 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SVSNet: An End-to-end Speaker Voice Similarity Assessment Model
Jul 20, 2021
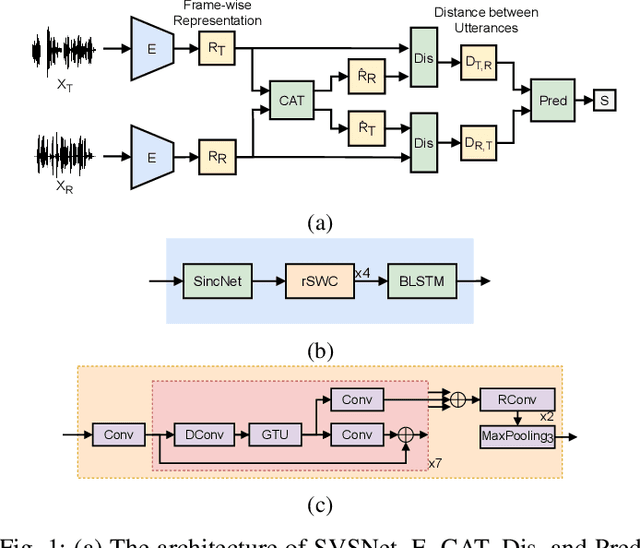
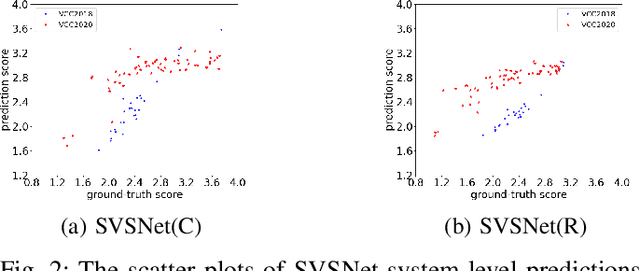
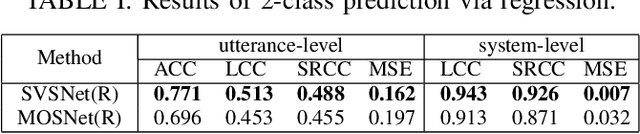
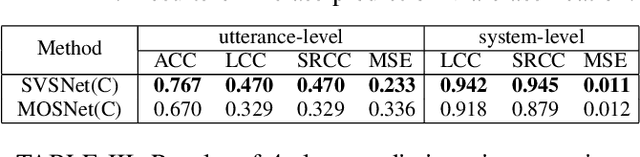
Neural evaluation metrics derived for numerous speech generation tasks have recently attracted great attention. In this paper, we propose SVSNet, the first end-to-end neural network model to assess the speaker voice similarity between natural speech and synthesized speech. Unlike most neural evaluation metrics that use hand-crafted features, SVSNet directly takes the raw waveform as input to more completely utilize speech information for prediction. SVSNet consists of encoder, co-attention, distance calculation, and prediction modules and is trained in an end-to-end manner. The experimental results on the Voice Conversion Challenge 2018 and 2020 (VCC2018 and VCC2020) datasets show that SVSNet notably outperforms well-known baseline systems in the assessment of speaker similarity at the utterance and system levels.
