 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Intuitive Physics with Multimodal Generative Models
Jan 12, 2021
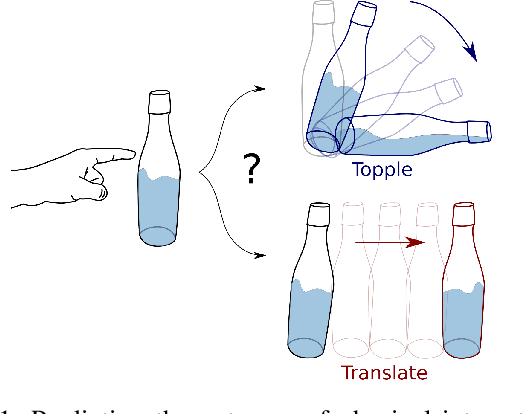
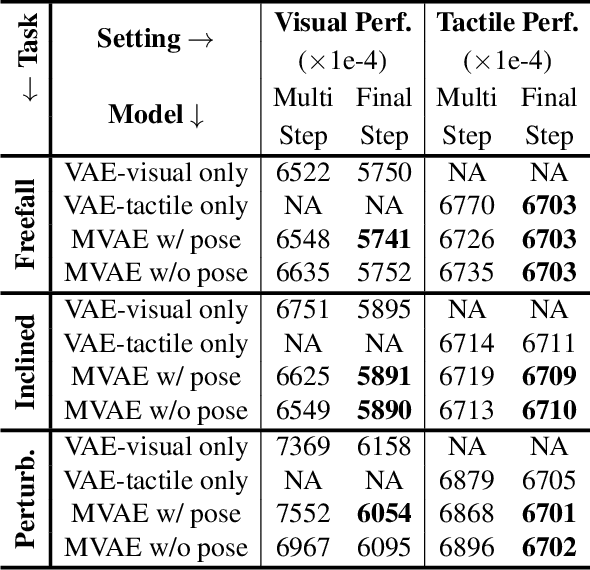
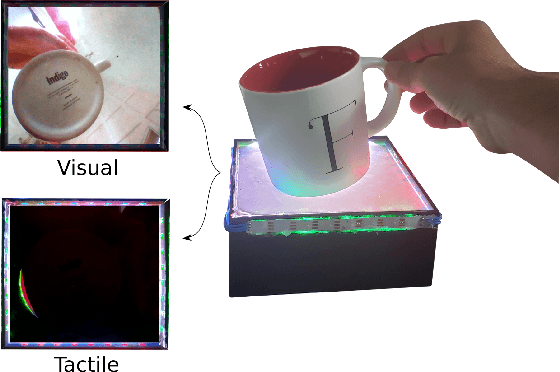

Predicting the future interaction of objects when they come into contact with their environment is key for autonomous agents to take intelligent and anticipatory actions. This paper presents a perception framework that fuses visual and tactile feedback to make predictions about the expected motion of objects in dynamic scenes. Visual information captures object properties such as 3D shape and location, while tactile information provides critical cues about interaction forces and resulting object motion when it makes contact with the environment. Utilizing a novel See-Through-your-Skin (STS) sensor that provides high resolution multimodal sensing of contact surfaces, our system captures both the visual appearance and the tactile properties of objects. We interpret the dual stream signals from the sensor using a Multimodal Variational Autoencoder (MVAE), allowing us to capture both modalities of contacting objects and to develop a mapping from visual to tactile interaction and vice-versa. Additionally, the perceptual system can be used to infer the outcome of future physical interactions, which we validate through simulated and real-world experiments in which the resting state of an object is predicted from given initial conditions.
