patent texts demonstrate high performance in terms of various evaluation measures. The explanations generated for each prediction highlight important relevant words that align with the predicted class, making the prediction more understandable. Explainable systems have the potential to facilitate the adoption of complex AI-enabled methods for patent classification in real-world applications.
From Large Language Models to Knowledge Graphs for Biomarker Discovery in Cancer
Oct 12, 2023



Domain experts often rely on up-to-date knowledge for apprehending and disseminating specific biological processes that help them design strategies to develop prevention and therapeutic decision-making. A challenging scenario for artificial intelligence (AI) is using biomedical data (e.g., texts, imaging, omics, and clinical) to provide diagnosis and treatment recommendations for cancerous conditions. Data and knowledge about cancer, drugs, genes, proteins, and their mechanism is spread across structured (knowledge bases (KBs)) and unstructured (e.g., scientific articles) sources. A large-scale knowledge graph (KG) can be constructed by integrating these data, followed by extracting facts about semantically interrelated entities and relations. Such KGs not only allow exploration and question answering (QA) but also allow domain experts to deduce new knowledge. However, exploring and querying large-scale KGs is tedious for non-domain users due to a lack of understanding of the underlying data assets and semantic technologies. In this paper, we develop a domain KG to leverage cancer-specific biomarker discovery and interactive QA. For this, a domain ontology called OncoNet Ontology (ONO) is developed to enable semantic reasoning for validating gene-disease relations. The KG is then enriched by harmonizing the ONO, controlled vocabularies, and additional biomedical concepts from scientific articles by employing BioBERT- and SciBERT-based information extraction (IE) methods. Further, since the biomedical domain is evolving, where new findings often replace old ones, without employing up-to-date findings, there is a high chance an AI system exhibits concept drift while providing diagnosis and treatment. Therefore, we finetuned the KG using large language models (LLMs) based on more recent articles and KBs that might not have been seen by the named entity recognition models.
Arabic Sentiment Analysis with Noisy Deep Explainable Model
Sep 24, 2023



Sentiment Analysis (SA) is an indispensable task for many real-world applications. Compared to limited resourced languages (i.e., Arabic, Bengali), most of the research on SA are conducted for high resourced languages (i.e., English, Chinese). Moreover, the reasons behind any prediction of the Arabic sentiment analysis methods exploiting advanced artificial intelligence (AI)-based approaches are like black-box - quite difficult to understand. This paper proposes an explainable sentiment classification framework for the Arabic language by introducing a noise layer on Bi-Directional Long Short-Term Memory (BiLSTM) and Convolutional Neural Networks (CNN)-BiLSTM models that overcome over-fitting problem. The proposed framework can explain specific predictions by training a local surrogate explainable model to understand why a particular sentiment (positive or negative) is being predicted. We carried out experiments on public benchmark Arabic SA datasets. The results concluded that adding noise layers improves the performance in sentiment analysis for the Arabic language by reducing overfitting and our method outperformed some known state-of-the-art methods. In addition, the introduced explainability with noise layer could make the model more transparent and accountable and hence help adopting AI-enabled system in practice.
Textual Entailment Recognition with Semantic Features from Empirical Text Representation
Oct 18, 2022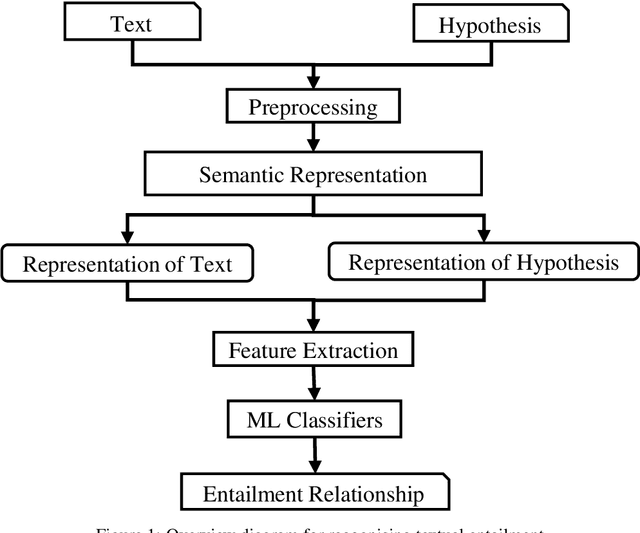
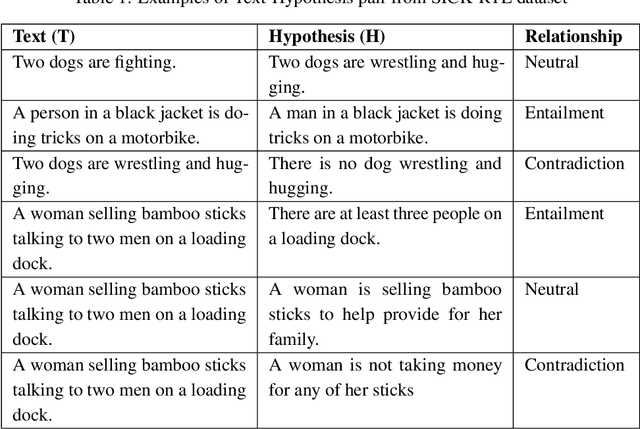

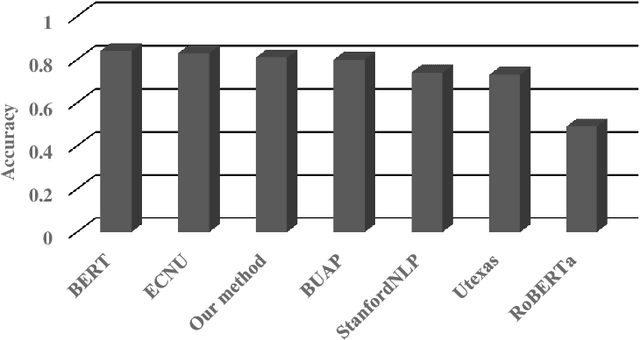
Textual entailment recognition is one of the basic natural language understanding(NLU) tasks. Understanding the meaning of sentences is a prerequisite before applying any natural language processing(NLP) techniques to automatically recognize the textual entailment. A text entails a hypothesis if and only if the true value of the hypothesis follows the text. Classical approaches generally utilize the feature value of each word from word embedding to represent the sentences. In this paper, we propose a novel approach to identifying the textual entailment relationship between text and hypothesis, thereby introducing a new semantic feature focusing on empirical threshold-based semantic text representation. We employ an element-wise Manhattan distance vector-based feature that can identify the semantic entailment relationship between the text-hypothesis pair. We carried out several experiments on a benchmark entailment classification(SICK-RTE) dataset. We train several machine learning(ML) algorithms applying both semantic and lexical features to classify the text-hypothesis pair as entailment, neutral, or contradiction. Our empirical sentence representation technique enriches the semantic information of the texts and hypotheses found to be more efficient than the classical ones. In the end, our approach significantly outperforms known methods in understanding the meaning of the sentences for the textual entailment classification task.