 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Red AI? Inconsistent Responses from GPT3.5 Models on Political Issues in the US and China
Dec 15, 2023
The rising popularity of ChatGPT and other AI-powered large language models (LLMs) has led to increasing studies highlighting their susceptibility to mistakes and biases. However, most of these studies focus on models trained on English texts. Taking an innovative approach, this study investigates political biases in GPT's multilingual models. We posed the same question about high-profile political issues in the United States and China to GPT in both English and simplified Chinese, and our analysis of the bilingual responses revealed that GPT's bilingual models' political "knowledge" (content) and the political "attitude" (sentiment) are significantly more inconsistent on political issues in China. The simplified Chinese GPT models not only tended to provide pro-China information but also presented the least negative sentiment towards China's problems, whereas the English GPT was significantly more negative towards China. This disparity may stem from Chinese state censorship and US-China geopolitical tensions, which influence the training corpora of GPT bilingual models. Moreover, both Chinese and English models tended to be less critical towards the issues of "their own" represented by the language used, than the issues of "the other." This suggests that GPT multilingual models could potentially develop a "political identity" and an associated sentiment bias based on their training language. We discussed the implications of our findings for information transmission and communication in an increasingly divided world.
TF-CLIP: Learning Text-free CLIP for Video-based Person Re-Identification
Dec 15, 2023Large-scale language-image pre-trained models (e.g., CLIP) have shown superior performances on many cross-modal retrieval tasks. However, the problem of transferring the knowledge learned from such models to video-based person re-identification (ReID) has barely been explored. In addition, there is a lack of decent text descriptions in current ReID benchmarks. To address these issues, in this work, we propose a novel one-stage text-free CLIP-based learning framework named TF-CLIP for video-based person ReID. More specifically, we extract the identity-specific sequence feature as the CLIP-Memory to replace the text feature. Meanwhile, we design a Sequence-Specific Prompt (SSP) module to update the CLIP-Memory online. To capture temporal information, we further propose a Temporal Memory Diffusion (TMD) module, which consists of two key components: Temporal Memory Construction (TMC) and Memory Diffusion (MD). Technically, TMC allows the frame-level memories in a sequence to communicate with each other, and to extract temporal information based on the relations within the sequence. MD further diffuses the temporal memories to each token in the original features to obtain more robust sequence features. Extensive experiments demonstrate that our proposed method shows much better results than other state-of-the-art methods on MARS, LS-VID and iLIDS-VID. The code is available at https://github.com/AsuradaYuci/TF-CLIP.
Can Physician Judgment Enhance Model Trustworthiness? A Case Study on Predicting Pathological Lymph Nodes in Rectal Cancer
Dec 15, 2023Explainability is key to enhancing artificial intelligence's trustworthiness in medicine. However, several issues remain concerning the actual benefit of explainable models for clinical decision-making. Firstly, there is a lack of consensus on an evaluation framework for quantitatively assessing the practical benefits that effective explainability should provide to practitioners. Secondly, physician-centered evaluations of explainability are limited. Thirdly, the utility of built-in attention mechanisms in transformer-based models as an explainability technique is unclear. We hypothesize that superior attention maps should align with the information that physicians focus on, potentially reducing prediction uncertainty and increasing model reliability. We employed a multimodal transformer to predict lymph node metastasis in rectal cancer using clinical data and magnetic resonance imaging, exploring how well attention maps, visualized through a state-of-the-art technique, can achieve agreement with physician understanding. We estimated the model's uncertainty using meta-level information like prediction probability variance and quantified agreement. Our assessment of whether this agreement reduces uncertainty found no significant effect. In conclusion, this case study did not confirm the anticipated benefit of attention maps in enhancing model reliability. Superficial explanations could do more harm than good by misleading physicians into relying on uncertain predictions, suggesting that the current state of attention mechanisms in explainability should not be overestimated. Identifying explainability mechanisms truly beneficial for clinical decision-making remains essential.