Text to Image Generation with Semantic-Spatial Aware GAN
Apr 24, 2021
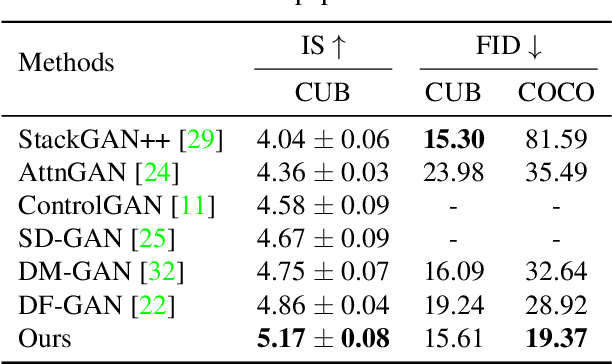


A text to image generation (T2I) model aims to generate photo-realistic images which are semantically consistent with the text descriptions. Built upon the recent advances in generative adversarial networks (GANs), existing T2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) The condition batch normalization methods are applied on the whole image feature maps equally, ignoring the local semantics; (2) The text encoder is fixed during training, which should be trained with the image generator jointly to learn better text representations for image generation. To address these limitations, we propose a novel framework Semantic-Spatial Aware GAN, which is trained in an end-to-end fashion so that the text encoder can exploit better text information. Concretely, we introduce a novel Semantic-Spatial Aware Convolution Network, which (1) learns semantic-adaptive transformation conditioned on text to effectively fuse text features and image features, and (2) learns a mask map in a weakly-supervised way that depends on the current text-image fusion process in order to guide the transformation spatially. Experiments on the challenging COCO and CUB bird datasets demonstrate the advantage of our method over the recent state-of-the-art approaches, regarding both visual fidelity and alignment with input text description. Code is available at https://github.com/wtliao/text2image.
Competency Problems: On Finding and Removing Artifacts in Language Data
Apr 17, 2021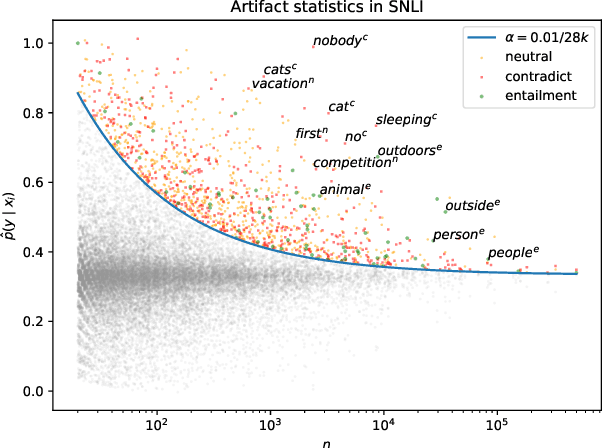

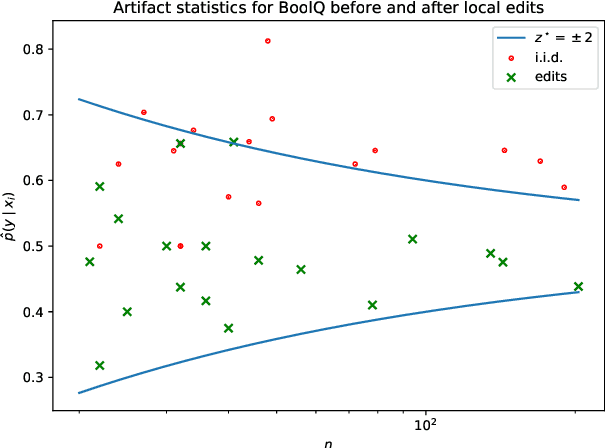
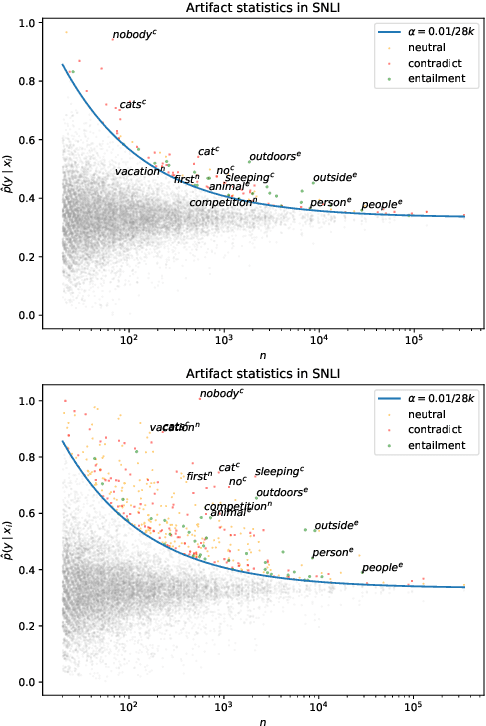
Much recent work in NLP has documented dataset artifacts, bias, and spurious correlations between input features and output labels. However, how to tell which features have "spurious" instead of legitimate correlations is typically left unspecified. In this work we argue that for complex language understanding tasks, all simple feature correlations are spurious, and we formalize this notion into a class of problems which we call competency problems. For example, the word "amazing" on its own should not give information about a sentiment label independent of the context in which it appears, which could include negation, metaphor, sarcasm, etc. We theoretically analyze the difficulty of creating data for competency problems when human bias is taken into account, showing that realistic datasets will increasingly deviate from competency problems as dataset size increases. This analysis gives us a simple statistical test for dataset artifacts, which we use to show more subtle biases than were described in prior work, including demonstrating that models are inappropriately affected by these less extreme biases. Our theoretical treatment of this problem also allows us to analyze proposed solutions, such as making local edits to dataset instances, and to give recommendations for future data collection and model design efforts that target competency problems.
