 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff3R: Feed-forward 3D Gaussian Splatting with Uncertainty-aware Differentiable Optimization
Apr 01, 2026Recent advances in 3D Gaussian Splatting (3DGS) present two main directions: feed-forward models offer fast inference in sparse-view settings, while per-scene optimization yields high-quality renderings but is computationally expensive. To combine the benefits of both, we introduce Diff3R, a novel framework that explicitly bridges feed-forward prediction and test-time optimization. By incorporating a differentiable 3DGS optimization layer directly into the training loop, our network learns to predict an optimal initialization for test-time optimization rather than a conventional zero-shot result. To overcome the computational cost of backpropagating through the optimization steps, we propose computing gradients via the Implicit Function Theorem and a scalable, matrix-free PCG solver tailored for 3DGS optimization. Additionally, we incorporate a data-driven uncertainty model into the optimization process by adaptively controlling how much the parameters are allowed to change during optimization. This approach effectively mitigates overfitting in under-constrained regions and increases robustness against input outliers. Since our proposed optimization layer is model-agnostic, we show that it can be seamlessly integrated into existing feed-forward 3DGS architectures for both pose-given and pose-free methods, providing improvements for test-time optimization.
TUM2TWIN: Introducing the Large-Scale Multimodal Urban Digital Twin Benchmark Dataset
May 13, 2025



Urban Digital Twins (UDTs) have become essential for managing cities and integrating complex, heterogeneous data from diverse sources. Creating UDTs involves challenges at multiple process stages, including acquiring accurate 3D source data, reconstructing high-fidelity 3D models, maintaining models' updates, and ensuring seamless interoperability to downstream tasks. Current datasets are usually limited to one part of the processing chain, hampering comprehensive UDTs validation. To address these challenges, we introduce the first comprehensive multimodal Urban Digital Twin benchmark dataset: TUM2TWIN. This dataset includes georeferenced, semantically aligned 3D models and networks along with various terrestrial, mobile, aerial, and satellite observations boasting 32 data subsets over roughly 100,000 $m^2$ and currently 767 GB of data. By ensuring georeferenced indoor-outdoor acquisition, high accuracy, and multimodal data integration, the benchmark supports robust analysis of sensors and the development of advanced reconstruction methods. Additionally, we explore downstream tasks demonstrating the potential of TUM2TWIN, including novel view synthesis of NeRF and Gaussian Splatting, solar potential analysis, point cloud semantic segmentation, and LoD3 building reconstruction. We are convinced this contribution lays a foundation for overcoming current limitations in UDT creation, fostering new research directions and practical solutions for smarter, data-driven urban environments. The project is available under: https://tum2t.win
QuickSplat: Fast 3D Surface Reconstruction via Learned Gaussian Initialization
May 08, 2025Surface reconstruction is fundamental to computer vision and graphics, enabling applications in 3D modeling, mixed reality, robotics, and more. Existing approaches based on volumetric rendering obtain promising results, but optimize on a per-scene basis, resulting in a slow optimization that can struggle to model under-observed or textureless regions. We introduce QuickSplat, which learns data-driven priors to generate dense initializations for 2D gaussian splatting optimization of large-scale indoor scenes. This provides a strong starting point for the reconstruction, which accelerates the convergence of the optimization and improves the geometry of flat wall structures. We further learn to jointly estimate the densification and update of the scene parameters during each iteration; our proposed densifier network predicts new Gaussians based on the rendering gradients of existing ones, removing the needs of heuristics for densification. Extensive experiments on large-scale indoor scene reconstruction demonstrate the superiority of our data-driven optimization. Concretely, we accelerate runtime by 8x, while decreasing depth errors by up to 48% in comparison to state of the art methods.
