 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning via interpolating structures
Mar 23, 2026Despite recent advances in population-based structural health monitoring (PBSHM), knowledge transfer between highly-disparate structures (i.e., heterogeneous populations) remains a challenge. The current work proposes that heterogeneous transfer may be accomplished via intermediate structures that bridge the gap in information between the structures of interest. A key aspect of the technique is the idea that by varying parameters such as material properties and geometry, one structure can be continuously morphed into another. The approach is demonstrated via a case study involving the parameterisation of (and transfer between) simulated heterogeneous bridge designs (Case 1). Transfer between simplified physical representations of a 'bridge' and 'aeroplane' is then demonstrated in Case 2, via a chain of finite-element models. The facetious question 'When is a bridge not an aeroplane?' has been previously asked in the context of predicting positive transfer based on structural similarity. While the obvious answer to this question is 'Always,' the results presented in the current paper show that, in some cases, positive transfer can indeed be achieved between highly-disparate systems.
Anomaly Detection in Offshore Wind Turbine Structures using Hierarchical Bayesian Modelling
Feb 29, 2024
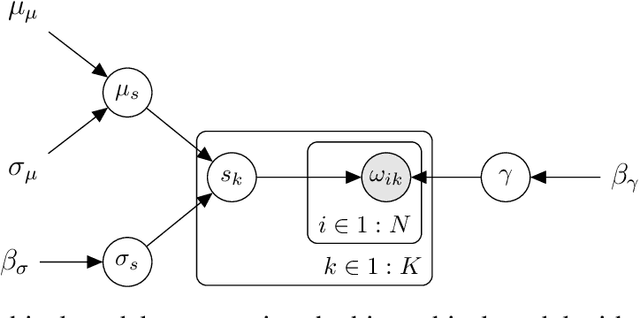
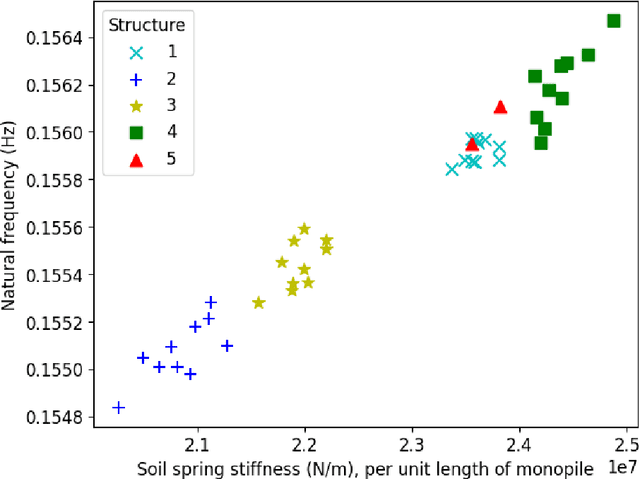
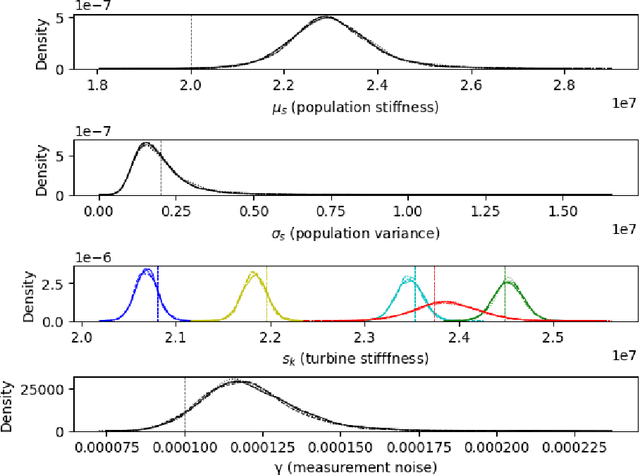
Population-based structural health monitoring (PBSHM), aims to share information between members of a population. An offshore wind (OW) farm could be considered as a population of nominally-identical wind-turbine structures. However, benign variations exist among members, such as geometry, sea-bed conditions and temperature differences. These factors could influence structural properties and therefore the dynamic response, making it more difficult to detect structural problems via traditional SHM techniques. This paper explores the use of a hierarchical Bayesian model to infer expected soil stiffness distributions at both population and local levels, as a basis to perform anomaly detection, in the form of scour, for new and existing turbines. To do this, observations of natural frequency will be generated as though they are from a small population of wind turbines. Differences between individual observations will be introduced by postulating distributions over the soil stiffness and measurement noise, as well as reducing soil depth (to represent scour), in the case of anomaly detection.