Blind Modulo Analog-to-Digital Conversion
Aug 19, 2021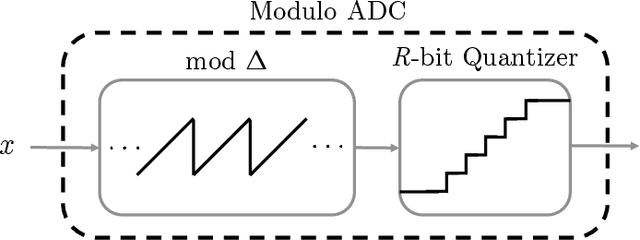
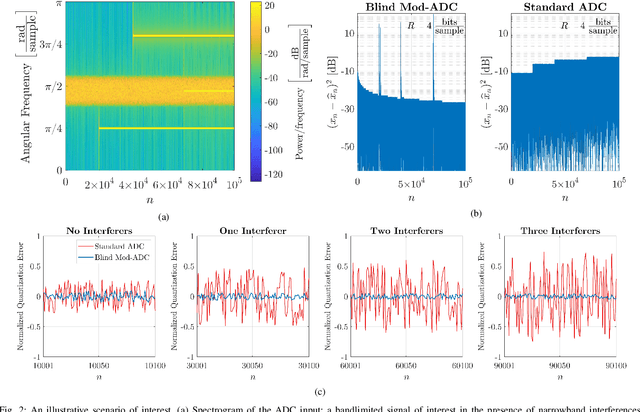
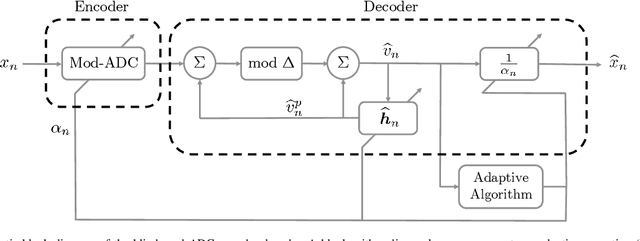
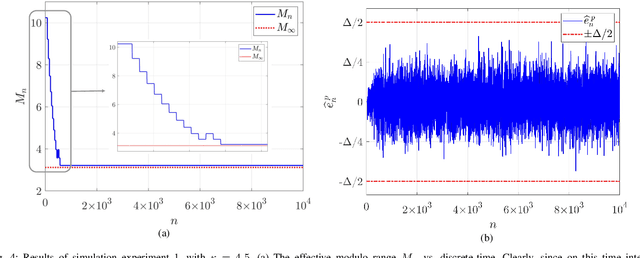
In a growing number of applications, there is a need to digitize signals whose spectral characteristics are challenging for traditional Analog-to-Digital Converters (ADCs). Examples, among others, include systems where the ADC must acquire at once a very wide but sparsely and dynamically occupied bandwidth supporting diverse services, as well as systems where the signal of interest is subject to strong narrowband co-channel interference. In such scenarios, the resolution requirements can be prohibitively high. As an alternative, the recently proposed modulo-ADC architecture can in principle require dramatically fewer bits in the conversation to obtain the target fidelity, but requires that information about the spectrum be known and explicitly taken into account by the analog and digital processing in the converter, which is frequently impractical. To address this limitation, we develop a blind version of the architecture that requires no such knowledge in the converter, without sacrificing performance. In particular, it features an automatic modulo-level adjustment and a fully adaptive modulo unwrapping mechanism, allowing it to asymptotically match the characteristics of the unknown input signal. In addition to detailed analysis, simulations demonstrate the attractive performance characteristics in representative settings.
Unifying Nonlocal Blocks for Neural Networks
Aug 13, 2021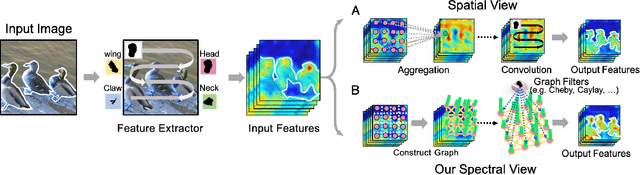

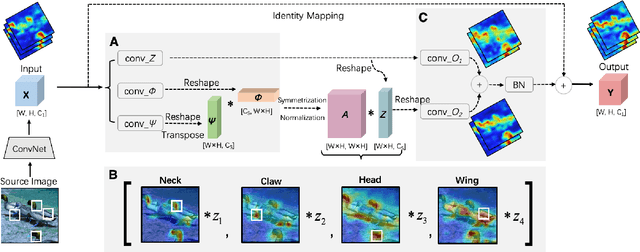
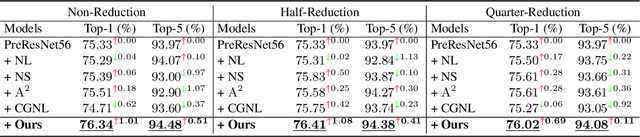
The nonlocal-based blocks are designed for capturing long-range spatial-temporal dependencies in computer vision tasks. Although having shown excellent performance, they still lack the mechanism to encode the rich, structured information among elements in an image or video. In this paper, to theoretically analyze the property of these nonlocal-based blocks, we provide a new perspective to interpret them, where we view them as a set of graph filters generated on a fully-connected graph. Specifically, when choosing the Chebyshev graph filter, a unified formulation can be derived for explaining and analyzing the existing nonlocal-based blocks (e.g., nonlocal block, nonlocal stage, double attention block). Furthermore, by concerning the property of spectral, we propose an efficient and robust spectral nonlocal block, which can be more robust and flexible to catch long-range dependencies when inserted into deep neural networks than the existing nonlocal blocks. Experimental results demonstrate the clear-cut improvements and practical applicabilities of our method on image classification, action recognition, semantic segmentation, and person re-identification tasks.
