 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HiddenCut: Simple Data Augmentation for Natural Language Understanding with Better Generalization
May 31, 2021
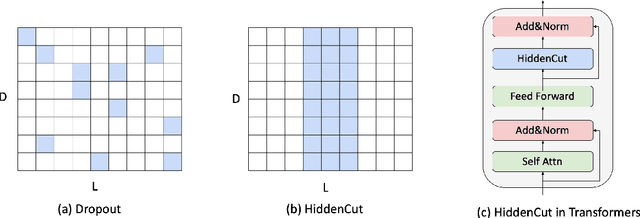
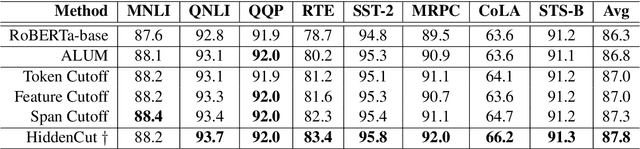

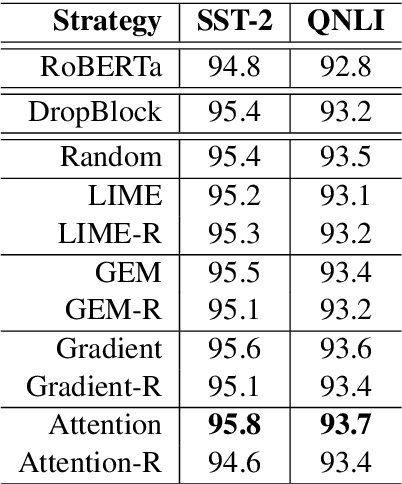
Fine-tuning large pre-trained models with task-specific data has achieved great success in NLP. However, it has been demonstrated that the majority of information within the self-attention networks is redundant and not utilized effectively during the fine-tuning stage. This leads to inferior results when generalizing the obtained models to out-of-domain distributions. To this end, we propose a simple yet effective data augmentation technique, HiddenCut, to better regularize the model and encourage it to learn more generalizable features. Specifically, contiguous spans within the hidden space are dynamically and strategically dropped during training. Experiments show that our HiddenCut method outperforms the state-of-the-art augmentation methods on the GLUE benchmark, and consistently exhibits superior generalization performances on out-of-distribution and challenging counterexamples. We have publicly released our code at https://github.com/GT-SALT/HiddenCut.
Drop-Bottleneck: Learning Discrete Compressed Representation for Noise-Robust Exploration
Mar 23, 2021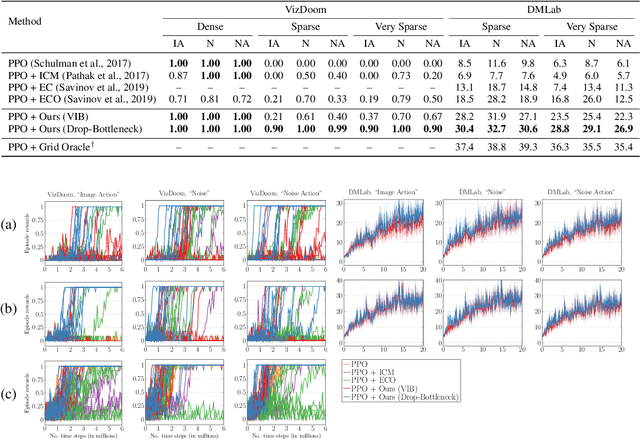

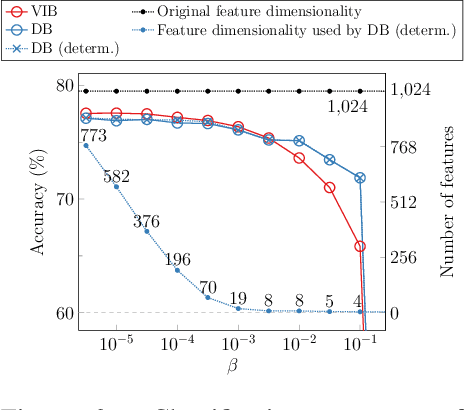
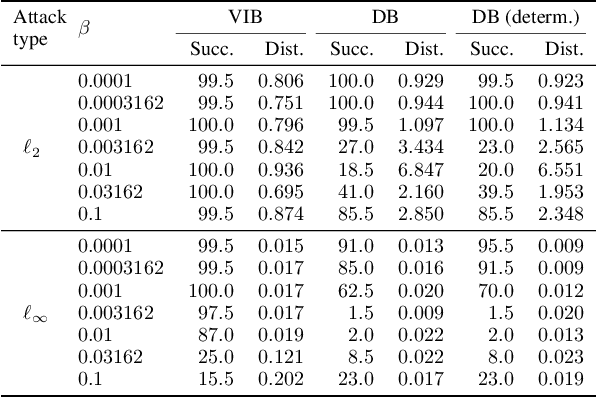
We propose a novel information bottleneck (IB) method named Drop-Bottleneck, which discretely drops features that are irrelevant to the target variable. Drop-Bottleneck not only enjoys a simple and tractable compression objective but also additionally provides a deterministic compressed representation of the input variable, which is useful for inference tasks that require consistent representation. Moreover, it can jointly learn a feature extractor and select features considering each feature dimension's relevance to the target task, which is unattainable by most neural network-based IB methods. We propose an exploration method based on Drop-Bottleneck for reinforcement learning tasks. In a multitude of noisy and reward sparse maze navigation tasks in VizDoom (Kempka et al., 2016) and DMLab (Beattie et al., 2016), our exploration method achieves state-of-the-art performance. As a new IB framework, we demonstrate that Drop-Bottleneck outperforms Variational Information Bottleneck (VIB) (Alemi et al., 2017) in multiple aspects including adversarial robustness and dimensionality reduction.
