 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Get away from Style: Category-Guided Domain Adaptation for Semantic Segmentation
Mar 29, 2021
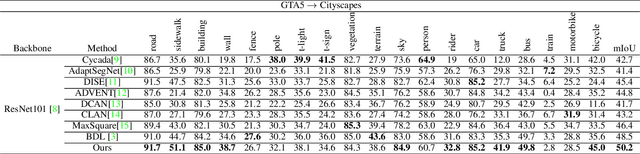
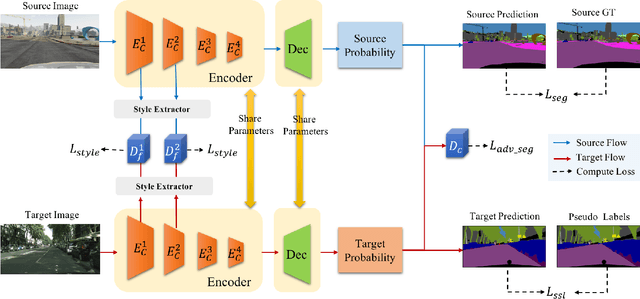

Unsupervised domain adaptation (UDA) becomes more and more popular in tackling real-world problems without ground truth of the target domain. Though a mass of tedious annotation work is not needed, UDA unavoidably faces the problem how to narrow the domain discrepancy to boost the transferring performance. In this paper, we focus on UDA for semantic segmentation task. Firstly, we propose a style-independent content feature extraction mechanism to keep the style information of extracted features in the similar space, since the style information plays a extremely slight role for semantic segmentation compared with the content part. Secondly, to keep the balance of pseudo labels on each category, we propose a category-guided threshold mechanism to choose category-wise pseudo labels for self-supervised learning. The experiments are conducted using GTA5 as the source domain, Cityscapes as the target domain. The results show that our model outperforms the state-of-the-arts with a noticeable gain on cross-domain adaptation tasks.
Deep Neural Networks Evolve Human-like Attention Distribution during Reading Comprehension
Jul 13, 2021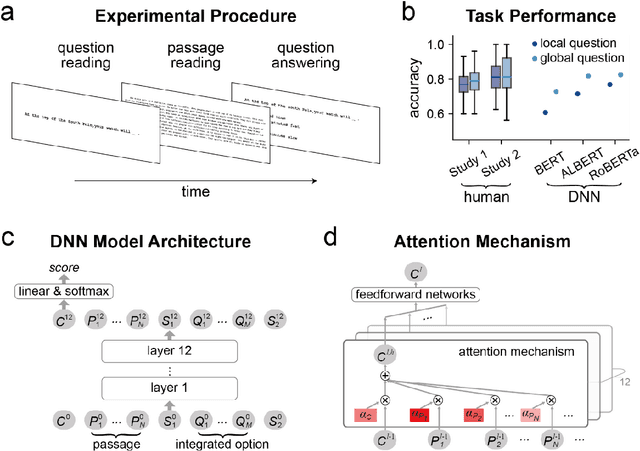

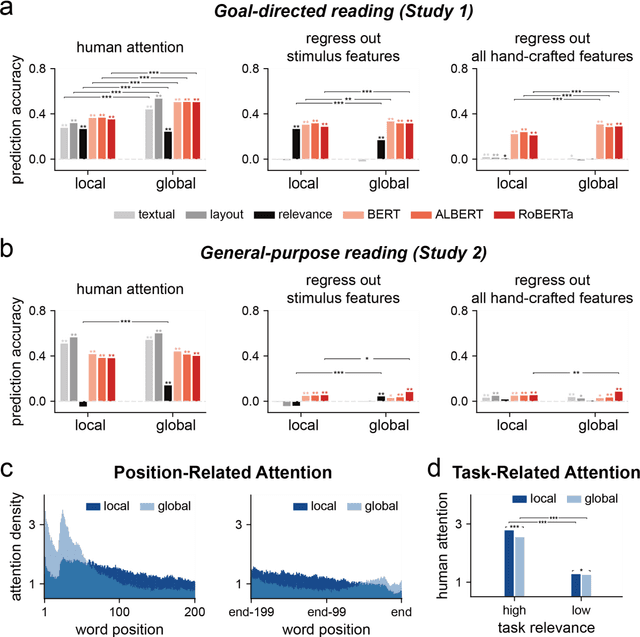
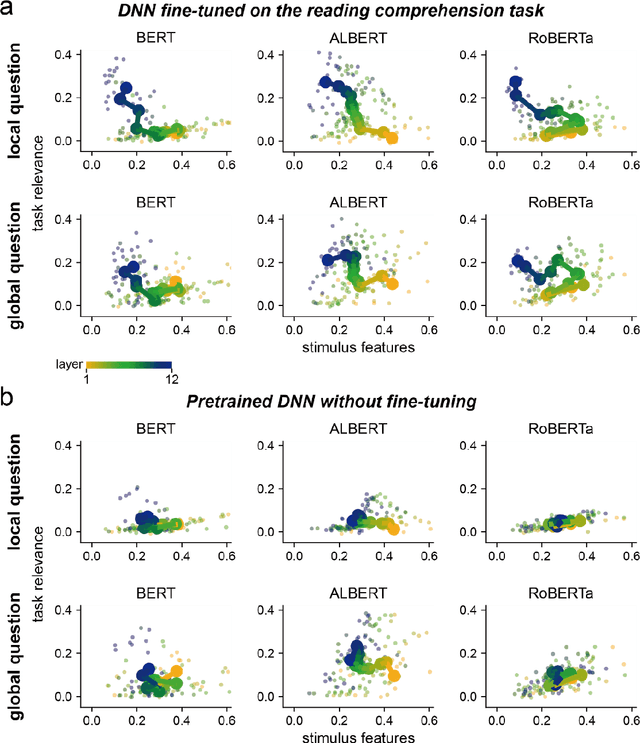
Attention is a key mechanism for information selection in both biological brains and many state-of-the-art deep neural networks (DNNs). Here, we investigate whether humans and DNNs allocate attention in comparable ways when reading a text passage to subsequently answer a specific question. We analyze 3 transformer-based DNNs that reach human-level performance when trained to perform the reading comprehension task. We find that the DNN attention distribution quantitatively resembles human attention distribution measured by fixation times. Human readers fixate longer on words that are more relevant to the question-answering task, demonstrating that attention is modulated by top-down reading goals, on top of lower-level visual and text features of the stimulus. Further