 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Multi-Channel Hypergraph Convolutional Network for Social Recommendation
Jan 21, 2021
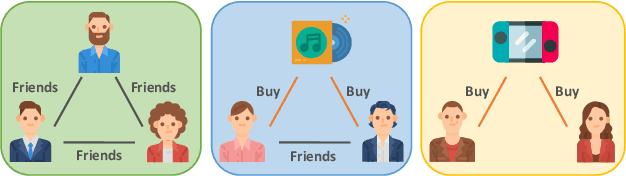


Social relations are often used to improve recommendation quality when user-item interaction data is sparse in recommender systems. Most existing social recommendation models exploit pairwise relations to mine potential user preferences. However, real-life interactions among users are very complicated and user relations can be high-order. Hypergraph provides a natural way to model complex high-order relations, while its potentials for improving social recommendation are under-explored. In this paper, we fill this gap and propose a multi-channel hypergraph convolutional network to enhance social recommendation by leveraging high-order user relations. Technically, each channel in the network encodes a hypergraph that depicts a common high-order user relation pattern via hypergraph convolution. By aggregating the embeddings learned through multiple channels, we obtain comprehensive user representations to generate recommendation results. However, the aggregation operation might also obscure the inherent characteristics of different types of high-order connectivity information. To compensate for the aggregating loss, we innovatively integrate self-supervised learning into the training of the hypergraph convolutional network to regain the connectivity information with hierarchical mutual information maximization. The experimental results on multiple real-world datasets show that the proposed model outperforms the SOTA methods, and the ablation study verifies the effectiveness of the multi-channel setting and the self-supervised task. The implementation of our model is available via https://github.com/Coder-Yu/RecQ.
Detecting Backdoor in Deep Neural Networks via Intentional Adversarial Perturbations
Jun 22, 2021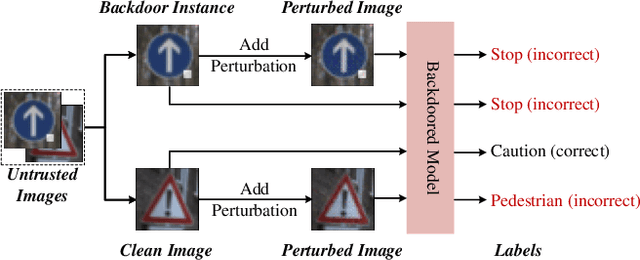
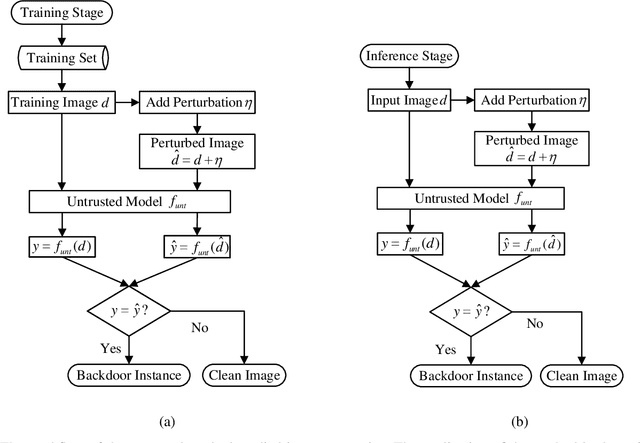


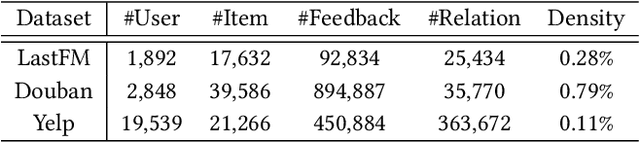
Recent researches show that deep learning model is susceptible to backdoor attacks. Many defenses against backdoor attacks have been proposed. However, existing defense works require high computational overhead or backdoor attack information such as the trigger size, which is difficult to satisfy in realistic scenarios. In this paper, a novel backdoor detection method based on adversarial examples is proposed. The proposed method leverages intentional adversarial perturbations to detect whether an image contains a trigger, which can be applied in both the training stage and the inference stage (sanitize the training set in training stage and detect the backdoor instances in inference stage). Specifically, given an untrusted image, the adversarial perturbation is added to the image intentionally. If the prediction of the model on the perturbed image is consistent with that on the unperturbed image, the input image will be considered as a backdoor instance. Compared with most existing defense works, the proposed adversarial perturbation based method requires low computational resources and maintains the visual quality of the images. Experimental results show that, the backdoor detection rate of the proposed defense method is 99.63%, 99.76% and 99.91% on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. Besides, the proposed method maintains the visual quality of the image as the l2 norm of the added perturbation are as low as 2.8715, 3.0513 and 2.4362 on Fashion-MNIST, CIFAR-10 and GTSRB datasets, respectively. In addition, it is also demonstrated that the proposed method can achieve high defense performance against backdoor attacks under different attack settings (trigger transparency, trigger size and trigger pattern). Compared with the existing defense work (STRIP), the proposed method has better detection performance on all the three datasets, and is more efficient than STRIP.