Modality Completion via Gaussian Process Prior Variational Autoencoders for Multi-Modal Glioma Segmentation
Jul 07, 2021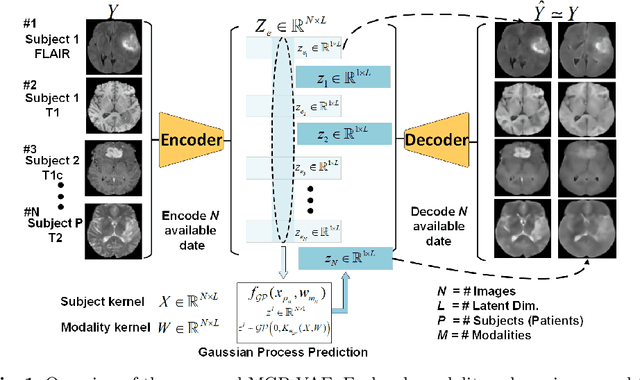
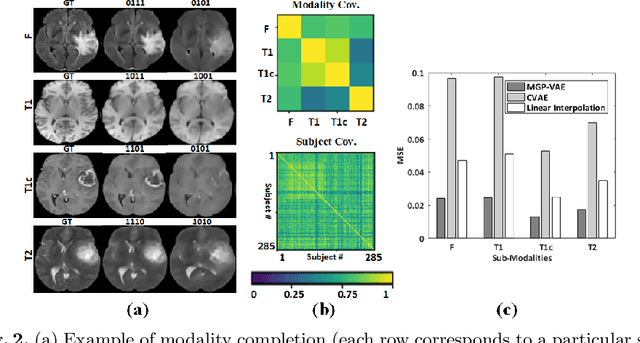
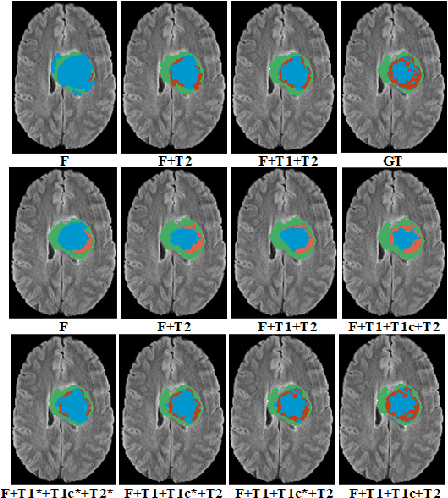
In large studies involving multi protocol Magnetic Resonance Imaging (MRI), it can occur to miss one or more sub-modalities for a given patient owing to poor quality (e.g. imaging artifacts), failed acquisitions, or hallway interrupted imaging examinations. In some cases, certain protocols are unavailable due to limited scan time or to retrospectively harmonise the imaging protocols of two independent studies. Missing image modalities pose a challenge to segmentation frameworks as complementary information contributed by the missing scans is then lost. In this paper, we propose a novel model, Multi-modal Gaussian Process Prior Variational Autoencoder (MGP-VAE), to impute one or more missing sub-modalities for a patient scan. MGP-VAE can leverage the Gaussian Process (GP) prior on the Variational Autoencoder (VAE) to utilize the subjects/patients and sub-modalities correlations. Instead of designing one network for each possible subset of present sub-modalities or using frameworks to mix feature maps, missing data can be generated from a single model based on all the available samples. We show the applicability of MGP-VAE on brain tumor segmentation where either, two, or three of four sub-modalities may be missing. Our experiments against competitive segmentation baselines with missing sub-modality on BraTS'19 dataset indicate the effectiveness of the MGP-VAE model for segmentation tasks.
