 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Estimates of maize plant density from UAV RGB images using Faster-RCNN detection model: impact of the spatial resolution
May 25, 2021
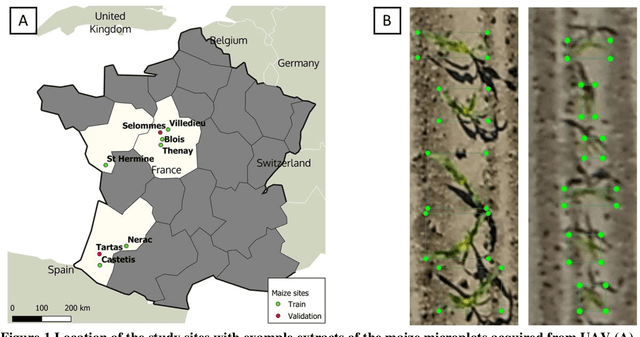
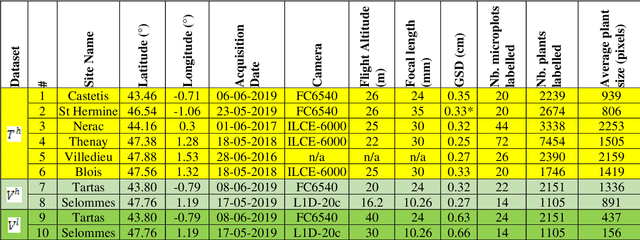

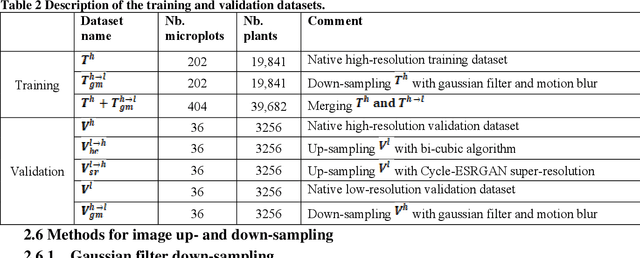
Early-stage plant density is an essential trait that determines the fate of a genotype under given environmental conditions and management practices. The use of RGB images taken from UAVs may replace traditional visual counting in fields with improved throughput, accuracy and access to plant localization. However, high-resolution (HR) images are required to detect small plants present at early stages. This study explores the impact of image ground sampling distance (GSD) on the performances of maize plant detection at 3-5 leaves stage using Faster-RCNN. Data collected at HR (GSD=0.3cm) over 6 contrasted sites were used for model training. Two additional sites with images acquired both at high and low (GSD=0.6cm) resolution were used for model evaluation. Results show that Faster-RCNN achieved very good plant detection and counting (rRMSE=0.08) performances when native HR images are used both for training and validation. Similarly, good performances were observed (rRMSE=0.11) when the model is trained over synthetic low-resolution (LR) images obtained by down-sampling the native training HR images, and applied to the synthetic LR validation images. Conversely, poor performances are obtained when the model is trained on a given spatial resolution and applied to another spatial resolution. Training on a mix of HR and LR images allows to get very good performances on the native HR (rRMSE=0.06) and synthetic LR (rRMSE=0.10) images. However, very low performances are still observed over the native LR images (rRMSE=0.48), mainly due to the poor quality of the native LR images. Finally, an advanced super-resolution method based on GAN (generative adversarial network) that introduces additional textural information derived from the native HR images was applied to the native LR validation images. Results show some significant improvement (rRMSE=0.22) compared to bicubic up-sampling approach.