On the hierarchical Bayesian modelling of frequency response functions
Jul 12, 2023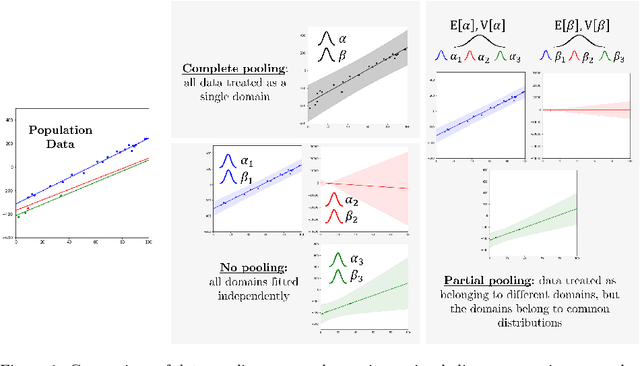

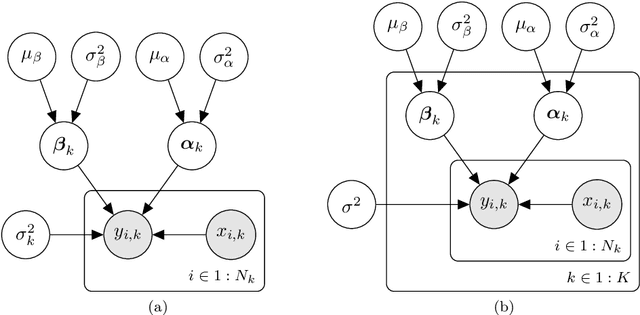

Population-based structural health monitoring (PBSHM) aims to share valuable information among members of a population, such as normal- and damage-condition data, to improve inferences regarding the health states of the members. Even when the population is comprised of nominally-identical structures, benign variations among the members will exist as a result of slight differences in material properties, geometry, boundary conditions, or environmental effects (e.g., temperature changes). These discrepancies can affect modal properties and present as changes in the characteristics of the resonance peaks of the frequency response function (FRF). Many SHM strategies depend on monitoring the dynamic properties of structures, so benign variations can be challenging for the practical implementation of these systems. Another common challenge with vibration-based SHM is data loss, which may result from transmission issues, sensor failure, a sample-rate mismatch between sensors, and other causes. Missing data in the time domain will result in decreased resolution in the frequency domain, which can impair dynamic characterisation. The hierarchical Bayesian approach provides a useful modelling structure for PBSHM, because statistical distributions at the population and individual (or domain) level are learnt simultaneously to bolster statistical strength among the parameters. As a result, variance is reduced among the parameter estimates, particularly when data are limited. In this paper, combined probabilistic FRF models are developed for a small population of nominally-identical helicopter blades under varying temperature conditions, using a hierarchical Bayesian structure. These models address critical challenges in SHM, by accommodating benign variations that present as differences in the underlying dynamics, while also considering (and utilising), the similarities among the blades.
