 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Subquadratic Architectures: From Applications to Principles
Jun 10, 2026Transformers dominate modern sequence modeling, but their quadratic attention incurs substantial computational cost. Subquadratic architectures offer a scalable alternative. However, it remains unclear which designs yield the most effective sequence models. We compare three leading approaches: xLSTM, Mamba-2, and Gated DeltaNet. We evaluate these models on tasks with complex dependencies: (1) code-model pre-training, (2) distillation of code models from large language models, and (3) pre-training of time-series foundation models. Across these settings, xLSTM delivers the strongest overall performance. To explain xLSTM's advantage, we present a unified formulation and analyze the underlying architectural mechanisms, focusing on state tracking and memory dynamics. Our results show that xLSTM enables more flexible and stable memory correction via its gating scheme. We corroborate these findings on controlled synthetic length-generalization tasks. Overall, our findings indicate that xLSTM's gains on complex tasks stem from robust state tracking and accumulation.
RREDCoT: Segment-Level Reward Redistribution for Reasoning Models
Jun 04, 2026Recent advancements in reasoning language models have been driven by Reinforcement Learning (RL) fine-tuning. Most often, these rely on the Group Relative Policy Optimization (GRPO) algorithm or modifications thereof to steer the models to produce Chain-of-Thought (CoT) traces. The final answer can only be verified, and the reward assigned, after the CoT trace is complete, making it a delayed reward problem. GRPO and its modifications correspond to Monte Carlo methods in standard RL, which are known to suffer from high variance. A possible solution to this problem is the redistribution of rewards through credit assignment, where segments of the CoT trace that are important for arriving at the desirable solution are emphasized by assigning a higher reward. While Monte Carlo sampling can be used to provide an unbiased estimate of intermediate state values, its computational overhead makes it unsuitable for train-time credit assignment in long contexts at high granularity. We introduce RREDCoT (Reward REDistribution for Chain of Thoughts), which utilizes the model itself to approximate the optimal reward redistribution without additional generation. We investigate the advantages of our method compared to MC sampling and several attribution methods. We further analyze several aspects relevant to the construction of the redistribution such as segmentation of CoT traces and state value estimation.
Unlocking the Working Memory of Large Language Models for Latent Reasoning
May 28, 2026To improve the reasoning capabilities of large language models, test-time compute is typically scaled by generating intermediate tokens before the final answer. However, this couples reasoning to autoregressive generation and thereby conflates internal computation with external communication. In contrast, human cognition can use working memory to hold and manipulate information internally without the need to externalize intermediate thoughts. Drawing on this principle, we introduce Reasoning in Memory (RiM), a latent reasoning method that replaces the autoregressive generation of reasoning steps with memory blocks. These memory blocks are fixed sequences of special tokens that unlock the working-memory capacity of large language models. Since they are fixed rather than generated, they can be processed in a single forward pass, enabling compute-efficient latent reasoning. To operationalize these memory blocks, we employ a two-stage curriculum. First, we ground them by predicting explicit reasoning steps after each memory block. Second, we discard this step-level supervision and iteratively refine the final answer after each memory block. Our experiments on reasoning benchmarks show that, across language models of different families and sizes, RiM matches or exceeds existing latent reasoning methods while avoiding the autoregressive generation of thoughts. These results demonstrate that large language models can be trained to use working memory as an effective mechanism for latent reasoning.
Effective Distillation to Hybrid xLSTM Architectures
Mar 16, 2026There have been numerous attempts to distill quadratic attention-based large language models (LLMs) into sub-quadratic linearized architectures. However, despite extensive research, such distilled models often fail to match the performance of their teacher LLMs on various downstream tasks. We set out the goal of lossless distillation, which we define in terms of tolerance-corrected Win-and-Tie rates between student and teacher on sets of tasks. To this end, we introduce an effective distillation pipeline for xLSTM-based students. We propose an additional merging stage, where individually linearized experts are combined into a single model. We show the effectiveness of this pipeline by distilling base and instruction-tuned models from the Llama, Qwen, and Olmo families. In many settings, our xLSTM-based students recover most of the teacher's performance, and even exceed it on some downstream tasks. Our contributions are an important step towards more energy-efficient and cost-effective replacements for transformer-based LLMs.