Supporting Clustering with Contrastive Learning
Mar 24, 2021
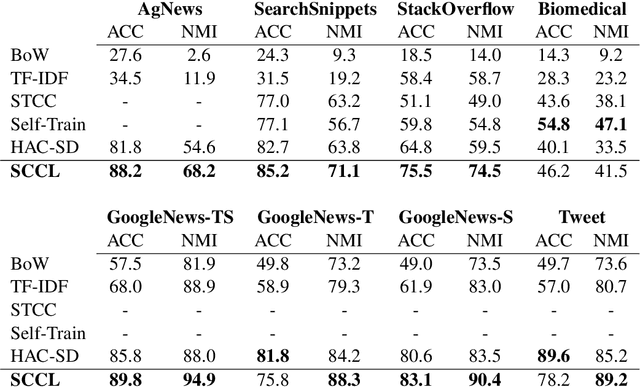
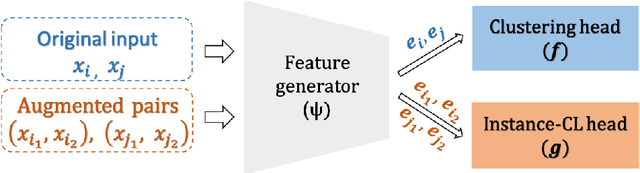
Unsupervised clustering aims at discovering the semantic categories of data according to some distance measured in the representation space. However, different categories often overlap with each other in the representation space at the beginning of the learning process, which poses a significant challenge for distance-based clustering in achieving good separation between different categories. To this end, we propose Supporting Clustering with Contrastive Learning (SCCL) -- a novel framework to leverage contrastive learning to promote better separation. We assess the performance of SCCL on short text clustering and show that SCCL significantly advances the state-of-the-art results on most benchmark datasets with 3%-11% improvement on Accuracy and 4%-15% improvement on Normalized Mutual Information. Furthermore, our quantitative analysis demonstrates the effectiveness of SCCL in leveraging the strengths of both bottom-up instance discrimination and top-down clustering to achieve better intra-cluster and inter-cluster distances when evaluated with the ground truth cluster labels
Learning from 2D: Pixel-to-Point Knowledge Transfer for 3D Pretraining
