 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Introducing an Improved Information-Theoretic Measure of Predictive Uncertainty
Nov 14, 2023
Applying a machine learning model for decision-making in the real world requires to distinguish what the model knows from what it does not. A critical factor in assessing the knowledge of a model is to quantify its predictive uncertainty. Predictive uncertainty is commonly measured by the entropy of the Bayesian model average (BMA) predictive distribution. Yet, the properness of this current measure of predictive uncertainty was recently questioned. We provide new insights regarding those limitations. Our analyses show that the current measure erroneously assumes that the BMA predictive distribution is equivalent to the predictive distribution of the true model that generated the dataset. Consequently, we introduce a theoretically grounded measure to overcome these limitations. We experimentally verify the benefits of our introduced measure of predictive uncertainty. We find that our introduced measure behaves more reasonably in controlled synthetic tasks. Moreover, our evaluations on ImageNet demonstrate that our introduced measure is advantageous in real-world applications utilizing predictive uncertainty.
VKIE: The Application of Key Information Extraction on Video Text
Oct 18, 2023Extracting structured information from videos is critical for numerous downstream applications in the industry. In this paper, we define a significant task of extracting hierarchical key information from visual texts on videos. To fulfill this task, we decouples it into four subtasks and introduce two implementation solutions called PipVKIE and UniVKIE. PipVKIE sequentially completes the four subtasks in continuous stages, while UniVKIE is improved by unifying all the subtasks into one backbone. Both PipVKIE and UniVKIE leverage multimodal information from vision, text, and coordinates for feature representation. Extensive experiments on one well-defined dataset demonstrate that our solutions can achieve remarkable performance and efficient inference speed. The code and dataset will be publicly available.
Understanding Environmental Posts: Sentiment and Emotion Analysis of Social Media Data
Dec 05, 2023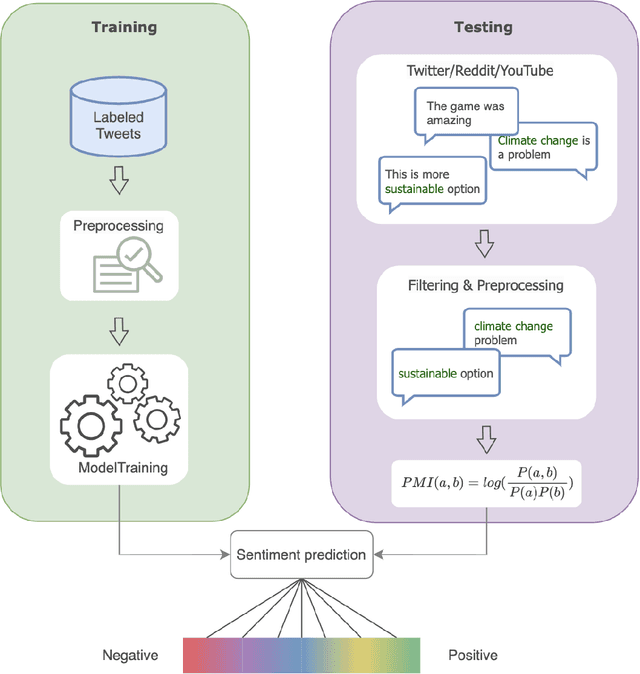
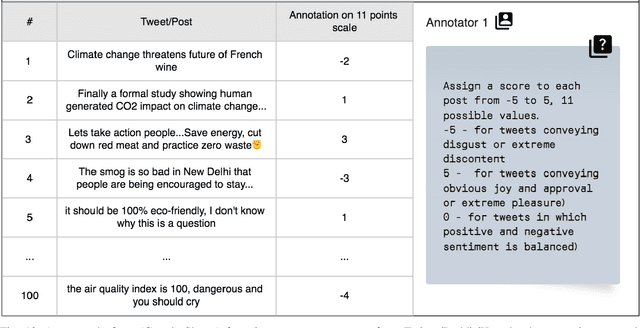
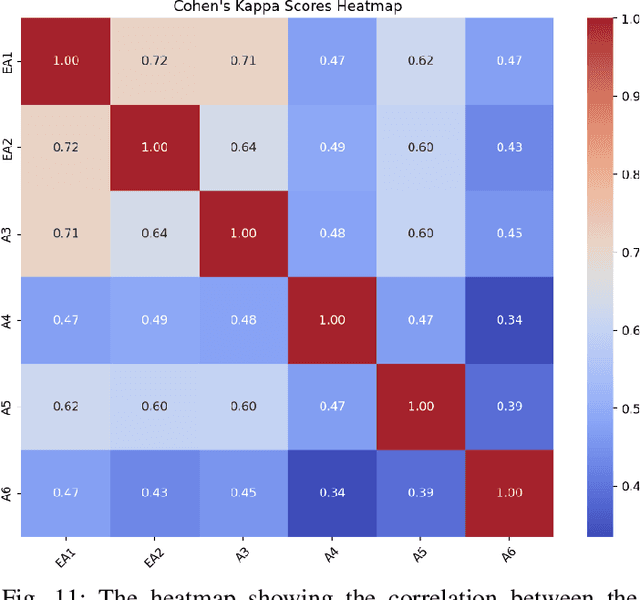
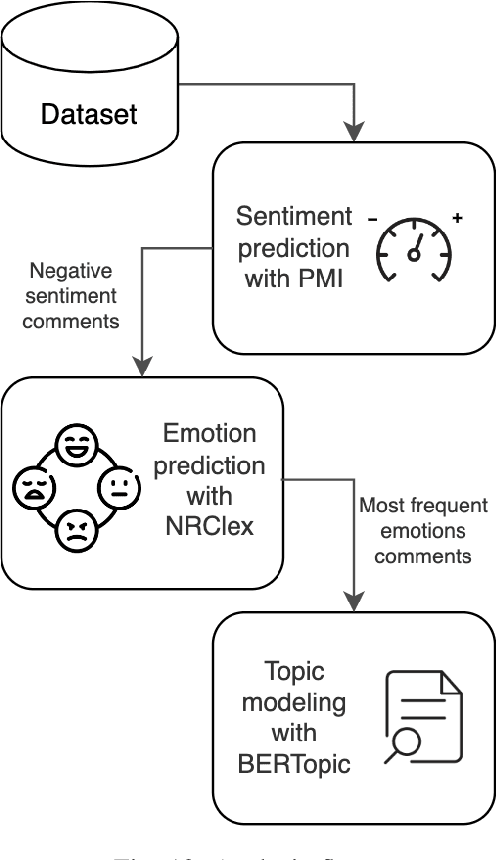
