 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoPeP: Benchmarking Continual Pretraining for Protein Language Models
Mar 03, 2026Protein language models (pLMs) have recently gained significant attention for their ability to uncover relationships between sequence, structure, and function from evolutionary statistics, thereby accelerating therapeutic drug discovery. These models learn from large protein databases that are continuously updated by the biology community and whose dynamic nature motivates the application of continual learning, not only to keep up with the ever-growing data, but also as an opportunity to take advantage of the temporal meta-information that is created during this process. As a result, we introduce the Continual Pretraining of Protein Language Models (CoPeP) benchmark, a novel benchmark for evaluating continual learning approaches on pLMs. Specifically, we curate a sequence of protein datasets derived from the UniProt Knowledgebase spanning a decade and define metrics to assess pLM performance across 31 protein understanding tasks. We evaluate several methods from the continual learning literature, including replay, unlearning, and plasticity-based methods, some of which have never been applied to models and data of this scale. Our findings reveal that incorporating temporal meta-information improves perplexity by up to 7% even when compared to training on data from all tasks jointly. Moreover, even at scale, several continual learning methods outperform naive continual pretraining. The CoPeP benchmark offers an exciting opportunity to study these methods at scale in an impactful real-world application.
Torque-Aware Momentum
Dec 25, 2024Efficiently exploring complex loss landscapes is key to the performance of deep neural networks. While momentum-based optimizers are widely used in state-of-the-art setups, classical momentum can still struggle with large, misaligned gradients, leading to oscillations. To address this, we propose Torque-Aware Momentum (TAM), which introduces a damping factor based on the angle between the new gradients and previous momentum, stabilizing the update direction during training. Empirical results show that TAM, which can be combined with both SGD and Adam, enhances exploration, handles distribution shifts more effectively, and improves generalization performance across various tasks, including image classification and large language model fine-tuning, when compared to classical momentum-based optimizers.
Predicting the Impact of Model Expansion through the Minima Manifold: A Loss Landscape Perspective
May 24, 2024



The optimal model for a given task is often challenging to determine, requiring training multiple models from scratch which becomes prohibitive as dataset and model sizes grow. A more efficient alternative is to reuse smaller pre-trained models by expanding them, however, this is not widely adopted as how this impacts training dynamics remains poorly understood. While prior works have introduced statistics to measure these effects, they remain flawed. To rectify this, we offer a new approach for understanding and quantifying the impact of expansion through the lens of the loss landscape, which has been shown to contain a manifold of linearly connected minima. Building on this new perspective, we propose a metric to study the impact of expansion by estimating the size of the manifold. Experimental results show a clear relationship between gains in performance and manifold size, enabling the comparison of candidate models and presenting a first step towards expanding models more reliably based on geometric properties of the loss landscape.
Lookbehind Optimizer: k steps back, 1 step forward
Jul 31, 2023The Lookahead optimizer improves the training stability of deep neural networks by having a set of fast weights that "look ahead" to guide the descent direction. Here, we combine this idea with sharpness-aware minimization (SAM) to stabilize its multi-step variant and improve the loss-sharpness trade-off. We propose Lookbehind, which computes $k$ gradient ascent steps ("looking behind") at each iteration and combine the gradients to bias the descent step toward flatter minima. We apply Lookbehind on top of two popular sharpness-aware training methods -- SAM and adaptive SAM (ASAM) -- and show that our approach leads to a myriad of benefits across a variety of tasks and training regimes. Particularly, we show increased generalization performance, greater robustness against noisy weights, and higher tolerance to catastrophic forgetting in lifelong learning settings.
Promoting Exploration in Memory-Augmented Adam using Critical Momenta
Jul 18, 2023Adaptive gradient-based optimizers, particularly Adam, have left their mark in training large-scale deep learning models. The strength of such optimizers is that they exhibit fast convergence while being more robust to hyperparameter choice. However, they often generalize worse than non-adaptive methods. Recent studies have tied this performance gap to flat minima selection: adaptive methods tend to find solutions in sharper basins of the loss landscape, which in turn hurts generalization. To overcome this issue, we propose a new memory-augmented version of Adam that promotes exploration towards flatter minima by using a buffer of critical momentum terms during training. Intuitively, the use of the buffer makes the optimizer overshoot outside the basin of attraction if it is not wide enough. We empirically show that our method improves the performance of several variants of Adam on standard supervised language modelling and image classification tasks.
