 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies
Jun 11, 2024



A diverse array of reasoning strategies has been proposed to elicit the capabilities of large language models. However, in this paper, we point out that traditional evaluations which focus solely on performance metrics miss a key factor: the increased effectiveness due to additional compute. By overlooking this aspect, a skewed view of strategy efficiency is often presented. This paper introduces a framework that incorporates the compute budget into the evaluation, providing a more informative comparison that takes into account both performance metrics and computational cost. In this budget-aware perspective, we find that complex reasoning strategies often don't surpass simpler baselines purely due to algorithmic ingenuity, but rather due to the larger computational resources allocated. When we provide a simple baseline like chain-of-thought self-consistency with comparable compute resources, it frequently outperforms reasoning strategies proposed in the literature. In this scale-aware perspective, we find that unlike self-consistency, certain strategies such as multi-agent debate or Reflexion can become worse if more compute budget is utilized.
Repoformer: Selective Retrieval for Repository-Level Code Completion
Mar 15, 2024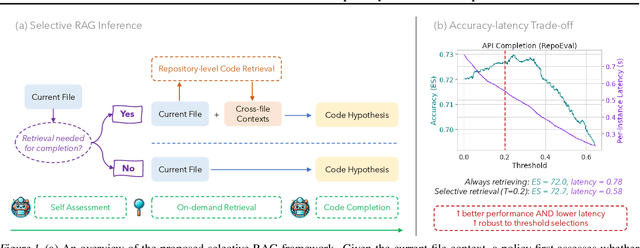
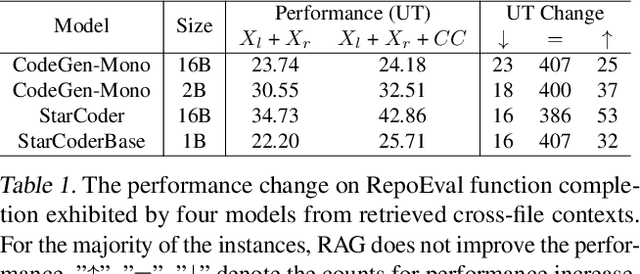
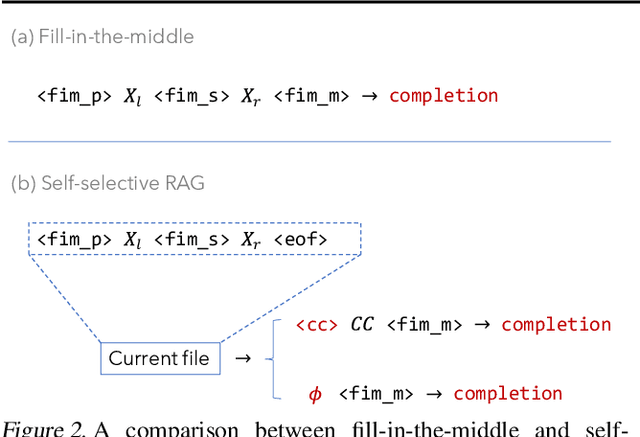
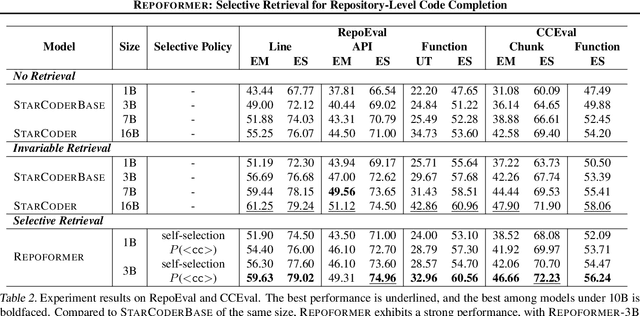
Recent advances in retrieval-augmented generation (RAG) have initiated a new era in repository-level code completion. However, the invariable use of retrieval in existing methods exposes issues in both efficiency and robustness, with a large proportion of the retrieved contexts proving unhelpful or harmful to code language models (code LMs). To tackle the challenges, this paper proposes a selective RAG framework where retrieval is avoided when unnecessary. To power this framework, we design a self-supervised learning approach that enables a code LM to accurately self-evaluate whether retrieval can improve its output quality and robustly leverage the potentially noisy retrieved contexts. Using this LM as both the selective retrieval policy and the generation model, our framework consistently outperforms the state-of-the-art prompting with an invariable retrieval approach on diverse benchmarks including RepoEval, CrossCodeEval, and a new benchmark. Meanwhile, our selective retrieval strategy results in strong efficiency improvements by as much as 70% inference speedup without harming the performance. We demonstrate that our framework effectively accommodates different generation models, retrievers, and programming languages. These advancements position our framework as an important step towards more accurate and efficient repository-level code completion.