analyses reveal that the attention weights in DNNs are also influenced by both top-down reading goals and lower-level stimulus features, with the shallow layers more strongly influenced by lower-level text features and the deep layers attending more to task-relevant words. Additionally, deep layers' attention to task-relevant words gradually emerges when pre-trained DNN models are fine-tuned to perform the reading comprehension task, which coincides with the improvement in task performance. These results demonstrate that DNNs can evolve human-like attention distribution through task optimization, which suggests that human attention during goal-directed reading comprehension is a consequence of task optimization.
Distributed stochastic optimization with large delays
Jul 06, 2021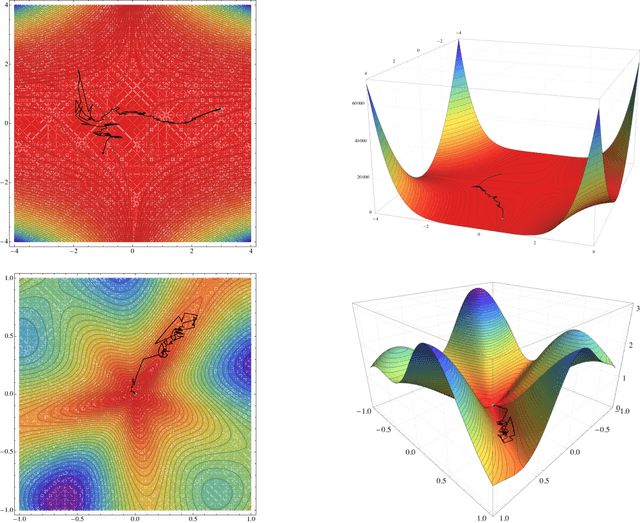
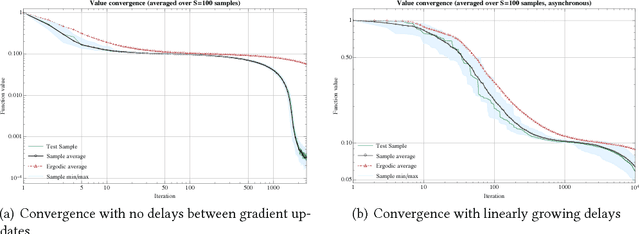
One of the most widely used methods for solving large-scale stochastic optimization problems is distributed asynchronous stochastic gradient descent (DASGD), a family of algorithms that result from parallelizing stochastic gradient descent on distributed computing architectures (possibly) asychronously. However, a key obstacle in the efficient implementation of DASGD is the issue of delays: when a computing node contributes a gradient update, the global model parameter may have already been updated by other nodes several times over, thereby rendering this gradient information stale. These delays can quickly add up if the computational throughput of a node is saturated, so the convergence of DASGD may be compromised in the presence of large delays. Our first contribution is that, by carefully tuning the algorithm's step-size, convergence to the critical set is still achieved in mean square, even if the delays grow unbounded at a polynomial rate. We also establish finer results in a broad class of structured optimization problems (called variationally coherent), where we show that DASGD converges to a global optimum with probability $1$ under the same delay assumptions. Together, these results contribute to the broad landscape of large-scale non-convex stochastic optimization by offering state-of-the-art theoretical guarantees and providing insights for algorithm design.