Curiosity-based Robot Navigation under Uncertainty in Crowded Environments
Jun 03, 2021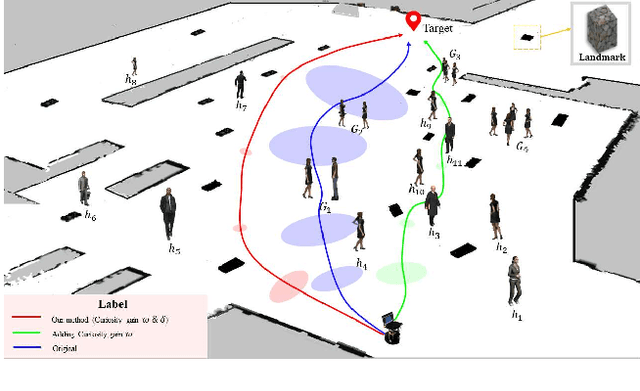
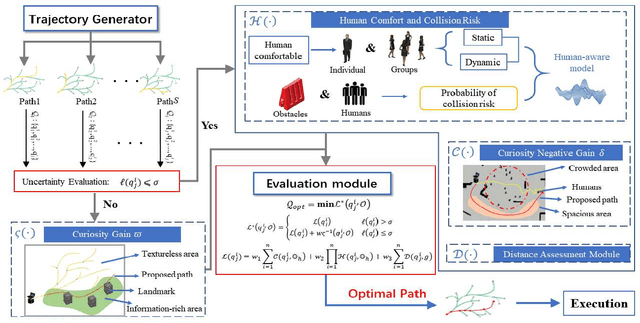
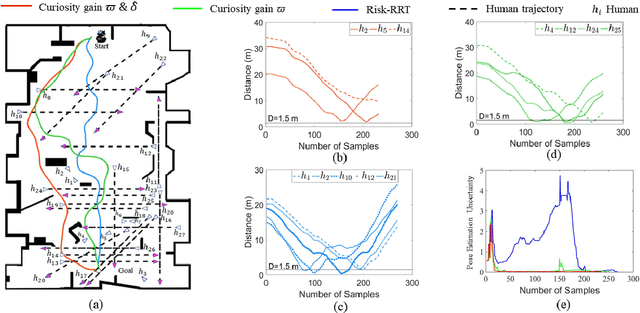

Mobile robots have become more and more popular in our daily life. In large-scale and crowded environments, how to navigate safely with localization precision is a critical problem. To solve this problem, we proposed a curiosity-based framework that can find an effective path with the consideration of human comfort, localization uncertainty, crowds, and the cost-to-go to the target. Three parts are involved in the proposed framework: the distance assessment module, the curiosity gain of the information-rich area, and the curiosity negative gain of crowded areas. The curiosity gain of the information-rich area was proposed to provoke the robot to approach localization referenced landmarks. To guarantee human comfort while coexisting with robots, we propose curiosity gain of the spacious area to bypass the crowd and maintain an appropriate distance between robots and humans. The evaluation is conducted in an unstructured environment. The results show that our method can find a feasible path, which can consider the localization uncertainty while simultaneously avoiding the crowded area.