Feature diversity in self-supervised learning
Sep 02, 2022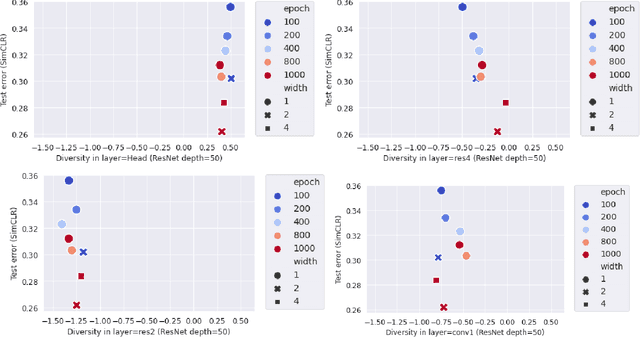
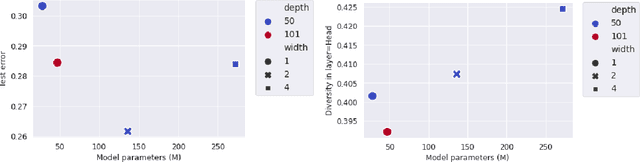
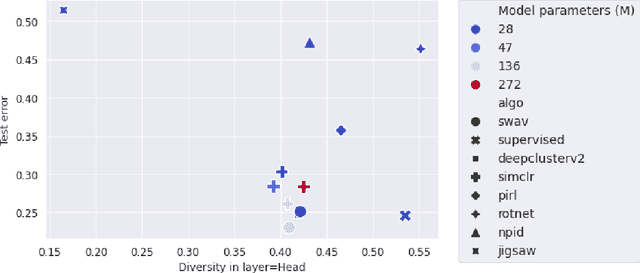
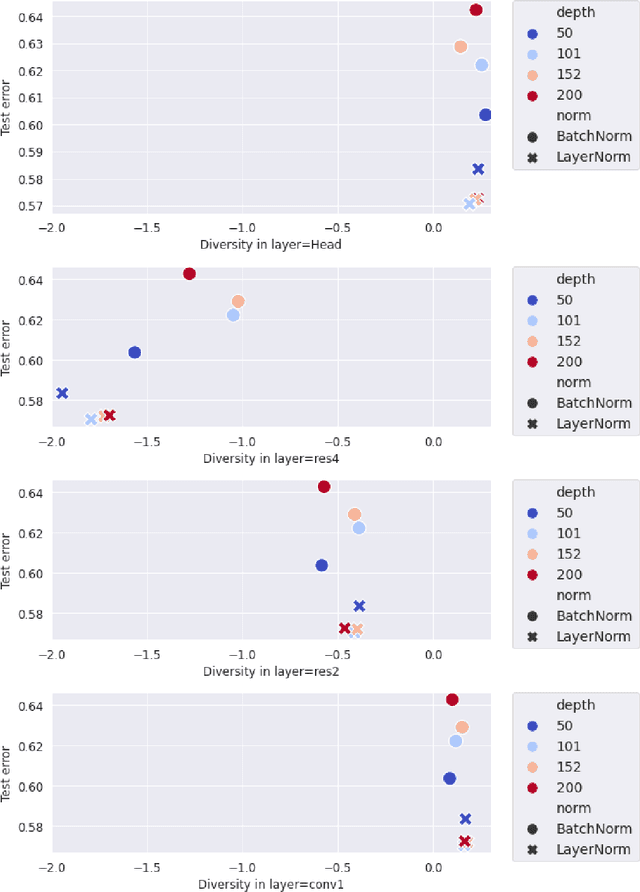
Many studies on scaling laws consider basic factors such as model size, model shape, dataset size, and compute power. These factors are easily tunable and represent the fundamental elements of any machine learning setup. But researchers have also employed more complex factors to estimate the test error and generalization performance with high predictability. These factors are generally specific to the domain or application. For example, feature diversity was primarily used for promoting syn-to-real transfer by Chen et al. (2021). With numerous scaling factors defined in previous works, it would be interesting to investigate how these factors may affect overall generalization performance in the context of self-supervised learning with CNN models. How do individual factors promote generalization, which includes varying depth, width, or the number of training epochs with early stopping? For example, does higher feature diversity result in higher accuracy held in complex settings other than a syn-to-real transfer? How do these factors depend on each other? We found that the last layer is the most diversified throughout the training. However, while the model's test error decreases with increasing epochs, its diversity drops. We also discovered that diversity is directly related to model width.