Information, learning and falsification
Nov 28, 2011There are (at least) three approaches to quantifying information. The first, algorithmic information or Kolmogorov complexity, takes events as strings and, given a universal Turing machine, quantifies the information content of a string as the length of the shortest program producing it. The second, Shannon information, takes events as belonging to ensembles and quantifies the information resulting from observing the given event in terms of the number of alternate events that have been ruled out. The third, statistical learning theory, has introduced measures of capacity that control (in part) the expected risk of classifiers. These capacities quantify the expectations regarding future data that learning algorithms embed into classifiers. This note describes a new method of quantifying information, effective information, that links algorithmic information to Shannon information, and also links both to capacities arising in statistical learning theory. After introducing the measure, we show that it provides a non-universal analog of Kolmogorov complexity. We then apply it to derive basic capacities in statistical learning theory: empirical VC-entropy and empirical Rademacher complexity. A nice byproduct of our approach is an interpretation of the explanatory power of a learning algorithm in terms of the number of hypotheses it falsifies, counted in two different ways for the two capacities. We also discuss how effective information relates to information gain, Shannon and mutual information.
Learning Disentangled Semantic Representation for Domain Adaptation
Dec 22, 2020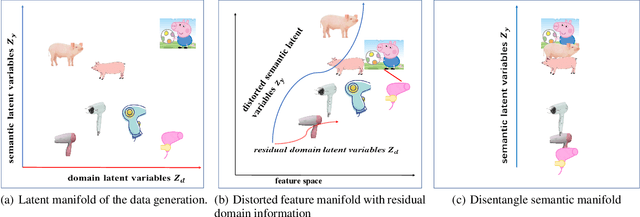
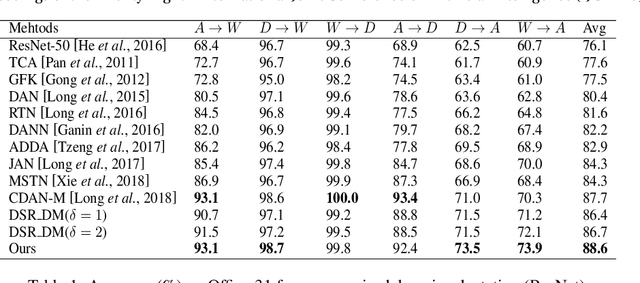
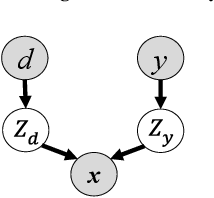
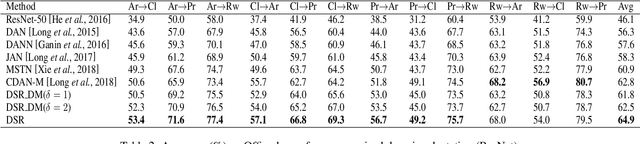
Domain adaptation is an important but challenging task. Most of the existing domain adaptation methods struggle to extract the domain-invariant representation on the feature space with entangling domain information and semantic information. Different from previous efforts on the entangled feature space, we aim to extract the domain invariant semantic information in the latent disentangled semantic representation (DSR) of the data. In DSR, we assume the data generation process is controlled by two independent sets of variables, i.e., the semantic latent variables and the domain latent variables. Under the above assumption, we employ a variational auto-encoder to reconstruct the semantic latent variables and domain latent variables behind the data. We further devise a dual adversarial network to disentangle these two sets of reconstructed latent variables. The disentangled semantic latent variables are finally adapted across the domains. Experimental studies testify that our model yields state-of-the-art performance on several domain adaptation benchmark datasets.