ScanNet++: A High-Fidelity Dataset of 3D Indoor Scenes
Aug 22, 2023We present ScanNet++, a large-scale dataset that couples together capture of high-quality and commodity-level geometry and color of indoor scenes. Each scene is captured with a high-end laser scanner at sub-millimeter resolution, along with registered 33-megapixel images from a DSLR camera, and RGB-D streams from an iPhone. Scene reconstructions are further annotated with an open vocabulary of semantics, with label-ambiguous scenarios explicitly annotated for comprehensive semantic understanding. ScanNet++ enables a new real-world benchmark for novel view synthesis, both from high-quality RGB capture, and importantly also from commodity-level images, in addition to a new benchmark for 3D semantic scene understanding that comprehensively encapsulates diverse and ambiguous semantic labeling scenarios. Currently, ScanNet++ contains 460 scenes, 280,000 captured DSLR images, and over 3.7M iPhone RGBD frames.
360-MLC: Multi-view Layout Consistency for Self-training and Hyper-parameter Tuning
Oct 24, 2022We present 360-MLC, a self-training method based on multi-view layout consistency for finetuning monocular room-layout models using unlabeled 360-images only. This can be valuable in practical scenarios where a pre-trained model needs to be adapted to a new data domain without using any ground truth annotations. Our simple yet effective assumption is that multiple layout estimations in the same scene must define a consistent geometry regardless of their camera positions. Based on this idea, we leverage a pre-trained model to project estimated layout boundaries from several camera views into the 3D world coordinate. Then, we re-project them back to the spherical coordinate and build a probability function, from which we sample the pseudo-labels for self-training. To handle unconfident pseudo-labels, we evaluate the variance in the re-projected boundaries as an uncertainty value to weight each pseudo-label in our loss function during training. In addition, since ground truth annotations are not available during training nor in testing, we leverage the entropy information in multiple layout estimations as a quantitative metric to measure the geometry consistency of the scene, allowing us to evaluate any layout estimator for hyper-parameter tuning, including model selection without ground truth annotations. Experimental results show that our solution achieves favorable performance against state-of-the-art methods when self-training from three publicly available source datasets to a unique, newly labeled dataset consisting of multi-view of the same scenes.
