 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolMol: Evolutionary Agentic Framework for Multi-objective Drug Discovery
May 14, 2026Advances in large language models (LLMs) have recently opened new and promising avenues for small-molecule drug discovery. Yet existing LLM-based approaches for molecular generation often suffer from high rates of invalid and low-quality ligand candidates, a result of the syntactic limitations of current models with regard to molecular strings. In this paper, we introduce $\texttt{ToolMol}$, an evolutionary agentic framework for de novo drug design. $\texttt{ToolMol}$ combines a multi-objective genetic algorithm with an agentic LLM operator that iteratively updates the ligand population. We build a comprehensive toolbox of RDKit-backed functions that allows our agentic operator to consisently make precise ligand modifications. $\texttt{ToolMol}$ achieves state-of-the-art performance on multi-objective property optimization tasks, discovering drug-like and synthesizable ligands that have $>10\%$ stronger predicted binding affinity compared to existing methods, evaluated on three protein targets. $\texttt{ToolMol}$ ligands additionally achieve state-of-the-art results in gold-standard Absolute Binding Free Energy scores, gaining over existing methods by over $35\%$. By studying chain-of-thought reasoning traces, we observe that tool-calling enables the model to more faithfully execute its planned modifications, efficiently exploiting the strong chemical prior knowledge in LLMs.
Use as Directed? A Comparison of Software Tools Intended to Check Rigor and Transparency of Published Work
Jul 23, 2025



The causes of the reproducibility crisis include lack of standardization and transparency in scientific reporting. Checklists such as ARRIVE and CONSORT seek to improve transparency, but they are not always followed by authors and peer review often fails to identify missing items. To address these issues, there are several automated tools that have been designed to check different rigor criteria. We have conducted a broad comparison of 11 automated tools across 9 different rigor criteria from the ScreenIT group. We found some criteria, including detecting open data, where the combination of tools showed a clear winner, a tool which performed much better than other tools. In other cases, including detection of inclusion and exclusion criteria, the combination of tools exceeded the performance of any one tool. We also identified key areas where tool developers should focus their effort to make their tool maximally useful. We conclude with a set of insights and recommendations for stakeholders in the development of rigor and transparency detection tools. The code and data for the study is available at https://github.com/PeterEckmann1/tool-comparison.
MF-LAL: Drug Compound Generation Using Multi-Fidelity Latent Space Active Learning
Oct 15, 2024


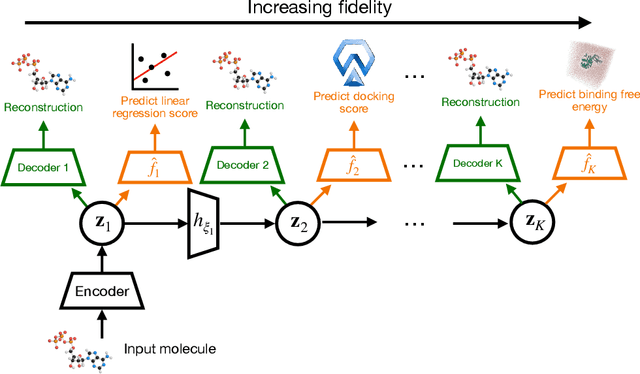
Current generative models for drug discovery primarily use molecular docking as an oracle to guide the generation of active compounds. However, such models are often not useful in practice because even compounds with high docking scores do not consistently show experimental activity. More accurate methods for activity prediction exist, such as molecular dynamics based binding free energy calculations, but they are too computationally expensive to use in a generative model. To address this challenge, we propose Multi-Fidelity Latent space Active Learning (MF-LAL), a generative modeling framework that integrates a set of oracles with varying cost-accuracy tradeoffs. Unlike previous approaches that separately learn the surrogate model and generative model, MF-LAL combines the generative and multi-fidelity surrogate models into a single framework, allowing for more accurate activity prediction and higher quality samples. We train MF-LAL with a novel active learning algorithm to further reduce computational cost. Our experiments on two disease-relevant proteins show that MF-LAL produces compounds with significantly better binding free energy scores than other single and multi-fidelity approaches.
Technical report: Improving the properties of molecules generated by LIMO
Jul 20, 2024This technical report investigates variants of the Latent Inceptionism on Molecules (LIMO) framework to improve the properties of generated molecules. We conduct ablative studies of molecular representation, decoder model, and surrogate model training scheme. The experiments suggest that an autogressive Transformer decoder with GroupSELFIES achieves the best average properties for the random generation task.
MFBind: a Multi-Fidelity Approach for Evaluating Drug Compounds in Practical Generative Modeling
Feb 16, 2024