OntoEA: Ontology-guided Entity Alignment via Joint Knowledge Graph Embedding
May 17, 2021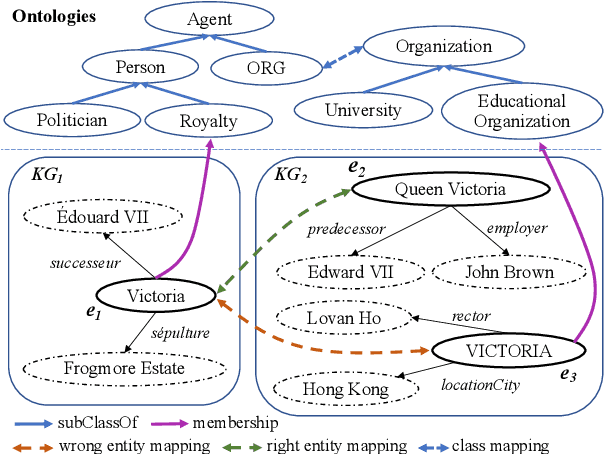
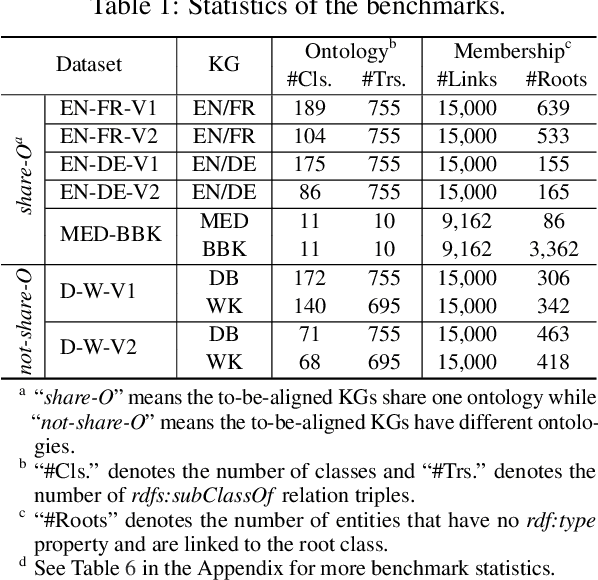
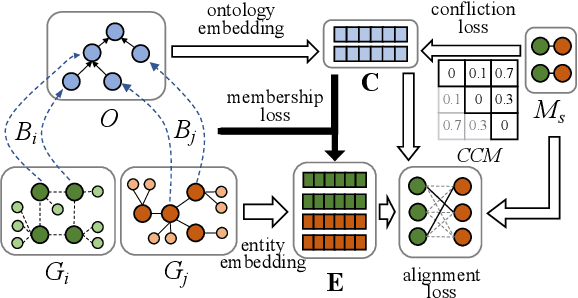
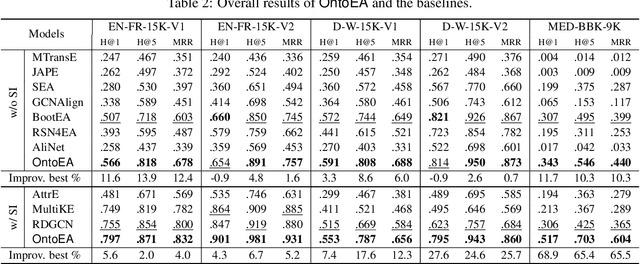
Semantic embedding has been widely investigated for aligning knowledge graph (KG) entities. Current methods have explored and utilized the graph structure, the entity names and attributes, but ignore the ontology (or ontological schema) which contains critical meta information such as classes and their membership relationships with entities. In this paper, we propose an ontology-guided entity alignment method named OntoEA, where both KGs and their ontologies are jointly embedded, and the class hierarchy and the class disjointness are utilized to avoid false mappings. Extensive experiments on seven public and industrial benchmarks have demonstrated the state-of-the-art performance of OntoEA and the effectiveness of the ontologies.
Fast and Scalable Image Search For Histology
Jul 28, 2021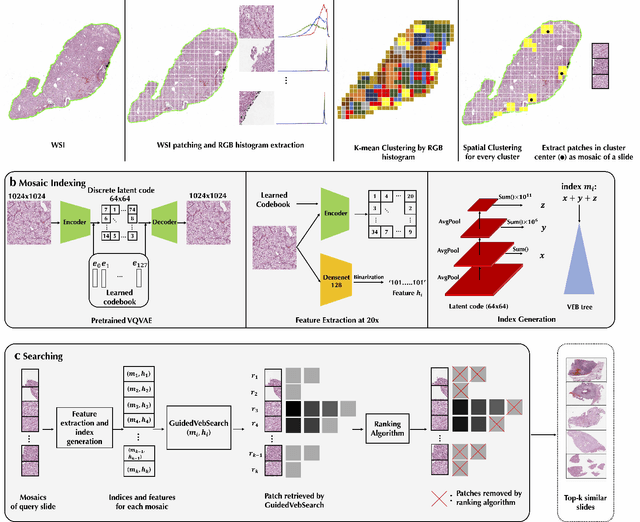
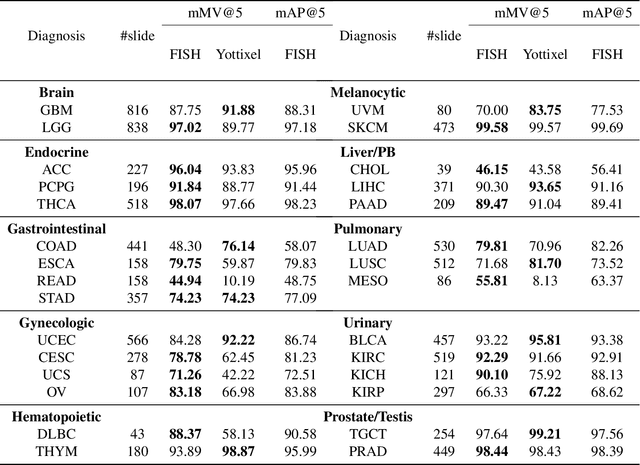
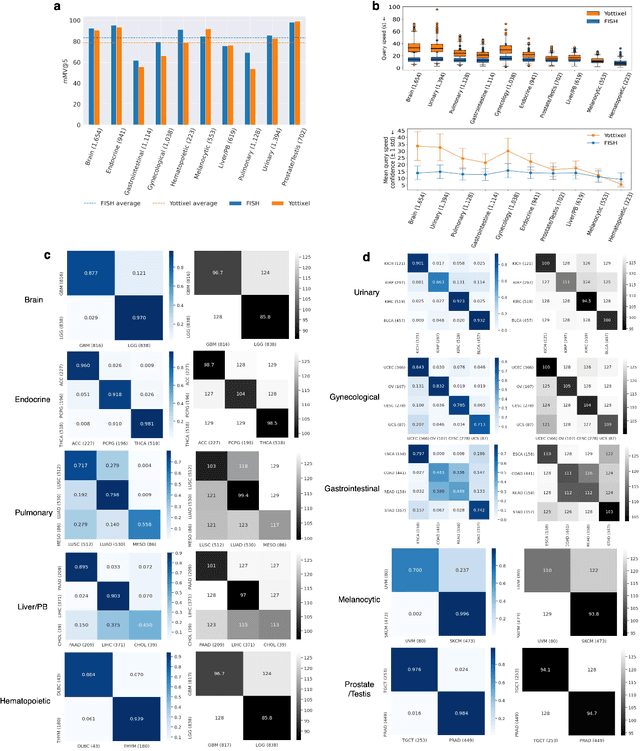
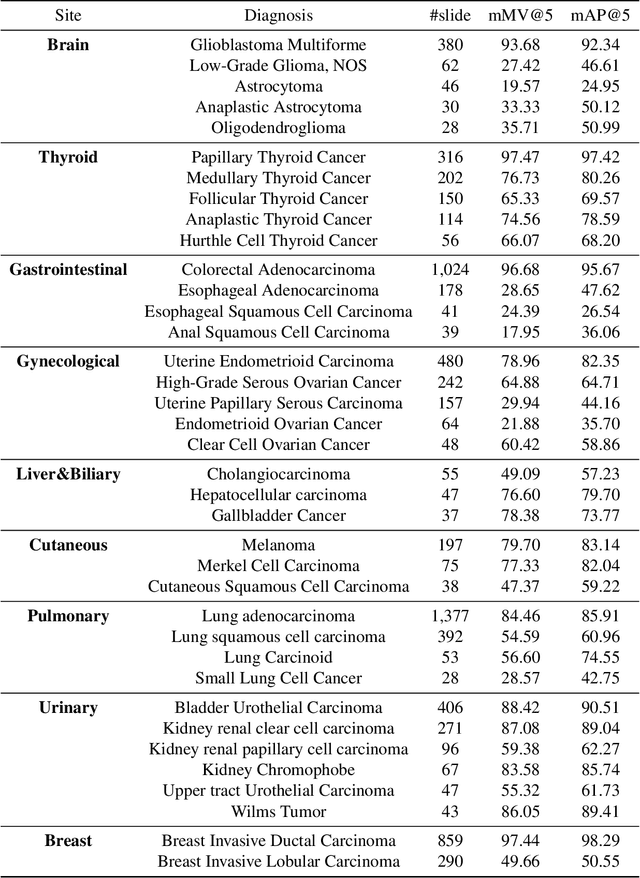
The expanding adoption of digital pathology has enabled the curation of large repositories of histology whole slide images (WSIs), which contain a wealth of information. Similar pathology image search offers the opportunity to comb through large historical repositories of gigapixel WSIs to identify cases with similar morphological features and can be particularly useful for diagnosing rare diseases, identifying similar cases for predicting prognosis, treatment outcomes, and potential clinical trial success. A critical challenge in developing a WSI search and retrieval system is scalability, which is uniquely challenging given the need to search a growing number of slides that each can consist of billions of pixels and are several gigabytes in size. Such systems are typically slow and retrieval speed often scales with the size of the repository they search through, making their clinical adoption tedious and are not feasible for repositories that are constantly growing. Here we present Fast Image Search for Histopathology (FISH), a histology image search pipeline that is infinitely scalable and achieves constant search speed that is independent of the image database size while being interpretable and without requiring detailed annotations. FISH uses self-supervised deep learning to encode meaningful representations from WSIs and a Van Emde Boas tree for fast search, followed by an uncertainty-based ranking algorithm to retrieve similar WSIs. We evaluated FISH on multiple tasks and datasets with over 22,000 patient cases spanning 56 disease subtypes. We additionally demonstrate that FISH can be used to assist with the diagnosis of rare cancer types where sufficient cases may not be available to train traditional supervised deep models. FISH is available as an easy-to-use, open-source software package (https://github.com/mahmoodlab/FISH).
