 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVE-LLM : Ontology-Assisted Automatic Vulnerability Evaluation Using Large Language Models
Feb 21, 2025



The National Vulnerability Database (NVD) publishes over a thousand new vulnerabilities monthly, with a projected 25 percent increase in 2024, highlighting the crucial need for rapid vulnerability identification to mitigate cybersecurity attacks and save costs and resources. In this work, we propose using large language models (LLMs) to learn vulnerability evaluation from historical assessments of medical device vulnerabilities in a single manufacturer's portfolio. We highlight the effectiveness and challenges of using LLMs for automatic vulnerability evaluation and introduce a method to enrich historical data with cybersecurity ontologies, enabling the system to understand new vulnerabilities without retraining the LLM. Our LLM system integrates with the in-house application - Cybersecurity Management System (CSMS) - to help Siemens Healthineers (SHS) product cybersecurity experts efficiently assess the vulnerabilities in our products. Also, we present guidelines for efficient integration of LLMs into the cybersecurity tool.
CVE-LLM : Automatic vulnerability evaluation in medical device industry using large language models
Jul 19, 2024



The healthcare industry is currently experiencing an unprecedented wave of cybersecurity attacks, impacting millions of individuals. With the discovery of thousands of vulnerabilities each month, there is a pressing need to drive the automation of vulnerability assessment processes for medical devices, facilitating rapid mitigation efforts. Generative AI systems have revolutionized various industries, offering unparalleled opportunities for automation and increased efficiency. This paper presents a solution leveraging Large Language Models (LLMs) to learn from historical evaluations of vulnerabilities for the automatic assessment of vulnerabilities in the medical devices industry. This approach is applied within the portfolio of a single manufacturer, taking into account device characteristics, including existing security posture and controls. The primary contributions of this paper are threefold. Firstly, it provides a detailed examination of the best practices for training a vulnerability Language Model (LM) in an industrial context. Secondly, it presents a comprehensive comparison and insightful analysis of the effectiveness of Language Models in vulnerability assessment. Finally, it proposes a new human-in-the-loop framework to expedite vulnerability evaluation processes.
General-Purpose vs. Domain-Adapted Large Language Models for Extraction of Data from Thoracic Radiology Reports
Dec 01, 2023



Radiologists produce unstructured data that could be valuable for clinical care when consumed by information systems. However, variability in style limits usage. Study compares performance of system using domain-adapted language model (RadLing) and general-purpose large language model (GPT-4) in extracting common data elements (CDE) from thoracic radiology reports. Three radiologists annotated a retrospective dataset of 1300 thoracic reports (900 training, 400 test) and mapped to 21 pre-selected relevant CDEs. RadLing was used to generate embeddings for sentences and identify CDEs using cosine-similarity, which were mapped to values using light-weight mapper. GPT-4 system used OpenAI's general-purpose embeddings to identify relevant CDEs and used GPT-4 to map to values. The output CDE:value pairs were compared to the reference standard; an identical match was considered true positive. Precision (positive predictive value) was 96% (2700/2824) for RadLing and 99% (2034/2047) for GPT-4. Recall (sensitivity) was 94% (2700/2876) for RadLing and 70% (2034/2887) for GPT-4; the difference was statistically significant (P<.001). RadLing's domain-adapted embeddings were more sensitive in CDE identification (95% vs 71%) and its light-weight mapper had comparable precision in value assignment (95.4% vs 95.0%). RadLing system exhibited higher performance than GPT-4 system in extracting CDEs from radiology reports. RadLing system's domain-adapted embeddings outperform general-purpose embeddings from OpenAI in CDE identification and its light-weight value mapper achieves comparable precision to large GPT-4. RadLing system offers operational advantages including local deployment and reduced runtime costs. Domain-adapted RadLing system surpasses GPT-4 system in extracting common data elements from radiology reports, while providing benefits of local deployment and lower costs.
shs-nlp at RadSum23: Domain-Adaptive Pre-training of Instruction-tuned LLMs for Radiology Report Impression Generation
Jun 05, 2023