Towards Establishing Dense Correspondence on Multiview Coronary Angiography: From Point-to-Point to Curve-to-Curve Query Matching
Dec 18, 2023Coronary angiography is the gold standard imaging technique for studying and diagnosing coronary artery disease. However, the resulting 2D X-ray projections lose 3D information and exhibit visual ambiguities. In this work, we aim to establish dense correspondence in multi-view angiography, serving as a fundamental basis for various clinical applications and downstream tasks. To overcome the challenge of unavailable annotated data, we designed a data simulation pipeline using 3D Coronary Computed Tomography Angiography (CCTA). We formulated the problem of dense correspondence estimation as a query matching task over all points of interest in the given views. We established point-to-point query matching and advanced it to curve-to-curve correspondence, significantly reducing errors by minimizing ambiguity and improving topological awareness. The method was evaluated on a set of 1260 image pairs from different views across 8 clinically relevant angulation groups, demonstrating compelling results and indicating the feasibility of establishing dense correspondence in multi-view angiography.
Learning from Imperfect Demonstrations through Dynamics Evaluation
Dec 18, 2023Standard imitation learning usually assumes that demonstrations are drawn from an optimal policy distribution. However, in real-world scenarios, every human demonstration may exhibit nearly random behavior and collecting high-quality human datasets can be quite costly. This requires imitation learning can learn from imperfect demonstrations to obtain robotic policies that align human intent. Prior work uses confidence scores to extract useful information from imperfect demonstrations, which relies on access to ground truth rewards or active human supervision. In this paper, we propose a dynamics-based method to evaluate the data confidence scores without above efforts. We develop a generalized confidence-based imitation learning framework called Confidence-based Inverse soft-Q Learning (CIQL), which can employ different optimal policy matching methods by simply changing object functions. Experimental results show that our confidence evaluation method can increase the success rate by $40.3\%$ over the original algorithm and $13.5\%$ over the simple noise filtering.
A low-rank non-convex norm method for multiview graph clustering
Dec 18, 2023This study introduces a novel technique for multi-view clustering known as the "Consensus Graph-Based Multi-View Clustering Method Using Low-Rank Non-Convex Norm" (CGMVC-NC). Multi-view clustering is a challenging task in machine learning as it requires the integration of information from multiple data sources or views to cluster data points accurately. The suggested approach makes use of the structural characteristics of multi-view data tensors, introducing a non-convex tensor norm to identify correlations between these views. In contrast to conventional methods, this approach demonstrates superior clustering accuracy across several benchmark datasets. Despite the non-convex nature of the tensor norm used, the proposed method remains amenable to efficient optimization using existing algorithms. The approach provides a valuable tool for multi-view data analysis and has the potential to enhance our understanding of complex systems in various fields. Further research can explore the application of this method to other types of data and extend it to other machine-learning tasks.
Conflict Detection for Temporal Knowledge Graphs:A Fast Constraint Mining Algorithm and New Benchmarks
Dec 18, 2023Temporal facts, which are used to describe events that occur during specific time periods, have become a topic of increased interest in the field of knowledge graph (KG) research. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. To address this problem, we start from the common pattern of temporal facts and propose a pattern-based temporal constraint mining method, PaTeCon. Unlike previous studies, PaTeCon uses graph patterns and statistical information relevant to the given KG to automatically generate temporal constraints, without the need for human experts. In this paper, we illustrate how this method can be optimized to achieve significant speed improvement. We also annotate Wikidata and Freebase to build two new benchmarks for conflict detection. Extensive experiments demonstrate that our pattern-based automatic constraint mining approach is highly effective in generating valuable temporal constraints.
Regularized Conditional Alignment for Multi-Domain Text Classification
Dec 18, 2023The most successful multi-domain text classification (MDTC) approaches employ the shared-private paradigm to facilitate the enhancement of domain-invariant features through domain-specific attributes. Additionally, they employ adversarial training to align marginal feature distributions. Nevertheless, these methodologies encounter two primary challenges: (1) Neglecting class-aware information during adversarial alignment poses a risk of misalignment; (2) The limited availability of labeled data across multiple domains fails to ensure adequate discriminative capacity for the model. To tackle these issues, we propose a method called Regularized Conditional Alignment (RCA) to align the joint distributions of domains and classes, thus matching features within the same category and amplifying the discriminative qualities of acquired features. Moreover, we employ entropy minimization and virtual adversarial training to constrain the uncertainty of predictions pertaining to unlabeled data and enhance the model's robustness. Empirical results on two benchmark datasets demonstrate that our RCA approach outperforms state-of-the-art MDTC techniques.