The Offline-Frontier Shift: Diagnosing Distributional Limits in Generative Multi-Objective Optimization
Feb 11, 2026Offline multi-objective optimization (MOO) aims to recover Pareto-optimal designs given a finite, static dataset. Recent generative approaches, including diffusion models, show strong performance under hypervolume, yet their behavior under other established MOO metrics is less understood. We show that generative methods systematically underperform evolutionary alternatives with respect to other metrics, such as generational distance. We relate this failure mode to the offline-frontier shift, i.e., the displacement of the offline dataset from the Pareto front, which acts as a fundamental limitation in offline MOO. We argue that overcoming this limitation requires out-of-distribution sampling in objective space (via an integral probability metric) and empirically observe that generative methods remain conservatively close to the offline objective distribution. Our results position offline MOO as a distribution-shift--limited problem and provide a diagnostic lens for understanding when and why generative optimization methods fail.
Adaptive Retrieval helps Reasoning in LLMs -- but mostly if it's not used
Feb 06, 2026Large Language Models (LLMs) often falter in complex reasoning tasks due to their static, parametric knowledge, leading to hallucinations and poor performance in specialized domains like mathematics. This work explores a fundamental principle for enhancing generative models: treating retrieval as a form of dynamic in-context learning. We test an adaptive retrieval-augmented architecture where an LLM agent actively decides when to query an external knowledge base during its reasoning process. We compare this adaptive strategy against a standard Chain-of-Thought (CoT) baseline and a static retrieval approach on the GSM8K and MATH-500 benchmarks. Although our experiments show that static retrieval is inferior to CoT, the adaptive retrieval shows interesting behavior: While traces including retrieved results show slightly worse performance compared to CoT, traces that do not include retrieval actually perform better compared to CoT. This suggests that: (a) retrieval only rarely helps reasoning (we show a few counterexamples, e.g. using useful theorems) and (b) actively not using retrieval is indicative of good model performance. Furthermore, we find that the model scales its retrieval frequency with the difficulty of the problem, reinforcing that the decision to retrieve is a crucial metacognitive signal. The agent's ability to self-assess its knowledge and selectively engage with external information represents a key principle for building more robust and reliable generative models.
AP-OOD: Attention Pooling for Out-of-Distribution Detection
Feb 05, 2026Out-of-distribution (OOD) detection, which maps high-dimensional data into a scalar OOD score, is critical for the reliable deployment of machine learning models. A key challenge in recent research is how to effectively leverage and aggregate token embeddings from language models to obtain the OOD score. In this work, we propose AP-OOD, a novel OOD detection method for natural language that goes beyond simple average-based aggregation by exploiting token-level information. AP-OOD is a semi-supervised approach that flexibly interpolates between unsupervised and supervised settings, enabling the use of limited auxiliary outlier data. Empirically, AP-OOD sets a new state of the art in OOD detection for text: in the unsupervised setting, it reduces the FPR95 (false positive rate at 95% true positives) from 27.84% to 4.67% on XSUM summarization, and from 77.08% to 70.37% on WMT15 En-Fr translation.
Pre-trained Forecasting Models: Strong Zero-Shot Feature Extractors for Time Series Classification
Oct 30, 2025



Recent research on time series foundation models has primarily focused on forecasting, leaving it unclear how generalizable their learned representations are. In this study, we examine whether frozen pre-trained forecasting models can provide effective representations for classification. To this end, we compare different representation extraction strategies and introduce two model-agnostic embedding augmentations. Our experiments show that the best forecasting models achieve classification accuracy that matches or even surpasses that of state-of-the-art models pre-trained specifically for classification. Moreover, we observe a positive correlation between forecasting and classification performance. These findings challenge the assumption that task-specific pre-training is necessary, and suggest that learning to forecast may provide a powerful route toward constructing general-purpose time series foundation models.