Code Representation Learning At Scale
Feb 02, 2024



Recent studies have shown that code language models at scale demonstrate significant performance gains on downstream tasks, i.e., code generation. However, most of the existing works on code representation learning train models at a hundred million parameter scale using very limited pretraining corpora. In this work, we fuel code representation learning with a vast amount of code data via a two-stage pretraining scheme. We first train the encoders via a mix that leverages both randomness in masking language modeling and the structure aspect of programming language. We then enhance the representations via contrastive learning with hard negative and hard positive constructed in an unsupervised manner. We establish an off-the-shelf encoder model that persistently outperforms the existing models on a wide variety of downstream tasks by large margins. To comprehend the factors contributing to successful code representation learning, we conduct detailed ablations and share our findings on (i) a customized and effective token-level denoising scheme for source code; (ii) the importance of hard negatives and hard positives; (iii) how the proposed bimodal contrastive learning boost the cross-lingual semantic search performance; and (iv) how the pretraining schemes decide the downstream task performance scales with the model size.
* 10 pages
Exploring Continual Learning for Code Generation Models
Jul 05, 2023



Large-scale code generation models such as Codex and CodeT5 have achieved impressive performance. However, libraries are upgraded or deprecated very frequently and re-training large-scale language models is computationally expensive. Therefore, Continual Learning (CL) is an important aspect that remains underexplored in the code domain. In this paper, we introduce a benchmark called CodeTask-CL that covers a wide range of tasks, including code generation, translation, summarization, and refinement, with different input and output programming languages. Next, on our CodeTask-CL benchmark, we compare popular CL techniques from NLP and Vision domains. We find that effective methods like Prompt Pooling (PP) suffer from catastrophic forgetting due to the unstable training of the prompt selection mechanism caused by stark distribution shifts in coding tasks. We address this issue with our proposed method, Prompt Pooling with Teacher Forcing (PP-TF), that stabilizes training by enforcing constraints on the prompt selection mechanism and leads to a 21.54% improvement over Prompt Pooling. Along with the benchmark, we establish a training pipeline that can be used for CL on code models, which we believe can motivate further development of CL methods for code models. Our code is available at https://github.com/amazon-science/codetaskcl-pptf
ContraGen: Effective Contrastive Learning For Causal Language Model
Oct 03, 2022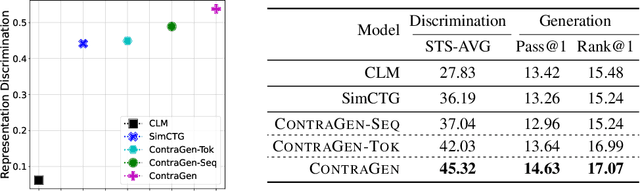
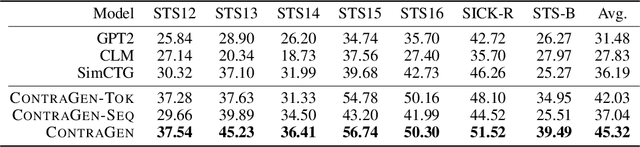
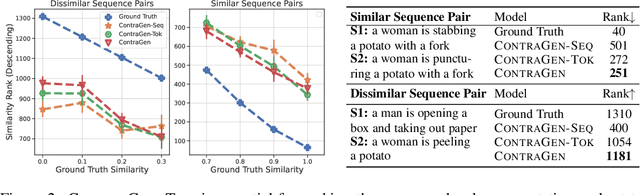
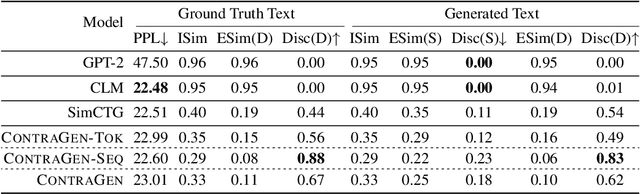
Despite exciting progress in large-scale language generation, the expressiveness of its representations is severely limited by the \textit{anisotropy} issue where the hidden representations are distributed into a narrow cone in the vector space. To address this issue, we present ContraGen, a novel contrastive learning framework to improve the representation with better uniformity and discrimination. We assess ContraGen on a wide range of downstream tasks in natural and programming languages. We show that ContraGen can effectively enhance both uniformity and discrimination of the representations and lead to the desired improvement on various language understanding tasks where discriminative representations are crucial for attaining good performance. Specifically, we attain $44\%$ relative improvement on the Semantic Textual Similarity tasks and $34\%$ on Code-to-Code Search tasks. Furthermore, by improving the expressiveness of the representations, ContraGen also boosts the source code generation capability with $9\%$ relative improvement on execution accuracy on the HumanEval benchmark.