Social media is now the predominant source of information due to the availability of immediate public response. As a result, social media data has become a valuable resource for comprehending public sentiments. Studies have shown that it can amplify ideas and influence public sentiments. This study analyzes the public perception of climate change and the environment over a decade from 2014 to 2023. Using the Pointwise Mutual Information (PMI) algorithm, we identify sentiment and explore prevailing emotions expressed within environmental tweets across various social media platforms, namely Twitter, Reddit, and YouTube. Accuracy on a human-annotated dataset was 0.65, higher than Vader score but lower than that of an expert rater (0.90). Our findings suggest that negative environmental tweets are far more common than positive or neutral ones. Climate change, air quality, emissions, plastic, and recycling are the most discussed topics on all social media platforms, highlighting its huge global concern. The most common emotions in environmental tweets are fear, trust, and anticipation, demonstrating public reactions wide and complex nature. By identifying patterns and trends in opinions related to the environment, we hope to provide insights that can help raise awareness regarding environmental issues, inform the development of interventions, and adapt further actions to meet environmental challenges.
FreestyleRet: Retrieving Images from Style-Diversified Queries
Dec 05, 2023Image Retrieval aims to retrieve corresponding images based on a given query. In application scenarios, users intend to express their retrieval intent through various query styles. However, current retrieval tasks predominantly focus on text-query retrieval exploration, leading to limited retrieval query options and potential ambiguity or bias in user intention. In this paper, we propose the Style-Diversified Query-Based Image Retrieval task, which enables retrieval based on various query styles. To facilitate the novel setting, we propose the first Diverse-Style Retrieval dataset, encompassing diverse query styles including text, sketch, low-resolution, and art. We also propose a light-weighted style-diversified retrieval framework. For various query style inputs, we apply the Gram Matrix to extract the query's textural features and cluster them into a style space with style-specific bases. Then we employ the style-init prompt tuning module to enable the visual encoder to comprehend the texture and style information of the query. Experiments demonstrate that our model, employing the style-init prompt tuning strategy, outperforms existing retrieval models on the style-diversified retrieval task. Moreover, style-diversified queries~(sketch+text, art+text, etc) can be simultaneously retrieved in our model. The auxiliary information from other queries enhances the retrieval performance within the respective query.