An Introduction to Lifelong Supervised Learning
Jul 12, 2022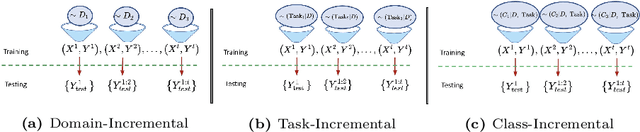
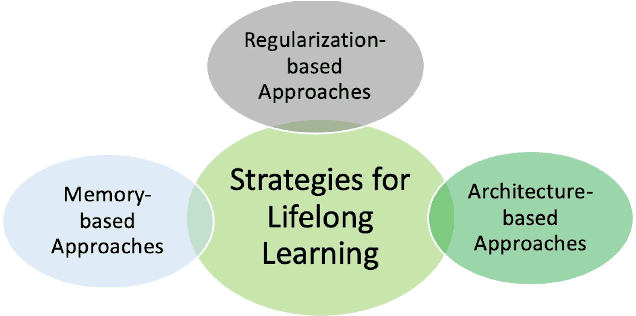
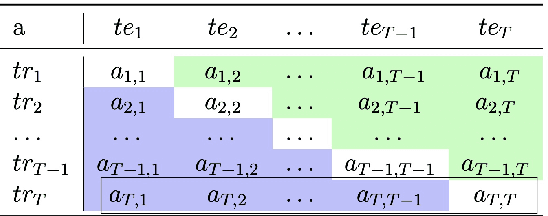
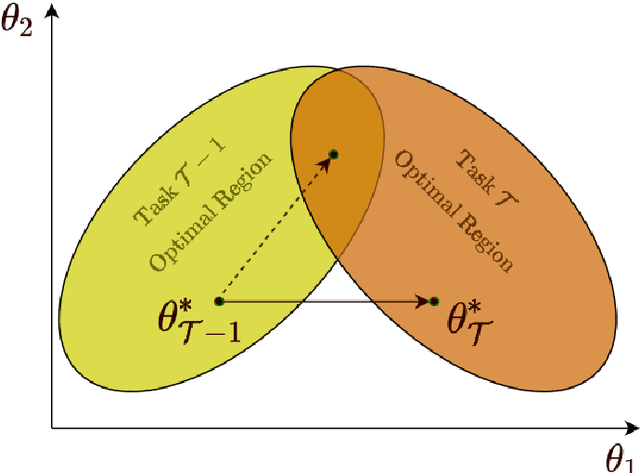
This primer is an attempt to provide a detailed summary of the different facets of lifelong learning. We start with Chapter 2 which provides a high-level overview of lifelong learning systems. In this chapter, we discuss prominent scenarios in lifelong learning (Section 2.4), provide 8 Introduction a high-level organization of different lifelong learning approaches (Section 2.5), enumerate the desiderata for an ideal lifelong learning system (Section 2.6), discuss how lifelong learning is related to other learning paradigms (Section 2.7), describe common metrics used to evaluate lifelong learning systems (Section 2.8). This chapter is more useful for readers who are new to lifelong learning and want to get introduced to the field without focusing on specific approaches or benchmarks. The remaining chapters focus on specific aspects (either learning algorithms or benchmarks) and are more useful for readers who are looking for specific approaches or benchmarks. Chapter 3 focuses on regularization-based approaches that do not assume access to any data from previous tasks. Chapter 4 discusses memory-based approaches that typically use a replay buffer or an episodic memory to save subset of data across different tasks. Chapter 5 focuses on different architecture families (and their instantiations) that have been proposed for training lifelong learning systems. Following these different classes of learning algorithms, we discuss the commonly used evaluation benchmarks and metrics for lifelong learning (Chapter 6) and wrap up with a discussion of future challenges and important research directions in Chapter 7.
