 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 7: Everyday Knowledge Across Diverse Languages and Cultures
May 04, 2026We present our shared task on evaluating the adaptability of LLMs and NLP systems across multiple languages and cultures. The task data consist of an extended version of our manually constructed BLEnD benchmark (Myung et al. 2024), covering more than 30 language-culture pairs, predominantly representing low-resource languages spoken across multiple continents. As the task is designed strictly for evaluation, participants were not permitted to use the data for training, fine-tuning, few-shot learning, or any other form of model modification. Our task includes two tracks: (a) Short-Answer Questions (SAQ) and (b) Multiple-Choice Questions (MCQ). Participants were required to predict labels and were allowed to submit any NLP system and adopt diverse modelling strategies, provided that the benchmark was used solely for evaluation. The task attracted more than 140 registered participants, and we received final submissions from 62 teams, along with 19 system description papers. We report the results and present an analysis of the best-performing systems and the most commonly adopted approaches. Furthermore, we discuss shared insights into open questions and challenges related to evaluation, misalignment, and methodological perspectives on model behaviour in low-resource languages and for under-represented cultures.
Effects of Cross-lingual Evidence in Multilingual Medical Question Answering
Apr 22, 2026This paper investigates Multilingual Medical Question Answering across high-resource (English, Spanish, French, Italian) and low-resource (Basque, Kazakh) languages. We evaluate three types of external evidence sources across models of varying size: curated repositories of specialized medical knowledge, web-retrieved content, and explanations from LLM's parametric knowledge. Moreover, we conduct experiments with multilingual, monolingual and cross-lingual retrieval. Our results demonstrate that larger models consistently achieve superior performance in English across baseline evaluations. When incorporating external knowledge, web-retrieved data in English proves most beneficial for high-resource languages. Conversely, for low-resource languages, the most effective strategy combines retrieval in both English and the target language, achieving comparable accuracy to high-resource language results. These findings challenge the assumption that external knowledge systematically improves performance and reveal that effective strategies depend on both the source of language resources and on model scale. Furthermore, specialized medical knowledge sources such as PubMed are limited: while they provide authoritative expert knowledge, they lack adequate multilingual coverage
A Catalog of Basque Dialectal Resources: Online Collections and Standard-to-Dialectal Adaptations
Mar 26, 2026Recent research on dialectal NLP has identified data scarcity as a primary limitation. To address this limitation, this paper presents a catalog of contemporary Basque dialectal data and resources, offering a systematic and comprehensive compilation of the dialectal data currently available in Basque. Two types of data sources have been distinguished: online data originally written in some dialect, and standard-to-dialect adapted data. The former includes all dialectal data that can be found online, such as news and radio sites, informal tweets, as well as online resources such as dictionaries, atlases, grammar rules, or videos. The latter consists of data that has been adapted from the standard variety to dialectal varieties, either manually or automatically. Regarding the manual adaptation, the test split of the XNLI Natural Language Inference dataset was manually adapted into three Basque dialects: Western, Central, and Navarrese-Lapurdian, yielding a high-quality parallel gold standard evaluation dataset. With respect to the automatic dialectal adaptation, the automatically adapted physical commonsense dataset (BasPhyCowest) underwent additional manual evaluation by native speakers to assess its quality and determine whether it could serve as a viable substitute for full manual adaptation (i.e., silver data creation).
Physical Commonsense Reasoning for Lower-Resourced Languages and Dialects: a Study on Basque
Feb 16, 2026Physical commonsense reasoning represents a fundamental capability of human intelligence, enabling individuals to understand their environment, predict future events, and navigate physical spaces. Recent years have witnessed growing interest in reasoning tasks within Natural Language Processing (NLP). However, no prior research has examined the performance of Large Language Models (LLMs) on non-question-answering (non-QA) physical commonsense reasoning tasks in low-resource languages such as Basque. Taking the Italian GITA as a starting point, this paper addresses this gap by presenting BasPhyCo, the first non-QA physical commonsense reasoning dataset for Basque, available in both standard and dialectal variants. We evaluate model performance across three hierarchical levels of commonsense understanding: (1) distinguishing between plausible and implausible narratives (accuracy), (2) identifying the conflicting element that renders a narrative implausible (consistency), and (3) determining the specific physical state that creates the implausibility (verifiability). These tasks were assessed using multiple multilingual LLMs as well as models pretrained specifically for Italian and Basque. Results indicate that, in terms of verifiability, LLMs exhibit limited physical commonsense capabilities in low-resource languages such as Basque, especially when processing dialectal variants.