Learning Dialogue Representations from Consecutive Utterances
May 26, 2022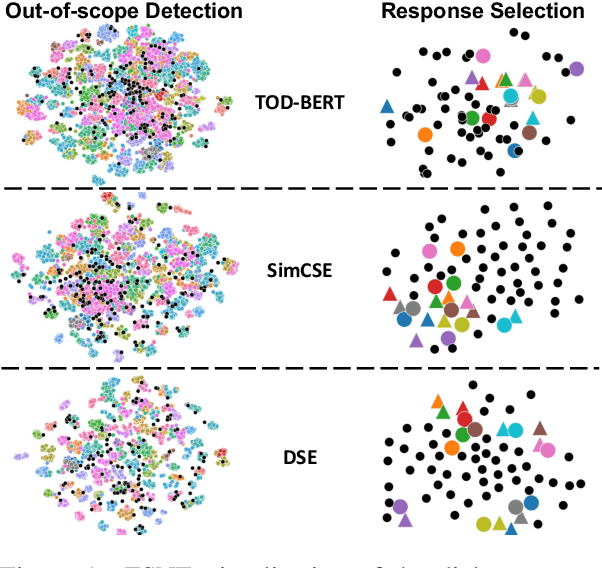

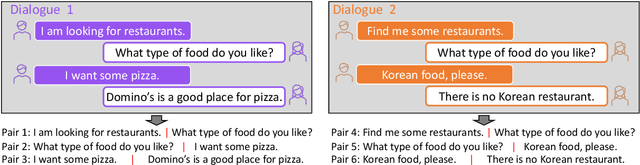
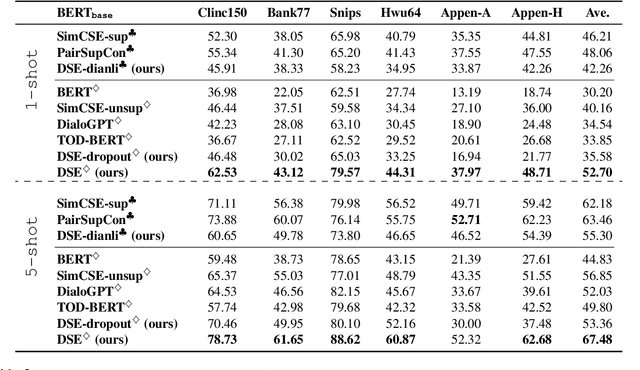
Learning high-quality dialogue representations is essential for solving a variety of dialogue-oriented tasks, especially considering that dialogue systems often suffer from data scarcity. In this paper, we introduce Dialogue Sentence Embedding (DSE), a self-supervised contrastive learning method that learns effective dialogue representations suitable for a wide range of dialogue tasks. DSE learns from dialogues by taking consecutive utterances of the same dialogue as positive pairs for contrastive learning. Despite its simplicity, DSE achieves significantly better representation capability than other dialogue representation and universal sentence representation models. We evaluate DSE on five downstream dialogue tasks that examine dialogue representation at different semantic granularities. Experiments in few-shot and zero-shot settings show that DSE outperforms baselines by a large margin. For example, it achieves 13 average performance improvement over the strongest unsupervised baseline in 1-shot intent classification on 6 datasets. We also provide analyses on the benefits and limitations of our model.