A Causal Approach for Unfair Edge Prioritization and Discrimination Removal
Nov 29, 2021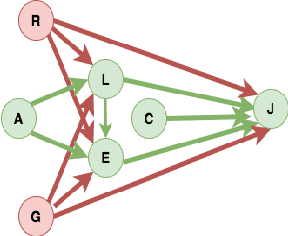
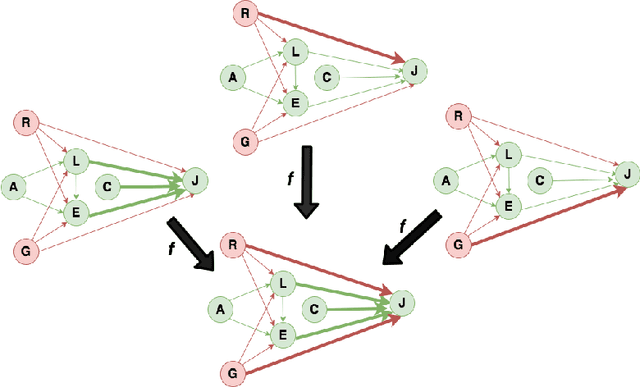
In budget-constrained settings aimed at mitigating unfairness, like law enforcement, it is essential to prioritize the sources of unfairness before taking measures to mitigate them in the real world. Unlike previous works, which only serve as a caution against possible discrimination and de-bias data after data generation, this work provides a toolkit to mitigate unfairness during data generation, given by the Unfair Edge Prioritization algorithm, in addition to de-biasing data after generation, given by the Discrimination Removal algorithm. We assume that a non-parametric Markovian causal model representative of the data generation procedure is given. The edges emanating from the sensitive nodes in the causal graph, such as race, are assumed to be the sources of unfairness. We first quantify Edge Flow in any edge X -> Y, which is the belief of observing a specific value of Y due to the influence of a specific value of X along X -> Y. We then quantify Edge Unfairness by formulating a non-parametric model in terms of edge flows. We then prove that cumulative unfairness towards sensitive groups in a decision, like race in a bail decision, is non-existent when edge unfairness is absent. We prove this result for the non-trivial non-parametric model setting when the cumulative unfairness cannot be expressed in terms of edge unfairness. We then measure the Potential to mitigate the Cumulative Unfairness when edge unfairness is decreased. Based on these measurements, we propose the Unfair Edge Prioritization algorithm that can then be used by policymakers. We also propose the Discrimination Removal Procedure that de-biases a data distribution by eliminating optimization constraints that grow exponentially in the number of sensitive attributes and values taken by them. Extensive experiments validate the theorem and specifications used for quantifying the above measures.
TAG: Task-based Accumulated Gradients for Lifelong learning
May 11, 2021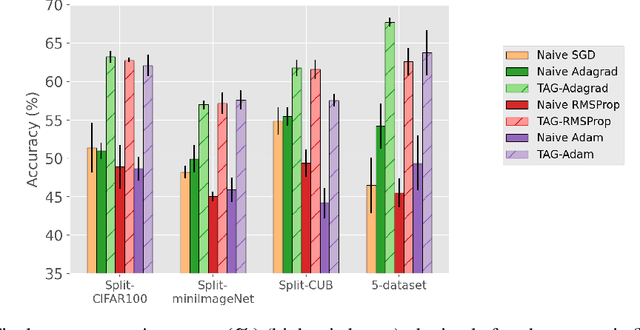
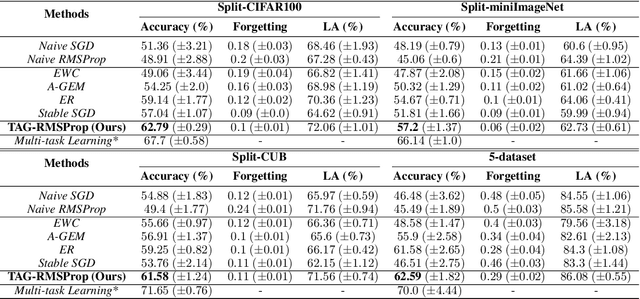
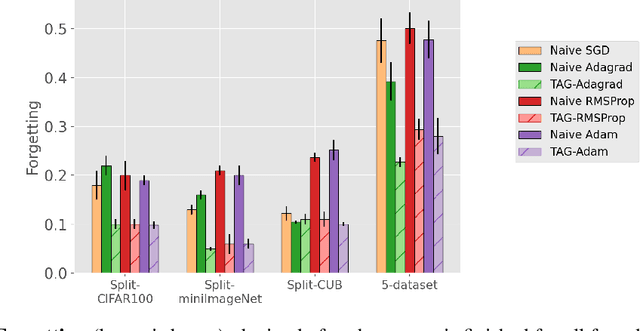
When an agent encounters a continual stream of new tasks in the lifelong learning setting, it leverages the knowledge it gained from the earlier tasks to help learn the new tasks better. In such a scenario, identifying an efficient knowledge representation becomes a challenging problem. Most research works propose to either store a subset of examples from the past tasks in a replay buffer, dedicate a separate set of parameters to each task or penalize excessive updates over parameters by introducing a regularization term. While existing methods employ the general task-agnostic stochastic gradient descent update rule, we propose a task-aware optimizer that adapts the learning rate based on the relatedness among tasks. We utilize the directions taken by the parameters during the updates by accumulating the gradients specific to each task. These task-based accumulated gradients act as a knowledge base that is maintained and updated throughout the stream. We empirically show that our proposed adaptive learning rate not only accounts for catastrophic forgetting but also allows positive backward transfer. We also show that our method performs better than several state-of-the-art methods in lifelong learning on complex datasets with a large number of tasks.