Leveraging Two Types of Global Graph for Sequential Fashion Recommendation
May 18, 2021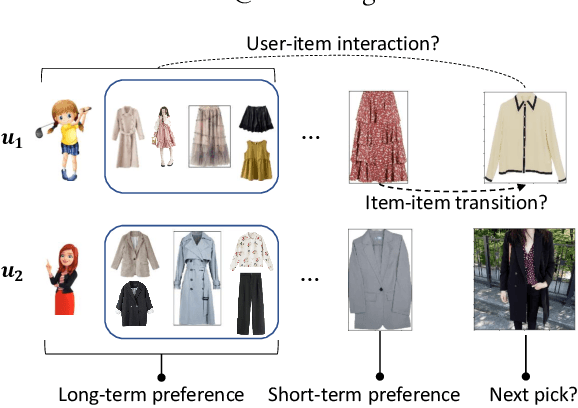
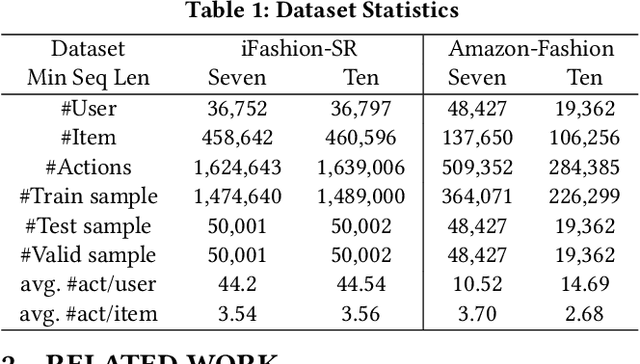
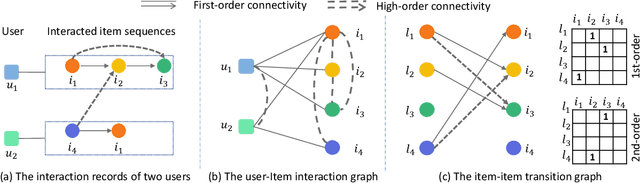
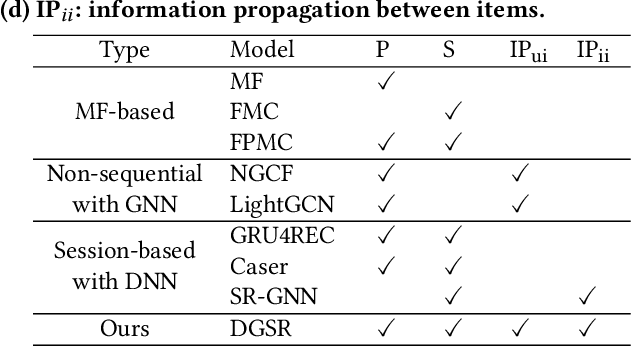
Sequential fashion recommendation is of great significance in online fashion shopping, which accounts for an increasing portion of either fashion retailing or online e-commerce. The key to building an effective sequential fashion recommendation model lies in capturing two types of patterns: the personal fashion preference of users and the transitional relationships between adjacent items. The two types of patterns are usually related to user-item interaction and item-item transition modeling respectively. However, due to the large sets of users and items as well as the sparse historical interactions, it is difficult to train an effective and efficient sequential fashion recommendation model. To tackle these problems, we propose to leverage two types of global graph, i.e., the user-item interaction graph and item-item transition graph, to obtain enhanced user and item representations by incorporating higher-order connections over the graphs. In addition, we adopt the graph kernel of LightGCN for the information propagation in both graphs and propose a new design for item-item transition graph. Extensive experiments on two established sequential fashion recommendation datasets validate the effectiveness and efficiency of our approach.