Bringing Structure into Summaries: a Faceted Summarization Dataset for Long Scientific Documents
May 31, 2021
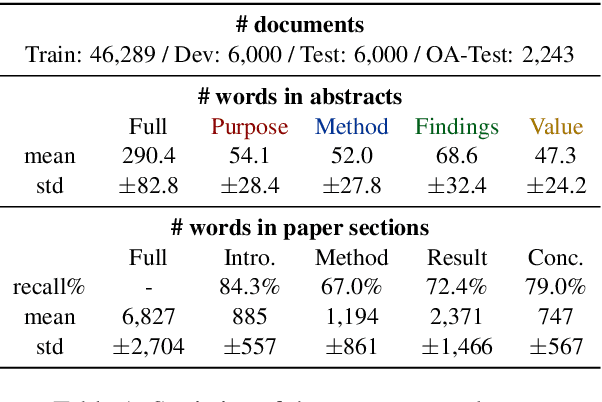

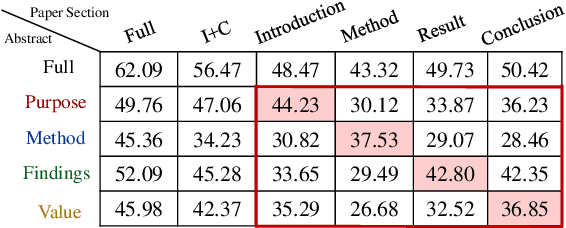
Faceted summarization provides briefings of a document from different perspectives. Readers can quickly comprehend the main points of a long document with the help of a structured outline. However, little research has been conducted on this subject, partially due to the lack of large-scale faceted summarization datasets. In this study, we present FacetSum, a faceted summarization benchmark built on Emerald journal articles, covering a diverse range of domains. Different from traditional document-summary pairs, FacetSum provides multiple summaries, each targeted at specific sections of a long document, including the purpose, method, findings, and value. Analyses and empirical results on our dataset reveal the importance of bringing structure into summaries. We believe FacetSum will spur further advances in summarization research and foster the development of NLP systems that can leverage the structured information in both long texts and summaries.
Pseudo-supervised Deep Subspace Clustering
Apr 08, 2021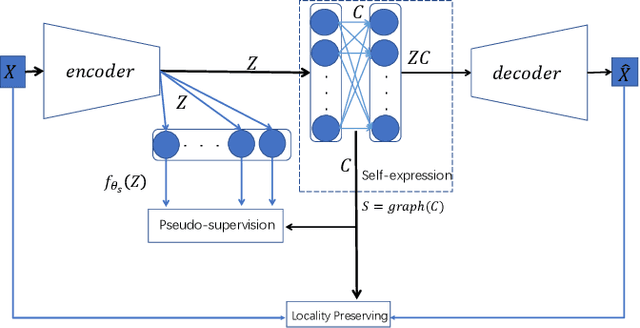
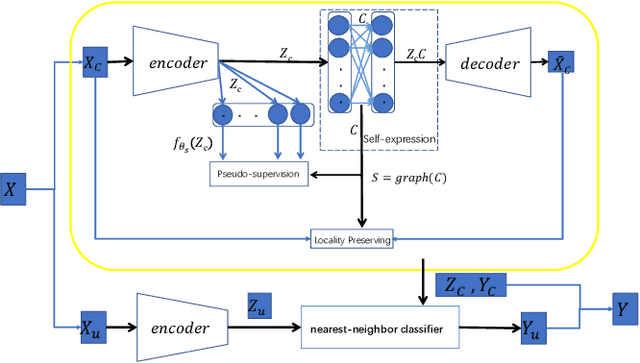
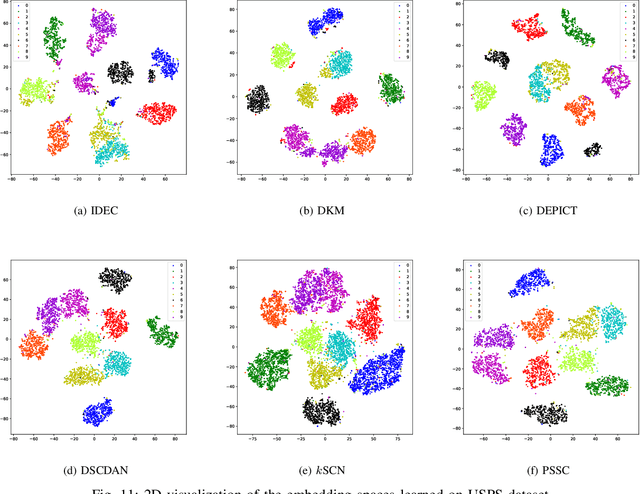
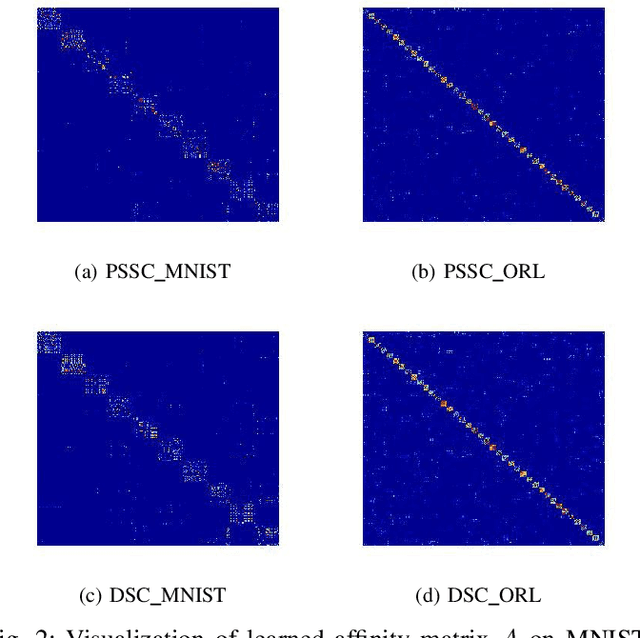
Auto-Encoder (AE)-based deep subspace clustering (DSC) methods have achieved impressive performance due to the powerful representation extracted using deep neural networks while prioritizing categorical separability. However, self-reconstruction loss of an AE ignores rich useful relation information and might lead to indiscriminative representation, which inevitably degrades the clustering performance. It is also challenging to learn high-level similarity