Better Together: Using Multi-task Learning to Improve Feature Selection within Structural Datasets
Mar 08, 2023



There have been recent efforts to move to population-based structural health monitoring (PBSHM) systems. One area of PBSHM which has been recognised for potential development is the use of multi-task learning (MTL); algorithms which differ from traditional independent learning algorithms. Presented here is the use of the MTL, ''Joint Feature Selection with LASSO'', to provide automatic feature selection for a structural dataset. The classification task is to differentiate between the port and starboard side of a tailplane, for samples from two aircraft of the same model. The independent learner produced perfect F1 scores but had poor engineering insight; whereas the MTL results were interpretable, highlighting structural differences as opposed to differences in experimental set-up.
Knowledge Transfer in Engineering Fleets: Hierarchical Bayesian Modelling for Multi-Task Learning
Apr 26, 2022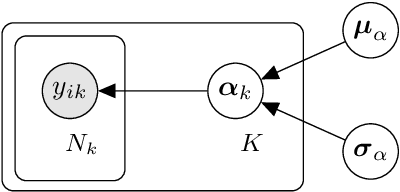

We propose a population-level analysis to address issues of data sparsity when building predictive models of engineering infrastructure. By sharing information between similar assets, hierarchical Bayesian modelling is used to improve the survival analysis of a truck fleet (hazard curves) and power prediction in a wind farm (power curves). In each example, a set of correlated functions are learnt over the asset fleet, in a combined inference, to learn a population model. Parameter estimation is improved when sub-fleets of assets are allowed to share correlated information at different levels in the hierarchy. In turn, groups with incomplete data automatically borrow statistical strength from those that are data-rich. The correlations can be inspected to inform which assets share information for which effect (i.e. parameter).
Bayesian Modelling of Multivalued Power Curves from an Operational Wind Farm
Nov 30, 2021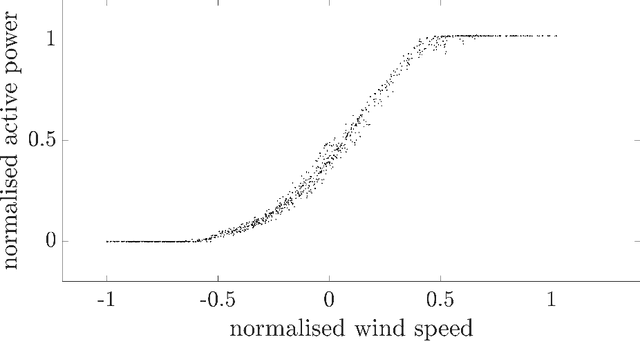

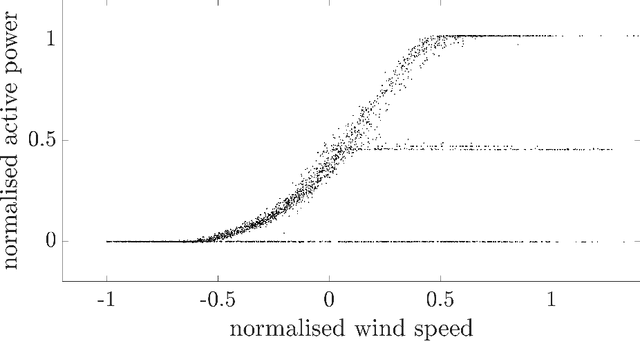

Power curves capture the relationship between wind speed and output power for a specific wind turbine. Accurate regression models of this function prove useful in monitoring, maintenance, design, and planning. In practice, however, the measurements do not always correspond to the ideal curve: power curtailments will appear as (additional) functional components. Such multivalued relationships cannot be modelled by conventional regression, and the associated data are usually removed during pre-processing. The current work suggests an alternative method to infer multivalued relationships in curtailed power data. Using a population-based approach, an overlapping mixture of probabilistic regression models is applied to signals recorded from turbines within an operational wind farm. The model is shown to provide an accurate representation of practical power data across the population.