360-DFPE: Leveraging Monocular 360-Layouts for Direct Floor Plan Estimation
Dec 21, 2021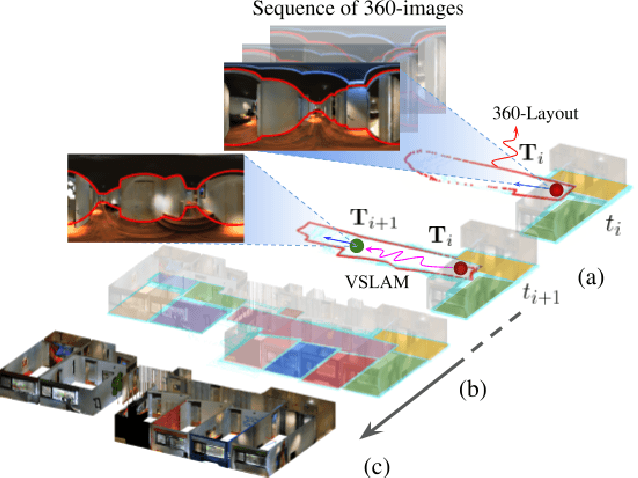
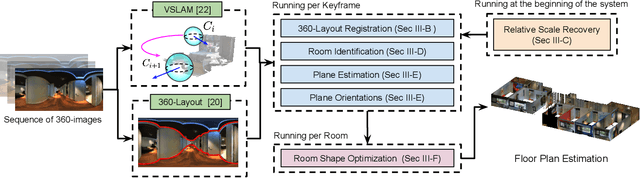
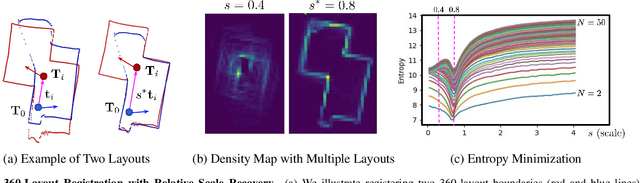
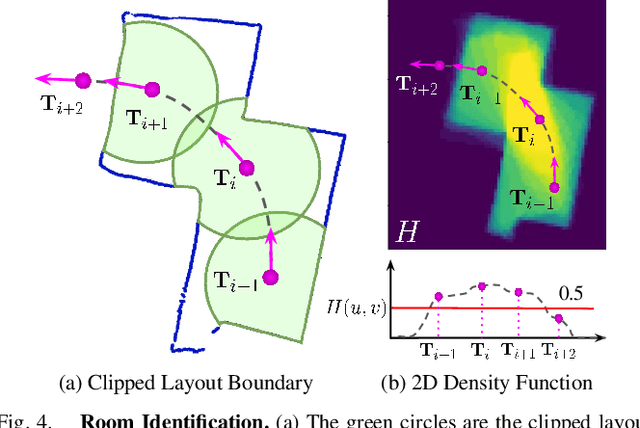
We present 360-DFPE, a sequential floor plan estimation method that directly takes 360-images as input without relying on active sensors or 3D information. Our approach leverages a loosely coupled integration between a monocular visual SLAM solution and a monocular 360-room layout approach, which estimate camera poses and layout geometries, respectively. Since our task is to sequentially capture the floor plan using monocular images, the entire scene structure, room instances, and room shapes are unknown. To tackle these challenges, we first handle the scale difference between visual odometry and layout geometry via formulating an entropy minimization process, which enables us to directly align 360-layouts without knowing the entire scene in advance. Second, to sequentially identify individual rooms, we propose a novel room identification algorithm that tracks every room along the camera exploration using geometry information. Lastly, to estimate the final shape of the room, we propose a shortest path algorithm with an iterative coarse-to-fine strategy, which improves prior formulations with higher accuracy and faster run-time. Moreover, we collect a new floor plan dataset with challenging large-scale scenes, providing both point clouds and sequential 360-image information. Experimental results show that our monocular solution achieves favorable performance against the current state-of-the-art algorithms that rely on active sensors and require the entire scene reconstruction data in advance. Our code and dataset will be released soon.
Anomaly-Aware Semantic Segmentation by Leveraging Synthetic-Unknown Data
Nov 29, 2021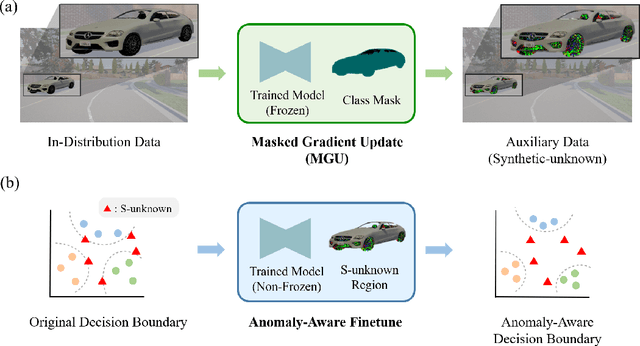
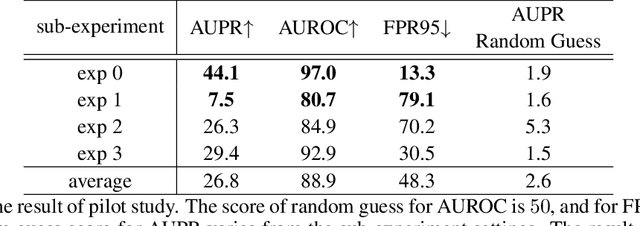
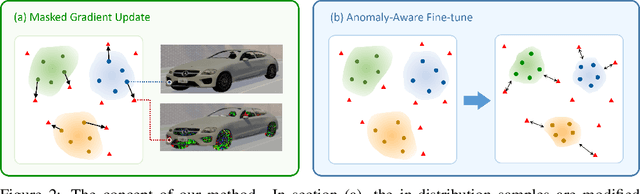
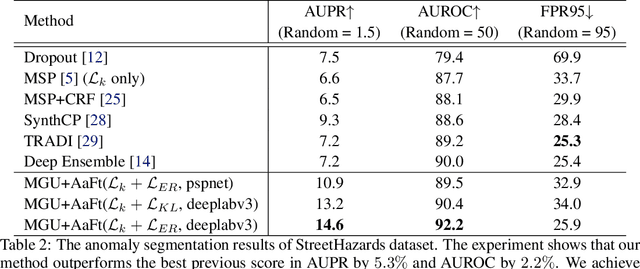
