 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On risk-based active learning for structural health monitoring
May 12, 2021

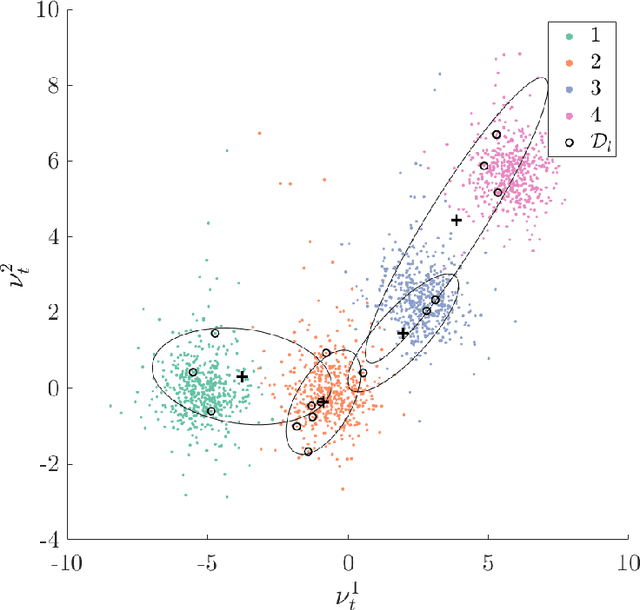
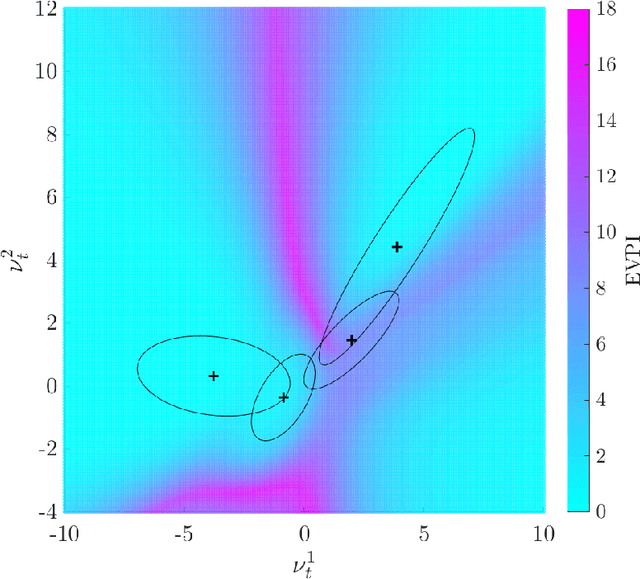
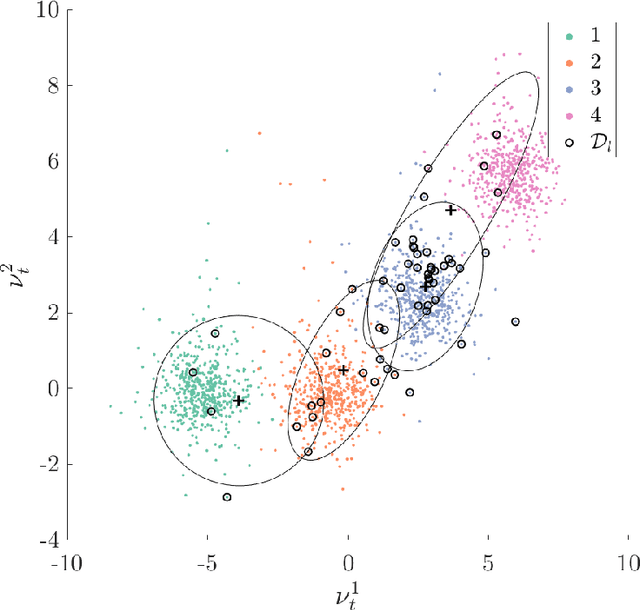
A primary motivation for the development and implementation of structural health monitoring systems, is the prospect of gaining the ability to make informed decisions regarding the operation and maintenance of structures and infrastructure. Unfortunately, descriptive labels for measured data corresponding to health-state information for the structure of interest are seldom available prior to the implementation of a monitoring system. This issue limits the applicability of the traditional supervised and unsupervised approaches to machine learning in the development of statistical classifiers for decision-supporting SHM systems. The current paper presents a risk-based formulation of active learning, in which the querying of class-label information is guided by the expected value of said information for each incipient data point. When applied to structural health monitoring, the querying of class labels can be mapped onto the inspection of a structure of interest in order to determine its health state. In the current paper, the risk-based active learning process is explained and visualised via a representative numerical example and subsequently applied to the Z24 Bridge benchmark. The results of the case studies indicate that a decision-maker's performance can be improved via the risk-based active learning of a statistical classifier, such that the decision process itself is taken into account.