Fast constraint satisfaction problem and learning-based algorithm for solving Minesweeper
May 10, 2021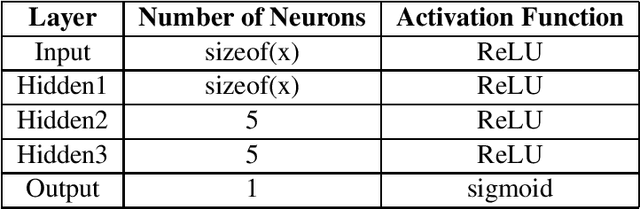
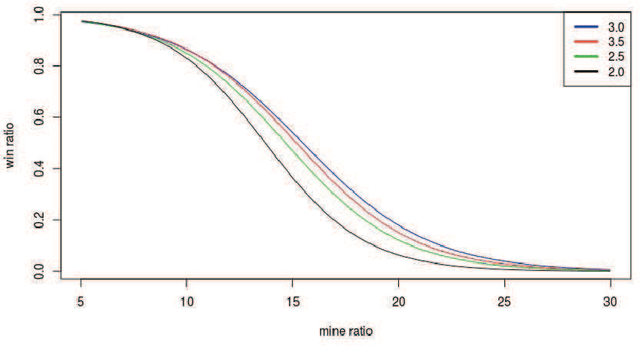
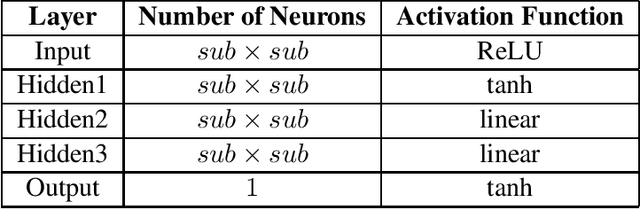
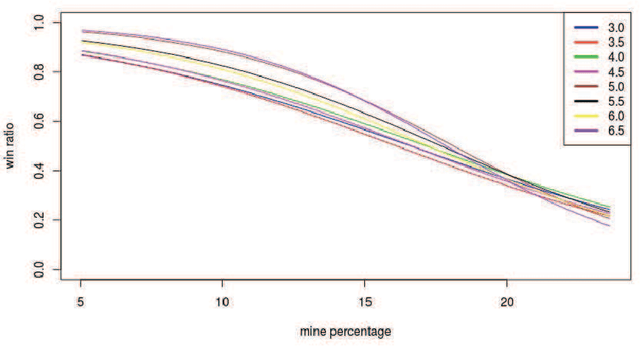
Minesweeper is a popular spatial-based decision-making game that works with incomplete information. As an exemplary NP-complete problem, it is a major area of research employing various artificial intelligence paradigms. The present work models this game as Constraint Satisfaction Problem (CSP) and Markov Decision Process (MDP). We propose a new method named as dependents from the independent set using deterministic solution search (DSScsp) for the faster enumeration of all solutions of a CSP based Minesweeper game and improve the results by introducing heuristics. Using MDP, we implement machine learning methods on these heuristics. We train the classification model on sparse data with results from CSP formulation. We also propose a new rewarding method for applying a modified deep Q-learning for better accuracy and versatile learning in the Minesweeper game. The overall results have been analyzed for different kinds of Minesweeper games and their accuracies have been recorded. Results from these experiments show that the proposed method of MDP based classification model and deep Q-learning overall is the best methods in terms of accuracy for games with given mine densities.