Addressing Pitfalls in the Evaluation of Uncertainty Estimation Methods for Natural Language Generation
Oct 02, 2025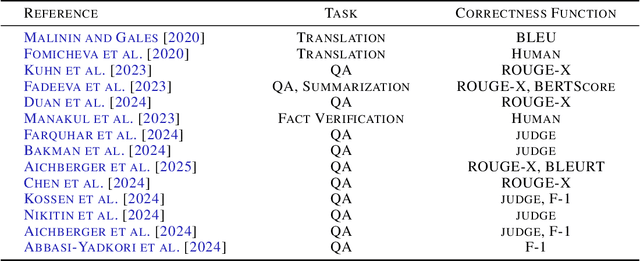
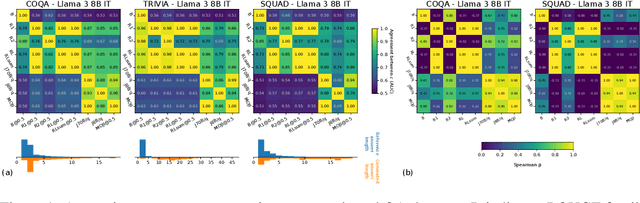
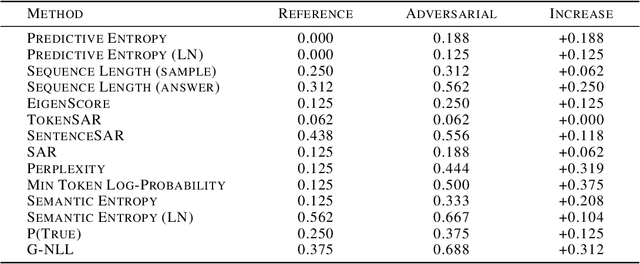
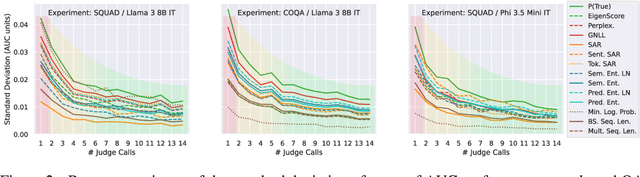
Hallucinations are a common issue that undermine the reliability of large language models (LLMs). Recent studies have identified a specific subset of hallucinations, known as confabulations, which arise due to predictive uncertainty of LLMs. To detect confabulations, various methods for estimating predictive uncertainty in natural language generation (NLG) have been developed. These methods are typically evaluated by correlating uncertainty estimates with the correctness of generated text, with question-answering (QA) datasets serving as the standard benchmark. However, commonly used approximate correctness functions have substantial disagreement between each other and, consequently, in the ranking of the uncertainty estimation methods. This allows one to inflate the apparent performance of uncertainty estimation methods. We propose using several alternative risk indicators for risk correlation experiments that improve robustness of empirical assessment of UE algorithms for NLG. For QA tasks, we show that marginalizing over multiple LLM-as-a-judge variants leads to reducing the evaluation biases. Furthermore, we explore structured tasks as well as out of distribution and perturbation detection tasks which provide robust and controllable risk indicators. Finally, we propose to use an Elo rating of uncertainty estimation methods to give an objective summarization over extensive evaluation settings.
xLSTM Scaling Laws: Competitive Performance with Linear Time-Complexity
Oct 02, 2025Scaling laws play a central role in the success of Large Language Models (LLMs), enabling the prediction of model performance relative to compute budgets prior to training. While Transformers have been the dominant architecture, recent alternatives such as xLSTM offer linear complexity with respect to context length while remaining competitive in the billion-parameter regime. We conduct a comparative investigation on the scaling behavior of Transformers and xLSTM along the following lines, providing insights to guide future model design and deployment. First, we study the scaling behavior for xLSTM in compute-optimal and over-training regimes using both IsoFLOP and parametric fit approaches on a wide range of model sizes (80M-7B) and number of training tokens (2B-2T). Second, we examine the dependence of optimal model sizes on context length, a pivotal aspect that was largely ignored in previous work. Finally, we analyze inference-time scaling characteristics. Our findings reveal that in typical LLM training and inference scenarios, xLSTM scales favorably compared to Transformers. Importantly, xLSTM's advantage widens as training and inference contexts grow.