La Leaderboard: A Large Language Model Leaderboard for Spanish Varieties and Languages of Spain and Latin America
Jul 01, 2025Leaderboards showcase the current capabilities and limitations of Large Language Models (LLMs). To motivate the development of LLMs that represent the linguistic and cultural diversity of the Spanish-speaking community, we present La Leaderboard, the first open-source leaderboard to evaluate generative LLMs in languages and language varieties of Spain and Latin America. La Leaderboard is a community-driven project that aims to establish an evaluation standard for everyone interested in developing LLMs for the Spanish-speaking community. This initial version combines 66 datasets in Basque, Catalan, Galician, and different Spanish varieties, showcasing the evaluation results of 50 models. To encourage community-driven development of leaderboards in other languages, we explain our methodology, including guidance on selecting the most suitable evaluation setup for each downstream task. In particular, we provide a rationale for using fewer few-shot examples than typically found in the literature, aiming to reduce environmental impact and facilitate access to reproducible results for a broader research community.
Lost in Variation? Evaluating NLI Performance in Basque and Spanish Geographical Variants
Jun 18, 2025



In this paper, we evaluate the capacity of current language technologies to understand Basque and Spanish language varieties. We use Natural Language Inference (NLI) as a pivot task and introduce a novel, manually-curated parallel dataset in Basque and Spanish, along with their respective variants. Our empirical analysis of crosslingual and in-context learning experiments using encoder-only and decoder-based Large Language Models (LLMs) shows a performance drop when handling linguistic variation, especially in Basque. Error analysis suggests that this decline is not due to lexical overlap, but rather to the linguistic variation itself. Further ablation experiments indicate that encoder-only models particularly struggle with Western Basque, which aligns with linguistic theory that identifies peripheral dialects (e.g., Western) as more distant from the standard. All data and code are publicly available.
Benchmarking Critical Questions Generation: A Challenging Reasoning Task for Large Language Models
May 16, 2025The task of Critical Questions Generation (CQs-Gen) aims to foster critical thinking by enabling systems to generate questions that expose assumptions and challenge the reasoning in arguments. Despite growing interest in this area, progress has been hindered by the lack of suitable datasets and automatic evaluation standards. This work presents a comprehensive approach to support the development and benchmarking of systems for this task. We construct the first large-scale manually-annotated dataset. We also investigate automatic evaluation methods and identify a reference-based technique using large language models (LLMs) as the strategy that best correlates with human judgments. Our zero-shot evaluation of 11 LLMs establishes a strong baseline while showcasing the difficulty of the task. Data, code, and a public leaderboard are provided to encourage further research not only in terms of model performance, but also to explore the practical benefits of CQs-Gen for both automated reasoning and human critical thinking.
Dynamic Knowledge Integration for Evidence-Driven Counter-Argument Generation with Large Language Models
Mar 07, 2025



This paper investigates the role of dynamic external knowledge integration in improving counter-argument generation using Large Language Models (LLMs). While LLMs have shown promise in argumentative tasks, their tendency to generate lengthy, potentially unfactual responses highlights the need for more controlled and evidence-based approaches. We introduce a new manually curated dataset of argument and counter-argument pairs specifically designed to balance argumentative complexity with evaluative feasibility. We also propose a new LLM-as-a-Judge evaluation methodology that shows a stronger correlation with human judgments compared to traditional reference-based metrics. Our experimental results demonstrate that integrating dynamic external knowledge from the web significantly improves the quality of generated counter-arguments, particularly in terms of relatedness, persuasiveness, and factuality. The findings suggest that combining LLMs with real-time external knowledge retrieval offers a promising direction for developing more effective and reliable counter-argumentation systems.
