 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeSeq: Taming Sparse Multimodal Motion Prediction with Sequential Mode Modeling
Nov 17, 2024



Anticipating the multimodality of future events lays the foundation for safe autonomous driving. However, multimodal motion prediction for traffic agents has been clouded by the lack of multimodal ground truth. Existing works predominantly adopt the winner-take-all training strategy to tackle this challenge, yet still suffer from limited trajectory diversity and misaligned mode confidence. While some approaches address these limitations by generating excessive trajectory candidates, they necessitate a post-processing stage to identify the most representative modes, a process lacking universal principles and compromising trajectory accuracy. We are thus motivated to introduce ModeSeq, a new multimodal prediction paradigm that models modes as sequences. Unlike the common practice of decoding multiple plausible trajectories in one shot, ModeSeq requires motion decoders to infer the next mode step by step, thereby more explicitly capturing the correlation between modes and significantly enhancing the ability to reason about multimodality. Leveraging the inductive bias of sequential mode prediction, we also propose the Early-Match-Take-All (EMTA) training strategy to diversify the trajectories further. Without relying on dense mode prediction or rule-based trajectory selection, ModeSeq considerably improves the diversity of multimodal output while attaining satisfactory trajectory accuracy, resulting in balanced performance on motion prediction benchmarks. Moreover, ModeSeq naturally emerges with the capability of mode extrapolation, which supports forecasting more behavior modes when the future is highly uncertain.
A Reference-Based 3D Semantic-Aware Framework for Accurate Local Facial Attribute Editing
Jul 29, 2024



Facial attribute editing plays a crucial role in synthesizing realistic faces with specific characteristics while maintaining realistic appearances. Despite advancements, challenges persist in achieving precise, 3D-aware attribute modifications, which are crucial for consistent and accurate representations of faces from different angles. Current methods struggle with semantic entanglement and lack effective guidance for incorporating attributes while maintaining image integrity. To address these issues, we introduce a novel framework that merges the strengths of latent-based and reference-based editing methods. Our approach employs a 3D GAN inversion technique to embed attributes from the reference image into a tri-plane space, ensuring 3D consistency and realistic viewing from multiple perspectives. We utilize blending techniques and predicted semantic masks to locate precise edit regions, merging them with the contextual guidance from the reference image. A coarse-to-fine inpainting strategy is then applied to preserve the integrity of untargeted areas, significantly enhancing realism. Our evaluations demonstrate superior performance across diverse editing tasks, validating our framework's effectiveness in realistic and applicable facial attribute editing.
BehaviorGPT: Smart Agent Simulation for Autonomous Driving with Next-Patch Prediction
May 27, 2024



Simulating realistic interactions among traffic agents is crucial for efficiently validating the safety of autonomous driving systems. Existing leading simulators primarily use an encoder-decoder structure to encode the historical trajectories for future simulation. However, such a paradigm complicates the model architecture, and the manual separation of history and future trajectories leads to low data utilization. To address these challenges, we propose Behavior Generative Pre-trained Transformers (BehaviorGPT), a decoder-only, autoregressive architecture designed to simulate the sequential motion of multiple agents. Crucially, our approach discards the traditional separation between "history" and "future," treating each time step as the "current" one, resulting in a simpler, more parameter- and data-efficient design that scales seamlessly with data and computation. Additionally, we introduce the Next-Patch Prediction Paradigm (NP3), which enables models to reason at the patch level of trajectories and capture long-range spatial-temporal interactions. BehaviorGPT ranks first across several metrics on the Waymo Sim Agents Benchmark, demonstrating its exceptional performance in multi-agent and agent-map interactions. We outperformed state-of-the-art models with a realism score of 0.741 and improved the minADE metric to 1.540, with an approximately 91.6% reduction in model parameters.
QCNeXt: A Next-Generation Framework For Joint Multi-Agent Trajectory Prediction
Jun 18, 2023Estimating the joint distribution of on-road agents' future trajectories is essential for autonomous driving. In this technical report, we propose a next-generation framework for joint multi-agent trajectory prediction called QCNeXt. First, we adopt the query-centric encoding paradigm for the task of joint multi-agent trajectory prediction. Powered by this encoding scheme, our scene encoder is equipped with permutation equivariance on the set elements, roto-translation invariance in the space dimension, and translation invariance in the time dimension. These invariance properties not only enable accurate multi-agent forecasting fundamentally but also empower the encoder with the capability of streaming processing. Second, we propose a multi-agent DETR-like decoder, which facilitates joint multi-agent trajectory prediction by modeling agents' interactions at future time steps. For the first time, we show that a joint prediction model can outperform marginal prediction models even on the marginal metrics, which opens up new research opportunities in trajectory prediction. Our approach ranks 1st on the Argoverse 2 multi-agent motion forecasting benchmark, winning the championship of the Argoverse Challenge at the CVPR 2023 Workshop on Autonomous Driving.