On the Binding Problem in Artificial Neural Networks
Dec 09, 2020
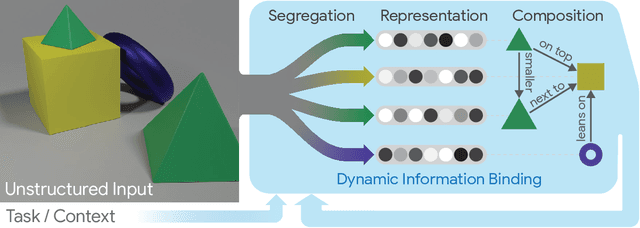


Contemporary neural networks still fall short of human-level generalization, which extends far beyond our direct experiences. In this paper, we argue that the underlying cause for this shortcoming is their inability to dynamically and flexibly bind information that is distributed throughout the network. This binding problem affects their capacity to acquire a compositional understanding of the world in terms of symbol-like entities (like objects), which is crucial for generalizing in predictable and systematic ways. To address this issue, we propose a unifying framework that revolves around forming meaningful entities from unstructured sensory inputs (segregation), maintaining this separation of information at a representational level (representation), and using these entities to construct new inferences, predictions, and behaviors (composition). Our analysis draws inspiration from a wealth of research in neuroscience and cognitive psychology, and surveys relevant mechanisms from the machine learning literature, to help identify a combination of inductive biases that allow symbolic information processing to emerge naturally in neural networks. We believe that a compositional approach to AI, in terms of grounded symbol-like representations, is of fundamental importance for realizing human-level generalization, and we hope that this paper may contribute towards that goal as a reference and inspiration.
User Preference-aware Fake News Detection
Apr 25, 2021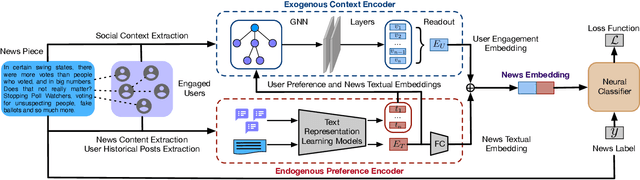
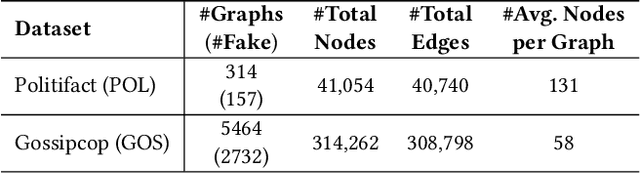
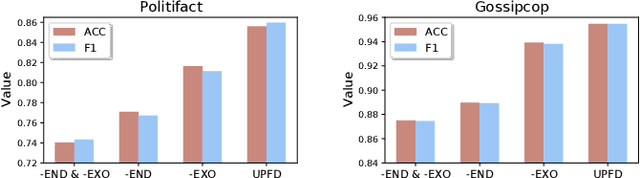
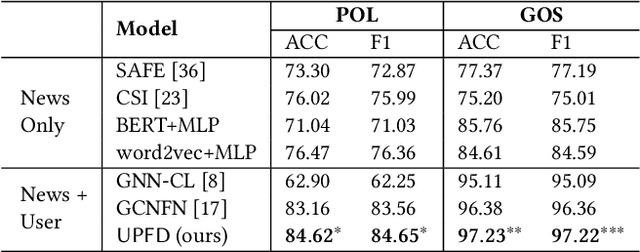
Disinformation and fake news have posed detrimental effects on individuals and society in recent years, attracting broad attention to fake news detection. The majority of existing fake news detection algorithms focus on mining news content and/or the surrounding exogenous context for discovering deceptive signals; while the endogenous preference of a user when he/she decides to spread a piece of fake news or not is ignored. The confirmation bias theory has indicated that a user is more likely to spread a piece of fake news when it confirms his/her existing beliefs/preferences. Users' historical, social engagements such as posts provide rich information about users' preferences toward news and have great potential to advance fake news detection. However, the work on exploring user preference for fake news detection is somewhat limited. Therefore, in this paper, we study the novel problem of exploiting user preference for fake news detection. We propose a new framework, UPFD, which simultaneously captures various signals from user preferences by joint content and graph modeling. Experimental results on real-world datasets demonstrate the effectiveness of the proposed framework. We release our code and data as a benchmark for GNN-based fake news detection: https://github.com/safe-graph/GNN-FakeNews.