Truth Knows No Language: Evaluating Truthfulness Beyond English
Feb 13, 2025
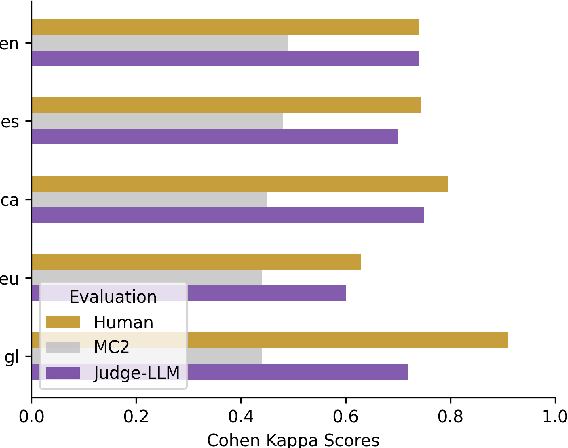
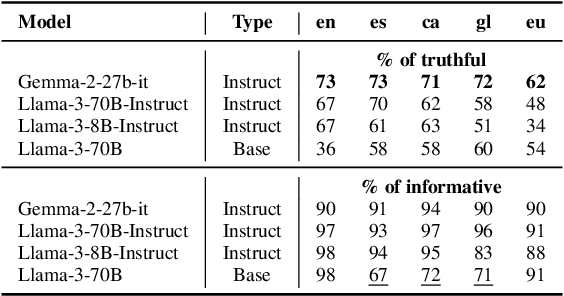
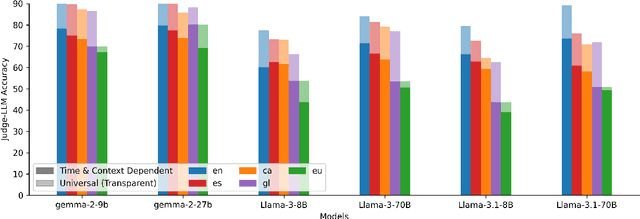
We introduce a professionally translated extension of the TruthfulQA benchmark designed to evaluate truthfulness in Basque, Catalan, Galician, and Spanish. Truthfulness evaluations of large language models (LLMs) have primarily been conducted in English. However, the ability of LLMs to maintain truthfulness across languages remains under-explored. Our study evaluates 12 state-of-the-art open LLMs, comparing base and instruction-tuned models using human evaluation, multiple-choice metrics, and LLM-as-a-Judge scoring. Our findings reveal that, while LLMs perform best in English and worst in Basque (the lowest-resourced language), overall truthfulness discrepancies across languages are smaller than anticipated. Furthermore, we show that LLM-as-a-Judge correlates more closely with human judgments than multiple-choice metrics, and that informativeness plays a critical role in truthfulness assessment. Our results also indicate that machine translation provides a viable approach for extending truthfulness benchmarks to additional languages, offering a scalable alternative to professional translation. Finally, we observe that universal knowledge questions are better handled across languages than context- and time-dependent ones, highlighting the need for truthfulness evaluations that account for cultural and temporal variability. Dataset and code are publicly available under open licenses.
Critical Questions Generation: Motivation and Challenges
Oct 18, 2024



The development of Large Language Models (LLMs) has brought impressive performances on mitigation strategies against misinformation, such as counterargument generation. However, LLMs are still seriously hindered by outdated knowledge and by their tendency to generate hallucinated content. In order to circumvent these issues, we propose a new task, namely, Critical Questions Generation, consisting of processing an argumentative text to generate the critical questions (CQs) raised by it. In argumentation theory CQs are tools designed to lay bare the blind spots of an argument by pointing at the information it could be missing. Thus, instead of trying to deploy LLMs to produce knowledgeable and relevant counterarguments, we use them to question arguments, without requiring any external knowledge. Research on CQs Generation using LLMs requires a reference dataset for large scale experimentation. Thus, in this work we investigate two complementary methods to create such a resource: (i) instantiating CQs templates as defined by Walton's argumentation theory and (ii), using LLMs as CQs generators. By doing so, we contribute with a procedure to establish what is a valid CQ and conclude that, while LLMs are reasonable CQ generators, they still have a wide margin for improvement in this task.