Apr 10, 2021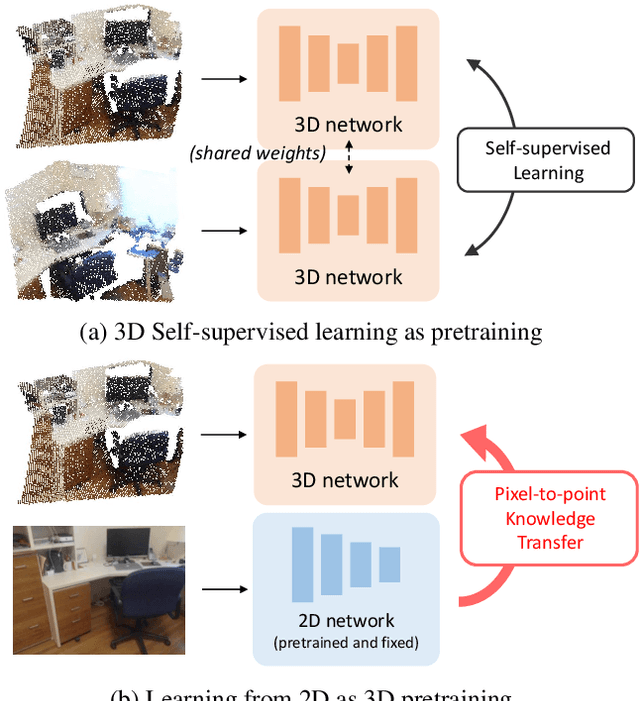
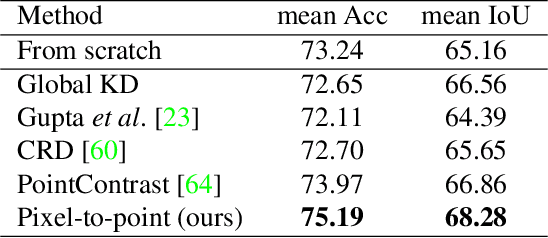
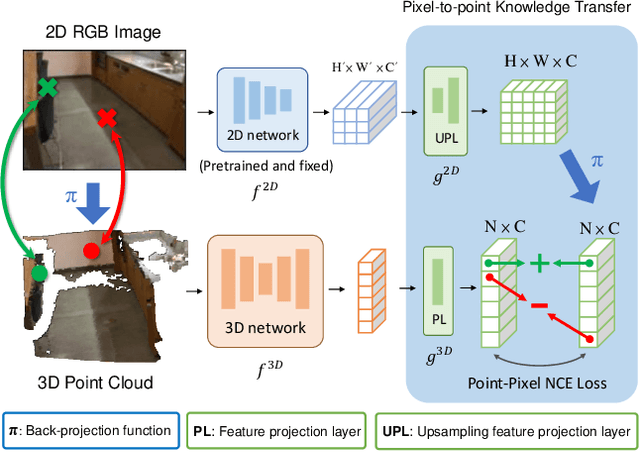
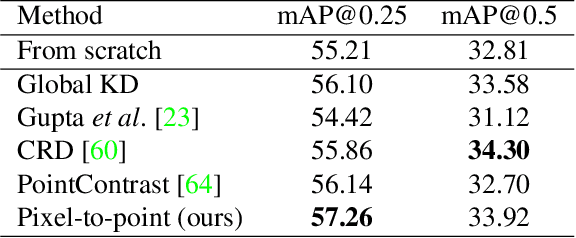
Most of the 3D networks are trained from scratch owning to the lack of large-scale labeled datasets. In this paper, we present a novel 3D pretraining method by leveraging 2D networks learned from rich 2D datasets. We propose the pixel-to-point knowledge transfer to effectively utilize the 2D information by mapping the pixel-level and point-level features into the same embedding space. Due to the heterogeneous nature between 2D and 3D networks, we introduce the back-projection function to align the features between 2D and 3D to make the transfer possible. Additionally, we devise an upsampling feature projection layer to increase the spatial resolution of high-level 2D feature maps, which helps learning fine-grained 3D representations. With a pretrained 2D network, the proposed pretraining process requires no additional 2D or 3D labeled data, further alleviating the expansive 3D data annotation cost. To the best of our knowledge, we are the first to exploit existing 2D trained weights to pretrain 3D deep neural networks. Our intensive experiments show that the 3D models pretrained with 2D knowledge boost the performances across various real-world 3D downstream tasks.