A General Model of Conversational Dynamics and an Example Application in Serious Illness Communication
Oct 11, 2020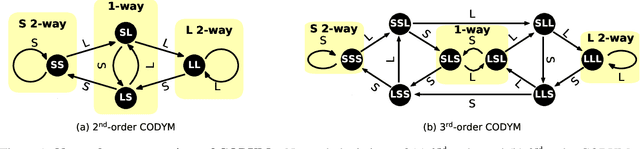

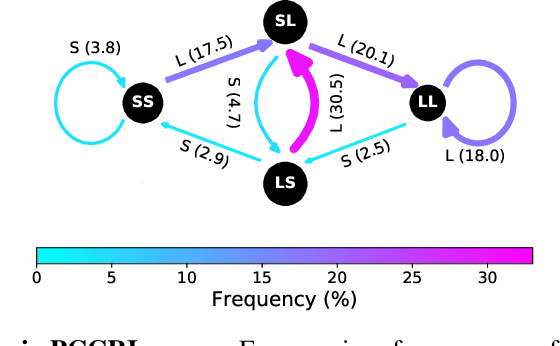
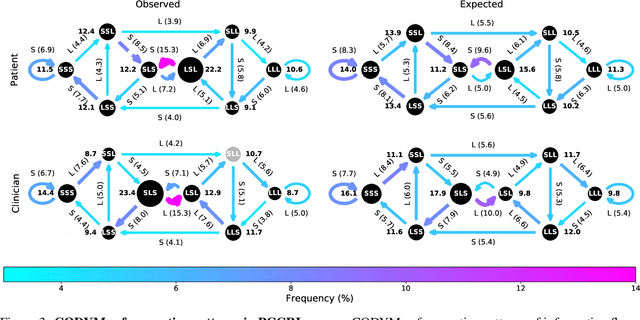
Conversation has been a primary means for the exchange of information since ancient times. Understanding patterns of information flow in conversations is a critical step in assessing and improving communication quality. In this paper, we describe COnversational DYnamics Model (CODYM) analysis, a novel approach for studying patterns of information flow in conversations. CODYMs are Markov Models that capture sequential dependencies in the lengths of speaker turns. The proposed method is automated and scalable, and preserves the privacy of the conversational participants. The primary function of CODYM analysis is to quantify and visualize patterns of information flow, concisely summarized over sequential turns from one or more conversations. Our approach is general and complements existing methods, providing a new tool for use in the analysis of any type of conversation. As an important first application, we demonstrate the model on transcribed conversations between palliative care clinicians and seriously ill patients. These conversations are dynamic and complex, taking place amidst heavy emotions, and include difficult topics such as end-of-life preferences and patient values. We perform a versatile set of CODYM analyses that (a) establish the validity of the model by confirming known patterns of conversational turn-taking and word usage, (b) identify normative patterns of information flow in serious illness conversations, and (c) show how these patterns vary across narrative time and differ under expressions of anger, fear and sadness. Potential applications of CODYMs range from assessment and training of effective healthcare communication to comparing conversational dynamics across language and culture, with the prospect of identifying universal similarities and unique "fingerprints" of information flow.
Boundary and Context Aware Training for CIF-based Non-Autoregressive End-to-end ASR
Apr 10, 2021Continuous integrate-and-fire (CIF) based models, which use a soft and monotonic alignment mechanism, have been well applied in non-autoregressive (NAR) speech recognition and achieved competitive performance compared with other NAR methods. However, such an alignment learning strategy may also result in inaccurate acoustic boundary estimation and deceleration in convergence speed. To eliminate these drawbacks and improve performance further, we incorporate an additional connectionist temporal classification (CTC) based alignment loss and a contextual decoder into the CIF-based NAR model. Specifically, we use the CTC spike information to guide the leaning of acoustic boundary and adopt a new contextual decoder to capture the linguistic dependencies within a sentence in the conventional CIF model. Besides, a recently proposed Conformer architecture is also employed to model both local and global acoustic dependencies. Experiments on the open-source Mandarin corpora AISHELL-1 show that the proposed method achieves a comparable character error rate (CER) of 4.9% with only 1/24 latency compared with a state-of-the-art autoregressive (AR) Conformer model.