Protein Language Model-Powered 3D Ligand Binding Site Prediction from Protein Sequence
Dec 05, 2023Prediction of ligand binding sites of proteins is a fundamental and important task for understanding the function of proteins and screening potential drugs. Most existing methods require experimentally determined protein holo-structures as input. However, such structures can be unavailable on novel or less-studied proteins. To tackle this limitation, we propose LaMPSite, which only takes protein sequences and ligand molecular graphs as input for ligand binding site predictions. The protein sequences are used to retrieve residue-level embeddings and contact maps from the pre-trained ESM-2 protein language model. The ligand molecular graphs are fed into a graph neural network to compute atom-level embeddings. Then we compute and update the protein-ligand interaction embedding based on the protein residue-level embeddings and ligand atom-level embeddings, and the geometric constraints in the inferred protein contact map and ligand distance map. A final pooling on protein-ligand interaction embedding would indicate which residues belong to the binding sites. Without any 3D coordinate information of proteins, our proposed model achieves competitive performance compared to baseline methods that require 3D protein structures when predicting binding sites. Given that less than 50% of proteins have reliable structure information in the current stage, LaMPSite will provide new opportunities for drug discovery.
Towards Granularity-adjusted Pixel-level Semantic Annotation
Dec 05, 2023

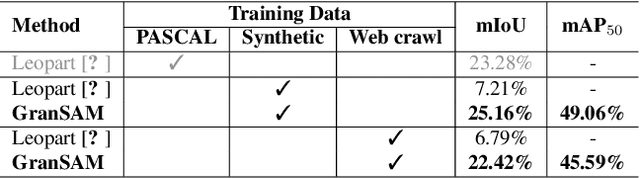

Recent advancements in computer vision predominantly rely on learning-based systems, leveraging annotations as the driving force to develop specialized models. However, annotating pixel-level information, particularly in semantic segmentation, presents a challenging and labor-intensive task, prompting the need for autonomous processes. In this work, we propose GranSAM which distinguishes itself by providing semantic segmentation at the user-defined granularity level on unlabeled data without the need for any manual supervision, offering a unique contribution in the realm of semantic mask annotation method. Specifically, we propose an approach to enable the Segment Anything Model (SAM) with semantic recognition capability to generate pixel-level annotations for images without any manual supervision. For this, we accumulate semantic information from synthetic images generated by the Stable Diffusion model or web crawled images and employ this data to learn a mapping function between SAM mask embeddings and object class labels. As a result, SAM, enabled with granularity-adjusted mask recognition, can be used for pixel-level semantic annotation purposes. We conducted experiments on the PASCAL VOC 2012 and COCO-80 datasets and observed a +17.95% and +5.17% increase in mIoU, respectively, compared to existing state-of-the-art methods when evaluated under our problem setting.