Multi-Stream Attention Learning for Monocular Vehicle Velocity and Inter-Vehicle Distance Estimation
Oct 22, 2021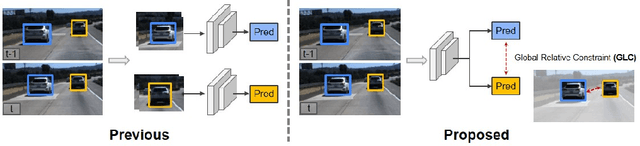
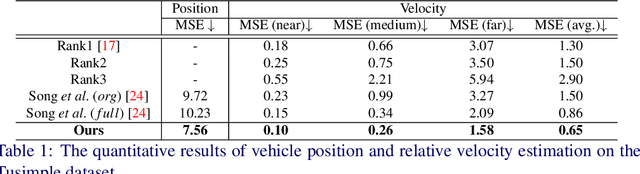
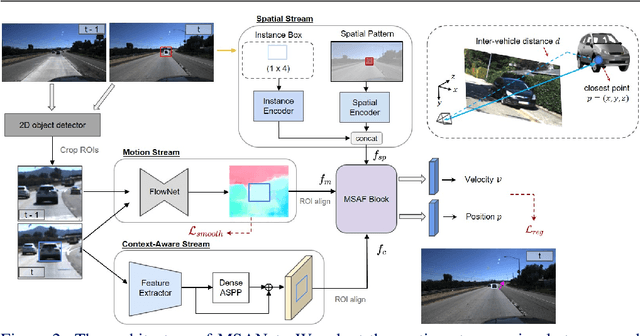

Vehicle velocity and inter-vehicle distance estimation are essential for ADAS (Advanced driver-assistance systems) and autonomous vehicles. To save the cost of expensive ranging sensors, recent studies focus on using a low-cost monocular camera to perceive the environment around the vehicle in a data-driven fashion. Existing approaches treat each vehicle independently for perception and cause inconsistent estimation. Furthermore, important information like context and spatial relation in 2D object detection is often neglected in the velocity estimation pipeline. In this paper, we explore the relationship between vehicles of the same frame with a global-relative-constraint (GLC) loss to encourage consistent estimation. A novel multi-stream attention network (MSANet) is proposed to extract different aspects of features, e.g., spatial and contextual features, for joint vehicle velocity and inter-vehicle distance estimation. Experiments show the effectiveness and robustness of our proposed approach. MSANet outperforms state-of-the-art algorithms on both the KITTI dataset and TuSimple velocity dataset.
ReDAL: Region-based and Diversity-aware Active Learning for Point Cloud Semantic Segmentation
Aug 07, 2021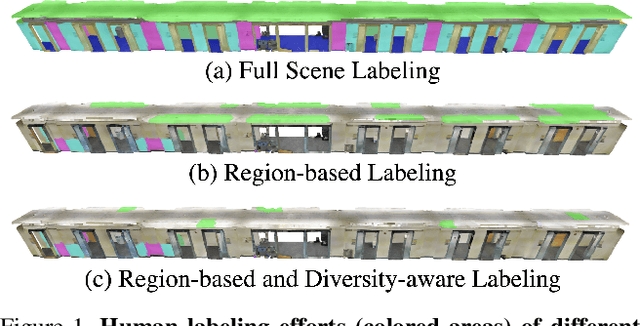


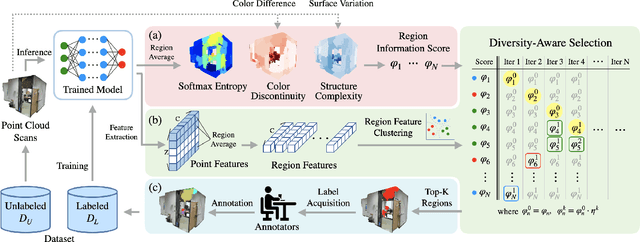
Despite the success of deep learning on supervised point cloud semantic segmentation, obtaining large-scale point-by-point manual annotations is still a significant challenge. To reduce the huge annotation burden, we propose a Region-based and Diversity-aware Active Learning (ReDAL), a general framework for many deep learning approaches, aiming to automatically select only informative and diverse sub-scene regions for label acquisition. Observing that only a small portion of annotated regions are sufficient for 3D scene understanding with deep learning, we use softmax entropy, color discontinuity, and structural complexity to measure the information of sub-scene regions. A diversity-aware selection algorithm is also developed to avoid redundant annotations resulting from selecting informative but similar regions in a querying batch. Extensive experiments show that our method highly outperforms previous active learning strategies, and we achieve the performance of 90% fully supervised learning, while less than 15% and 5% annotations are required on S3DIS and SemanticKITTI datasets, respectively.