without feeding semantic labels. Another unsolved problem facing DSC is the huge memory cost due to $n\times n$ similarity matrix, which is incurred by the self-expression layer between an encoder and decoder. To tackle these problems, we use pairwise similarity to weigh the reconstruction loss to capture local structure information, while a similarity is learned by the self-expression layer. Pseudo-graphs and pseudo-labels, which allow benefiting from uncertain knowledge acquired during network training, are further employed to supervise similarity learning. Joint learning and iterative training facilitate to obtain an overall optimal solution. Extensive experiments on benchmark datasets demonstrate the superiority of our approach. By combining with the $k$-nearest neighbors algorithm, we further show that our method can address the large-scale and out-of-sample problems.
Knowledge distillation from multi-modal to mono-modal segmentation networks
Jun 17, 2021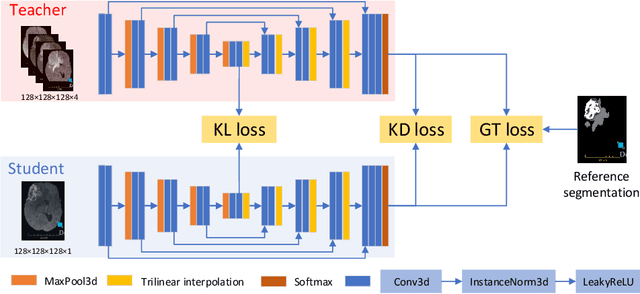
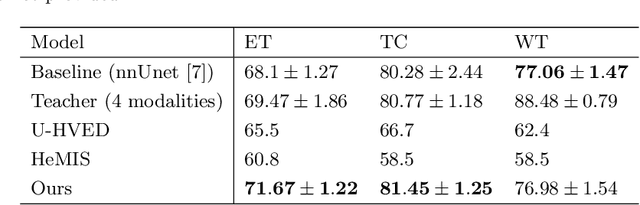
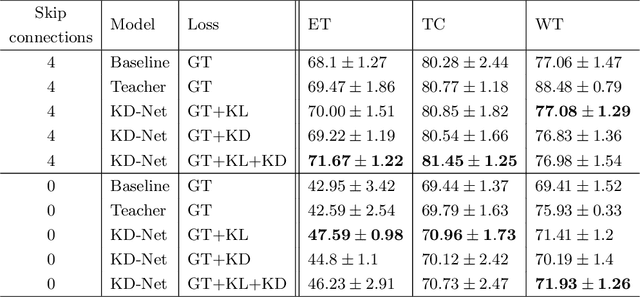
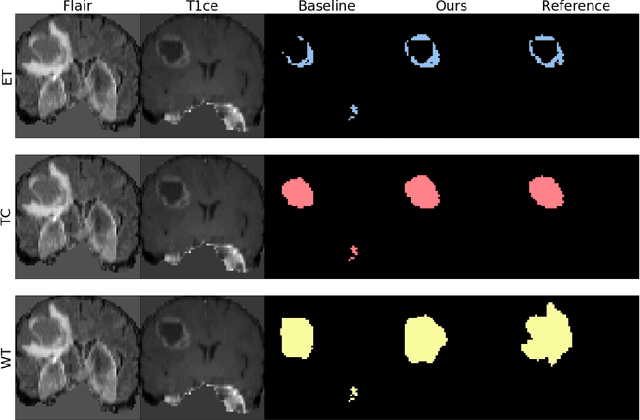
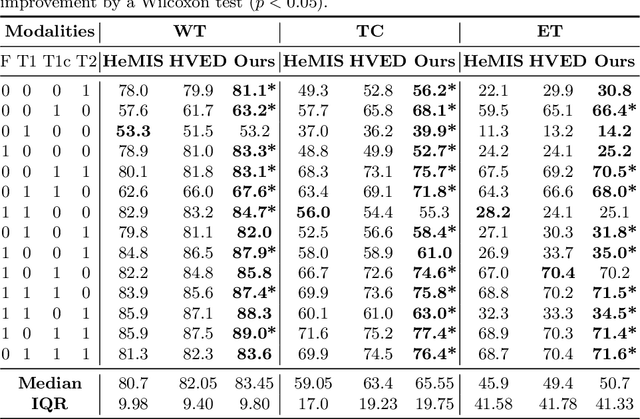
The joint use of multiple imaging modalities for medical image segmentation has been widely studied in recent years. The fusion of information from different modalities has demonstrated to improve the segmentation accuracy, with respect to mono-modal segmentations, in several applications. However, acquiring multiple modalities is usually not possible in a clinical setting due to a limited number of physicians and scanners, and to limit costs and scan time. Most of the time, only one modality is acquired. In this paper, we propose KD-Net, a framework to transfer knowledge from a trained multi-modal network (teacher) to a mono-modal one (student). The