 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep learning for prediction of hepatocellular carcinoma recurrence after resection or liver transplantation: a discovery and validation study
May 31, 2021

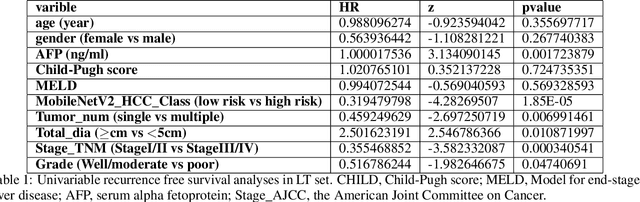
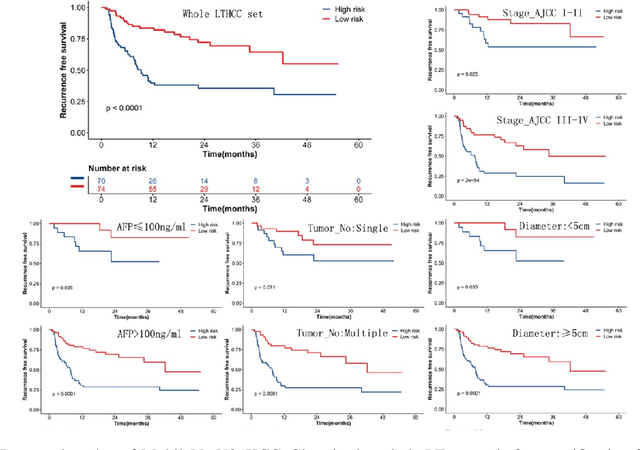
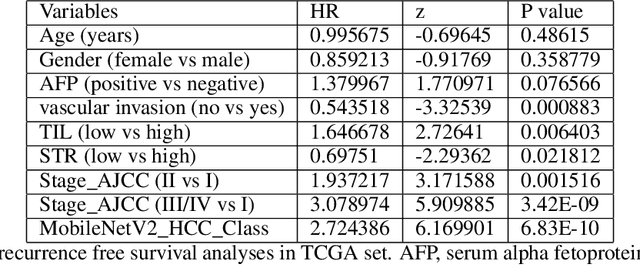
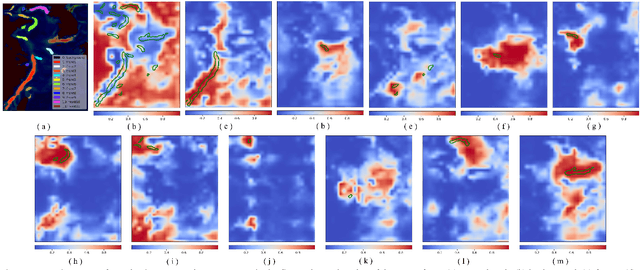
This study aimed to develop a classifier of prognosis after resection or liver transplantation (LT) for HCC by directly analysing the ubiquitously available histological images using deep learning based neural networks. Nucleus map set was used to train U-net to capture the nuclear architectural information. Train set included the patients with HCC treated by resection and has a distinct outcome. LT set contained patients with HCC treated by LT. Train set and its nuclear architectural information extracted by U-net were used to train MobileNet V2 based classifier (MobileNetV2_HCC_Class), purpose-built for classifying supersized heterogeneous images. The MobileNetV2_HCC_Class maintained relative higher discriminatory power than the other factors after HCC resection or LT in the independent validation set. Pathological review showed that the tumoral areas most predictive of recurrence were characterized by presence of stroma, high degree of cytological atypia, nuclear hyperchomasia, and a lack of immune infiltration. A clinically useful prognostic classifier was developed using deep learning allied to histological slides. The classifier has been extensively evaluated in independent patient populations with different treatment, and gives consistent excellent results across the classical clinical, biological and pathological features. The classifier assists in refining the prognostic prediction of HCC patients and identifying patients who would benefit from more intensive management.