Discriminative Feature Representation with Spatio-temporal Cues for Vehicle Re-identification
Nov 13, 2020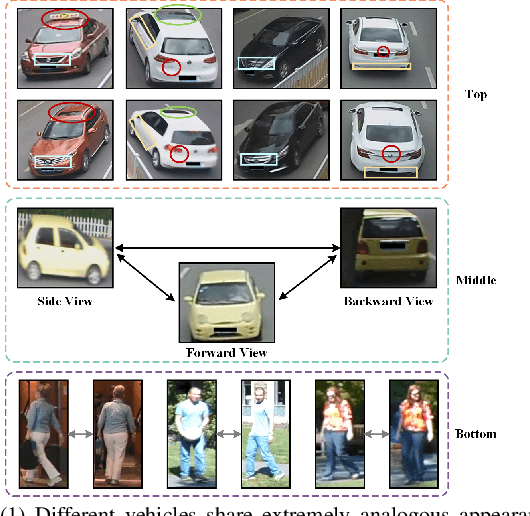
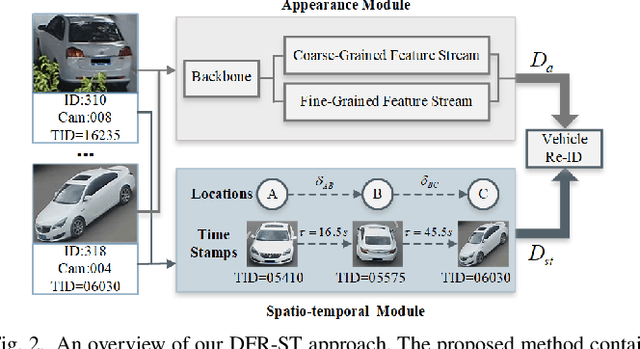
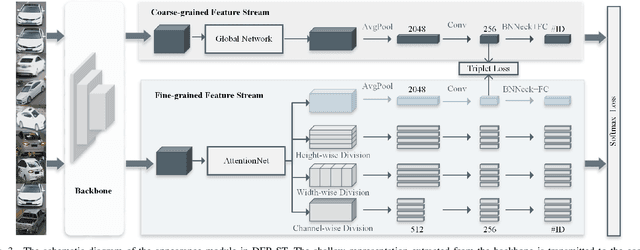
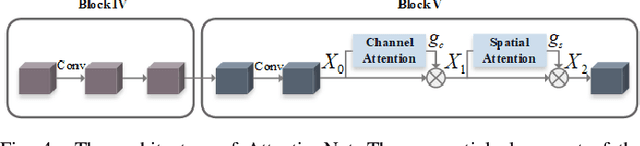
Vehicle re-identification (re-ID) aims to discover and match the target vehicles from a gallery image set taken by different cameras on a wide range of road networks. It is crucial for lots of applications such as security surveillance and traffic management. The remarkably similar appearances of distinct vehicles and the significant changes of viewpoints and illumination conditions take grand challenges to vehicle re-ID. Conventional solutions focus on designing global visual appearances without sufficient consideration of vehicles' spatiotamporal relationships in different images. In this paper, we propose a novel discriminative feature representation with spatiotemporal clues (DFR-ST) for vehicle re-ID. It is capable of building robust features in the embedding space by involving appearance and spatio-temporal information. Based on this multi-modal information, the proposed DFR-ST constructs an appearance model for a multi-grained visual representation by a two-stream architecture and a spatio-temporal metric to provide complementary information. Experimental results on two public datasets demonstrate DFR-ST outperforms the state-of-the-art methods, which validate the effectiveness of the proposed method.