Anomaly awareness is an essential capability for safety-critical applications such as autonomous driving. While recent progress of robotics and computer vision has enabled anomaly detection for image classification, anomaly detection on semantic segmentation is less explored. Conventional anomaly-aware systems assuming other existing classes as out-of-distribution (pseudo-unknown) classes for training a model will result in two drawbacks. (1) Unknown classes, which applications need to cope with, might not actually exist during training time. (2) Model performance would strongly rely on the class selection. Observing this, we propose a novel Synthetic-Unknown Data Generation, intending to tackle the anomaly-aware semantic segmentation task. We design a new Masked Gradient Update (MGU) module to generate auxiliary data along the boundary of in-distribution data points. In addition, we modify the traditional cross-entropy loss to emphasize the border data points. We reach the state-of-the-art performance on two anomaly segmentation datasets. Ablation studies also demonstrate the effectiveness of proposed modules.
ReDAL: Region-based and Diversity-aware Active Learning for Point Cloud Semantic Segmentation
Aug 07, 2021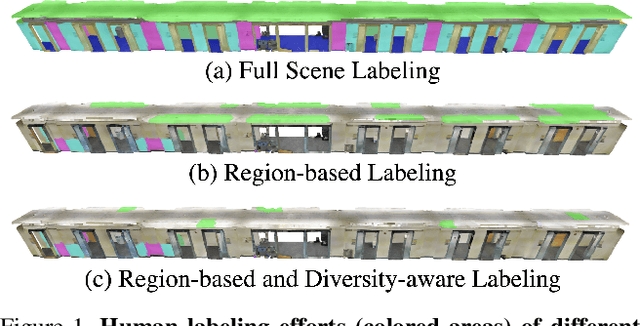


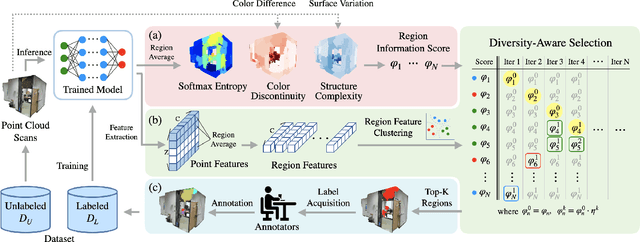
Despite the success of deep learning on supervised point cloud semantic segmentation, obtaining large-scale point-by-point manual annotations is still a significant challenge. To reduce the huge annotation burden, we propose a Region-based and Diversity-aware Active Learning (ReDAL), a general framework for many deep learning approaches, aiming to automatically select only informative and diverse sub-scene regions for label acquisition. Observing that only a small portion of annotated regions are sufficient for 3D scene understanding with deep learning, we use softmax entropy, color discontinuity, and structural complexity to measure the information of sub-scene regions. A diversity-aware selection algorithm is also developed to avoid redundant annotations resulting from selecting informative but similar regions in a querying batch. Extensive experiments show that our method highly outperforms previous active learning strategies, and we achieve the performance of 90% fully supervised learning, while less than 15% and 5% annotations are required on S3DIS and SemanticKITTI datasets, respectively.