proposed method is an adaptation of the generalized distillation framework where the student network is trained on a subset (1 modality) of the teacher's inputs (n modalities). We illustrate the effectiveness of the proposed framework in brain tumor segmentation with the BraTS 2018 dataset. Using different architectures, we show that the student network effectively learns from the teacher and always outperforms the baseline mono-modal network in terms of segmentation accuracy.
* MICCAI 2020
Self-Paced Context Evaluation for Contextual Reinforcement Learning
Jun 09, 2021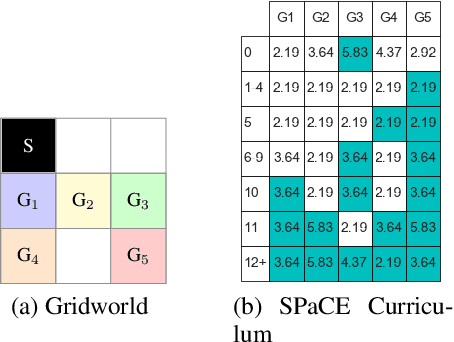
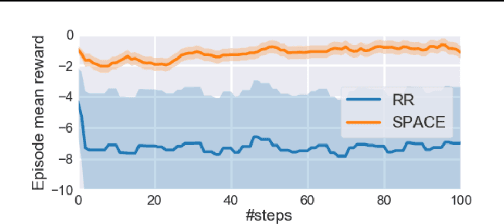
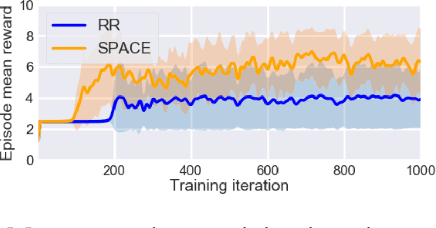
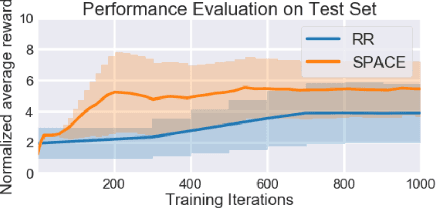
Reinforcement learning (RL) has made a lot of advances for solving a single problem in a given environment; but learning policies that generalize to unseen variations of a problem remains challenging. To improve sample efficiency for learning on such instances of a problem domain, we present Self-Paced Context Evaluation (SPaCE). Based on self-paced learning, \spc automatically generates \task curricula online with little computational overhead. To this end, SPaCE leverages information contained in state values during training to accelerate and improve training performance as well as generalization capabilities to new instances from the same problem domain. Nevertheless, SPaCE is independent of the problem domain at hand and can be applied on top of any RL agent with state-value function approximation. We demonstrate SPaCE's ability to speed up learning of different value-based RL agents on two environments, showing better generalization capabilities and up to 10x faster learning compared to naive approaches such as round robin or SPDRL, as the closest state-of-the-art approach.