Lifelong Learning with Sketched Structural Regularization
Apr 17, 2021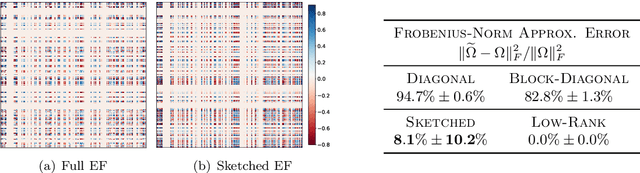
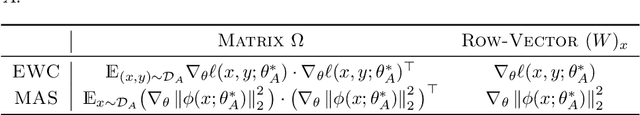
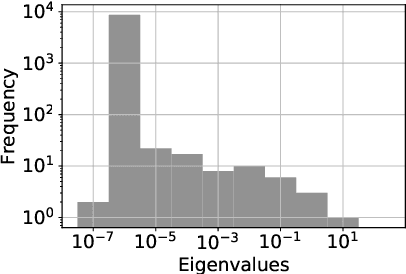
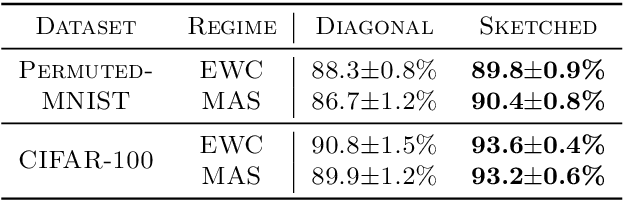
Preventing catastrophic forgetting while continually learning new tasks is an essential problem in lifelong learning. Structural regularization (SR) refers to a family of algorithms that mitigate catastrophic forgetting by penalizing the network for changing its "critical parameters" from previous tasks while learning a new one. The penalty is often induced via a quadratic regularizer defined by an \emph{importance matrix}, e.g., the (empirical) Fisher information matrix in the Elastic Weight Consolidation framework. In practice and due to computational constraints, most SR methods crudely approximate the importance matrix by its diagonal. In this paper, we propose \emph{Sketched Structural Regularization} (Sketched SR) as an alternative approach to compress the importance matrices used for regularizing in SR methods. Specifically, we apply \emph{linear sketching methods} to better approximate the importance matrices in SR algorithms. We show that sketched SR: (i) is computationally efficient and straightforward to implement, (ii) provides an approximation error that is justified in theory, and (iii) is method oblivious by construction and can be adapted to any method that belongs to the structural regularization class. We show that our proposed approach consistently improves various SR algorithms' performance on both synthetic experiments and benchmark continual learning tasks, including permuted-MNIST and CIFAR-100.
A Robust Blockchain Readiness Index Model
Jan 20, 2021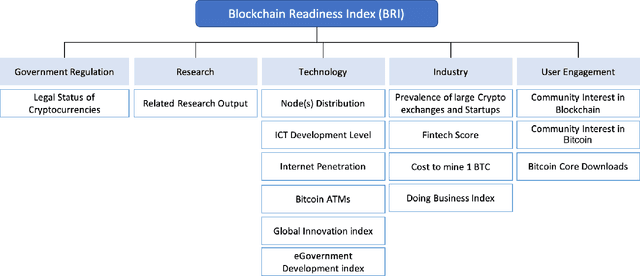
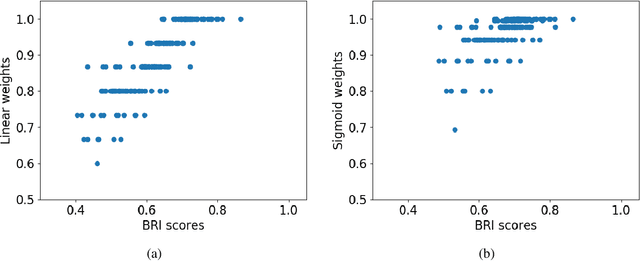

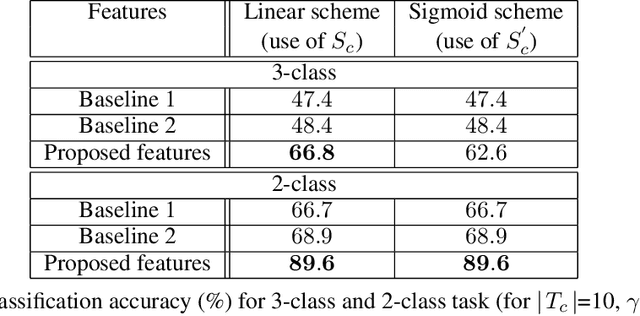
As the blockchain ecosystem gets more mature many businesses, investors, and entrepreneurs are seeking opportunities on working with blockchain systems and cryptocurrencies. A critical challenge for these actors is to identify the most suitable environment to start or evolve their businesses. In general, the question is to identify which countries are offering the most suitable conditions to host their blockchain-based activities and implement their innovative projects. The Blockchain Readiness Index (BRI) provides a numerical metric (referred to as the blockchain readiness score) in measuring the maturity/readiness levels of a country in adopting blockchain and cryptocurrencies. In doing so, BRI leverages on techniques from information retrieval to algorithmically derive an index ranking for a set of countries. The index considers a range of indicators organized under five pillars: Government Regulation, Research, Technology, Industry, and User Engagement. In this paper, we further extent BRI with the capability of deriving the index - at the country level - even in the presence of missing information for the indicators. In doing so, we are proposing two weighting schemes namely, linear and sigmoid weighting for refining the initial estimates for the indicator values. A classification framework was employed to evaluate the effectiveness of the developed techniques which yielded to a significant classification accuracy.