Learning from 2D: Pixel-to-Point Knowledge Transfer for 3D Pretraining
Apr 10, 2021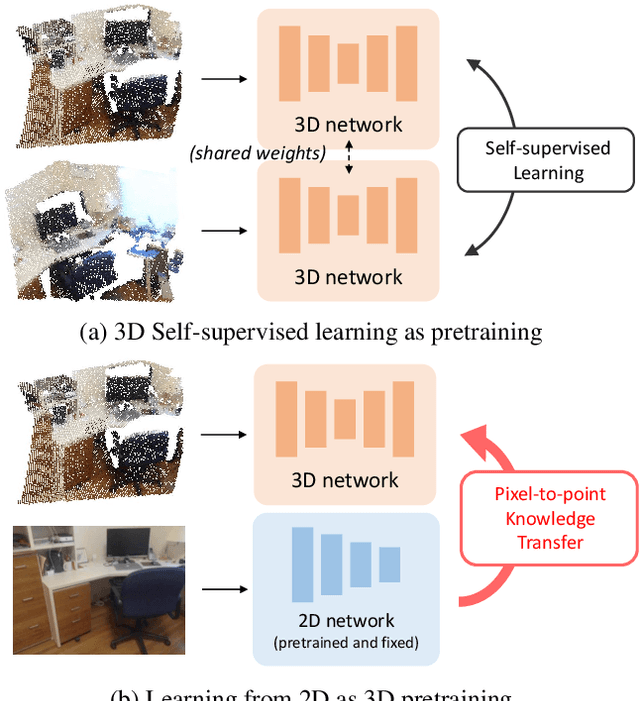
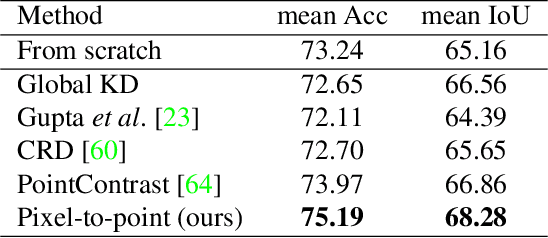
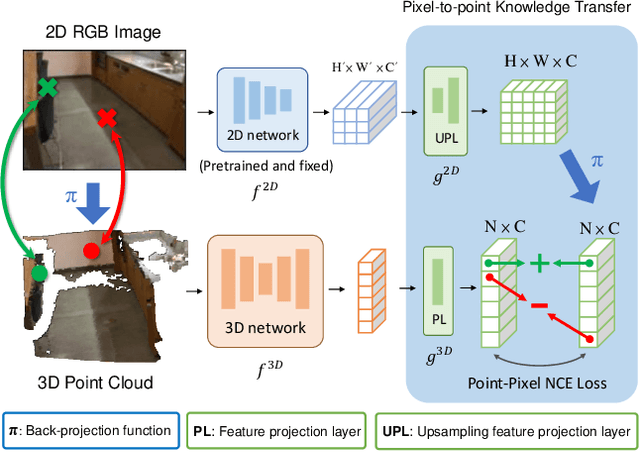
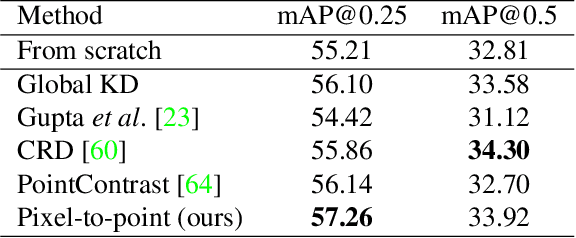
Most of the 3D networks are trained from scratch owning to the lack of large-scale labeled datasets. In this paper, we present a novel 3D pretraining method by leveraging 2D networks learned from rich 2D datasets. We propose the pixel-to-point knowledge transfer to effectively utilize the 2D information by mapping the pixel-level and point-level features into the same embedding space. Due to the heterogeneous nature between 2D and 3D networks, we introduce the back-projection function to align the features between 2D and 3D to make the transfer possible. Additionally, we devise an upsampling feature projection layer to increase the spatial resolution of high-level 2D feature maps, which helps learning fine-grained 3D representations. With a pretrained 2D network, the proposed pretraining process requires no additional 2D or 3D labeled data, further alleviating the expansive 3D data annotation cost. To the best of our knowledge, we are the first to exploit existing 2D trained weights to pretrain 3D deep neural networks. Our intensive experiments show that the 3D models pretrained with 2D knowledge boost the performances across various real-world 3D downstream tasks.