LSENet: Location and Seasonality Enhanced Network for Multi-Class Ocean Front Detection
Aug 05, 2021
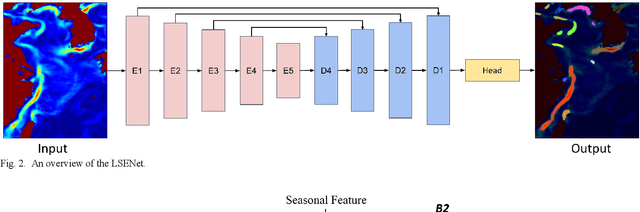
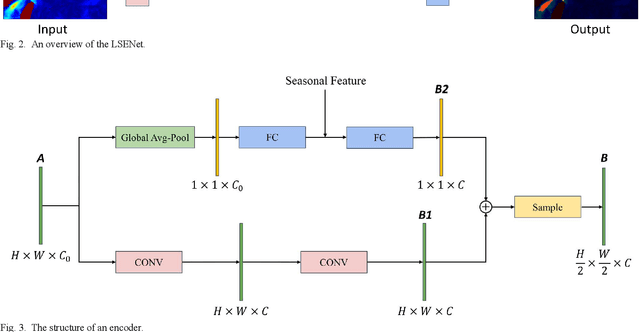
Ocean fronts can cause the accumulation of nutrients and affect the propagation of underwater sound, so high-precision ocean front detection is of great significance to the marine fishery and national defense fields. However, the current ocean front detection methods either have low detection accuracy or most can only detect the occurrence of ocean front by binary classification, rarely considering the differences of the characteristics of multiple ocean fronts in different sea areas. In order to solve the above problems, we propose a semantic segmentation network called location and seasonality enhanced network (LSENet) for multi-class ocean fronts detection at pixel level. In this network, we first design a channel supervision unit structure, which integrates the seasonal characteristics of the ocean front itself and the contextual information to improve the detection accuracy. We also introduce a location attention mechanism to adaptively assign attention weights to the fronts according to their frequently occurred sea area, which can further improve the accuracy of multi-class ocean front detection. Compared with other semantic segmentation methods and current representative ocean front detection method, the experimental results demonstrate convincingly that our method is more effective.
Deep Sensing of Urban Waterlogging
Mar 10, 2021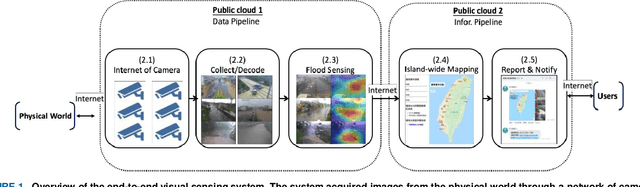
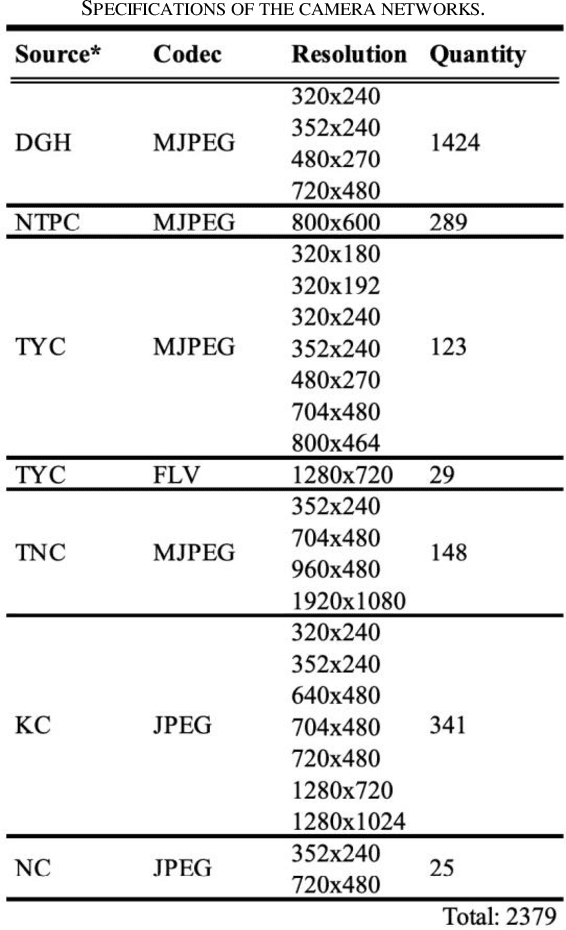
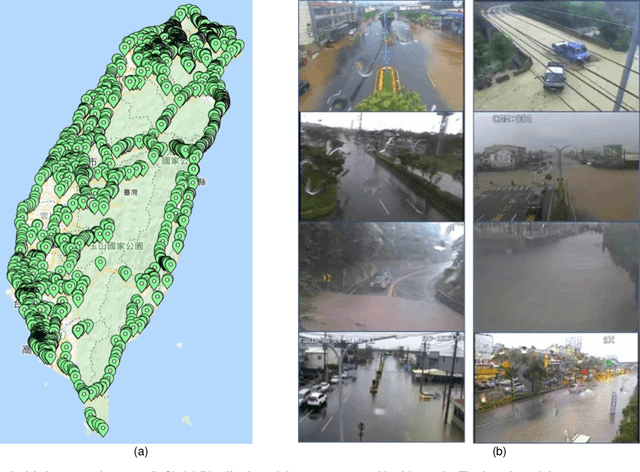
In the monsoon season, sudden flood events occur frequently in urban areas, which hamper the social and economic activities and may threaten the infrastructure and lives. The use of an efficient large-scale waterlogging sensing and information system can provide valuable real-time disaster information to facilitate disaster management and enhance awareness of the general public to alleviate losses during and after flood disasters. Therefore, in this study, a visual sensing approach driven by deep neural networks and information and communication technology was developed to provide an end-to-end mechanism to realize waterlogging sensing and event-location mapping. The use of a deep sensing system in the monsoon season in Taiwan was demonstrated, and waterlogging events were predicted on the island-wide scale. The system could sense approximately 2379 vision sources through an internet of video things framework and transmit the event-location information in 5 min. The proposed approach can sense waterlogging events at a national scale and provide an efficient and highly scalable alternative to conventional waterlogging sensing methods.