Boundary-Aware 3D Object Detection from Point Clouds
May 05, 2021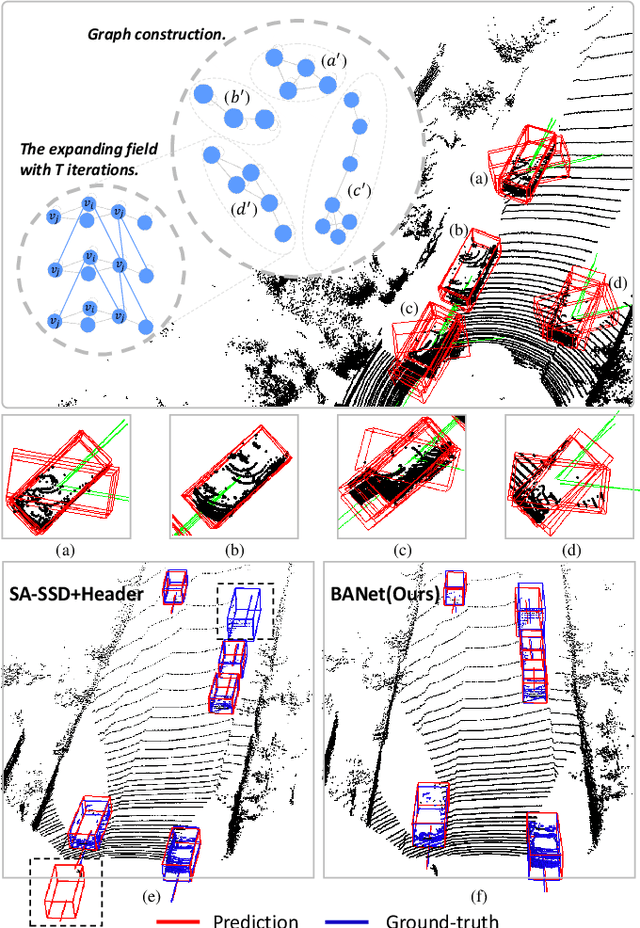
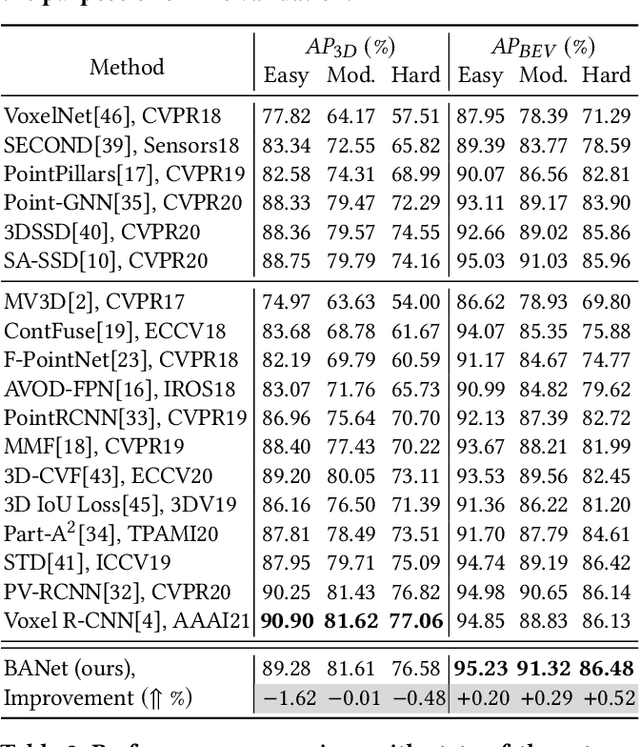
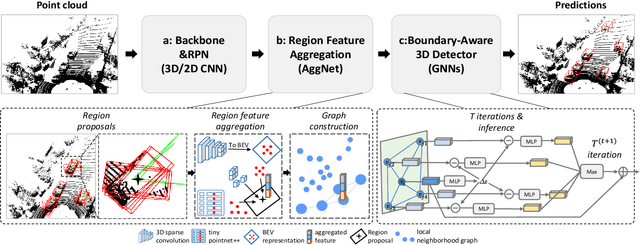
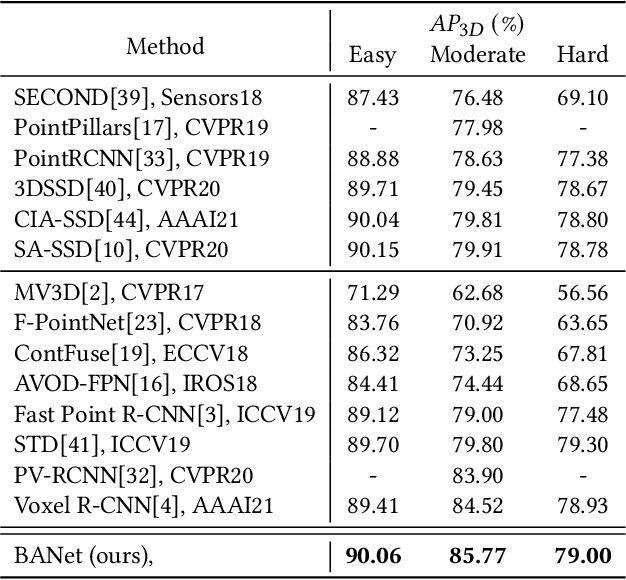
Currently, existing state-of-the-art 3D object detectors are in two-stage paradigm. These methods typically comprise two steps: 1) Utilize region proposal network to propose a fraction of high-quality proposals in a bottom-up fashion. 2) Resize and pool the semantic features from the proposed regions to summarize RoI-wise representations for further refinement. Note that these RoI-wise representations in step 2) are considered individually as an uncorrelated entry when fed to following detection headers. Nevertheless, we observe these proposals generated by step 1) offset from ground truth somehow, emerging in local neighborhood densely with an underlying probability. Challenges arise in the case where a proposal largely forsakes its boundary information due to coordinate offset while existing networks lack corresponding information compensation mechanism. In this paper, we propose BANet for 3D object detection from point clouds. Specifically, instead of refining each proposal independently as previous works do, we represent each proposal as a node for graph construction within a given cut-off threshold, associating proposals in the form of local neighborhood graph, with boundary correlations of an object being explicitly exploited. Besides, we devise a lightweight Region Feature Aggregation Network to fully exploit voxel-wise, pixel-wise, and point-wise feature with expanding receptive fields for more informative RoI-wise representations. As of Apr. 17th, 2021, our BANet achieves on par performance on KITTI 3D detection leaderboard and ranks $1^{st}$ on $Moderate$ difficulty of $Car$ category on KITTI BEV detection leaderboard. The source code will be released once the paper is accepted.
