 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Search: A Decision-Based Agent for Knowledge-Based Visual Question Answering
Apr 09, 2026Knowledge-based visual question answering (KB-VQA) requires vision-language models to understand images and use external knowledge, especially for rare entities and long-tail facts. Most existing retrieval-augmented generation (RAG) methods adopt a fixed pipeline that sequentially retrieves information, filters it, and then produces an answer. Such a design makes it difficult to adapt to diverse question types. Moreover, it separates retrieval from reasoning, making it hard for the model to decide when to search, how to refine queries, or when to stop. As a result, the retrieved evidence is often poorly aligned with the question. To address these limitations, we reformulate KB-VQA as a search-agent problem and model the solving process as a multi-step decision-making procedure. At each step, the agent selects one of four actions-Answer, Image Retrieval, Text Retrieval, and Caption-based on its current information state. We further design an automated pipeline to collect multi-step trajectories that record the agent's reasoning process, tool usage, and intermediate decisions. These trajectories are then used as supervision for fine-tuning. Experiments on InfoSeek and E-VQA demonstrate that our method achieves state-of-the-art performance, consistently outperforming prior baselines and confirming the effectiveness of our framework.
Stabilizing Unsupervised Self-Evolution of MLLMs via Continuous Softened Retracing reSampling
Apr 04, 2026In the unsupervised self-evolution of Multimodal Large Language Models, the quality of feedback signals during post-training is pivotal for stable and effective learning. However, existing self-evolution methods predominantly rely on majority voting to select the most frequent output as the pseudo-golden answer, which may stem from the model's intrinsic biases rather than guaranteeing the objective correctness of the reasoning paths. To counteract the degradation, we propose \textbf{C}ontinuous \textbf{S}oftened \textbf{R}etracing re\textbf{S}ampling (\textbf{CSRS}) in MLLM self-evolution. Specifically, we introduce a Retracing Re-inference Mechanism (\textbf{RRM}) that the model re-inferences from anchor points to expand the exploration of long-tail reasoning paths. Simultaneously, we propose Softened Frequency Reward (\textbf{SFR}), which replaces binary rewards with continuous signals, calibrating reward based on the answers' frequency across sampled reasoning sets. Furthermore, incorporated with Visual Semantic Perturbation (\textbf{VSP}), CSRS ensures the model prioritizes mathematical logic over visual superficiality. Experimental results demonstrate that CSRS significantly enhances the reasoning performance of Qwen2.5-VL-7B on benchmarks such as MathVision. We achieve state-of-the-art (SOTA) results in unsupervised self-evolution on geometric tasks. Our code is avaible at https://github.com/yyy195/CSRS.
3D Face Arbitrary Style Transfer
Mar 14, 2023



Style transfer of 3D faces has gained more and more attention. However, previous methods mainly use images of artistic faces for style transfer while ignoring arbitrary style images such as abstract paintings. To solve this problem, we propose a novel method, namely Face-guided Dual Style Transfer (FDST). To begin with, FDST employs a 3D decoupling module to separate facial geometry and texture. Then we propose a style fusion strategy for facial geometry. Subsequently, we design an optimization-based DDSG mechanism for textures that can guide the style transfer by two style images. Besides the normal style image input, DDSG can utilize the original face input as another style input as the face prior. By this means, high-quality face arbitrary style transfer results can be obtained. Furthermore, FDST can be applied in many downstream tasks, including region-controllable style transfer, high-fidelity face texture reconstruction, large-pose face reconstruction, and artistic face reconstruction. Comprehensive quantitative and qualitative results show that our method can achieve comparable performance. All source codes and pre-trained weights will be released to the public.
SFE-Net: EEG-based Emotion Recognition with Symmetrical Spatial Feature Extraction
Apr 25, 2021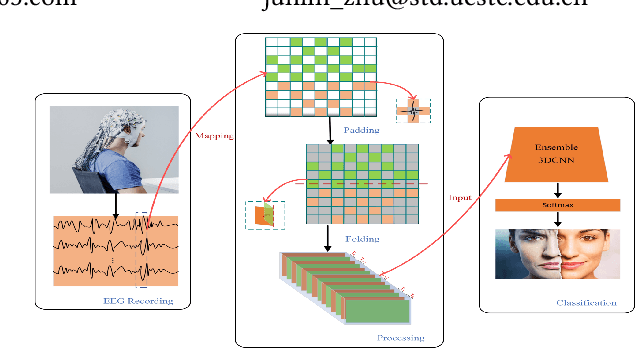

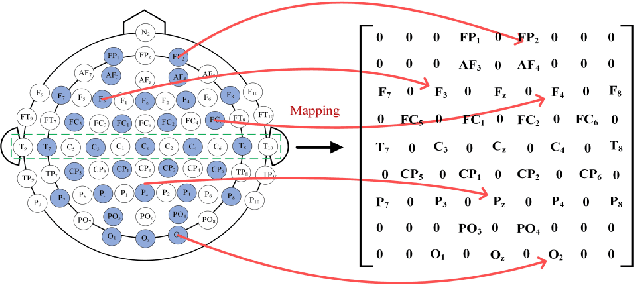
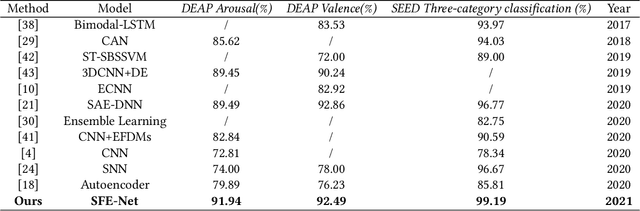
Emotion recognition based on EEG (electroencephalography) has been widely used in human-computer interaction, distance education and health care. However, the conventional methods ignore the adjacent and symmetrical characteristics of EEG signals, which also contain salient information related to emotion. In this paper, we present a spatial folding ensemble network (SFENet) for EEG feature extraction and emotion recognition. Firstly, for the undetected area between EEG electrodes, we employ an improved Bicubic-EEG interpolation algorithm for EEG channel information completion, which allows us to extract a wider range of adjacent space features. Then, motivated by the spatial symmetry mechanism of human brain, we fold the input EEG channel data with five different symmetrical strategies: the left-right folds, the right-left folds, the top-bottom folds, the bottom-top folds, and the entire double-sided brain folding, which enable the proposed network to extract the information of space features of EEG signals more effectively. Finally, 3DCNN based spatial and temporal extraction and multi voting strategy of ensemble Learning are employed to model a new neural network. With this network, the spatial features of different symmetric folding signlas can be extracted simultaneously, which greatly improves the robustness and accuracy of feature recognition. The experimental results on DEAP and SEED data sets show that the proposed algorithm has comparable performance in term of recognition accuracy.