Self-Adaptive Training: Bridging the Supervised and Self-Supervised Learning
Jan 21, 2021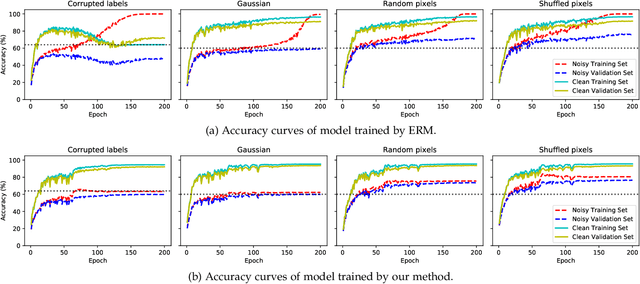
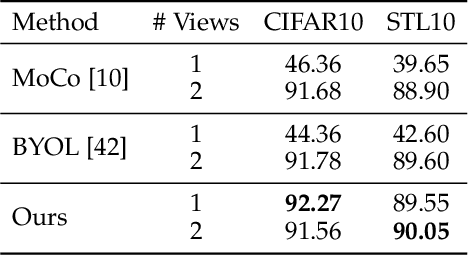
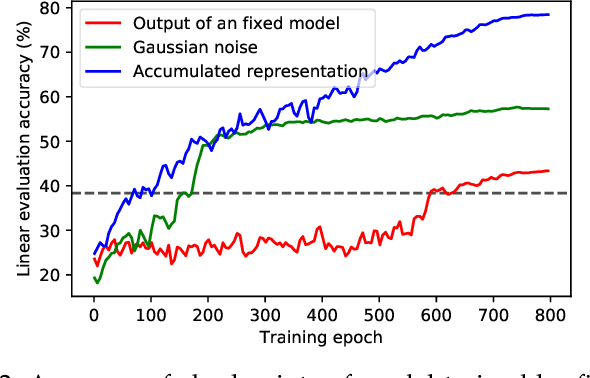
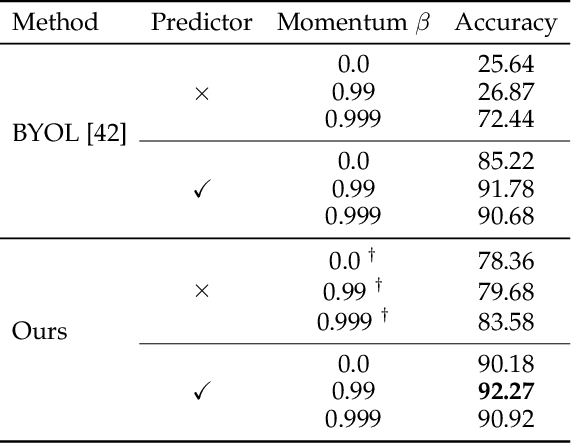
We propose self-adaptive training -- a unified training algorithm that dynamically calibrates and enhances training process by model predictions without incurring extra computational cost -- to advance both supervised and self-supervised learning of deep neural networks. We analyze the training dynamics of deep networks on training data that are corrupted by, e.g., random noise and adversarial examples. Our analysis shows that model predictions are able to magnify useful underlying information in data and this phenomenon occurs broadly even in the absence of \emph{any} label information, highlighting that model predictions could substantially benefit the training process: self-adaptive training improves the generalization of deep networks under noise and enhances the self-supervised representation learning. The analysis also sheds light on understanding deep learning, e.g., a potential explanation of the recently-discovered double-descent phenomenon in empirical risk minimization and the collapsing issue of the state-of-the-art self-supervised learning algorithms. Experiments on the CIFAR, STL and ImageNet datasets verify the effectiveness of our approach in three applications: classification with label noise, selective classification and linear evaluation. To facilitate future research, the code has been made public available at https://github.com/LayneH/self-adaptive-training.