IWA: Integrated Gradient based White-box Attacks for Fooling Deep Neural Networks
Feb 03, 2021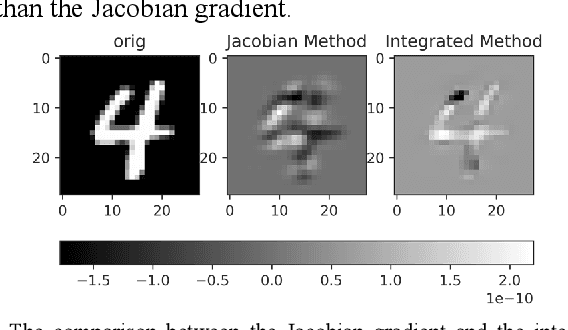
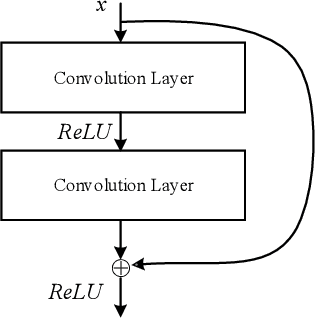
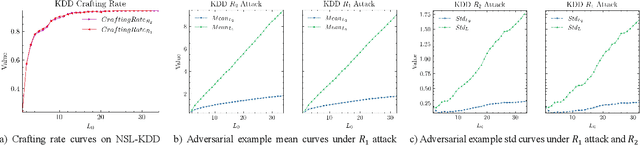
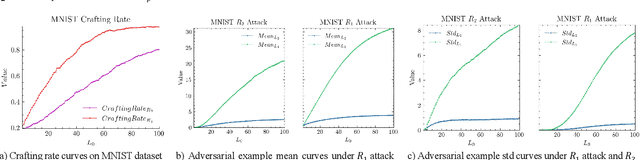
The widespread application of deep neural network (DNN) techniques is being challenged by adversarial examples, the legitimate input added with imperceptible and well-designed perturbations that can fool DNNs easily in the DNN testing/deploying stage. Previous adversarial example generation algorithms for adversarial white-box attacks used Jacobian gradient information to add perturbations. This information is too imprecise and inexplicit, which will cause unnecessary perturbations when generating adversarial examples. This paper aims to address this issue. We first propose to apply a more informative and distilled gradient information, namely integrated gradient, to generate adversarial examples. To further make the perturbations more imperceptible, we propose to employ the restriction combination of $L_0$ and $L_1/L_2$ secondly, which can restrict the total perturbations and perturbation points simultaneously. Meanwhile, to address the non-differentiable problem of $L_1$, we explore a proximal operation of $L_1$ thirdly. Based on these three works, we propose two Integrated gradient based White-box Adversarial example generation algorithms (IWA): IFPA and IUA. IFPA is suitable for situations where there are a determined number of points to be perturbed. IUA is suitable for situations where no perturbation point number is preset in order to obtain more adversarial examples. We verify the effectiveness of the proposed algorithms on both structured and unstructured datasets, and we compare them with five baseline generation algorithms. The results show that our proposed algorithms do craft adversarial examples with more imperceptible perturbations and satisfactory crafting rate. $L_2$ restriction is more suitable for unstructured dataset and $L_1$ restriction performs better in structured dataset.
HIN-RNN: A Graph Representation Learning Neural Network for Fraudster Group Detection With No Handcrafted Features
May 25, 2021



Social reviews are indispensable resources for modern consumers' decision making. For financial gain, companies pay fraudsters preferably in groups to demote or promote products and services since consumers are more likely to be misled by a large number of similar reviews from groups. Recent approaches on fraudster group detection employed handcrafted features of group behaviors without considering the semantic relation between reviews from the reviewers in a group. In this paper, we propose the first neural approach, HIN-RNN, a Heterogeneous Information Network (HIN) Compatible RNN for fraudster group detection that requires no handcrafted features. HIN-RNN provides a unifying architecture for representation learning of each reviewer, with the initial vector as the sum of word embeddings of all review text written by the same reviewer, concatenated by the ratio of negative reviews. Given a co-review network representing reviewers who have reviewed the same items with the same ratings and the reviewers' vector representation, a collaboration matrix is acquired through HIN-RNN training. The proposed approach is confirmed to be effective with marked improvement over state-of-the-art approaches on both the Yelp (22% and 12% in terms of recall and F1-value, respectively) and Amazon (4% and 2% in terms of recall and F1-value, respectively) datasets.