Discovering Collaborative Signals for Next POI Recommendation with Iterative Seq2Graph Augmentation
Jun 30, 2021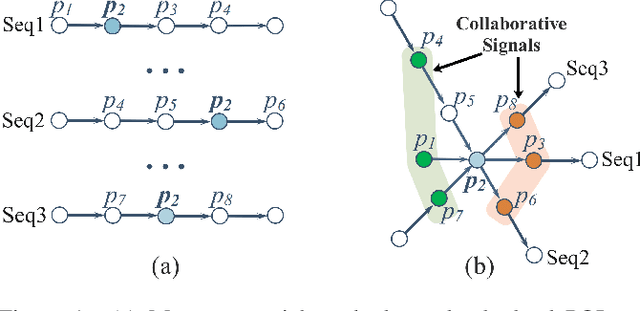

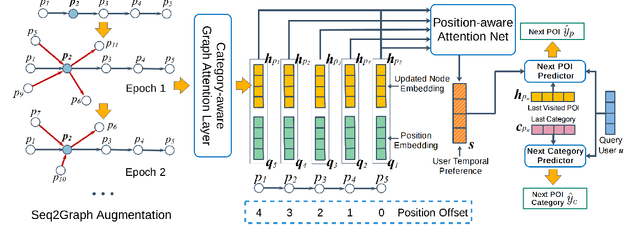
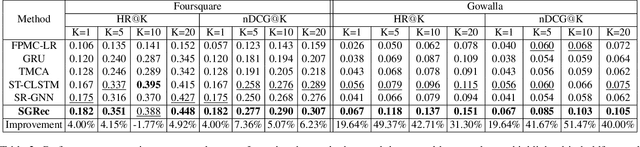
Being an indispensable component in location-based social networks, next point-of-interest (POI) recommendation recommends users unexplored POIs based on their recent visiting histories. However, existing work mainly models check-in data as isolated POI sequences, neglecting the crucial collaborative signals from cross-sequence check-in information. Furthermore, the sparse POI-POI transitions restrict the ability of a model to learn effective sequential patterns for recommendation. In this paper, we propose Sequence-to-Graph (Seq2Graph) augmentation for each POI sequence, allowing collaborative signals to be propagated from correlated POIs belonging to other sequences. We then devise a novel Sequence-to-Graph POI Recommender (SGRec), which jointly learns POI embeddings and infers a user's temporal preferences from the graph-augmented POI sequence. To overcome the sparsity of POI-level interactions, we further infuse category-awareness into SGRec with a multi-task learning scheme that captures the denser category-wise transitions. As such, SGRec makes full use of the collaborative signals for learning expressive POI representations, and also comprehensively uncovers multi-level sequential patterns for user preference modelling. Extensive experiments on two real-world datasets demonstrate the superiority of SGRec against state-of-the-art methods in next POI recommendation.
Comparing merging behaviors observed in naturalistic data with behaviors generated by a machine learned model
Apr 21, 2021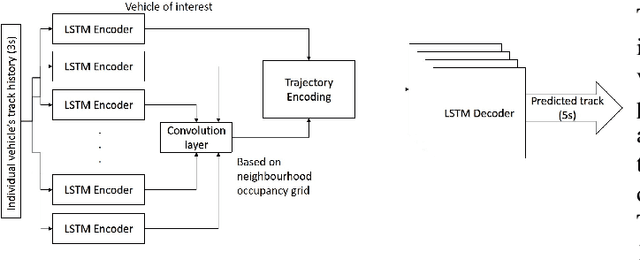
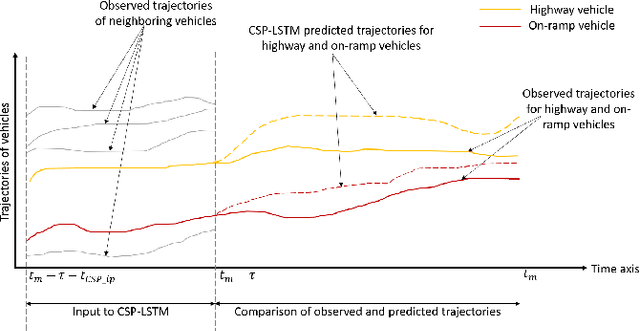
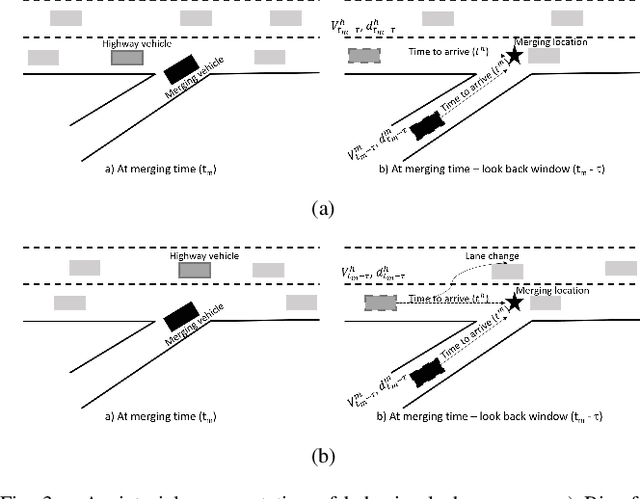
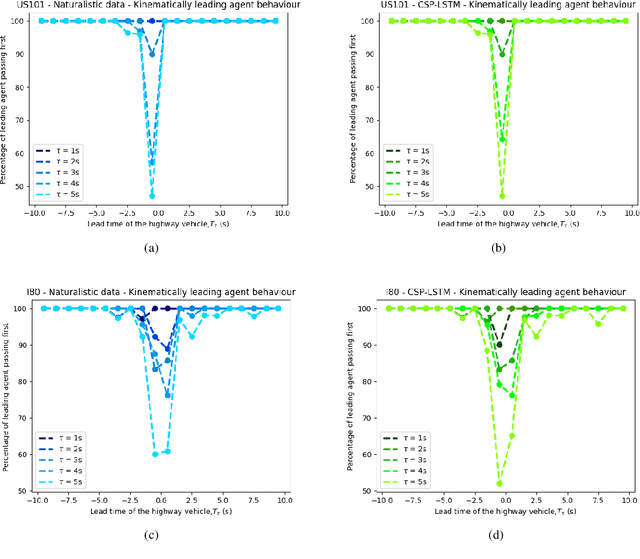
There is quickly growing literature on machine-learned models that predict human driving trajectories in road traffic. These models focus their learning on low-dimensional error metrics, for example average distance between model-generated and observed trajectories. Such metrics permit relative comparison of models, but do not provide clearly interpretable