Learning from 2D: Pixel-to-Point Knowledge Transfer for 3D Pretraining
Apr 10, 2021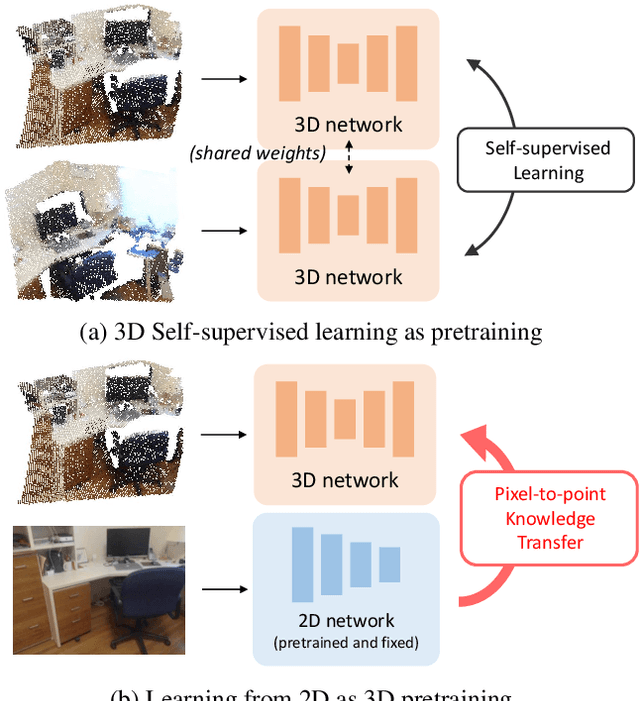
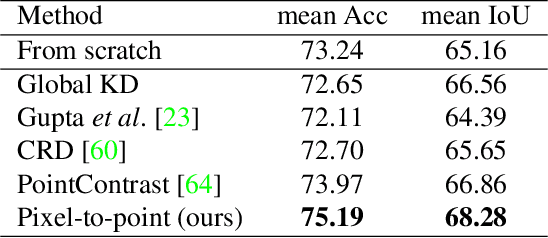
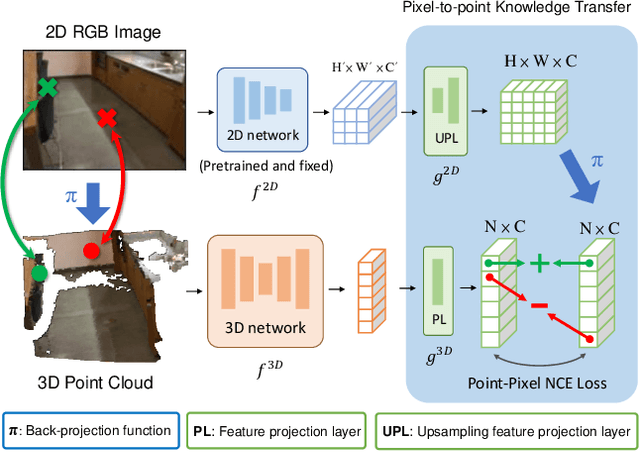
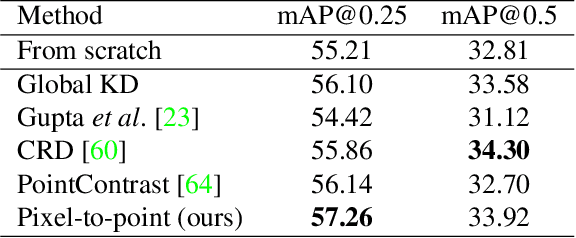
Most of the 3D networks are trained from scratch owning to the lack of large-scale labeled datasets. In this paper, we present a novel 3D pretraining method by leveraging 2D networks learned from rich 2D datasets. We propose the pixel-to-point knowledge transfer to effectively utilize the 2D information by mapping the pixel-level and point-level features into the same embedding space. Due to the heterogeneous nature between 2D and 3D networks, we introduce the back-projection function to align the features between 2D and 3D to make the transfer possible. Additionally, we devise an upsampling feature projection layer to increase the spatial resolution of high-level 2D feature maps, which helps learning fine-grained 3D representations. With a pretrained 2D network, the proposed pretraining process requires no additional 2D or 3D labeled data, further alleviating the expansive 3D data annotation cost. To the best of our knowledge, we are the first to exploit existing 2D trained weights to pretrain 3D deep neural networks. Our intensive experiments show that the 3D models pretrained with 2D knowledge boost the performances across various real-world 3D downstream tasks.