Dynamic Metasurface Antennas for Energy Efficient Massive MIMO Uplink Communications
Jun 17, 2021
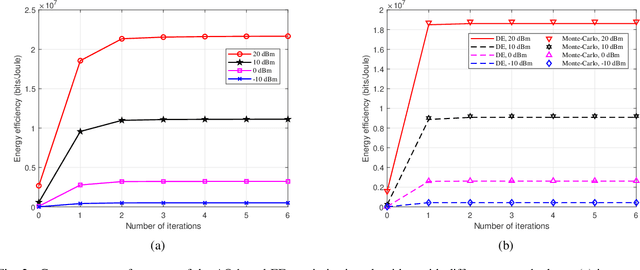
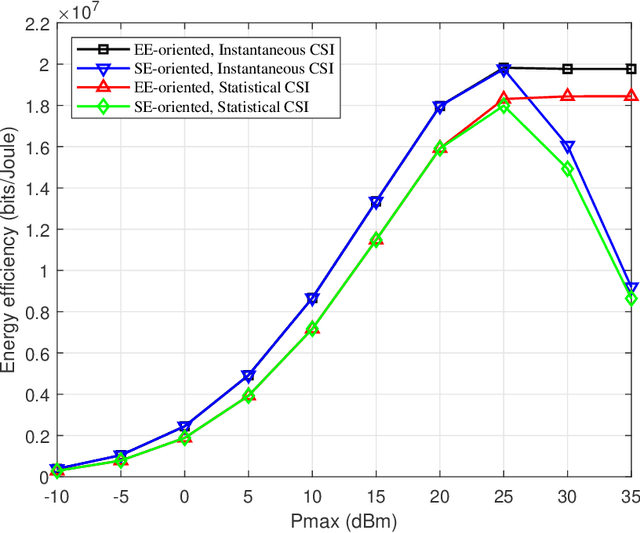
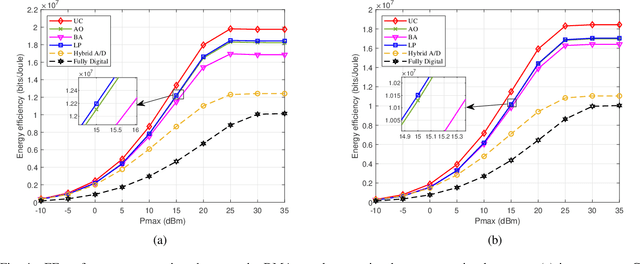
Future wireless communications are largely inclined to deploy a massive number of antennas at the base stations (BS) by exploiting energy-efficient and environmentally friendly technologies. An emerging technology called dynamic metasurface antennas (DMAs) is promising to realize such massive antenna arrays with reduced physical size, hardware cost, and power consumption. This paper aims to optimize the energy efficiency (EE) performance of DMAs-assisted massive MIMO uplink communications. We propose an algorithmic framework for designing the transmit precoding of each multi-antenna user and the DMAs tuning strategy at the BS to maximize the EE performance, considering the availability of the instantaneous and statistical channel state information (CSI), respectively. Specifically, the proposed framework includes Dinkelbach's transform, alternating optimization, and deterministic equivalent methods. In addition, we obtain a closed-form solution to the optimal transmit signal directions for the statistical CSI case, which simplifies the corresponding transmission design. The numerical results show good convergence performance of our proposed algorithms as well as considerable EE performance gains of the DMAs-assisted massive MIMO uplink communications over the baseline schemes.