PolyDNN: Polynomial Representation of NN for Communication-less SMPC Inference
Apr 02, 2021
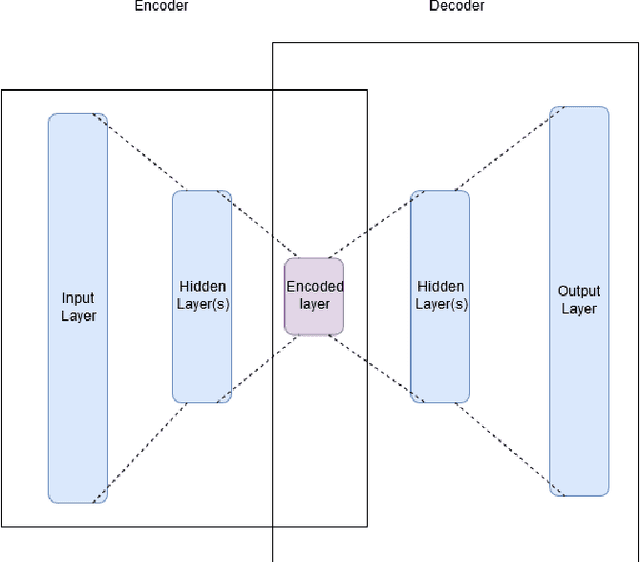
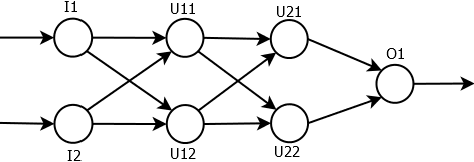
The structure and weights of Deep Neural Networks (DNN) typically encode and contain very valuable information about the dataset that was used to train the network. One way to protect this information when DNN is published is to perform an interference of the network using secure multi-party computations (MPC). In this paper, we suggest a translation of deep neural networks to polynomials, which are easier to calculate efficiently with MPC techniques. We show a way to translate complete networks into a single polynomial and how to calculate the polynomial with an efficient and information-secure MPC algorithm. The calculation is done without intermediate communication between the participating parties, which is beneficial in several cases, as explained in the paper.
Large-vocabulary Audio-visual Speech Recognition in Noisy Environments
Sep 10, 2021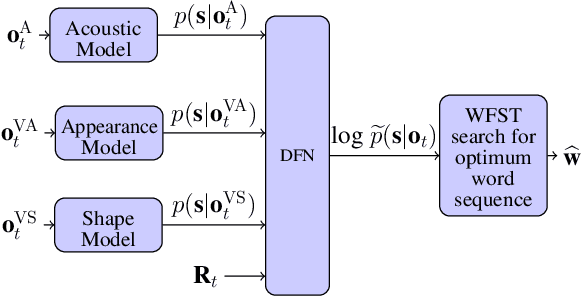
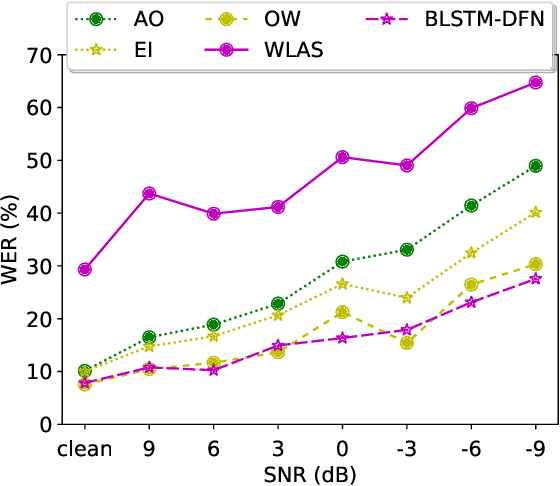

Audio-visual speech recognition (AVSR) can effectively and significantly improve the recognition rates of small-vocabulary systems, compared to their audio-only counterparts. For large-vocabulary systems, however, there are still many difficulties, such as unsatisfactory video recognition accuracies, that make it hard to improve over audio-only baselines. In this paper, we specifically consider such scenarios, focusing on the large-vocabulary task of the LRS2 database, where audio-only performance is far superior to video-only accuracies, making this an interesting and challenging setup for multi-modal integration. To address the inherent difficulties, we propose a new fusion strategy: a recurrent integration network is trained to fuse the state posteriors of multiple single-modality models, guided by a set of model-based and signal-based stream reliability measures. During decoding, this network is used for stream integration within a hybrid recognizer, where it can thus cope with the time-variant reliability and information content of its multiple feature inputs. We compare the results with end-to-end AVSR systems as well as with competitive hybrid baseline models, finding that the new fusion strategy shows superior results, on average even outperforming oracle dynamic stream weighting, which has so far marked the -- realistically unachievable -- upper bound for standard stream weighting. Even though the pure lipreading performance is low, audio-visual integration is helpful under all -- clean, noisy, and reverberant -- conditions. On average, the new system achieves a relative word error rate reduction of 42.18\% compared to the audio-only model, pointing at a high effectiveness of the proposed integration approach.