Lane detection in complex scenes based on end-to-end neural network
Oct 26, 2020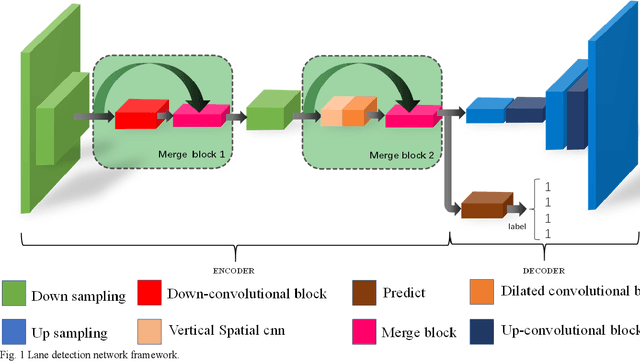
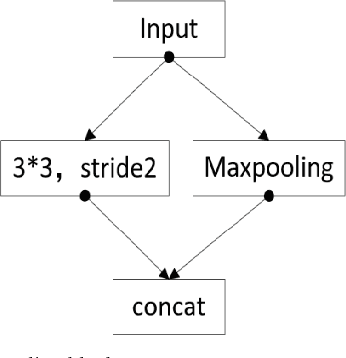
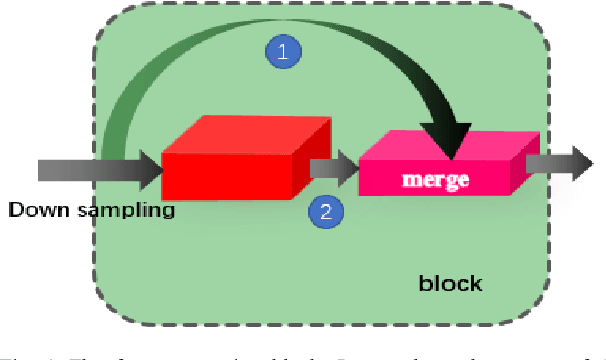

The lane detection is a key problem to solve the division of derivable areas in unmanned driving, and the detection accuracy of lane lines plays an important role in the decision-making of vehicle driving. Scenes faced by vehicles in daily driving are relatively complex. Bright light, insufficient light, and crowded vehicles will bring varying degrees of difficulty to lane detection. So we combine the advantages of spatial convolution in spatial information processing and the efficiency of ERFNet in semantic segmentation, propose an end-to-end network to lane detection in a variety of complex scenes. And we design the information exchange block by combining spatial convolution and dilated convolution, which plays a great role in understanding detailed information. Finally, our network was tested on the CULane database and its F1-measure with IOU threshold of 0.5 can reach 71.9%.