Unsupervised Disentanglement of Linear-Encoded Facial Semantics
Mar 30, 2021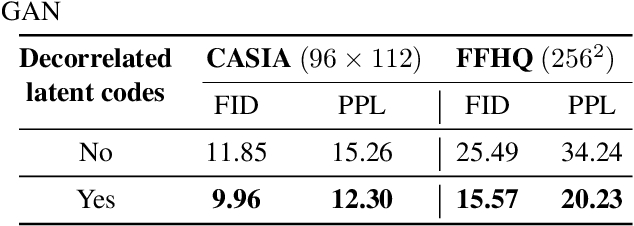
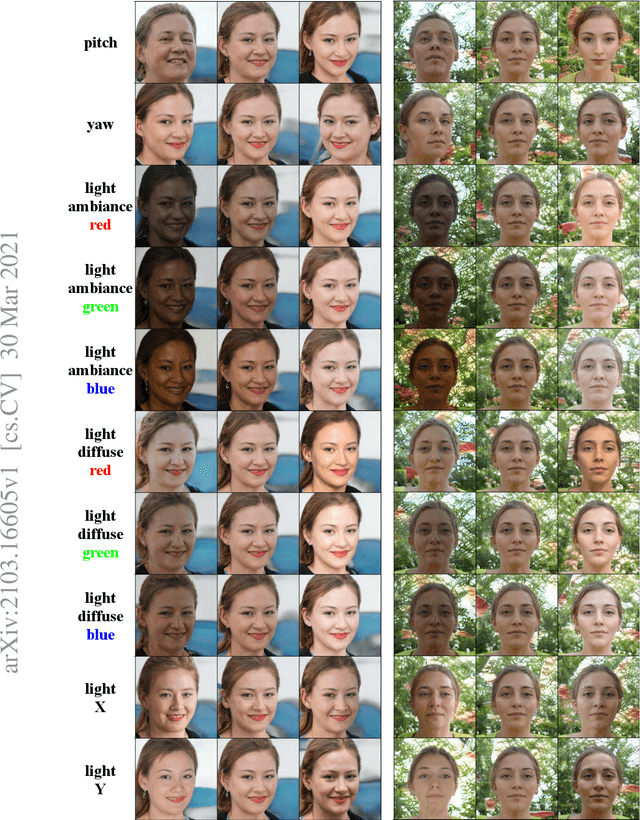
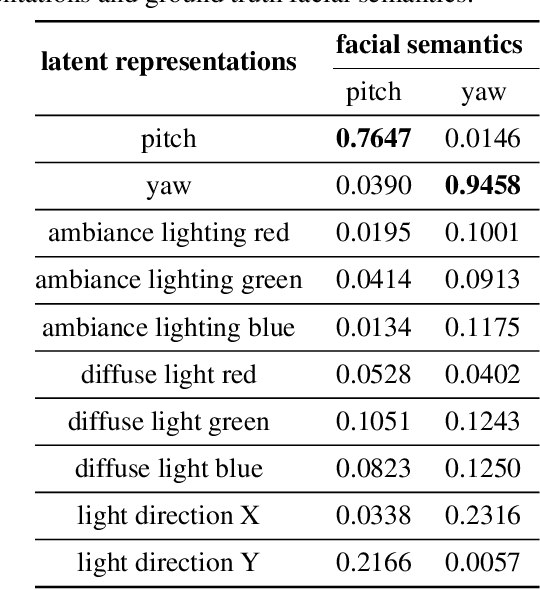
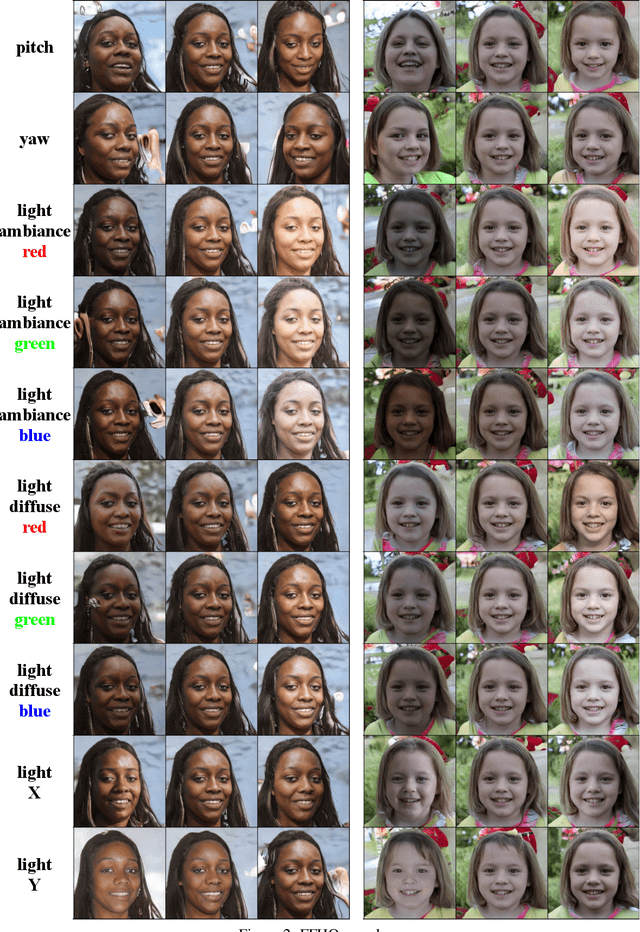
We propose a method to disentangle linear-encoded facial semantics from StyleGAN without external supervision. The method derives from linear regression and sparse representation learning concepts to make the disentangled latent representations easily interpreted as well. We start by coupling StyleGAN with a stabilized 3D deformable facial reconstruction method to decompose single-view GAN generations into multiple semantics. Latent representations are then extracted to capture interpretable facial semantics. In this work, we make it possible to get rid of labels for disentangling meaningful facial semantics. Also, we demonstrate that the guided extrapolation along the disentangled representations can help with data augmentation, which sheds light on handling unbalanced data. Finally, we provide an analysis of our learned localized facial representations and illustrate that the