information on how close to human behavior the models actually come, for example in terms of higher-level behavior phenomena that are known to be present in human driving. We study highway driving as an example scenario, and introduce metrics to quantitatively demonstrate the presence, in a naturalistic dataset, of two familiar behavioral phenomena: (1) The kinematics-dependent contest, between on-highway and on-ramp vehicles, of who passes the merging point first. (2) Courtesy lane changes away from the outermost lane, to leave space for a merging vehicle. Applying the exact same metrics to the output of a state-of-the-art machine-learned model, we show that the model is capable of reproducing the former phenomenon, but not the latter. We argue that this type of behavioral analysis provides information that is not available from conventional model-fitting metrics, and that it may be useful to analyze (and possibly fit) models also based on these types of behavioral criteria.
Artefact-removal algorithms for Fourier domain Quantum Optical Coherence Tomography
Mar 29, 2021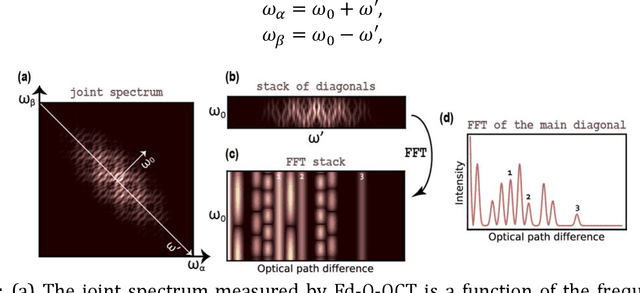
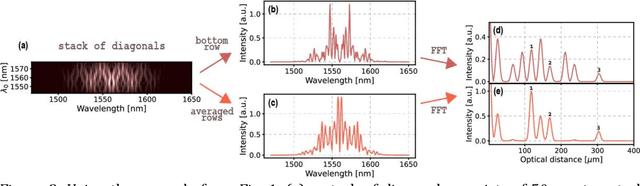
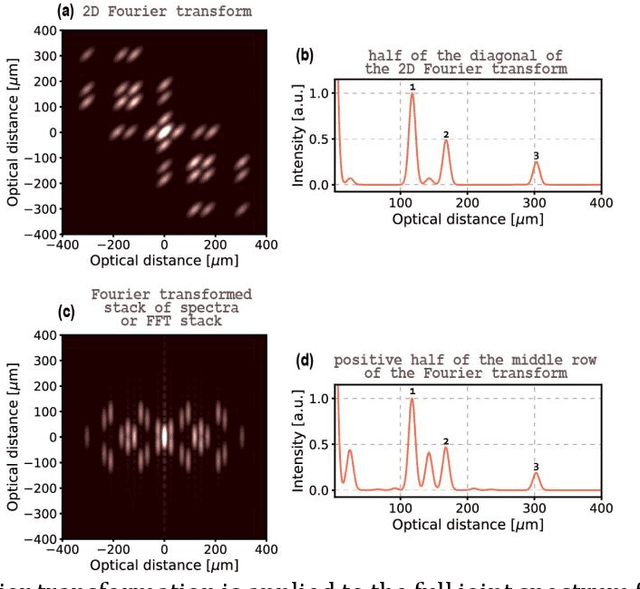
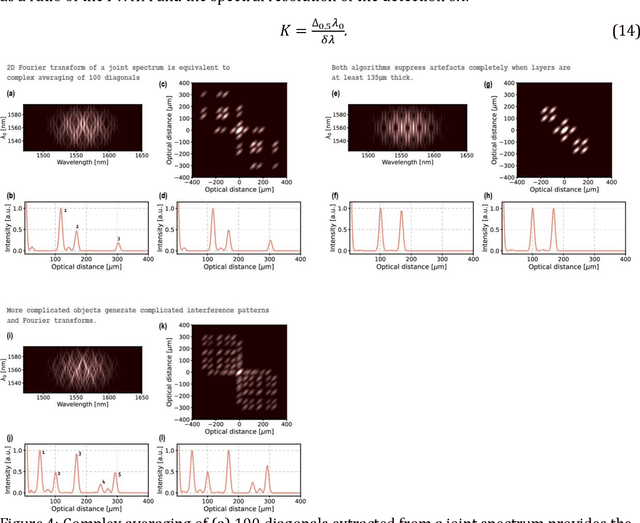
Quantum Optical Coherence Tomography (Q-OCT) is a non-classical equivalent of Optical Coherence Tomography and is able to provide a twofold axial resolution increase and immunity to resolution-degrading dispersion. The main drawback of Q-OCT are artefacts which are additional elements that clutter an A-scan and lead to a complete loss of structural information for multilayered objects. Whereas there are successful methods for artefact removal in Time-domain Q-OCT, no such scheme has been devised for Fourier-domain Q-OCT (Fd-Q-OCT), although the latter modality - through joint spectrum detection - outputs a lot of useful information on both the system and the imaged object. Here, we propose two algorithms which process a Fd-Q-OCT's joint spectrum into an artefact-free A-scan. We present the theoretical background of these algorithms and show their performance on computer-generated data. The limitations of both algorithms with regards to the experimental system and the imaged object are discussed.