Gaussian Dynamic Convolution for Efficient Single-Image Segmentation
Apr 18, 2021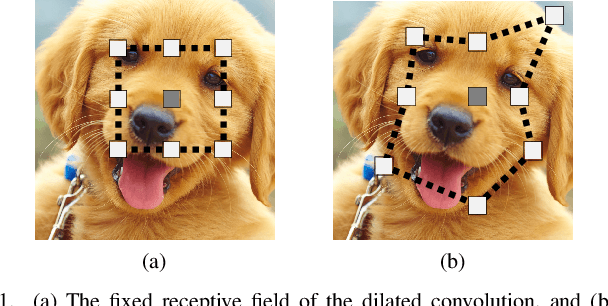
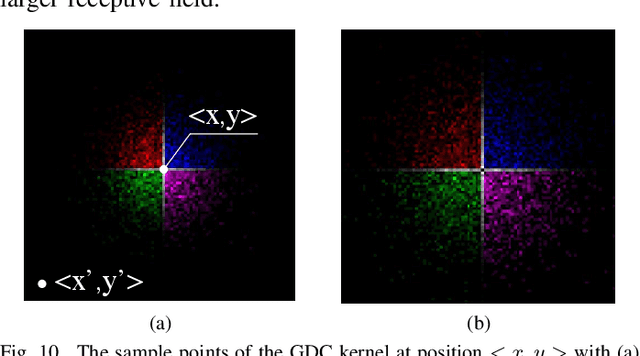

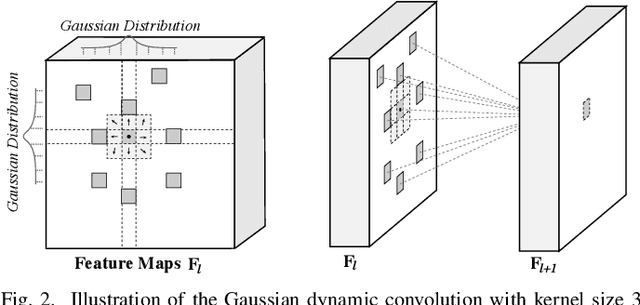
Interactive single-image segmentation is ubiquitous in the scientific and commercial imaging software. In this work, we focus on the single-image segmentation problem only with some seeds such as scribbles. Inspired by the dynamic receptive field in the human being's visual system, we propose the Gaussian dynamic convolution (GDC) to fast and efficiently aggregate the contextual information for neural networks. The core idea is randomly selecting the spatial sampling area according to the Gaussian distribution offsets. Our GDC can be easily used as a module to build lightweight or complex segmentation networks. We adopt the proposed GDC to address the typical single-image segmentation tasks. Furthermore, we also build a Gaussian dynamic pyramid Pooling to show its potential and generality in common semantic segmentation. Experiments demonstrate that the GDC outperforms other existing convolutions on three benchmark segmentation datasets including Pascal-Context, Pascal-VOC 2012, and Cityscapes. Additional experiments are also conducted to illustrate that the GDC can produce richer and more vivid features compared with other convolutions. In general, our GDC is conducive to the convolutional neural networks to form an overall impression of the image.