U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition
Jun 10, 2021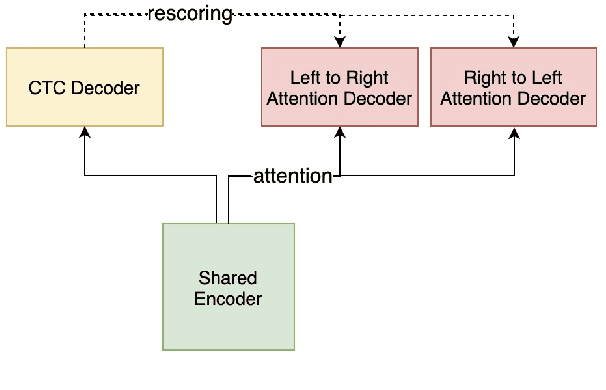
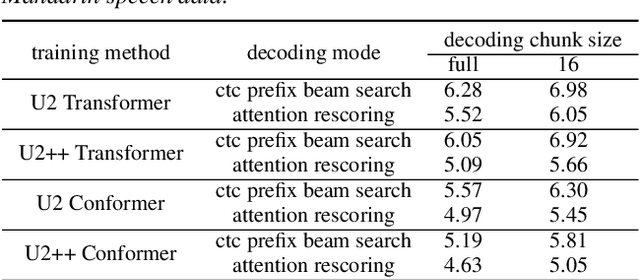
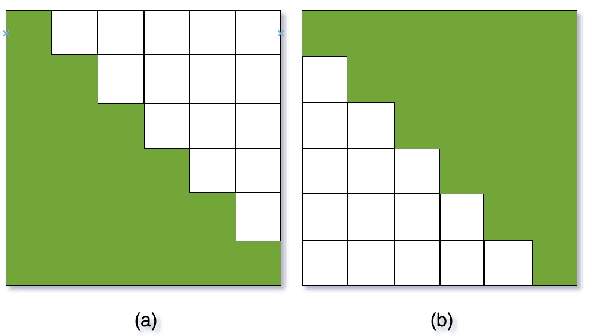
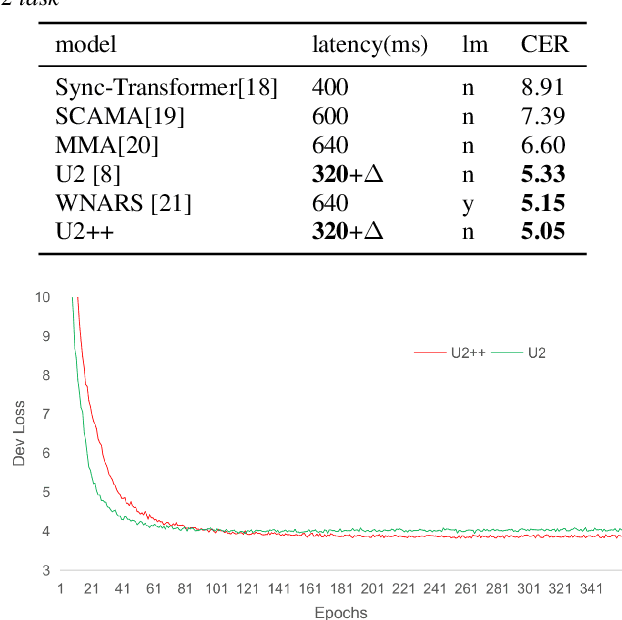
The unified streaming and non-streaming two-pass (U2) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy, real-time factor (RTF), and latency. In this paper, we present U2++, an enhanced version of U2 to further improve the accuracy. The core idea of U2++ is to use the forward and the backward information of the labeling sequences at the same time at training to learn richer information, and combine the forward and backward prediction at decoding to give more accurate recognition results. We also proposed a new data augmentation method called SpecSub to help the U2++ model to be more accurate and robust. Our experiments show that, compared with U2, U2++ shows faster convergence at training, better robustness to the decoding method, as well as consistent 5\% - 8\% word error rate reduction gain over U2. On the experiment of AISHELL-1, we achieve a 4.63\% character error rate (CER) with a non-streaming setup and 5.05\% with a streaming setup with 320ms latency by U2++. To the best of our knowledge, 5.05\% is the best-published streaming result on the AISHELL-1 test set.