Complex Factoid Question Answering with a Free-Text Knowledge Graph
Mar 23, 2021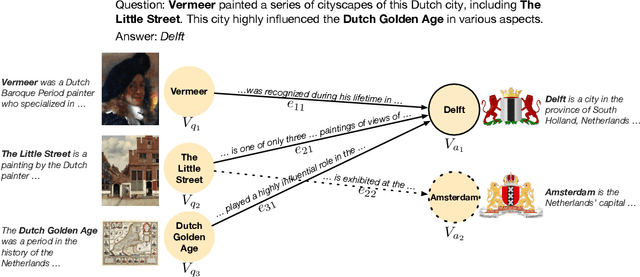
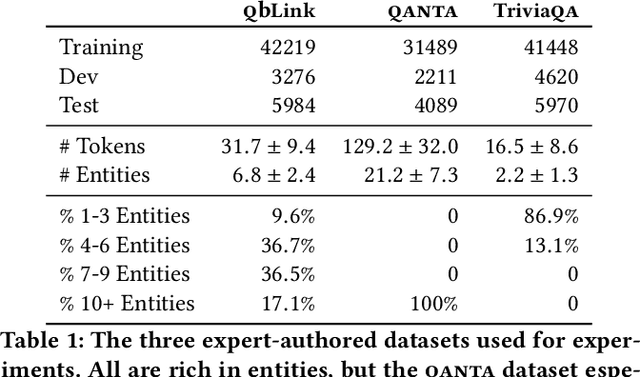
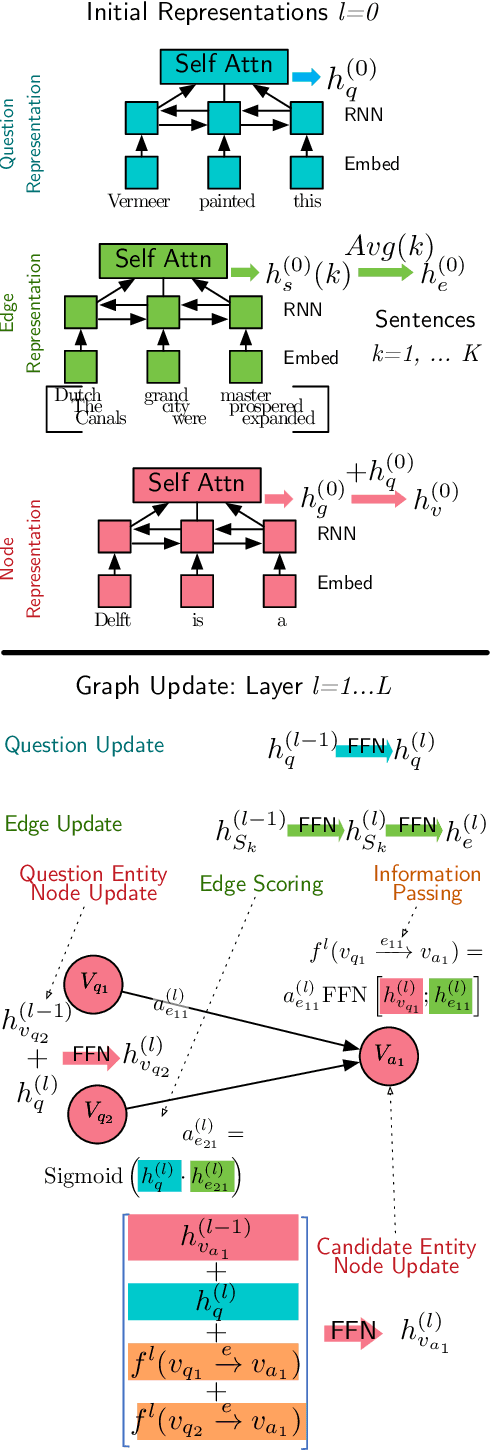

We introduce DELFT, a factoid question answering system which combines the nuance and depth of knowledge graph question answering approaches with the broader coverage of free-text. DELFT builds a free-text knowledge graph from Wikipedia, with entities as nodes and sentences in which entities co-occur as edges. For each question, DELFT finds the subgraph linking question entity nodes to candidates using text sentences as edges, creating a dense and high coverage semantic graph. A novel graph neural network reasons over the free-text graph-combining evidence on the nodes via information along edge sentences-to select a final answer. Experiments on three question answering datasets show DELFT can answer entity-rich questions better than machine reading based models, bert-based answer ranking and memory networks. DELFT's advantage comes from both the high coverage of its free-text knowledge graph-more than double that of dbpedia relations-and the novel graph neural network which reasons on the rich but noisy free-text evidence.