Trajectory Servoing: Image-Based Trajectory Tracking Using SLAM
Mar 06, 2021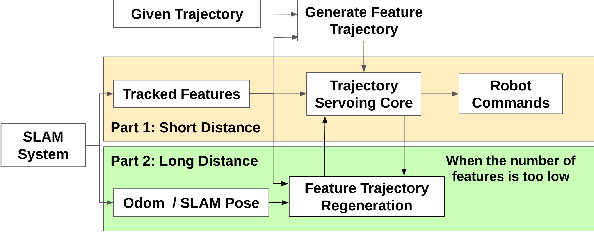
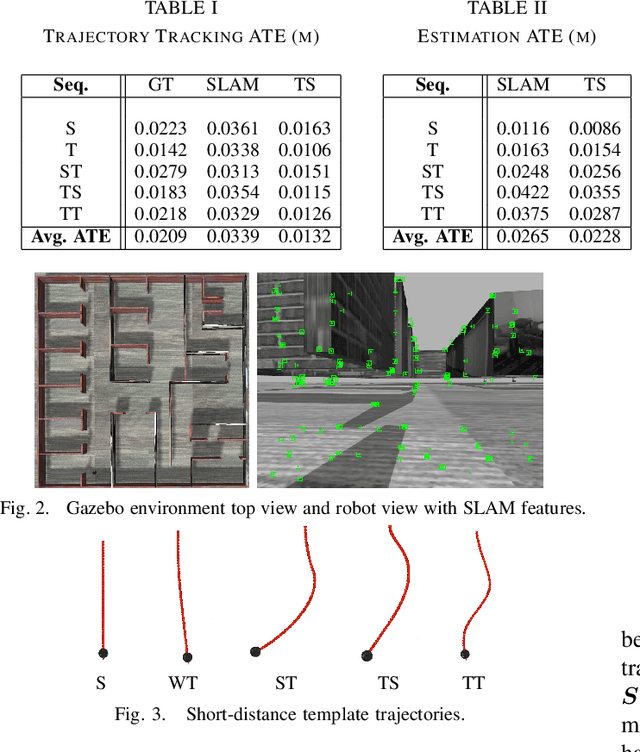
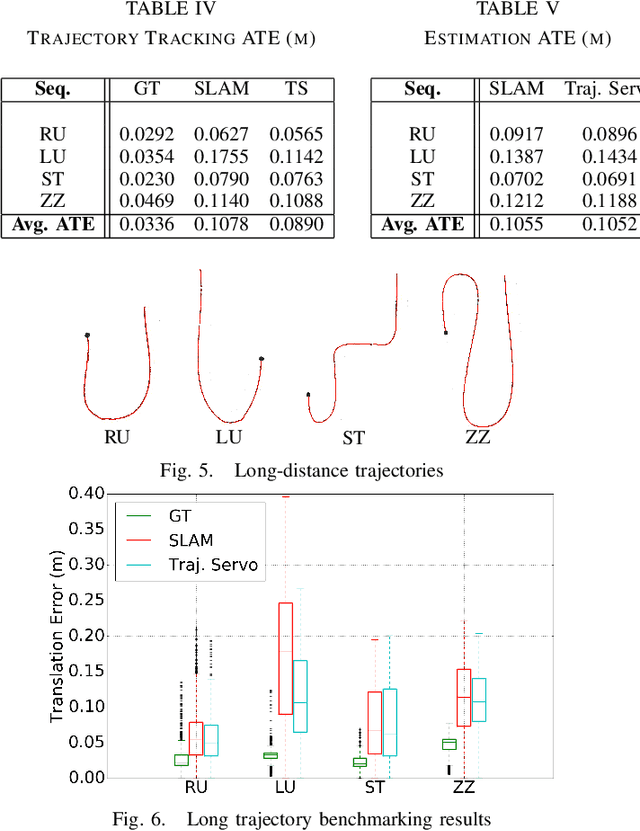
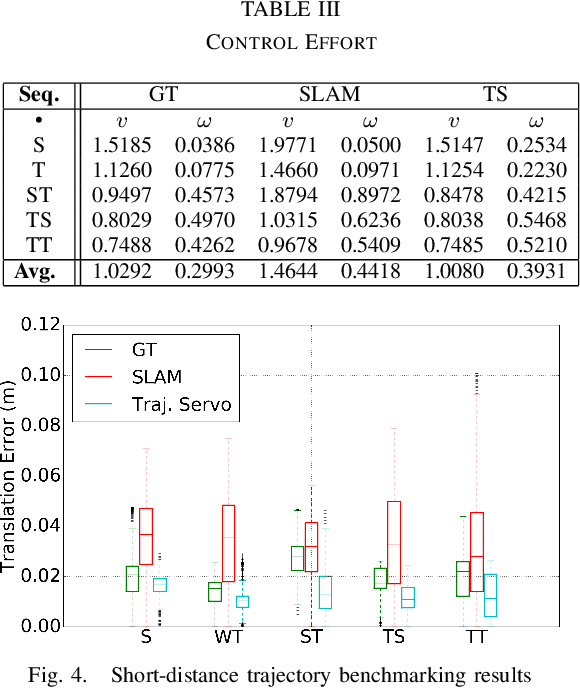
This paper describes an image based visual servoing (IBVS) system for a nonholonomic robot to achieve good trajectory following without real-time robot pose information and without a known visual map of the environment. We call it trajectory servoing. The critical component is a feature-based, indirect SLAM method to provide a pool of available features with estimated depth, so that they may be propagated forward in time to generate image feature trajectories for visual servoing. Short and long distance experiments show the benefits of trajectory servoing for navigating unknown areas without absolute positioning. Trajectory servoing is shown to be more accurate than pose-based feedback when both rely on the same underlying SLAM system.