QaNER: Prompting Question Answering Models for Few-shot Named Entity Recognition
Mar 04, 2022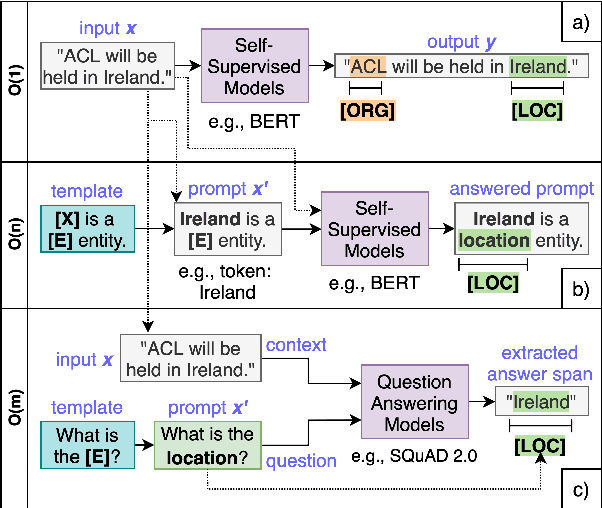

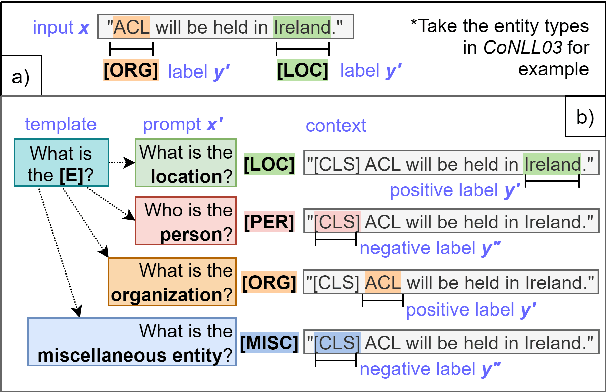
Recently, prompt-based learning for pre-trained language models has succeeded in few-shot Named Entity Recognition (NER) by exploiting prompts as task guidance to increase label efficiency. However, previous prompt-based methods for few-shot NER have limitations such as a higher computational complexity, poor zero-shot ability, requiring manual prompt engineering, or lack of prompt robustness. In this work, we address these shortcomings by proposing a new prompt-based learning NER method with Question Answering (QA), called QaNER. Our approach includes 1) a refined strategy for converting NER problems into the QA formulation; 2) NER prompt generation for QA models; 3) prompt-based tuning with QA models on a few annotated NER examples; 4) zero-shot NER by prompting the QA model. Comparing the proposed approach with previous methods, QaNER is faster at inference, insensitive to the prompt quality, and robust to hyper-parameters, as well as demonstrating significantly better low-resource performance and zero-shot capability.
Virtual Augmentation Supported Contrastive Learning of Sentence Representations
Oct 16, 2021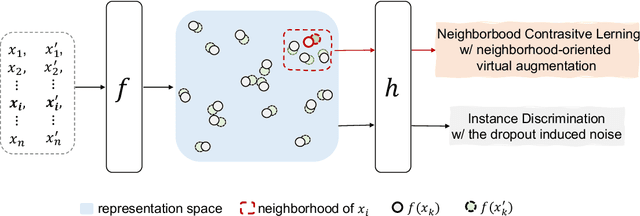
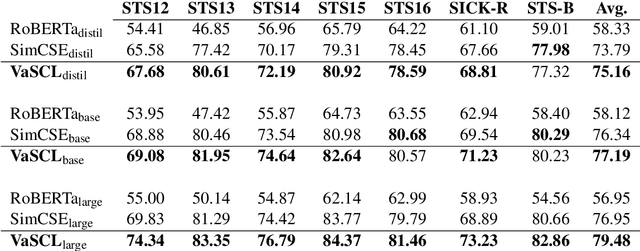
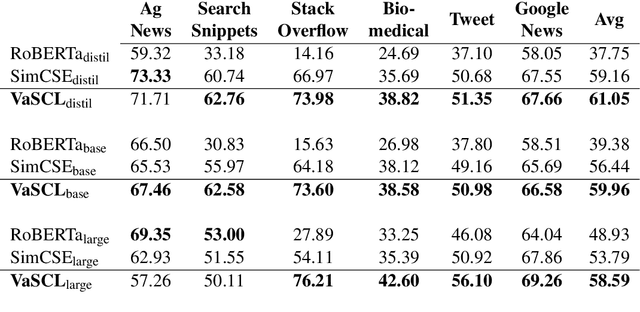
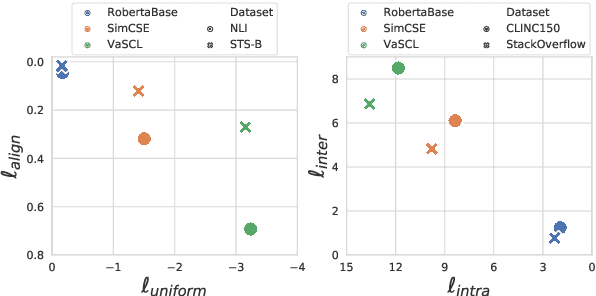
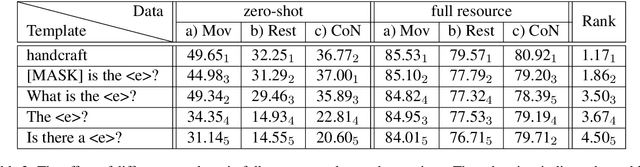
Despite profound successes, contrastive representation learning relies on carefully designed data augmentations using domain specific knowledge. This challenge is magnified in natural language processing where no general rules exist for data augmentation due to the discrete nature of natural language. We tackle this challenge by presenting a Virtual augmentation Supported Contrastive Learning of sentence representations (VaSCL). Originating from the interpretation that data augmentation essentially constructs the neighborhoods of each training instance, we in turn utilize