Monocular 3D Object Detection: An Extrinsic Parameter Free Approach
Jun 30, 2021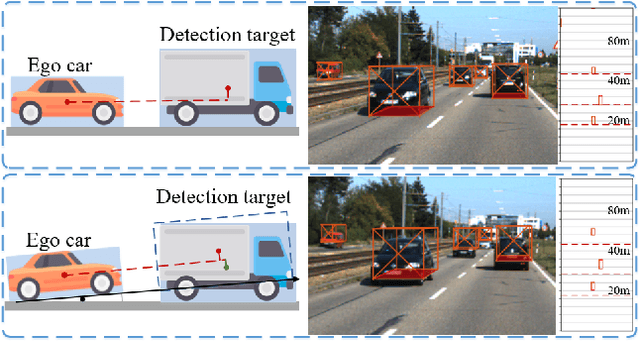
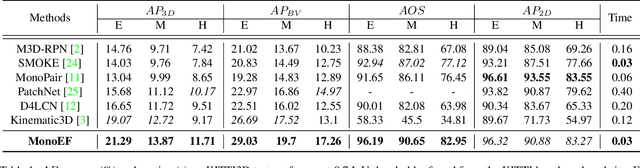
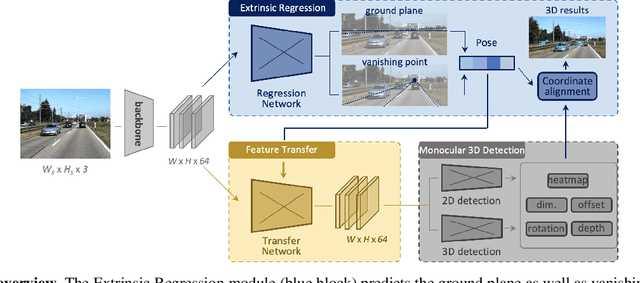
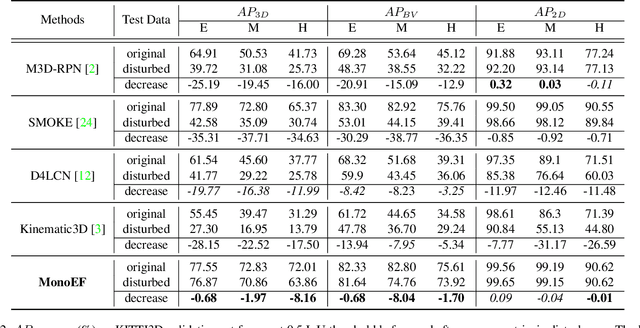
Monocular 3D object detection is an important task in autonomous driving. It can be easily intractable where there exists ego-car pose change w.r.t. ground plane. This is common due to the slight fluctuation of road smoothness and slope. Due to the lack of insight in industrial application, existing methods on open datasets neglect the camera pose information, which inevitably results in the detector being susceptible to camera extrinsic parameters. The perturbation of objects is very popular in most autonomous driving cases for industrial products. To this end, we propose a novel method to capture camera pose to formulate the detector free from extrinsic perturbation. Specifically, the proposed framework predicts camera extrinsic parameters by detecting vanishing point and horizon change. A converter is designed to rectify perturbative features in the latent space. By doing so, our 3D detector works independent of the extrinsic parameter variations and produces accurate results in realistic cases, e.g., potholed and uneven roads, where almost all existing monocular detectors fail to handle. Experiments demonstrate our method yields the best performance compared with the other state-of-the-arts by a large margin on both KITTI 3D and nuScenes datasets.