Rethinking Graph Neural Network Search from Message-passing
Apr 18, 2021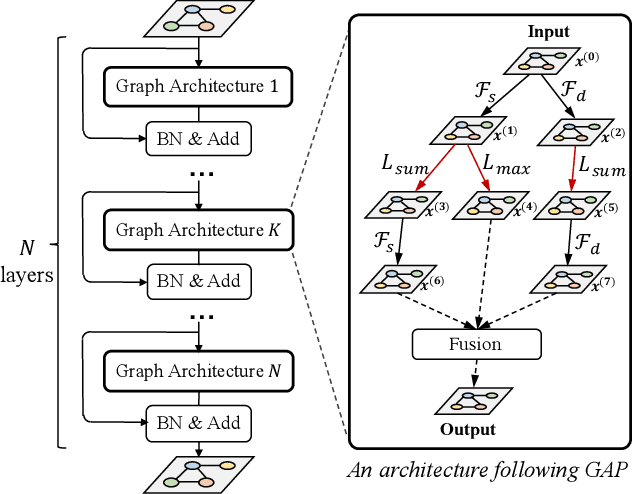

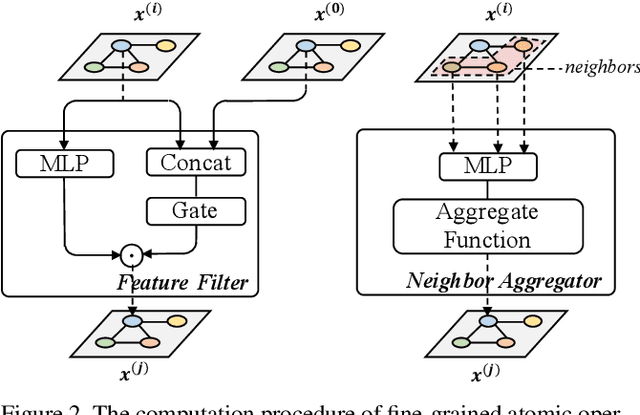
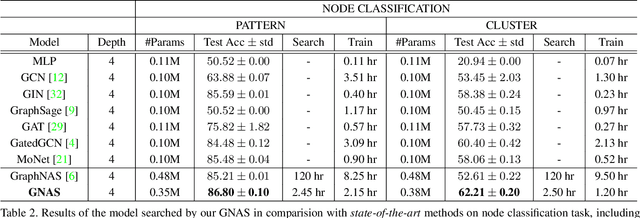
Graph neural networks (GNNs) emerged recently as a standard toolkit for learning from data on graphs. Current GNN designing works depend on immense human expertise to explore different message-passing mechanisms, and require manual enumeration to determine the proper message-passing depth. Inspired by the strong searching capability of neural architecture search (NAS) in CNN, this paper proposes Graph Neural Architecture Search (GNAS) with novel-designed search space. The GNAS can automatically learn better architecture with the optimal depth of message passing on the graph. Specifically, we design Graph Neural Architecture Paradigm (GAP) with tree-topology computation procedure and two types of fine-grained atomic operations (feature filtering and neighbor aggregation) from message-passing mechanism to construct powerful graph network search space. Feature filtering performs adaptive feature selection, and neighbor aggregation captures structural information and calculates neighbors' statistics. Experiments show that our GNAS can search for better GNNs with multiple message-passing mechanisms and optimal message-passing depth. The searched network achieves remarkable improvement over state-of-the-art manual designed and search-based GNNs on five large-scale datasets at three classical graph tasks. Codes can be found at https://github.com/phython96/GNAS-MP.