semantic information is encoded, which surprisingly complies with human intuition. The overall unsupervised design brings more flexibility to representation learning in the wild.
$S^3$: Learnable Sparse Signal Superdensity for Guided Depth Estimation
Mar 22, 2021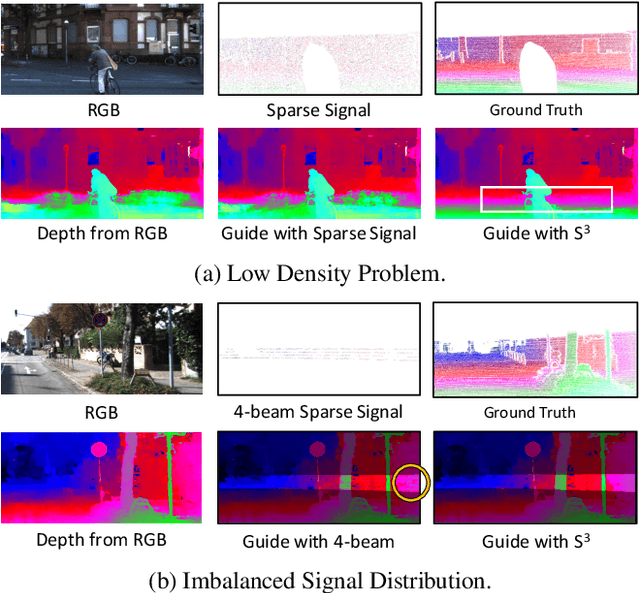

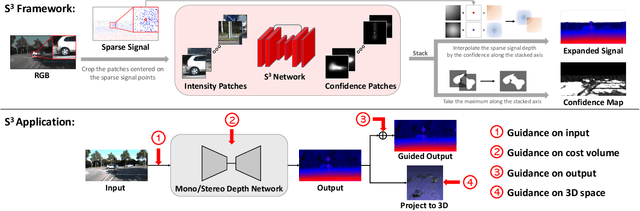
Dense depth estimation plays a key role in multiple applications such as robotics, 3D reconstruction, and augmented reality. While sparse signal, e.g., LiDAR and Radar, has been leveraged as guidance for enhancing dense depth estimation, the improvement is limited due to its low density and imbalanced distribution. To maximize the utility from the sparse source, we propose $S^3$ technique, which expands the depth value from sparse cues while estimating the confidence of expanded region. The proposed $S^3$ can be applied to various guided depth estimation approaches and trained end-to-end at different stages, including input, cost volume and output. Extensive experiments demonstrate the effectiveness, robustness, and flexibility of the $S^3$ technique on LiDAR and Radar signal.