Pix2Prof: fast extraction of sequential information from galaxy imagery via deep learning
Oct 01, 2020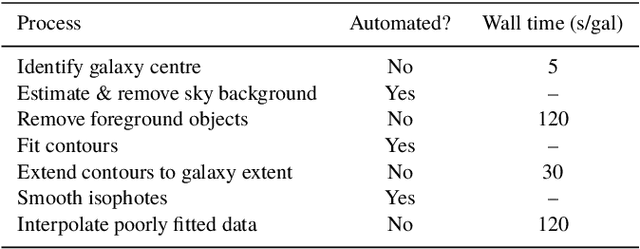
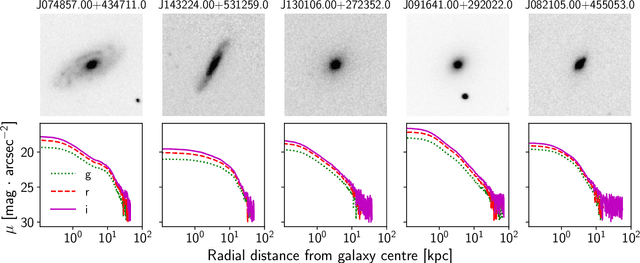
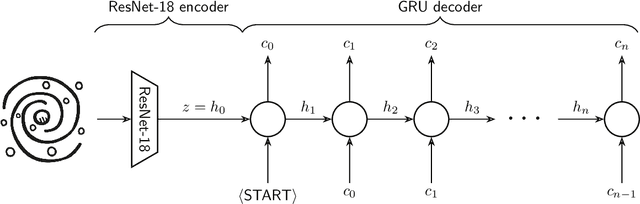
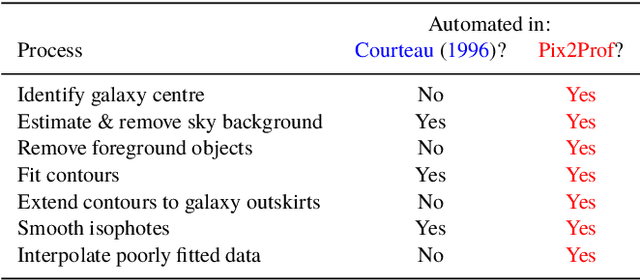
We present "Pix2Prof", a deep learning model that eliminates manual steps in the measurement of galaxy surface brightness (SB) profiles. We argue that a galaxy "profile" of any sort is conceptually similar to an image caption. This idea allows us to leverage image captioning methods from the field of natural language processing, and so we design Pix2Prof as a float sequence "captioning" model suitable for SB profile inferral. We demonstrate the technique by approximating the galaxy SB fitting method described by Courteau (1996), an algorithm with several manual steps. We use g, r, and i-band images from the Sloan Digital Sky Survey (SDSS) Data Release 10 (DR10) to train Pix2Prof on 5367 image--SB profile pairs. We test Pix2Prof on 300 SDSS DR10 galaxy image--SB profile pairs in each of the g, r, and i bands to calibrate the mean SB deviation between interactive manual measurements and automated extractions, and demonstrate the effectiveness of Pix2Prof in mirroring the manual method. Pix2Prof processes $\sim1$ image per second on an Intel Xeon E5-2650 v3 and $\sim2$ images per second on a NVIDIA TESLA V100, improving on the speed of the manual interactive method by more than two orders of magnitude. Crucially, Pix2Prof requires no manual interaction, and since galaxy profile estimation is an embarrassingly parallel problem, we can further increase the throughput by running many Pix2Prof instances simultaneously. In perspective, Pix2Prof would take under an hour to infer profiles for $10^5$ galaxies on a single NVIDIA DGX-2 system. A single human expert would take approximately two years to complete the same task. Automated methodology such as this will accelerate the analysis of the next generation of large area sky surveys expected to yield hundreds of millions of targets. In such instances, all manual approaches -- even those involving a large number of experts -- would be impractical.