Fast constraint satisfaction problem and learning-based algorithm for solving Minesweeper
May 10, 2021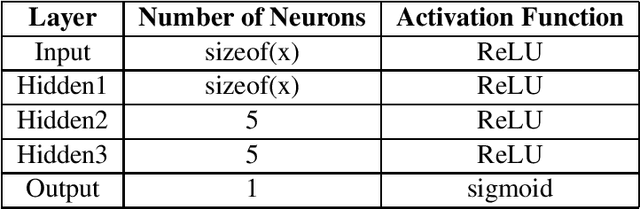
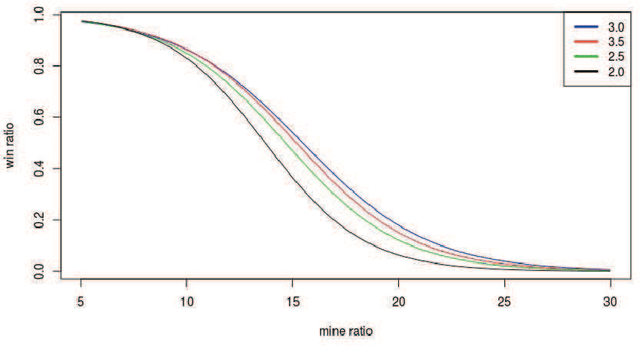
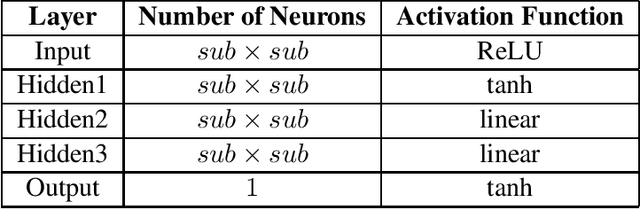
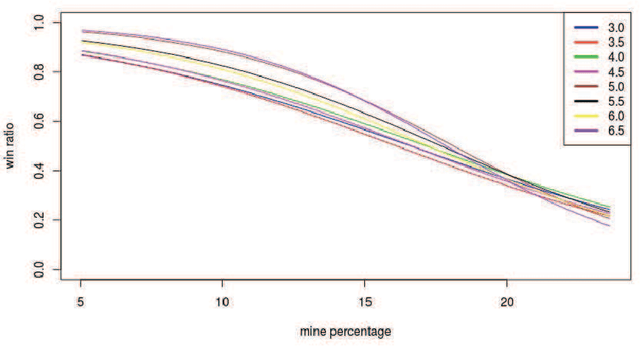
Minesweeper is a popular spatial-based decision-making game that works with incomplete information. As an exemplary NP-complete problem, it is a major area of research employing various artificial intelligence paradigms. The present work models this game as Constraint Satisfaction Problem (CSP) and Markov Decision Process (MDP). We propose a new method named as dependents from the independent set using deterministic solution search (DSScsp) for the faster enumeration of all solutions of a CSP based Minesweeper game and improve the results by introducing heuristics. Using MDP, we implement machine learning methods on these heuristics. We train the classification model on sparse data with results from CSP formulation. We also propose a new rewarding method for applying a modified deep Q-learning for better accuracy and versatile learning in the Minesweeper game. The overall results have been analyzed for different kinds of Minesweeper games and their accuracies have been recorded. Results from these experiments show that the proposed method of MDP based classification model and deep Q-learning overall is the best methods in terms of accuracy for games with given mine densities.