A Real-Time Online Learning Framework for Joint 3D Reconstruction and Semantic Segmentation of Indoor Scenes
Aug 11, 2021
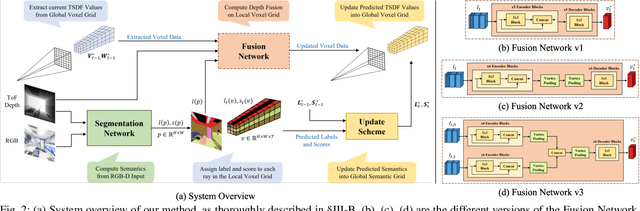

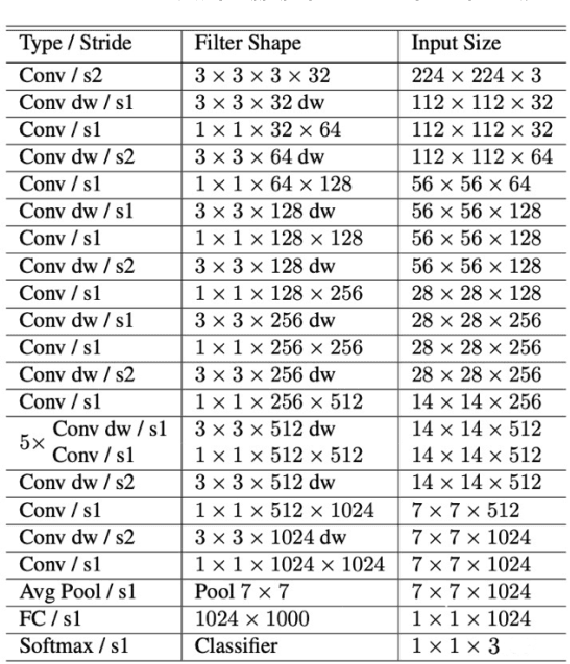
This paper presents a real-time online vision framework to jointly recover an indoor scene's 3D structure and semantic label. Given noisy depth maps, a camera trajectory, and 2D semantic labels at train time, the proposed neural network learns to fuse the depth over frames with suitable semantic labels in the scene space. Our approach exploits the joint volumetric representation of the depth and semantics in the scene feature space to solve this task. For a compelling online fusion of the semantic labels and geometry in real-time, we introduce an efficient vortex pooling block while dropping the routing network in online depth fusion to preserve high-frequency surface details. We show that the context information provided by the semantics of the scene helps the depth fusion network learn noise-resistant features. Not only that, it helps overcome the shortcomings of the current online depth fusion method in dealing with thin object structures, thickening artifacts, and false surfaces. Experimental evaluation on the Replica dataset shows that our approach can perform depth fusion at 37, 10 frames per second with an average reconstruction F-score of 88%, and 91%, respectively, depending on the depth map resolution. Moreover, our model shows an average IoU score of 0.515 on the ScanNet 3D semantic benchmark leaderboard.