Not All Words are Equal: Video-specific Information Loss for Video Captioning
Jan 01, 2019
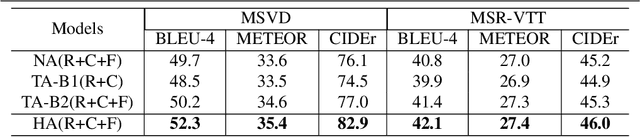
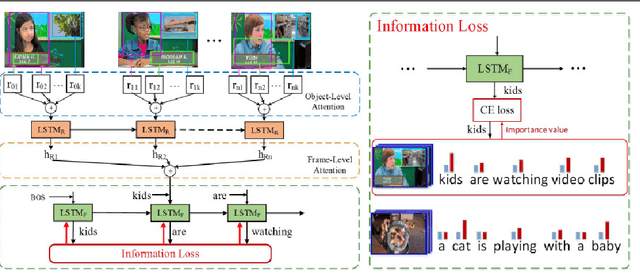
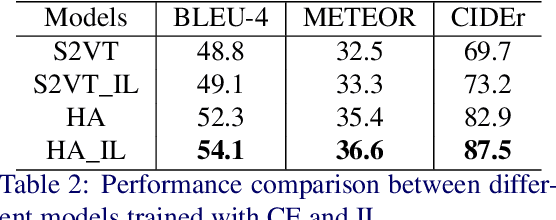
An ideal description for a given video should fix its gaze on salient and representative content, which is capable of distinguishing this video from others. However, the distribution of different words is unbalanced in video captioning datasets, where distinctive words for describing video-specific salient objects are far less than common words such as 'a' 'the' and 'person'. The dataset bias often results in recognition error or detail deficiency of salient but unusual objects. To address this issue, we propose a novel learning strategy called Information Loss, which focuses on the relationship between the video-specific visual content and corresponding representative words. Moreover, a framework with hierarchical visual representations and an optimized hierarchical attention mechanism is established to capture the most salient spatial-temporal visual information, which fully exploits the potential strength of the proposed learning strategy. Extensive experiments demonstrate that the ingenious guidance strategy together with the optimized architecture outperforms state-of-the-art video captioning methods on MSVD with CIDEr score 87.5, and achieves superior CIDEr score 47.7 on MSR-VTT. We also show that our Information Loss is generic which improves various models by significant margins.
Learning Conditional Knowledge Distillation for Degraded-Reference Image Quality Assessment
Aug 18, 2021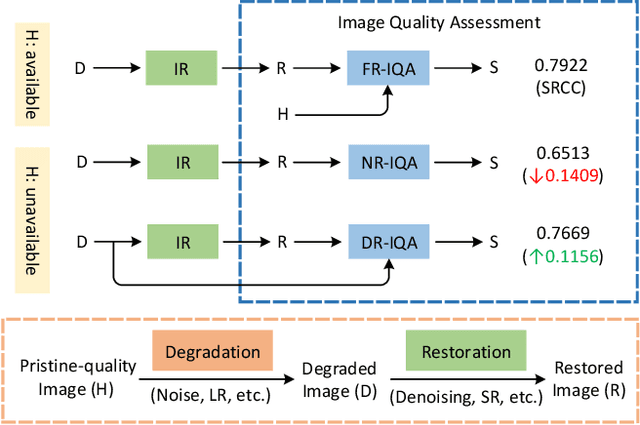
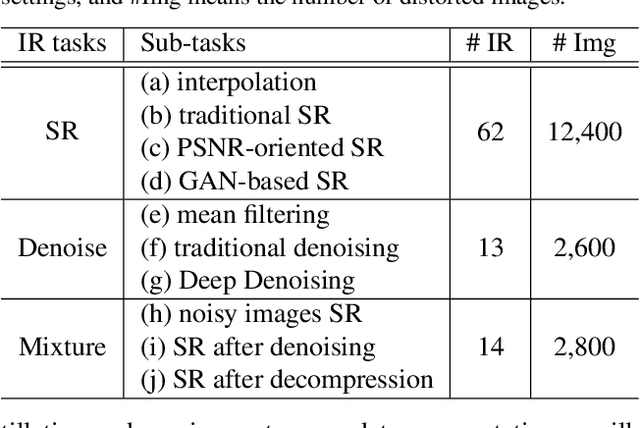
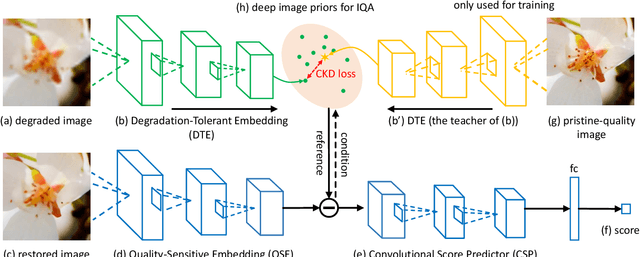
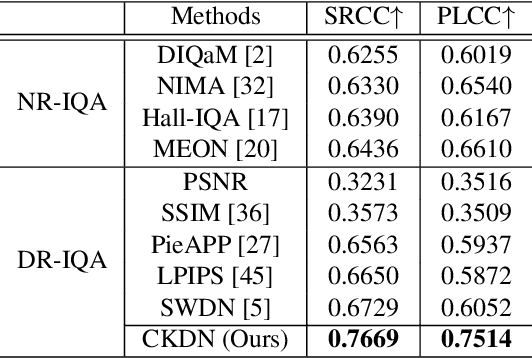
An important scenario for image quality assessment (IQA) is to evaluate image restoration (IR) algorithms. The state-of-the-art approaches adopt a full-reference paradigm that compares restored images with their corresponding pristine-quality images. However, pristine-quality images are usually unavailable in blind image restoration tasks and real-world scenarios. In this paper, we propose a practical solution named degraded-reference IQA (DR-IQA), which exploits the inputs of IR models, degraded images, as references. Specifically, we extract reference information from degraded images by distilling knowledge from pristine-quality images. The distillation is achieved through learning a reference space, where various degraded images are encouraged to share the same feature statistics with pristine-quality images. And the reference space is optimized to capture deep image priors that are useful for quality assessment. Note that pristine-quality images are only used during training. Our work provides a powerful and differentiable metric for blind IRs, especially for GAN-based methods. Extensive experiments show that our results can even be close to the performance of full-reference settings.