Fairness in Ranking: A Survey
Mar 25, 2021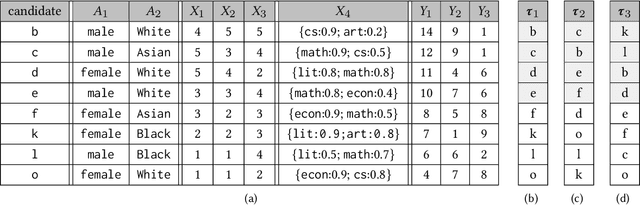

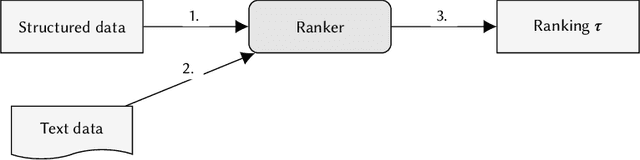
In the past few years, there has been much work on incorporating fairness requirements into algorithmic rankers, with contributions coming from the data management, algorithms, information retrieval, and recommender systems communities. In this survey we give a systematic overview of this work, offering a broad perspective that connects formalizations and algorithmic approaches across subfields. An important contribution of our work is in developing a common narrative around the value frameworks that motivate specific fairness-enhancing interventions in ranking. This allows us to unify the presentation of mitigation objectives and of algorithmic techniques to help meet those objectives or identify trade-offs.
Tracking Cells and their Lineages via Labeled Random Finite Sets
Apr 22, 2021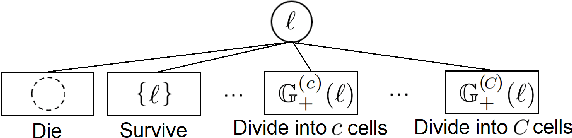
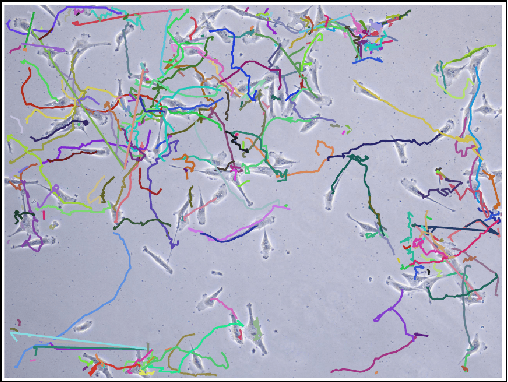
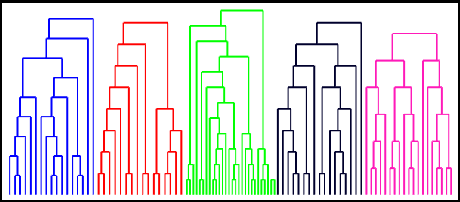
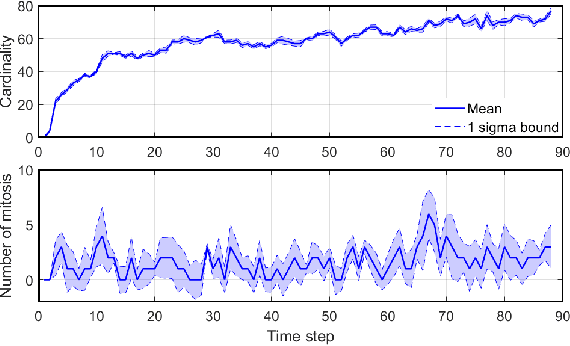
Determining the trajectories of cells and their lineages or ancestries in live-cell experiments are fundamental to the understanding of how cells behave and divide. This paper proposes novel online algorithms for jointly tracking and resolving lineages of an unknown and time-varying number of cells from time-lapse video data. Our approach involves modeling the cell ensemble as a labeled random finite set with labels representing cell identities and lineages. A spawning model is developed to take into account cell lineages and changes in cell appearance prior to division. We then derive analytic filters to propagate multi-object distributions that contain information on the current cell ensemble including their lineages. We also develop numerical implementations of the resulting multi-object filters. Experiments using simulation, synthetic cell migration video, and real time-lapse sequence, are presented to demonstrate the capability of the solutions.