TRACE: A Differentiable Approach to Line-level Stroke Recovery for Offline Handwritten Text
May 24, 2021
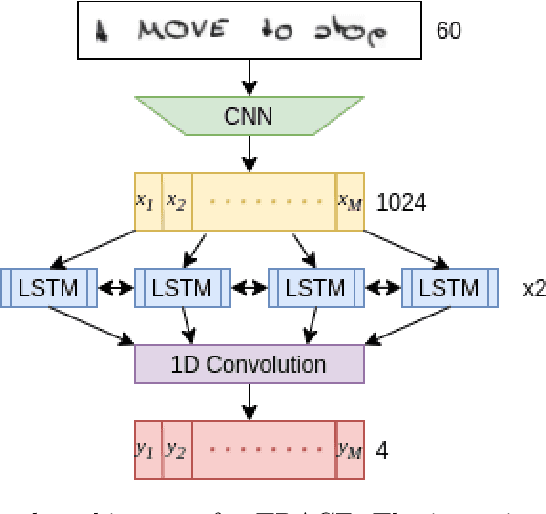
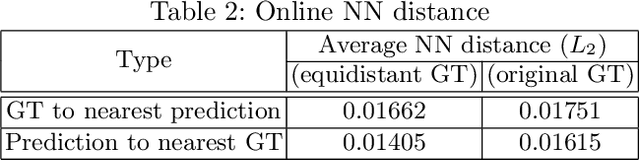
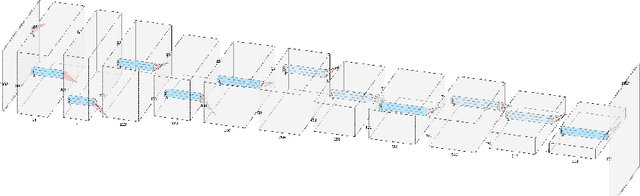
Stroke order and velocity are helpful features in the fields of signature verification, handwriting recognition, and handwriting synthesis. Recovering these features from offline handwritten text is a challenging and well-studied problem. We propose a new model called TRACE (Trajectory Recovery by an Adaptively-trained Convolutional Encoder). TRACE is a differentiable approach that uses a convolutional recurrent neural network (CRNN) to infer temporal stroke information from long lines of offline handwritten text with many characters and dynamic time warping (DTW) to align predictions and ground truth points. TRACE is perhaps the first system to be trained end-to-end on entire lines of text of arbitrary width and does not require the use of dynamic exemplars. Moreover, the system does not require images to undergo any pre-processing, nor do the predictions require any post-processing. Consequently, the recovered trajectory is differentiable and can be used as a loss function for other tasks, including synthesizing offline handwritten text. We demonstrate that temporal stroke information recovered by TRACE from offline data can be used for handwriting synthesis and establish the first benchmarks for a stroke trajectory recovery system trained on the IAM online handwriting dataset.
CURE: Enabling RF Energy Harvesting using Cell-Free Massive MIMO UAVs Assisted by RIS
Jul 22, 2021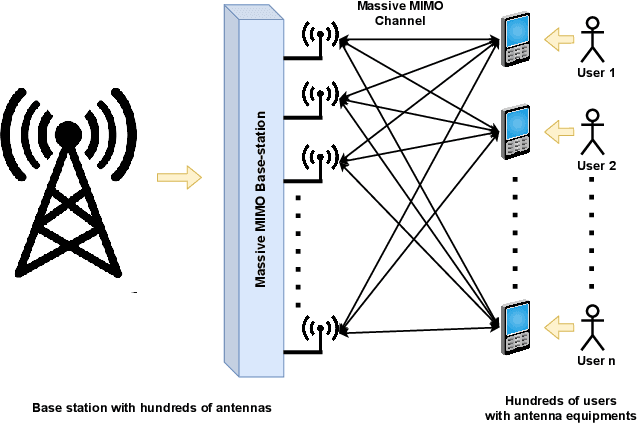
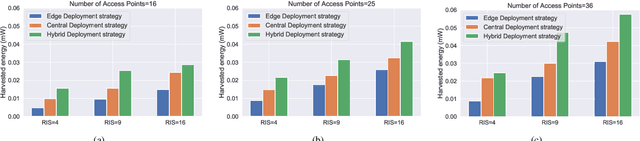
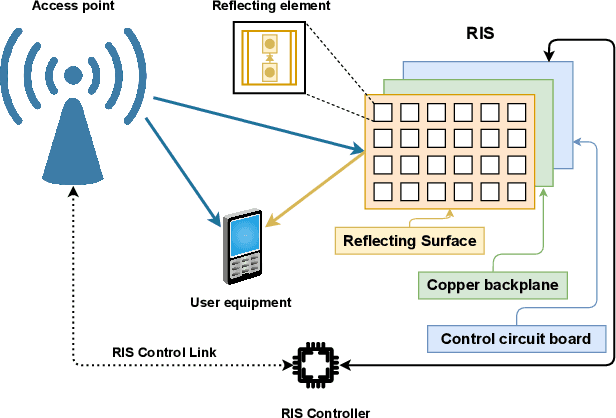
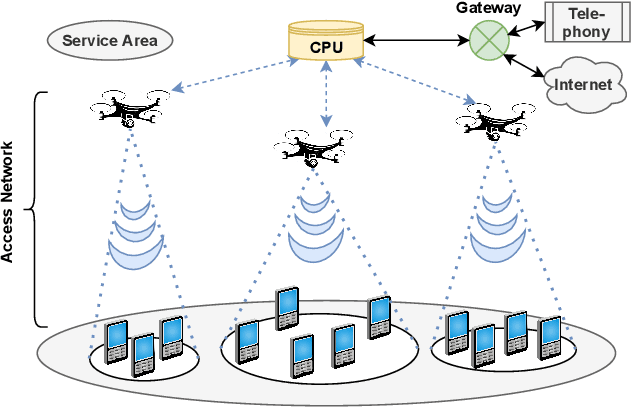