Ctrl-P: Temporal Control of Prosodic Variation for Speech Synthesis
Jun 15, 2021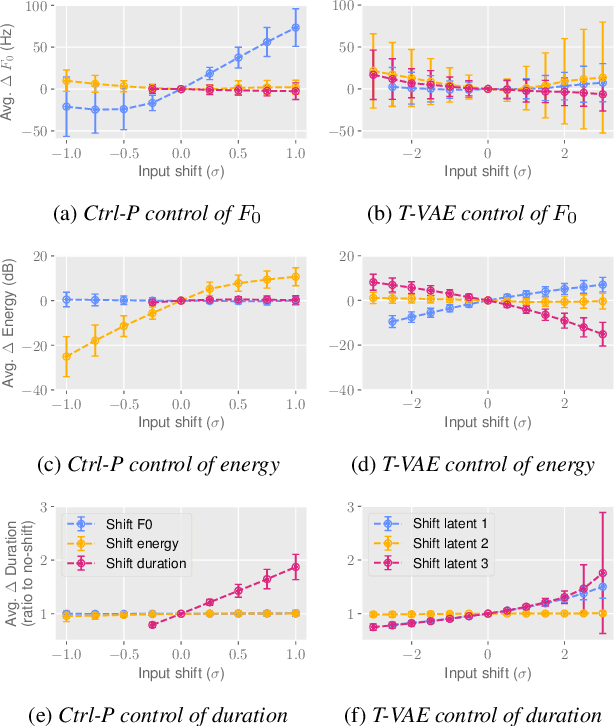
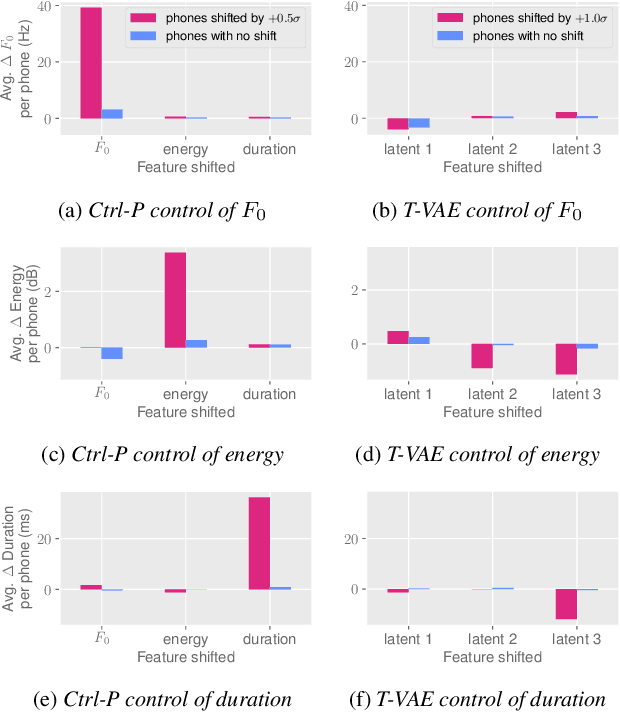
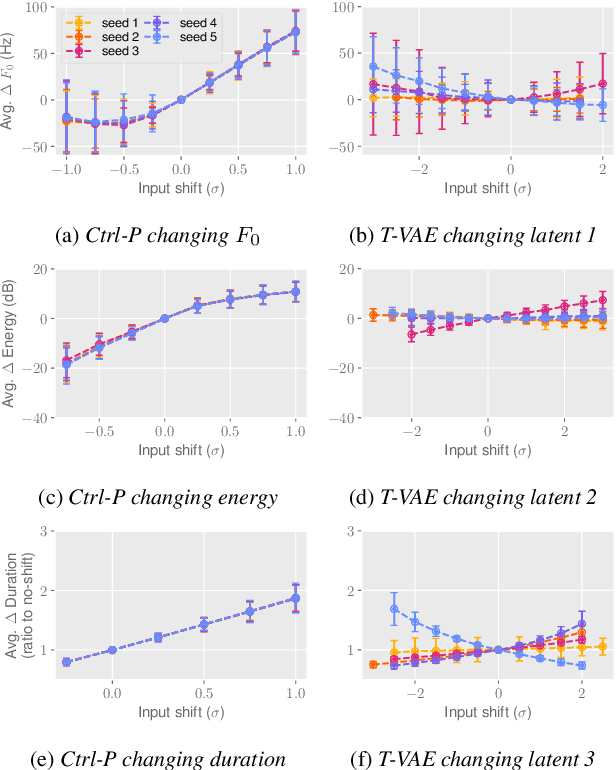
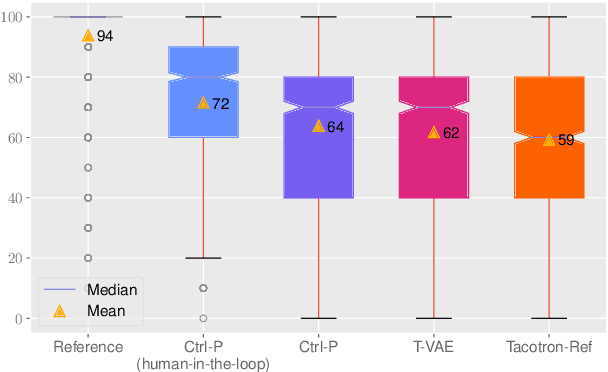
Text does not fully specify the spoken form, so text-to-speech models must be able to learn from speech data that vary in ways not explained by the corresponding text. One way to reduce the amount of unexplained variation in training data is to provide acoustic information as an additional learning signal. When generating speech, modifying this acoustic information enables multiple distinct renditions of a text to be produced. Since much of the unexplained variation is in the prosody, we propose a model that generates speech explicitly conditioned on the three primary acoustic correlates of prosody: $F_{0}$, energy and duration. The model is flexible about how the values of these features are specified: they can be externally provided, or predicted from text, or predicted then subsequently modified. Compared to a model that employs a variational auto-encoder to learn unsupervised latent features, our model provides more interpretable, temporally-precise, and disentangled control. When automatically predicting the acoustic features from text, it generates speech that is more natural than that from a Tacotron 2 model with reference encoder. Subsequent human-in-the-loop modification of the predicted acoustic features can significantly further increase naturalness.
Self-Supervised Learning with Kernel Dependence Maximization