Force Sensing in Robot-assisted Keyhole Endoscopy: A Systematic Survey
Mar 20, 2021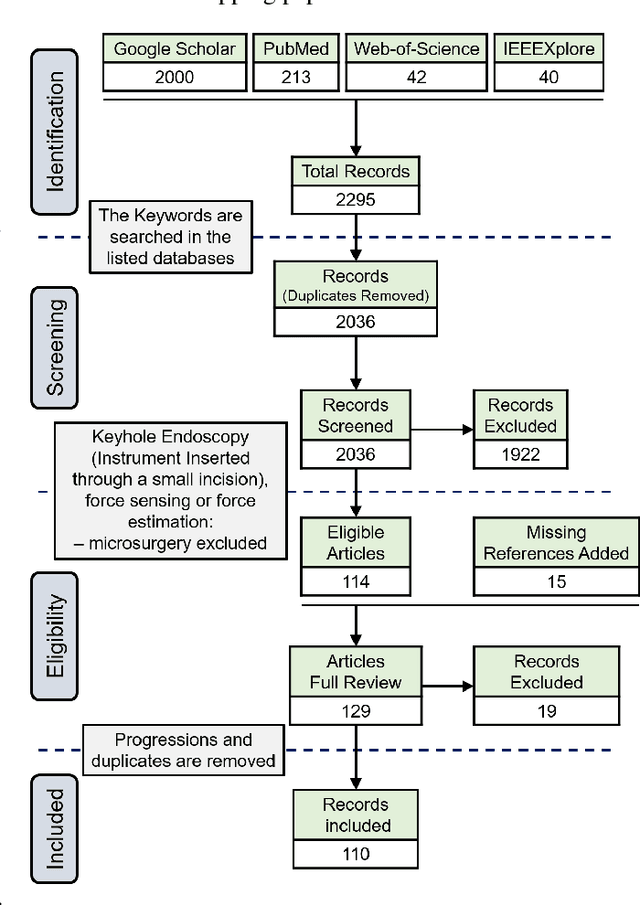
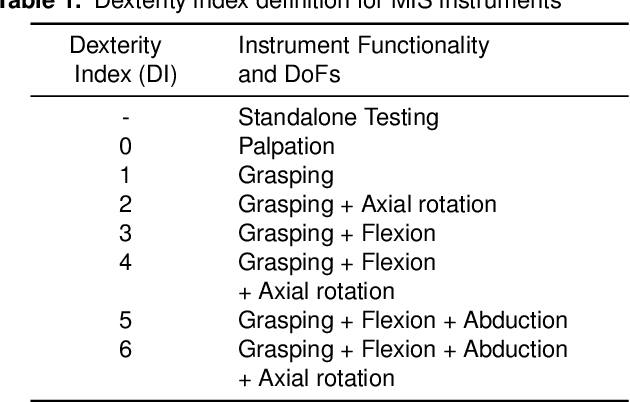
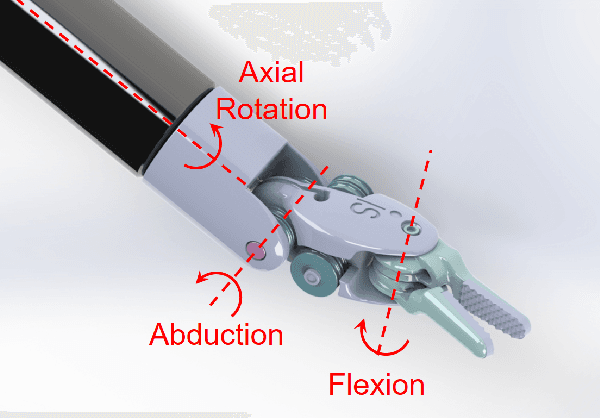
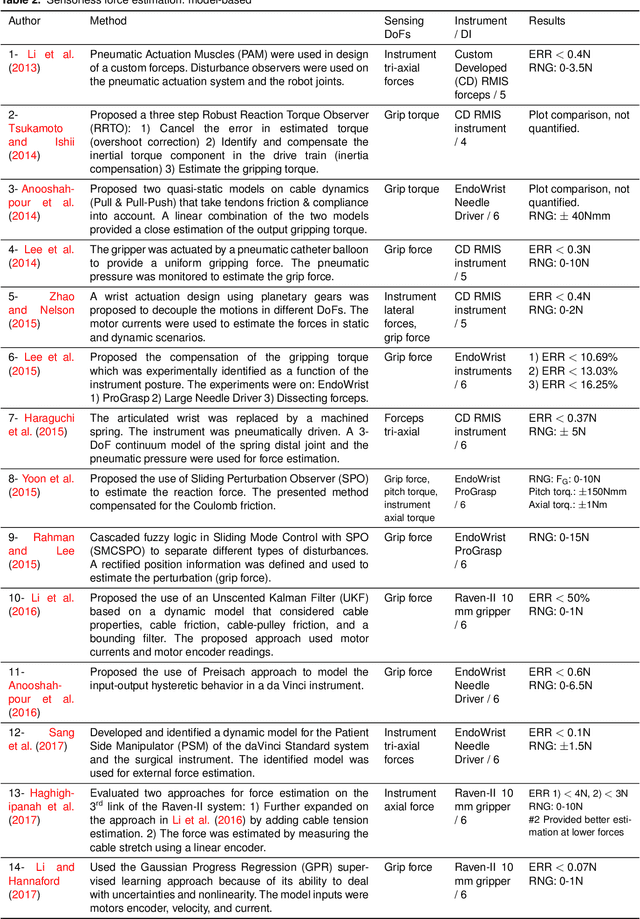
Instrument-tissue interaction forces in Minimally Invasive Surgery (MIS) provide valuable information that can be used to provide haptic perception, monitor tissue trauma, develop training guidelines, and evaluate the skill level of novice and expert surgeons.Force and tactile sensing is lost in many Robot-Assisted Surgery (RAS) systems. Therefore, many researchers have focused on recovering this information through sensing systems and estimation algorithms. This article provides a comprehensive systematic review of the current force sensing research aimed at RAS and, more generally, keyhole endoscopy, in which instruments enter the body through small incisions. Articles published between January 2011 and May 2020 are considered, following the Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) guidelines. The literature search resulted in 110 papers on different force estimation algorithms and sensing technologies, sensor design specifications, and fabrication techniques.