the neighborhood to generate effective data augmentations. Leveraging the large training batch size of contrastive learning, we approximate the neighborhood of an instance via its K-nearest in-batch neighbors in the representation space. We then define an instance discrimination task within this neighborhood, and generate the virtual augmentation in an adversarial training manner. We access the performance of VaSCL on a wide range of downstream tasks, and set a new state-of-the-art for unsupervised sentence representation learning.
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
Oct 16, 2021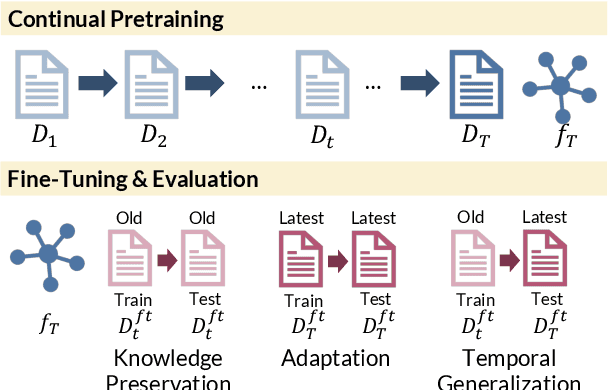
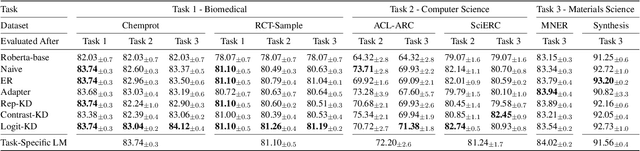
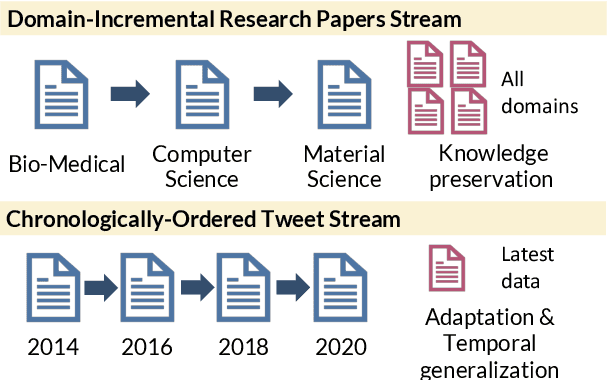
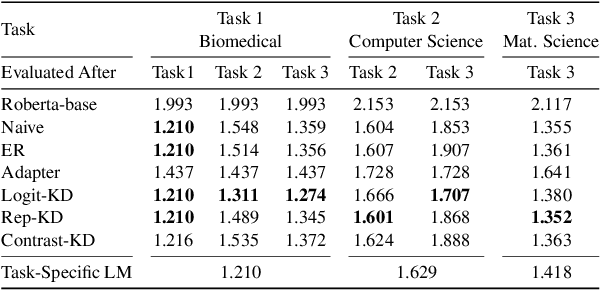
Pretrained language models (PTLMs) are typically learned over a large, static corpus and further fine-tuned for various downstream tasks. However, when deployed in the real world, a PTLM-based model must deal with data from a new domain that deviates from what the PTLM was initially trained on, or newly emerged data that contains out-of-distribution information. In this paper, we study a lifelong language model pretraining challenge where a PTLM is continually updated so as to adapt to emerging data. Over a domain-incremental research paper stream and a chronologically ordered tweet stream, we incrementally pretrain a PTLM with different continual learning algorithms, and keep track of the downstream task performance (after fine-tuning) to analyze its ability of acquiring new knowledge and preserving learned knowledge. Our experiments show continual learning algorithms improve knowledge preservation, with logit distillation being the most effective approach. We further show that continual pretraining improves generalization when training and testing data of downstream tasks are drawn from different time steps, but do not improve when they are from the same time steps. We believe our problem formulation, methods, and analysis will inspire future studies towards continual pretraining of language models.