Generative Adversarial Networks (GAN) Powered Fast Magnetic Resonance Imaging -- Mini Review, Comparison and Perspectives
May 04, 2021
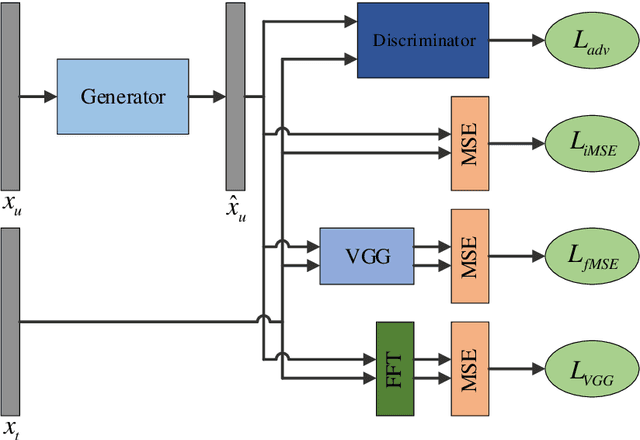
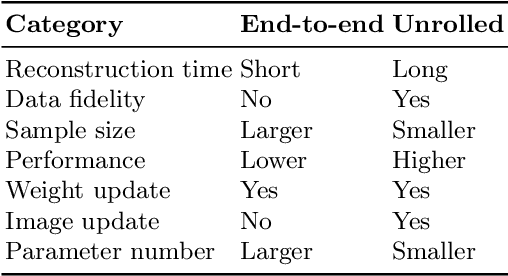
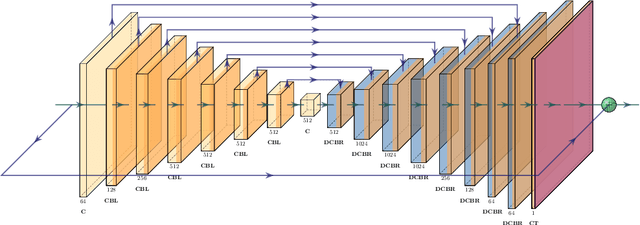
Magnetic Resonance Imaging (MRI) is a vital component of medical imaging. When compared to other image modalities, it has advantages such as the absence of radiation, superior soft tissue contrast, and complementary multiple sequence information. However, one drawback of MRI is its comparatively slow scanning and reconstruction compared to other image modalities, limiting its usage in some clinical applications when imaging time is critical. Traditional compressive sensing based MRI (CS-MRI) reconstruction can speed up MRI acquisition, but suffers from a long iterative process and noise-induced artefacts. Recently, Deep Neural Networks (DNNs) have been used in sparse MRI reconstruction models to recreate relatively high-quality images from heavily undersampled k-space data, allowing for much faster MRI scanning. However, there are still some hurdles to tackle. For example, directly training DNNs based on L1/L2 distance to the target fully sampled images could result in blurry reconstruction because L1/L2 loss can only enforce overall image or patch similarity and does not take into account local information such as anatomical sharpness. It is also hard to preserve fine image details while maintaining a natural appearance. More recently, Generative Adversarial Networks (GAN) based methods are proposed to solve fast MRI with enhanced image perceptual quality. The encoder obtains a latent space for the undersampling image, and the image is reconstructed by the decoder using the GAN loss. In this chapter, we review the GAN powered fast MRI methods with a comparative study on various anatomical datasets to demonstrate the generalisability and robustness of this kind of fast MRI while providing future perspectives.