MKA: A Scalable Medical Knowledge Assisted Mechanism for Generative Models on Medical Conversation Tasks
Dec 05, 2023Using natural language processing (NLP) technologies to develop medical chatbots makes the diagnosis of the patient more convenient and efficient, which is a typical application in healthcare AI. Because of its importance, lots of research have been come out. Recently, the neural generative models have shown their impressive ability as the core of chatbot, while it cannot scale well when directly applied to medical conversation due to the lack of medical-specific knowledge. To address the limitation, a scalable Medical Knowledge Assisted mechanism, MKA, is proposed in this paper. The mechanism aims to assist general neural generative models to achieve better performance on the medical conversation task. The medical-specific knowledge graph is designed within the mechanism, which contains 6 types of medical-related information, including department, drug, check, symptom, disease, food. Besides, the specific token concatenation policy is defined to effectively inject medical information into the input data. Evaluation of our method is carried out on two typical medical datasets, MedDG and MedDialog-CN. The evaluation results demonstrate that models combined with our mechanism outperform original methods in multiple automatic evaluation metrics. Besides, MKA-Bert-GPT achieves state-of-the-art performance. The open-sourced codes are public: https://github.com/LIANGKE23/Knowledge_Assisted_Medical_Dialogue_Generation_Mechanism
Decoupling Meta-Reinforcement Learning with Gaussian Task Contexts and Skills
Dec 11, 2023Offline meta-reinforcement learning (meta-RL) methods, which adapt to unseen target tasks with prior experience, are essential in robot control tasks. Current methods typically utilize task contexts and skills as prior experience, where task contexts are related to the information within each task and skills represent a set of temporally extended actions for solving subtasks. However, these methods still suffer from limited performance when adapting to unseen target tasks, mainly because the learned prior experience lacks generalization, i.e., they are unable to extract effective prior experience from meta-training tasks by exploration and learning of continuous latent spaces. We propose a framework called decoupled meta-reinforcement learning (DCMRL), which (1) contrastively restricts the learning of task contexts through pulling in similar task contexts within the same task and pushing away different task contexts of different tasks, and (2) utilizes a Gaussian quantization variational autoencoder (GQ-VAE) for clustering the Gaussian distributions of the task contexts and skills respectively, and decoupling the exploration and learning processes of their spaces. These cluster centers which serve as representative and discrete distributions of task context and skill are stored in task context codebook and skill codebook, respectively. DCMRL can acquire generalizable prior experience and achieve effective adaptation to unseen target tasks during the meta-testing phase. Experiments in the navigation and robot manipulation continuous control tasks show that DCMRL is more effective than previous meta-RL methods with more generalizable prior experience.
Tackling Cyberattacks through AI-based Reactive Systems: A Holistic Review and Future Vision
Dec 11, 2023There is no denying that the use of Information Technology (IT) is undergoing exponential growth in today's world. This digital transformation has also given rise to a multitude of security challenges, notably in the realm of cybercrime. In response to these growing threats, public and private sectors have prioritized the strengthening of IT security measures. In light of the growing security concern, Artificial Intelligence (AI) has gained prominence within the cybersecurity landscape. This paper presents a comprehensive survey of recent advancements in AI-driven threat response systems. To the best of our knowledge, the most recent survey covering the AI reaction domain was conducted in 2017. Since then, considerable literature has been published and therefore it is worth reviewing it. By means of several shared features, each of the studies is compared on a common ground. Through an analysis of the research papers conducted on a standardized basis, this survey aims to unravel the complexities and opportunities of integrating AI into cyber defense. The conclusions drawn from this collective analysis provide a comprehensive snapshot of the evolving landscape at the intersection of AI and cybersecurity. This landscape underscores the growing significance of not only anticipating and detecting threats but also responding to them effectively. Additionally, from these reviews, various research challenges for the future are presented. These challenges serve as a roadmap for researchers and practitioners in the field of AI-integrated reactive strategies.
Implicit Shape Modeling for Anatomical Structure Refinement of Volumetric Medical Images
Dec 11, 2023Shape modeling of volumetric medical images is a critical task for quantitative analysis and surgical plans in computer-aided diagnosis. To relieve the burden of expert clinicians, the reconstructed shapes are widely acquired from deep learning models, e.g. Convolutional Neural Networks (CNNs), followed by marching cube algorithm. However, automatically obtaining reconstructed shapes can not always achieve perfect results due to the limited resolution of images and lack of shape prior constraints. In this paper, we design a unified framework for the refinement of medical image segmentation on top of an implicit neural network. Specifically, To learn a sharable shape prior from different instances within the same category in the training phase, the physical information of volumetric medical images are firstly utilized to construct the Physical-Informed Continuous Coordinate Transform (PICCT). PICCT transforms the input data in an aligned manner fed into the implicit shape modeling. To better learn shape representation, we introduce implicit shape constraints on top of the signed distance function (SDF) into the implicit shape modeling of both instances and latent template. For the inference phase, a template interaction module (TIM) is proposed to refine initial results produced by CNNs via deforming deep implicit templates with latent codes. Experimental results on three datasets demonstrated the superiority of our approach in shape refinement. The Chamfer Distance/Earth Mover's Distance achieved by the proposed method are 0.232/0.087 on the Liver dataset, 0.128/0.069 on the Pancreas dataset, and 0.417/0.100 on the Lung Lobe dataset.