BanditMF: Multi-Armed Bandit Based Matrix Factorization Recommender System
Jun 23, 2021
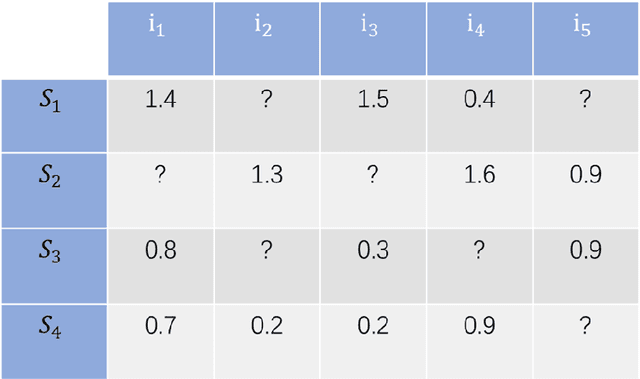
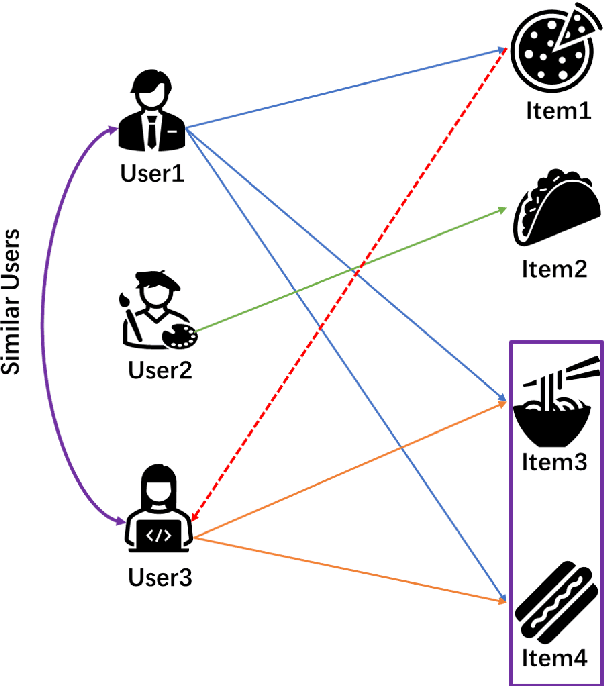
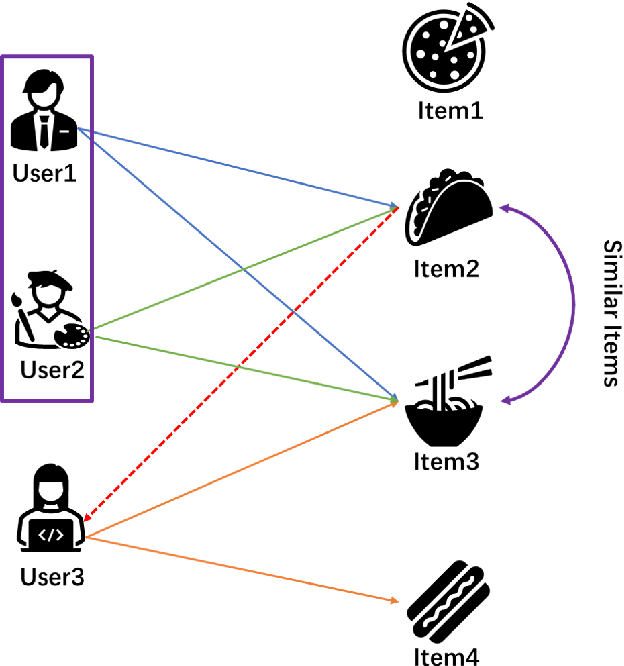
Multi-armed bandits (MAB) provide a principled online learning approach to attain the balance between exploration and exploitation. Due to the superior performance and low feedback learning without the learning to act in multiple situations, Multi-armed Bandits drawing widespread attention in applications ranging such as recommender systems. Likewise, within the recommender system, collaborative filtering (CF) is arguably the earliest and most influential method in the recommender system. Crucially, new users and an ever-changing pool of recommended items are the challenges that recommender systems need to address. For collaborative filtering, the classical method is training the model offline, then perform the online testing, but this approach can no longer handle the dynamic changes in user preferences which is the so-called cold start. So how to effectively recommend items to users in the absence of effective information? To address the aforementioned problems, a multi-armed bandit based collaborative filtering recommender system has been proposed, named BanditMF. BanditMF is designed to address two challenges in the multi-armed bandits algorithm and collaborative filtering: (1) how to solve the cold start problem for collaborative filtering under the condition of scarcity of valid information, (2) how to solve the sub-optimal problem of bandit algorithms in strong social relations domains caused by independently estimating unknown parameters associated with each user and ignoring correlations between users.