Jun 15, 2021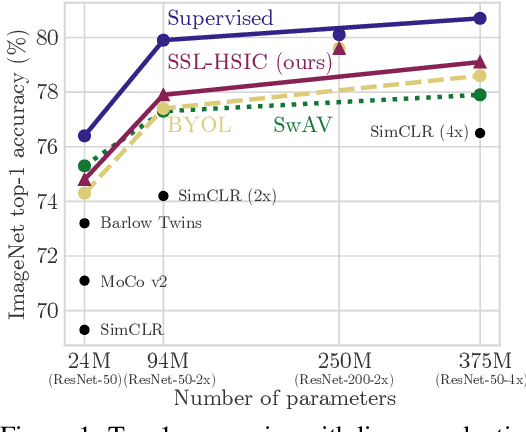
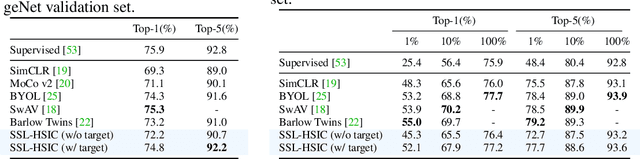
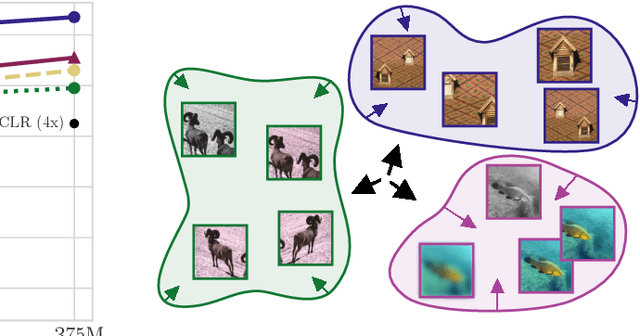
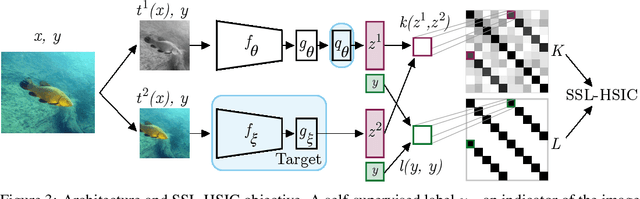
We approach self-supervised learning of image representations from a statistical dependence perspective, proposing Self-Supervised Learning with the Hilbert-Schmidt Independence Criterion (SSL-HSIC). SSL-HSIC maximizes dependence between representations of transformed versions of an image and the image identity, while minimizing the kernelized variance of those features. This self-supervised learning framework yields a new understanding of InfoNCE, a variational lower bound on the mutual information (MI) between different transformations. While the MI itself is known to have pathologies which can result in meaningless representations being learned, its bound is much better behaved: we show that it implicitly approximates SSL-HSIC (with a slightly different regularizer). Our approach also gives us insight into BYOL, since SSL-HSIC similarly learns local neighborhoods of samples. SSL-HSIC allows us to directly optimize statistical dependence in time linear in the batch size, without restrictive data assumptions or indirect mutual information estimators. Trained with or without a target network, SSL-HSIC matches the current state-of-the-art for standard linear evaluation on ImageNet, semi-supervised learning and transfer to other classification and vision tasks such as semantic segmentation, depth estimation and object recognition.