$S^3$: Learnable Sparse Signal Superdensity for Guided Depth Estimation
Mar 22, 2021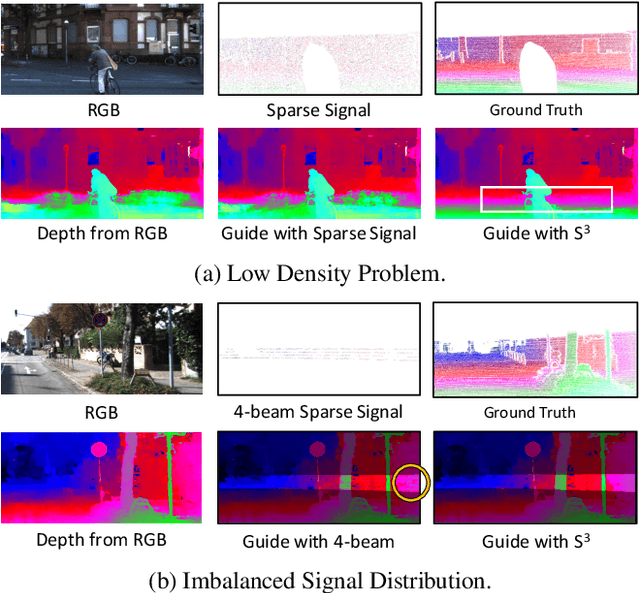

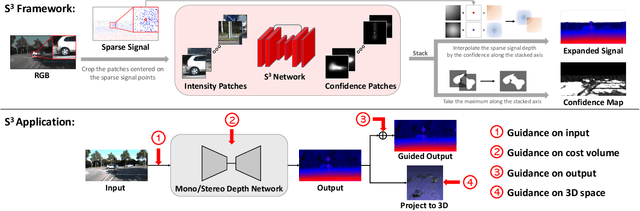
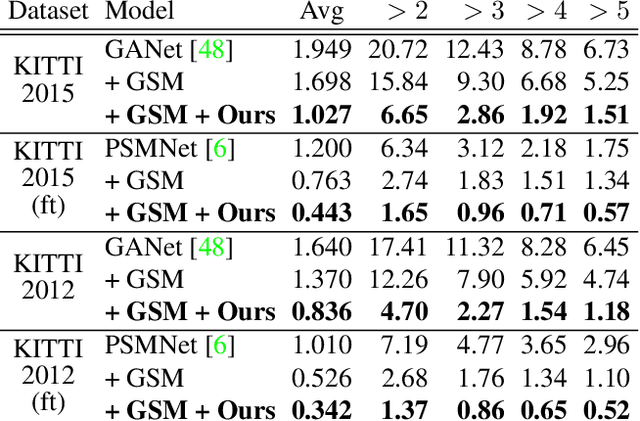
Dense depth estimation plays a key role in multiple applications such as robotics, 3D reconstruction, and augmented reality. While sparse signal, e.g., LiDAR and Radar, has been leveraged as guidance for enhancing dense depth estimation, the improvement is limited due to its low density and imbalanced distribution. To maximize the utility from the sparse source, we propose $S^3$ technique, which expands the depth value from sparse cues while estimating the confidence of expanded region. The proposed $S^3$ can be applied to various guided depth estimation approaches and trained end-to-end at different stages, including input, cost volume and output. Extensive experiments demonstrate the effectiveness, robustness, and flexibility of the $S^3$ technique on LiDAR and Radar signal.