Challenges and Solutions for Utilizing Earth Observations in the "Big Data" era
Aug 19, 2021The ever-growing need of data preservation and their systematic analysis contributing to sustainable development of the society spurred in the past decade,numerous Big Data projects and initiatives are focusing on the Earth Observation (EO). The number of Big Data EO applications has grown extremely worldwide almost simultaneously with other scientific and technological areas of the human knowledge due to the revolutionary technological progress in the space and information technology sciences. The substantial contribution to this development are the space programs of the renowned space agencies, such as NASA, ESA,Roskosmos, JAXA, DLR, INPE, ISRO, CNES etc. A snap-shot of the current Big Data sets from available satellite missions covering the Bulgarian territory is also presented. This short overview of the geoscience Big Data collection with a focus on EO will emphasize to the multiple Vs of EO in order to provide a snapshot on the current state-of-the-art in EO data preservation and manipulation. Main modern approaches for compressing, clustering and modelling EO in the geoinformation science for Big Data analysis, interpretation and visualization for a variety of applications are outlined. Special attention is paid to the contemporary EO data modelling and visualization systems.
Assessing the Causal Impact of COVID-19 Related Policies on Outbreak Dynamics: A Case Study in the US
May 29, 2021

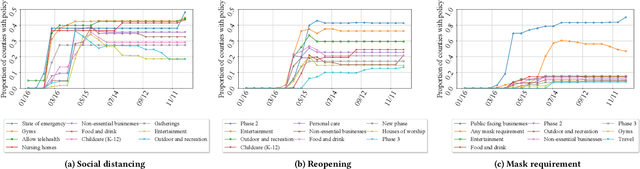
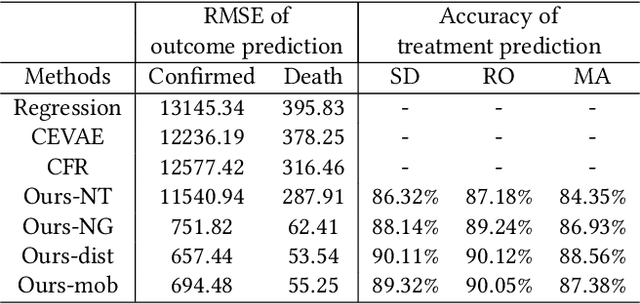
To mitigate the spread of COVID-19 pandemic, decision-makers and public authorities have announced various non-pharmaceutical policies. Analyzing the causal impact of these policies in reducing the spread of COVID-19 is important for future policy-making. The main challenge here is the existence of unobserved confounders (e.g., vigilance of residents). Besides, as the confounders may be time-varying during COVID-19 (e.g., vigilance of residents changes in the course of the pandemic), it is even more difficult to capture them. In this paper, we study the problem of assessing the causal effects of different COVID-19 related policies on the outbreak dynamics in different counties at any given time period. To this end, we integrate data about different COVID-19 related policies (treatment) and outbreak dynamics (outcome) for different United States counties over time and analyze them with respect to variables that can infer the confounders, including the covariates of different counties, their relational information and historical information. Based on these data, we develop a neural network based causal effect estimation framework which leverages above information in observational data and learns the representations of time-varying (unobserved) confounders. In this way, it enables us to quantify the causal impact of policies at different granularities, ranging from a category of policies with a certain goal to a specific policy type in this category. Besides, experimental results also indicate the effectiveness of our proposed framework in capturing the confounders for quantifying the causal impact of different policies. More specifically, compared with several baseline methods, our framework captures the outbreak dynamics more accurately, and our assessment of policies is more consistent with existing epidemiological studies of COVID-19.