Survival Prediction of Heart Failure Patients using Stacked Ensemble Machine Learning Algorithm
Aug 30, 2021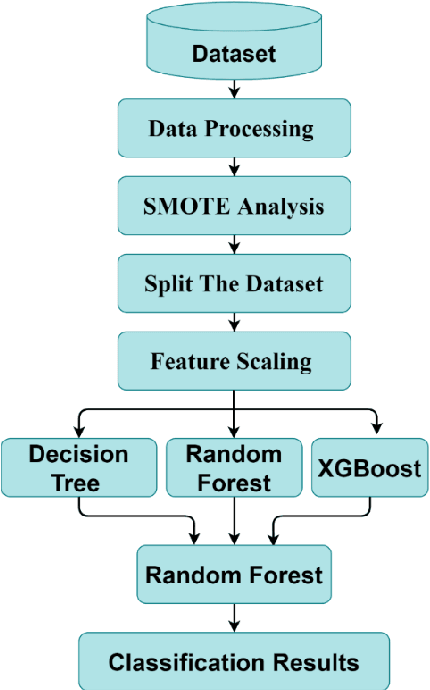
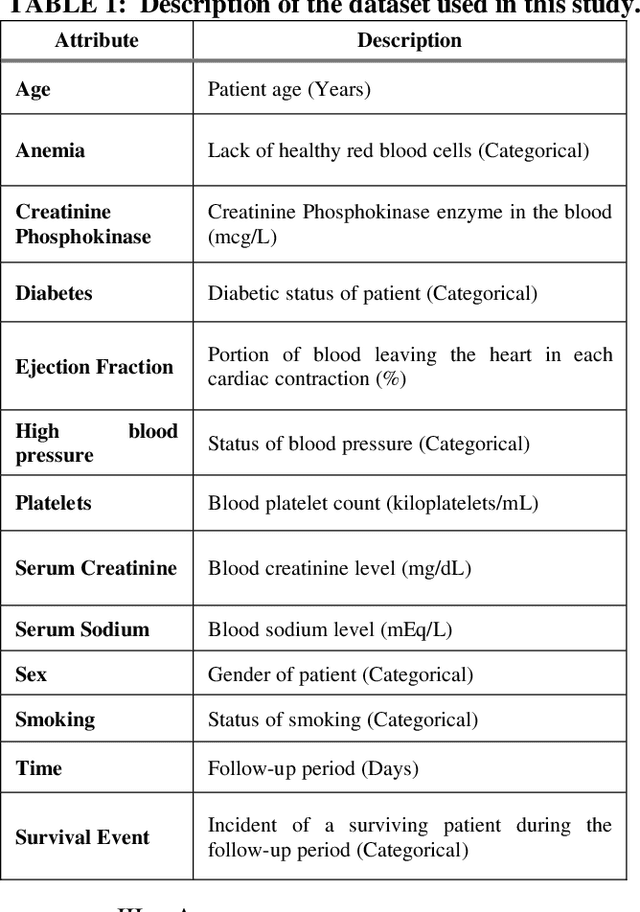
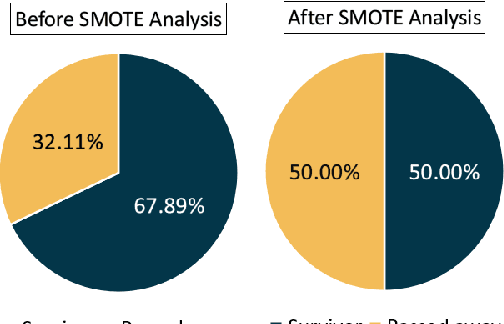
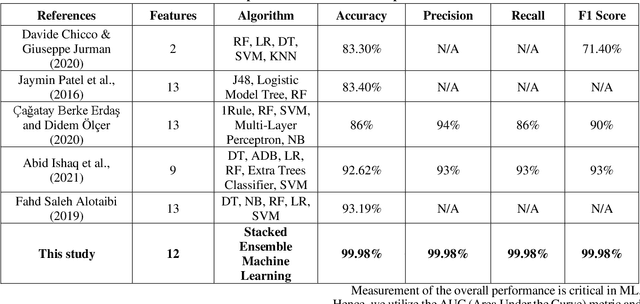
Cardiovascular disease, especially heart failure is one of the major health hazard issues of our time and is a leading cause of death worldwide. Advancement in data mining techniques using machine learning (ML) models is paving promising prediction approaches. Data mining is the process of converting massive volumes of raw data created by the healthcare institutions into meaningful information that can aid in making predictions and crucial decisions. Collecting various follow-up data from patients who have had heart failures, analyzing those data, and utilizing several ML models to predict the survival possibility of cardiovascular patients is the key aim of this study. Due to the imbalance of the classes in the dataset, Synthetic Minority Oversampling Technique (SMOTE) has been implemented. Two unsupervised models (K-Means and Fuzzy C-Means clustering) and three supervised classifiers (Random Forest, XGBoost and Decision Tree) have been used in our study. After thorough investigation, our results demonstrate a superior performance of the supervised ML algorithms over unsupervised models. Moreover, we designed and propose a supervised stacked ensemble learning model that can achieve an accuracy, precision, recall and F1 score of 99.98%. Our study shows that only certain attributes collected from the patients are imperative to successfully predict the surviving possibility post heart failure, using supervised ML algorithms.