Expanding Sparse Guidance for Stereo Matching
Apr 24, 2020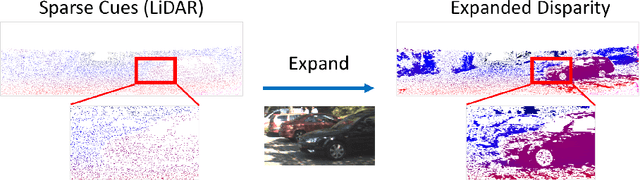
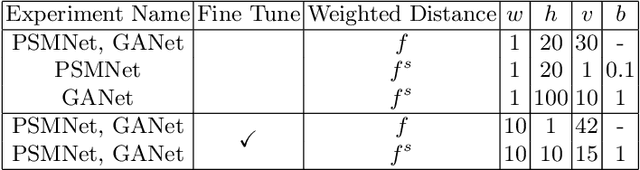
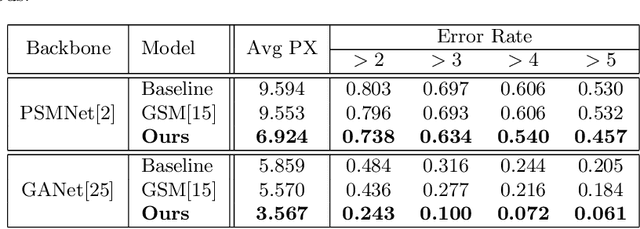

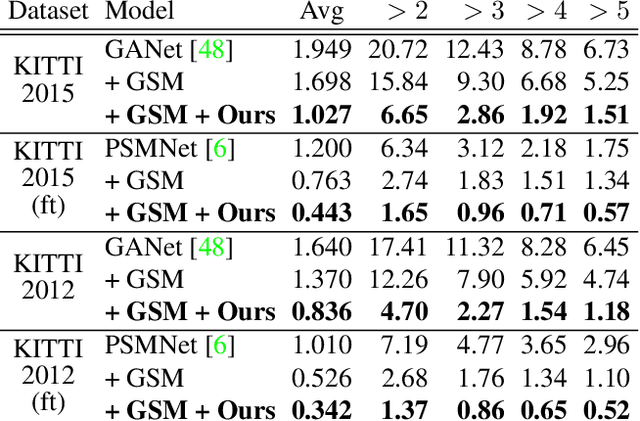
The performance of image based stereo estimation suffers from lighting variations, repetitive patterns and homogeneous appearance. Moreover, to achieve good performance, stereo supervision requires sufficient densely-labeled data, which are hard to obtain. In this work, we leverage small amount of data with very sparse but accurate disparity cues from LiDAR to bridge the gap. We propose a novel sparsity expansion technique to expand the sparse cues concerning RGB images for local feature enhancement. The feature enhancement method can be easily applied to any stereo estimation algorithms with cost volume at the test stage. Extensive experiments on stereo datasets demonstrate the effectiveness and robustness across different backbones on domain adaption and self-supervision scenario. Our sparsity expansion method outperforms previous methods in terms of disparity by more than 2 pixel error on KITTI Stereo 2012 and 3 pixel error on KITTI Stereo 2015. Our approach significantly boosts the existing state-of-the-art stereo algorithms with extremely sparse cues.