Current generative models for drug discovery primarily use molecular docking to evaluate the quality of generated compounds. However, such models are often not useful in practice because even compounds with high docking scores do not consistently show experimental activity. More accurate methods for activity prediction exist, such as molecular dynamics based binding free energy calculations, but they are too computationally expensive to use in a generative model. We propose a multi-fidelity approach, Multi-Fidelity Bind (MFBind), to achieve the optimal trade-off between accuracy and computational cost. MFBind integrates docking and binding free energy simulators to train a multi-fidelity deep surrogate model with active learning. Our deep surrogate model utilizes a pretraining technique and linear prediction heads to efficiently fit small amounts of high-fidelity data. We perform extensive experiments and show that MFBind (1) outperforms other state-of-the-art single and multi-fidelity baselines in surrogate modeling, and (2) boosts the performance of generative models with markedly higher quality compounds.
Target-Free Compound Activity Prediction via Few-Shot Learning
Nov 27, 2023Predicting the activities of compounds against protein-based or phenotypic assays using only a few known compounds and their activities is a common task in target-free drug discovery. Existing few-shot learning approaches are limited to predicting binary labels (active/inactive). However, in real-world drug discovery, degrees of compound activity are highly relevant. We study Few-Shot Compound Activity Prediction (FS-CAP) and design a novel neural architecture to meta-learn continuous compound activities across large bioactivity datasets. Our model aggregates encodings generated from the known compounds and their activities to capture assay information. We also introduce a separate encoder for the unknown compound. We show that FS-CAP surpasses traditional similarity-based techniques as well as other state of the art few-shot learning methods on a variety of target-free drug discovery settings and datasets.
LIMO: Latent Inceptionism for Targeted Molecule Generation
Jun 17, 2022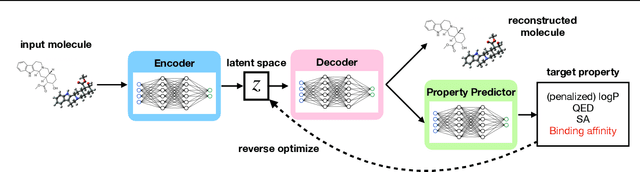
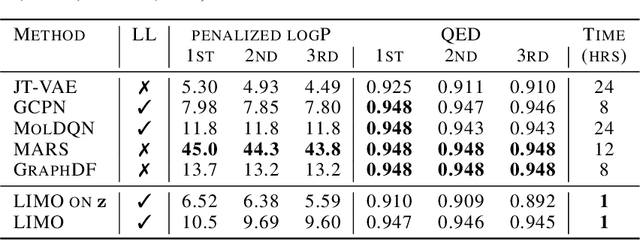
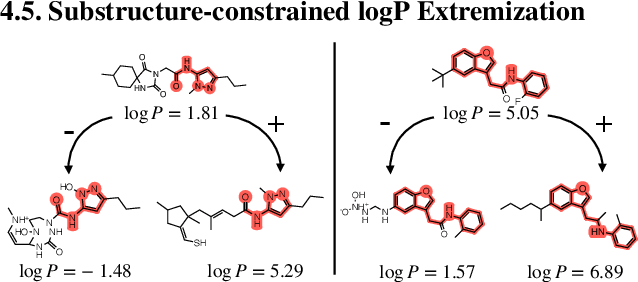

Generation of drug-like molecules with high binding affinity to target proteins remains a difficult and resource-intensive task in drug discovery. Existing approaches primarily employ reinforcement learning, Markov sampling, or deep generative models guided by Gaussian processes, which can be prohibitively slow when generating molecules with high binding affinity calculated by computationally-expensive physics-based methods. We present Latent Inceptionism on Molecules (LIMO), which significantly accelerates molecule generation with an inceptionism-like technique. LIMO employs a variational autoencoder-generated latent space and property prediction by two neural networks in sequence to enable faster gradient-based reverse-optimization of molecular properties. Comprehensive experiments show that LIMO performs competitively on benchmark tasks and markedly outperforms state-of-the-art techniques on the novel task of generating drug-like compounds with high binding affinity, reaching nanomolar range against two protein targets. We corroborate these docking-based results with more accurate molecular dynamics-based calculations of absolute binding free energy and show that one of our generated drug-like compounds has a predicted $K_D$ (a measure of binding affinity) of $6 \cdot 10^{-14}$ M against the human estrogen receptor, well beyond the affinities of typical early-stage drug candidates and most FDA-approved drugs to their respective targets. Code is available at https://github.com/Rose-STL-Lab/LIMO.