Automatic Online Multi-Source Domain Adaptation
Sep 05, 2021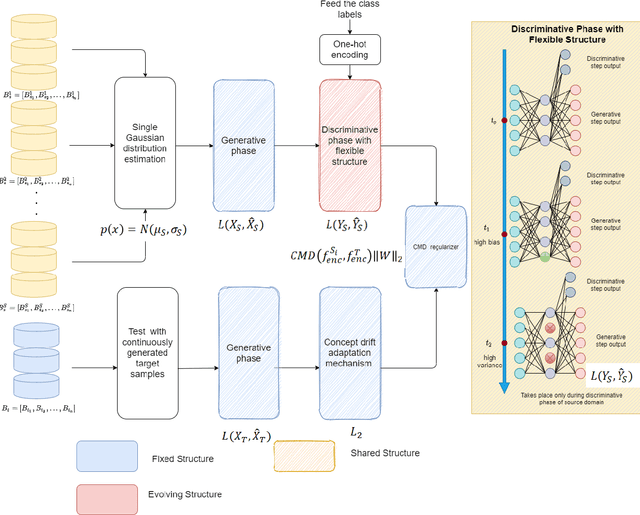
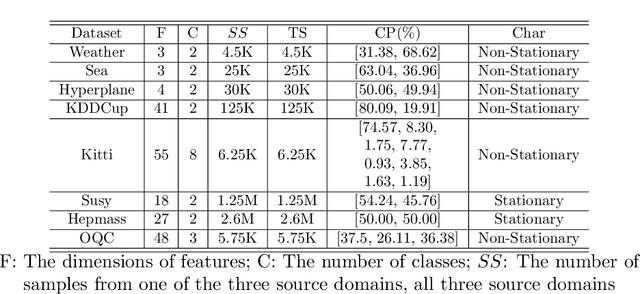
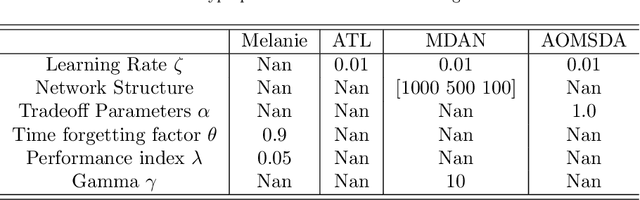
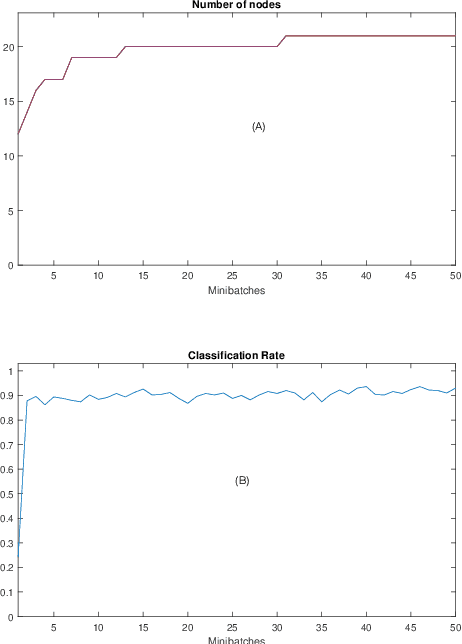
Knowledge transfer across several streaming processes remain challenging problem not only because of different distributions of each stream but also because of rapidly changing and never-ending environments of data streams. Albeit growing research achievements in this area, most of existing works are developed for a single source domain which limits its resilience to exploit multi-source domains being beneficial to recover from concept drifts quickly and to avoid the negative transfer problem. An online domain adaptation technique under multisource streaming processes, namely automatic online multi-source domain adaptation (AOMSDA), is proposed in this paper. The online domain adaptation strategy of AOMSDA is formulated under a coupled generative and discriminative approach of denoising autoencoder (DAE) where the central moment discrepancy (CMD)-based regularizer is integrated to handle the existence of multi-source domains thereby taking advantage of complementary information sources. The asynchronous concept drifts taking place at different time periods are addressed by a self-organizing structure and a node re-weighting strategy. Our numerical study demonstrates that AOMSDA is capable of outperforming its counterparts in 5 of 8 study cases while the ablation study depicts the advantage of each learning component. In addition, AOMSDA is general for any number of source streams. The source code of AOMSDA is shared publicly in https://github.com/Renchunzi-Xie/AOMSDA.git.