Instruction-tuned generative Large language models (LLMs) like ChatGPT and Bloomz possess excellent generalization abilities, but they face limitations in understanding radiology reports, particularly in the task of generating the IMPRESSIONS section from the FINDINGS section. They tend to generate either verbose or incomplete IMPRESSIONS, mainly due to insufficient exposure to medical text data during training. We present a system which leverages large-scale medical text data for domain-adaptive pre-training of instruction-tuned LLMs to enhance its medical knowledge and performance on specific medical tasks. We show that this system performs better in a zero-shot setting than a number of pretrain-and-finetune adaptation methods on the IMPRESSIONS generation task, and ranks 1st among participating systems in Task 1B: Radiology Report Summarization at the BioNLP 2023 workshop.
* 1st Place in Task 1B: Radiology Report Summarization at BioNLP 2023
RadLing: Towards Efficient Radiology Report Understanding
Jun 04, 2023



Most natural language tasks in the radiology domain use language models pre-trained on biomedical corpus. There are few pretrained language models trained specifically for radiology, and fewer still that have been trained in a low data setting and gone on to produce comparable results in fine-tuning tasks. We present RadLing, a continuously pretrained language model using Electra-small (Clark et al., 2020) architecture, trained using over 500K radiology reports, that can compete with state-of-the-art results for fine tuning tasks in radiology domain. Our main contribution in this paper is knowledge-aware masking which is a taxonomic knowledge-assisted pretraining task that dynamically masks tokens to inject knowledge during pretraining. In addition, we also introduce an knowledge base-aided vocabulary extension to adapt the general tokenization vocabulary to radiology domain.
* Association for Computational Linguistics (ACL), 2023
Toward the Engineering of Virtuous Machines
Dec 30, 2018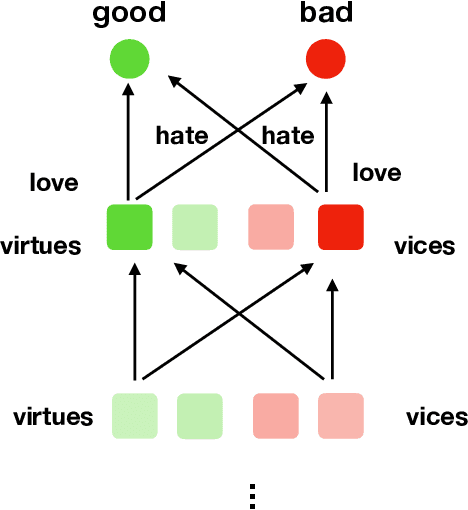
While various traditions under the 'virtue ethics' umbrella have been studied extensively and advocated by ethicists, it has not been clear that there exists a version of virtue ethics rigorous enough to be a target for machine ethics (which we take to include the engineering of an ethical sensibility in a machine or robot itself, not only the study of ethics in the humans who might create artificial agents). We begin to address this by presenting an embryonic formalization of a key part of any virtue-ethics theory: namely, the learning of virtue by a focus on exemplars of moral virtue. Our work is based in part on a computational formal logic previously used to formally model other ethical theories and principles therein, and to implement these models in artificial agents.
One Formalization of Virtue Ethics via Learning
May 20, 2018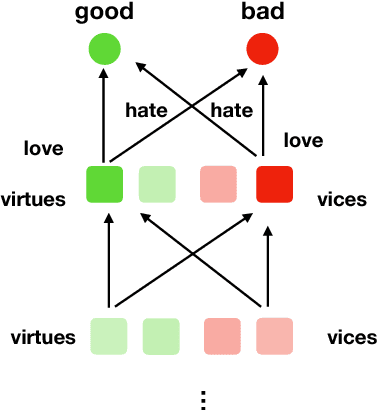
Given that there exist many different formal and precise treatments of deontologi- cal and consequentialist ethics, we turn to virtue ethics and consider what could be a formalization of virtue ethics that makes it amenable to automation. We present an embroyonic formalization in a cognitive calculus (which subsumes a quantified first-order logic) that has been previously used to model robust ethical principles, in both the deontological and consequentialist traditions.