The ever-evolving internet of things (IoT) has led to the growth of numerous wireless sensors, communicating through the internet infrastructure. When designing a network using these sensors, one critical aspect is the longevity and self-sustainability of these devices. For extending the lifetime of these sensors, radio frequency energy harvesting (RFEH) technology has proved to be promising. In this paper, we propose CURE, a novel framework for RFEH that effectively combines the benefits of cell-free massive MIMO (CFmMIMO), unmanned aerial vehicles (UAVs), and reconfigurable intelligent surfaces (RISs) to provide seamless energy harvesting to IoT devices. We consider UAV as an access point (AP) in the CFmMIMO framework. To enhance the signal strength of the RFEH and information transfer, we leverage RISs owing to their passive reflection capability. Based on an extensive simulation, we validate our framework's performance by comparing the max-min fairness (MMF) algorithm for the amount of harvested energy.
Evaluation of In-Person Counseling Strategies To Develop Physical Activity Chatbot for Women
Jul 22, 2021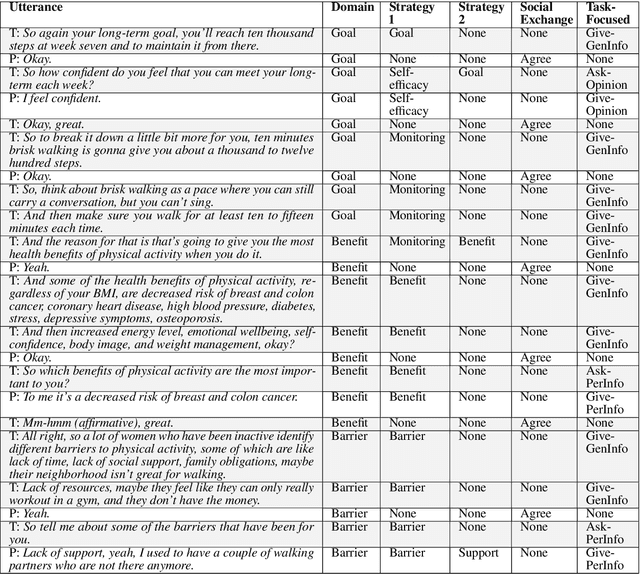
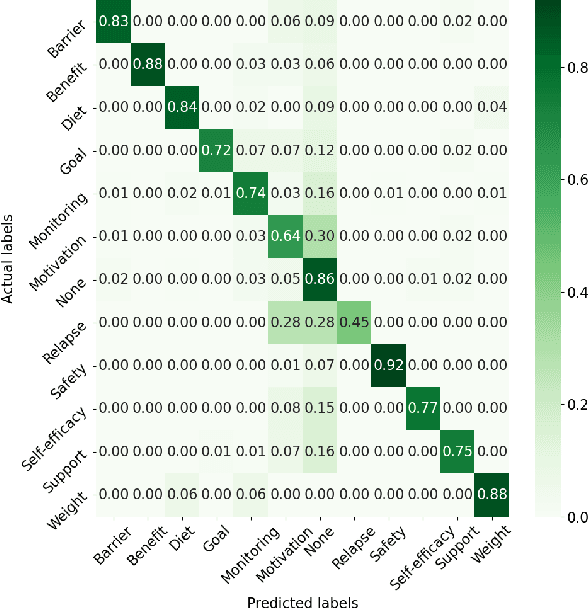

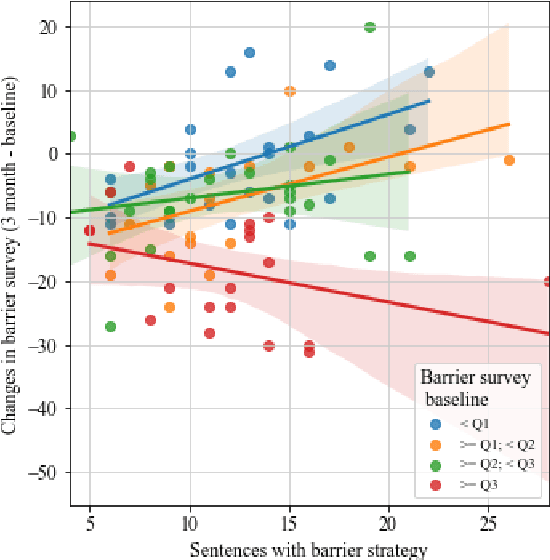
Artificial intelligence chatbots are the vanguard in technology-based intervention to change people's behavior. To develop intervention chatbots, the first step is to understand natural language conversation strategies in human conversation. This work introduces an intervention conversation dataset collected from a real-world physical activity intervention program for women. We designed comprehensive annotation schemes in four dimensions (domain, strategy, social exchange, and task-focused exchange) and annotated a subset of dialogs. We built a strategy