Knowledge Enhanced Pretrained Language Models: A Compreshensive Survey
Oct 16, 2021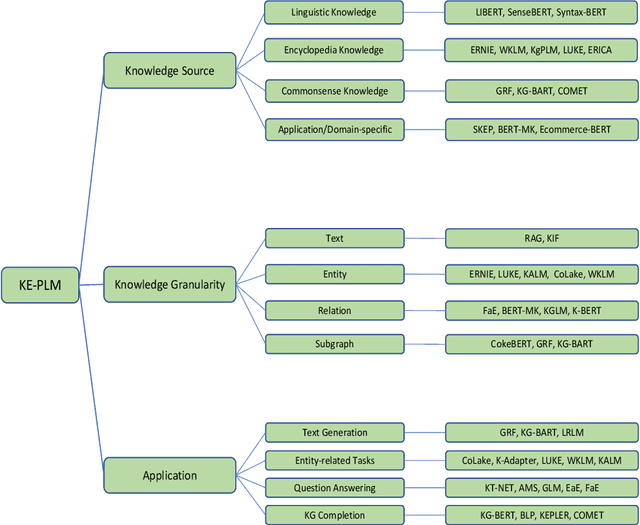

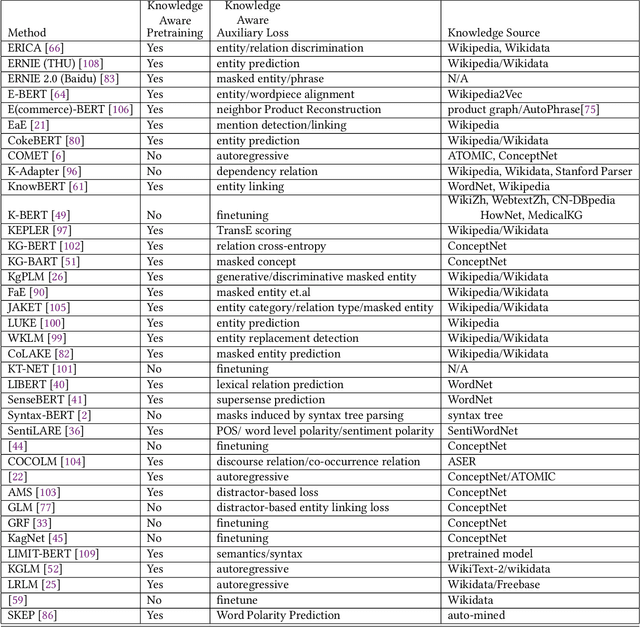
Pretrained Language Models (PLM) have established a new paradigm through learning informative contextualized representations on large-scale text corpus. This new paradigm has revolutionized the entire field of natural language processing, and set the new state-of-the-art performance for a wide variety of NLP tasks. However, though PLMs could store certain knowledge/facts from training corpus, their knowledge awareness is still far from satisfactory. To address this issue, integrating knowledge into PLMs have recently become a very active research area and a variety of approaches have been developed. In this paper, we provide a comprehensive survey of the literature on this emerging and fast-growing field - Knowledge Enhanced Pretrained Language Models (KE-PLMs). We introduce three taxonomies to categorize existing work. Besides, we also survey the various NLU and NLG applications on which KE-PLM has demonstrated superior performance over vanilla PLMs. Finally, we discuss challenges that face KE-PLMs and also promising directions for future research.