Aspect-Based Sentiment Analysis with Explicit Sentiment Augmentations
Dec 18, 2023Aspect-based sentiment analysis (ABSA), a fine-grained sentiment classification task, has received much attention recently. Many works investigate sentiment information through opinion words, such as ''good'' and ''bad''. However, implicit sentiment widely exists in the ABSA dataset, which refers to the sentence containing no distinct opinion words but still expresses sentiment to the aspect term. To deal with implicit sentiment, this paper proposes an ABSA method that integrates explicit sentiment augmentations. And we propose an ABSA-specific augmentation method to create such augmentations. Specifically, we post-trains T5 by rule-based data. We employ Syntax Distance Weighting and Unlikelihood Contrastive Regularization in the training procedure to guide the model to generate an explicit sentiment. Meanwhile, we utilize the Constrained Beam Search to ensure the augmentation sentence contains the aspect terms. We test ABSA-ESA on two of the most popular benchmarks of ABSA. The results show that ABSA-ESA outperforms the SOTA baselines on implicit and explicit sentiment accuracy.
APGL4SR: A Generic Framework with Adaptive and Personalized Global Collaborative Information in Sequential Recommendation
Nov 06, 2023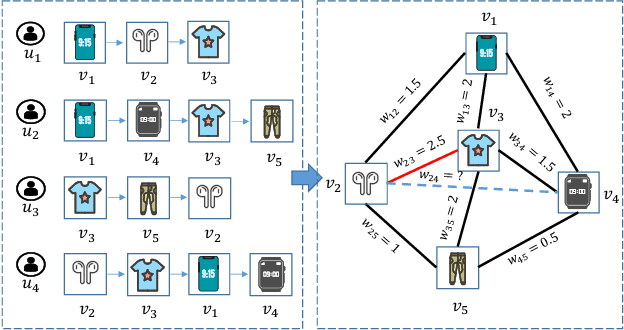
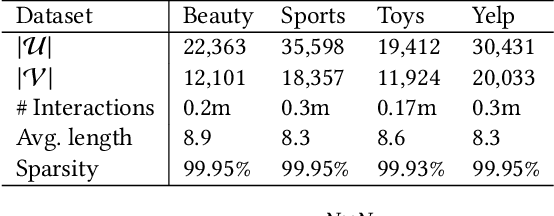
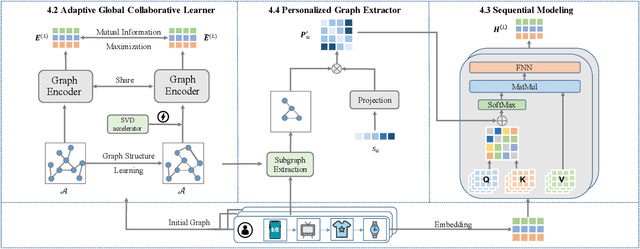
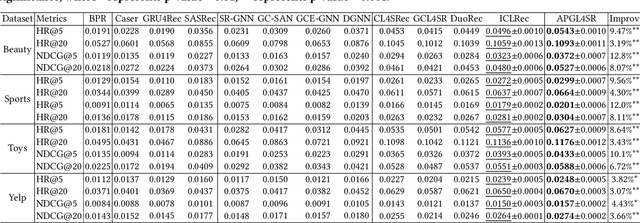
The sequential recommendation system has been widely studied for its promising effectiveness in capturing dynamic preferences buried in users' sequential behaviors. Despite the considerable achievements, existing methods usually focus on intra-sequence modeling while overlooking exploiting global collaborative information by inter-sequence modeling, resulting in inferior recommendation performance. Therefore, previous works attempt to tackle this problem with a global collaborative item graph constructed by pre-defined rules. However, these methods neglect two crucial properties when capturing global collaborative information, i.e., adaptiveness and personalization, yielding sub-optimal user representations. To this end, we propose a graph-driven framework, named Adaptive and Personalized Graph Learning for Sequential Recommendation (APGL4SR), that incorporates adaptive and personalized global collaborative information into sequential recommendation systems. Specifically, we first learn an adaptive global graph among all items and capture global collaborative information with it in a self-supervised fashion, whose computational burden can be further alleviated by the proposed SVD-based accelerator. Furthermore, based on the graph, we propose to extract and utilize personalized item correlations in the form of relative positional encoding, which is a highly compatible manner of personalizing the utilization of global collaborative information. Finally, the entire framework is optimized in a multi-task learning paradigm, thus each part of APGL4SR can be mutually reinforced. As a generic framework, APGL4SR can outperform other baselines with significant margins. The code is available at https://github.com/Graph-Team/APGL4SR.