classifier with context information to detect strategies from both trainers and participants based on the annotation. To understand how human intervention induces effective behavior changes, we analyzed the relationships between the intervention strategies and the participants' changes in the barrier and social support for physical activity. We also analyzed how participant's baseline weight correlates to the amount of occurrence of the corresponding strategy. This work lays the foundation for developing a personalized physical activity intervention bot. The dataset and code are available at https://github.com/KaihuiLiang/physical-activity-counseling
Energy Efficiency Optimization for Multi-cell Massive MIMO: Centralized and Distributed Power Allocation Algorithms
May 31, 2021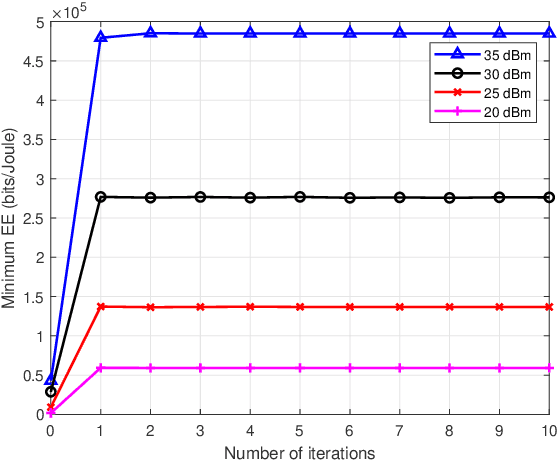
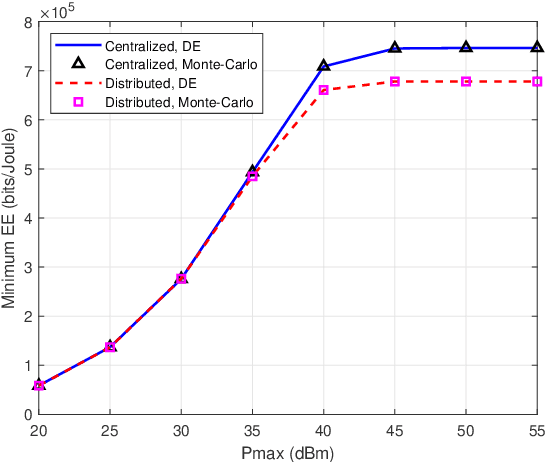
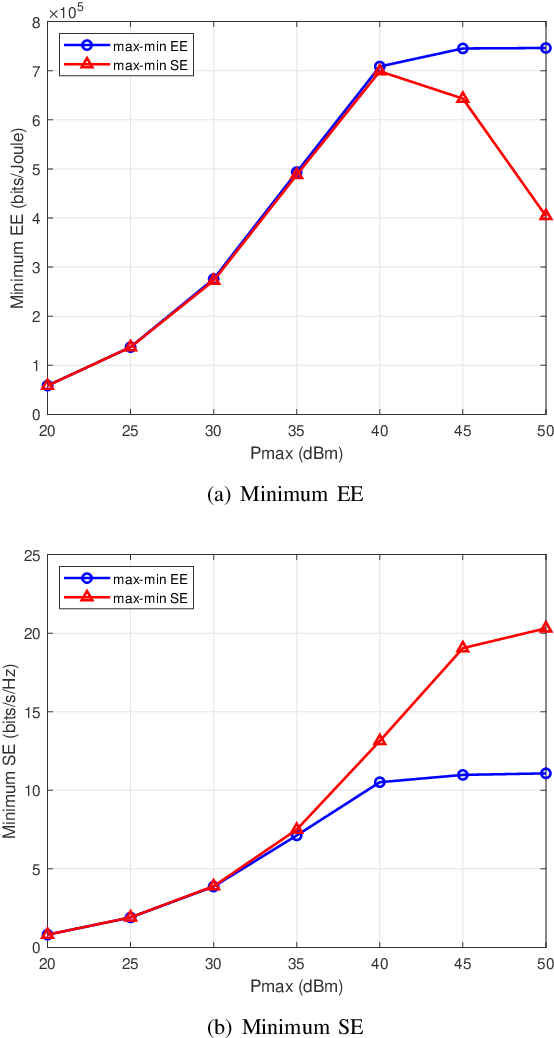
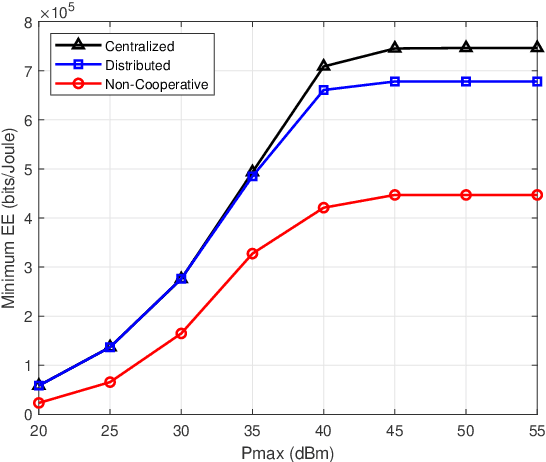
This paper investigates the energy efficiency (EE) optimization in downlink multi-cell massive multiple-input multiple-output (MIMO). In our research, the statistical channel state information (CSI) is exploited to reduce the signaling overhead. To maximize the minimum EE among the neighbouring cells, we design the transmit covariance matrices for each base station (BS). Specifically, optimization schemes for this max-min EE problem are developed, in the centralized and distributed ways, respectively. To obtain the transmit covariance matrices, we first find out the closed-form optimal transmit eigenmatrices for the BS in each cell, and convert the original transmit covariance matrices designing problem into a power allocation one. Then, to lower the computational complexity, we utilize an asymptotic approximation expression for the problem