Demographic Aware Probabilistic Medical Knowledge Graph Embeddings of Electronic Medical Records
Mar 22, 2021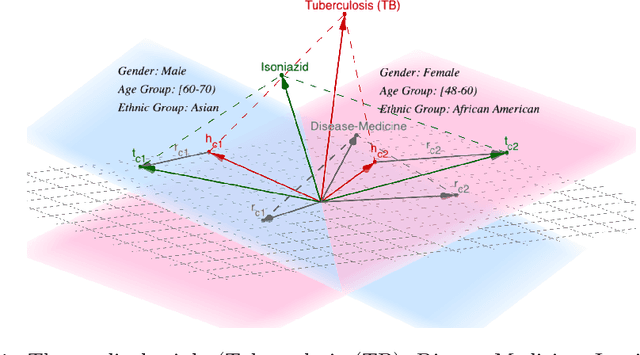
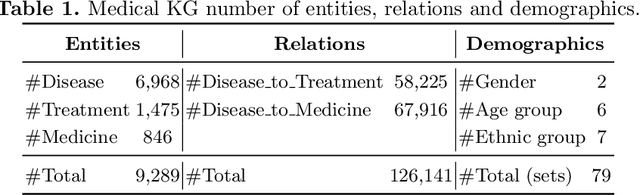
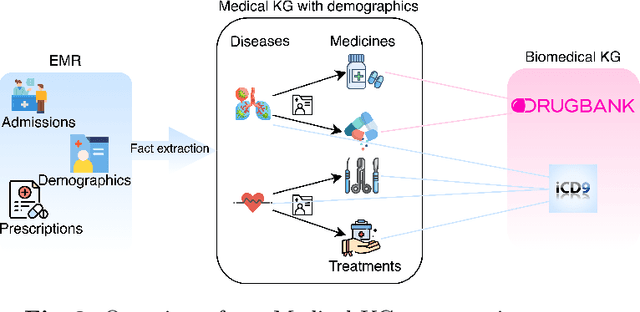
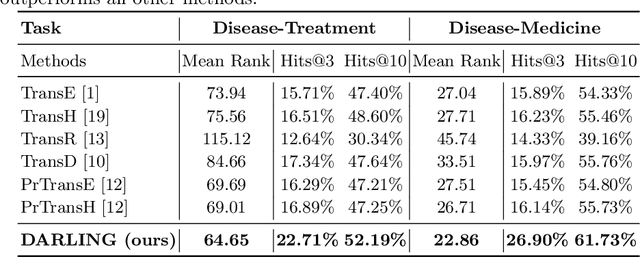
Medical knowledge graphs (KGs) constructed from Electronic Medical Records (EMR) contain abundant information about patients and medical entities. The utilization of KG embedding models on these data has proven to be efficient for different medical tasks. However, existing models do not properly incorporate patient demographics and most of them ignore the probabilistic features of the medical KG. In this paper, we propose DARLING (Demographic Aware pRobabiListic medIcal kNowledge embeddinG), a demographic-aware medical KG embedding framework that explicitly incorporates demographics in the medical entities space by associating patient demographics with a corresponding hyperplane. Our framework leverages the probabilistic features within the medical entities for learning their representations through demographic guidance. We evaluate DARLING through link prediction for treatments and medicines, on a medical KG constructed from EMR data, and illustrate its superior performance compared to existing KG embedding models.