InfoBot: Transfer and Exploration via the Information Bottleneck
Feb 07, 2019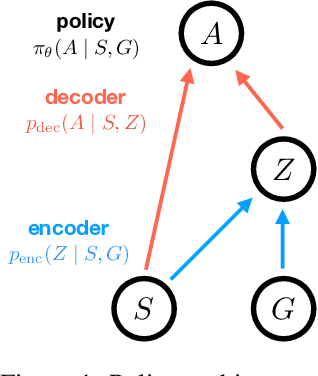



A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.
REFINE: Random RangE FInder for Network Embedding
Aug 24, 2021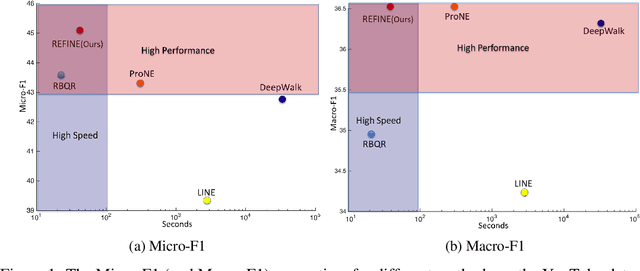
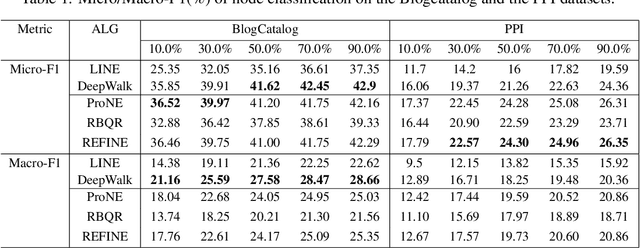
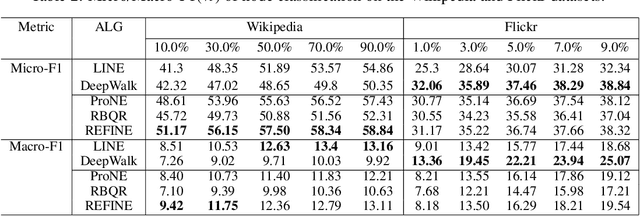
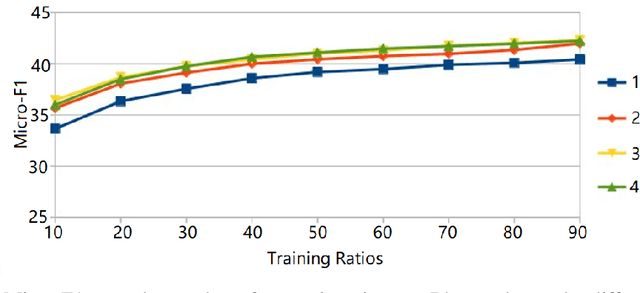
Network embedding approaches have recently attracted considerable interest as they learn low-dimensional vector representations of nodes. Embeddings based on the matrix factorization are effective but they are usually computationally expensive due to the eigen-decomposition step. In this paper, we propose a Random RangE FInder based Network Embedding (REFINE) algorithm, which can perform embedding on one million of nodes (YouTube) within 30 seconds in a single thread. REFINE is 10x faster than ProNE, which is 10-400x faster than other methods such as LINE, DeepWalk, Node2Vec, GraRep, and Hope. Firstly, we formulate our network embedding approach as a skip-gram model, but with an orthogonal constraint, and we reformulate it into the matrix factorization problem. Instead of using randomized tSVD (truncated SVD) as other methods, we employ the Randomized Blocked QR decomposition to obtain the node representation fast. Moreover, we design a simple but efficient spectral filter for network enhancement to obtain higher-order information for node representation. Experimental results prove that REFINE is very efficient on datasets of different sizes (from thousand to million of nodes/edges) for node classification, while enjoying a good performance.