objective. Moreover, for the power allocation design, we adopt the minorization maximization method to address the non-convexity of the ergodic rate, and use Dinkelbach's transform to convert the max-min fractional problem into a series of convex optimization subproblems. To tackle the transformed subproblems, we propose a centralized iterative water-filling scheme. For reducing the backhaul burden, we further develop a distributed algorithm for the power allocation problem, which requires limited inter-cell information sharing. Finally, the performance of the proposed algorithms are demonstrated by extensive numerical results.
Deep Sequence Learning with Auxiliary Information for Traffic Prediction
Jun 13, 2018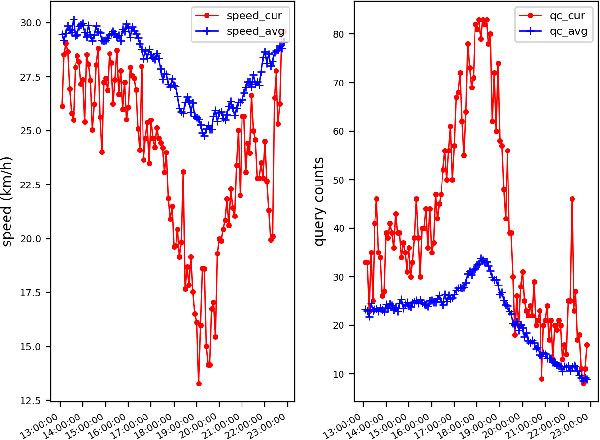

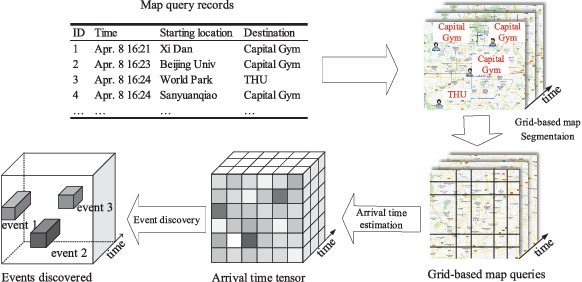
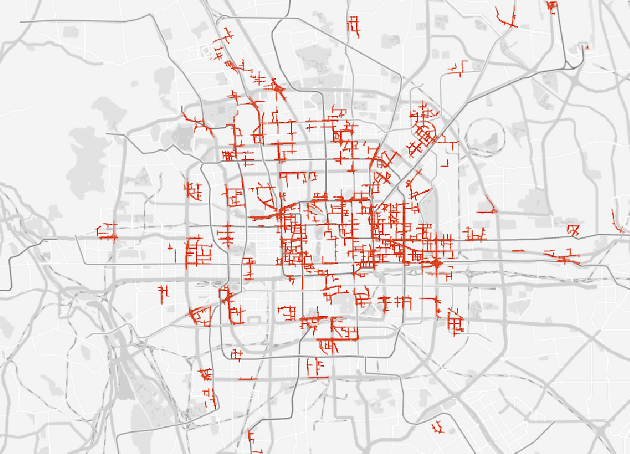
Predicting traffic conditions from online route queries is a challenging task as there are many complicated interactions over the roads and crowds involved. In this paper, we intend to improve traffic prediction by appropriate integration of three kinds of implicit but essential factors encoded in auxiliary information. We do this within an encoder-decoder sequence learning framework that integrates the following data: 1) offline geographical and social attributes. For example, the geographical structure of roads or public social events such as national celebrations; 2) road intersection information. In general, traffic congestion occurs at major junctions; 3) online crowd queries. For example, when many online queries issued for the same destination due to a public performance, the traffic around the destination will potentially become heavier at this location after a while. Qualitative and quantitative experiments on a real-world dataset from Baidu have demonstrated the effectiveness of our framework.
SFE-Net: EEG-based Emotion Recognition with Symmetrical Spatial Feature Extraction
Apr 25, 2021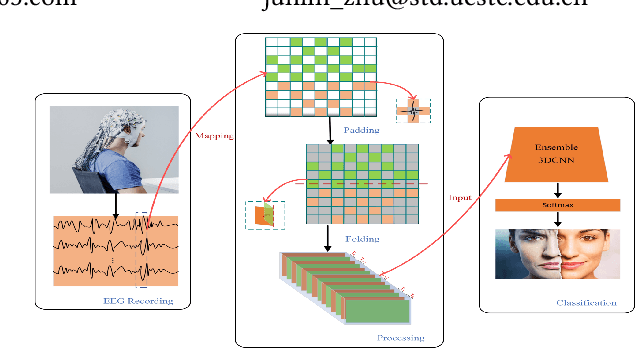

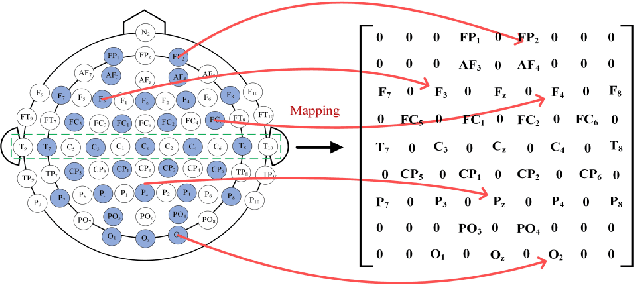
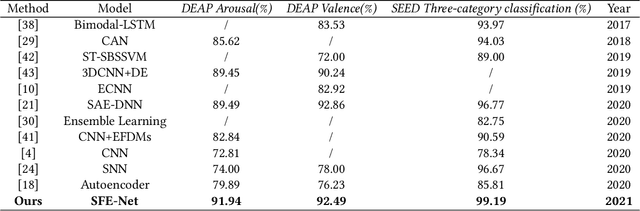
Emotion recognition based on EEG (electroencephalography) has been widely used in human-computer interaction, distance education and health care. However, the conventional methods ignore the adjacent and symmetrical characteristics of EEG signals, which also contain salient information related to emotion. In this paper, we present a spatial folding ensemble network (SFENet) for EEG feature extraction and emotion recognition. Firstly, for the undetected area between EEG electrodes, we employ an improved Bicubic-EEG interpolation algorithm for EEG channel information completion, which allows us to extract a wider range of adjacent space features. Then, motivated by the spatial symmetry mechanism of human brain, we fold the input EEG channel data with five different symmetrical strategies: the left-right folds, the right-left folds, the top-bottom folds, the bottom-top folds, and the entire double-sided brain folding, which enable the proposed network to extract the information of space features of EEG signals more effectively. Finally, 3DCNN based spatial and temporal extraction and multi voting strategy of ensemble Learning are employed to model a new neural network. With this network, the spatial features of different symmetric folding signlas can be extracted simultaneously, which greatly improves the robustness and accuracy of feature recognition. The experimental results on DEAP and SEED data sets show that the proposed algorithm has comparable performance in term of recognition accuracy.