On risk-based active learning for structural health monitoring
May 12, 2021
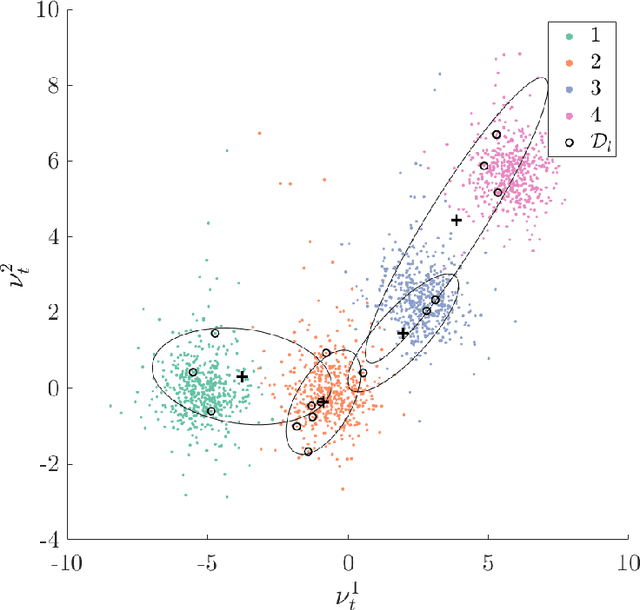
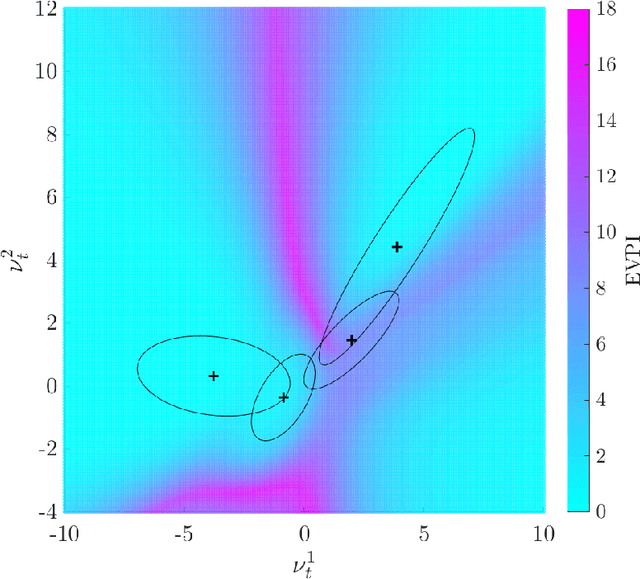
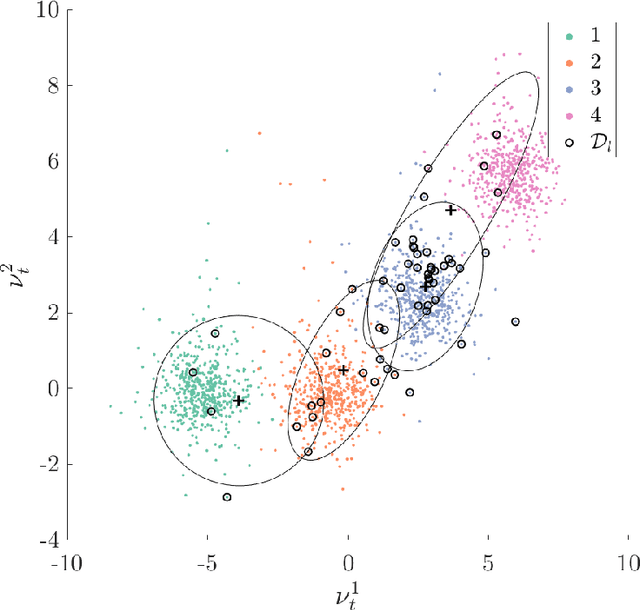
A primary motivation for the development and implementation of structural health monitoring systems, is the prospect of gaining the ability to make informed decisions regarding the operation and maintenance of structures and infrastructure. Unfortunately, descriptive labels for measured data corresponding to health-state information for the structure of interest are seldom available prior to the implementation of a monitoring system. This issue limits the applicability of the traditional supervised and unsupervised approaches to machine learning in the development of statistical classifiers for decision-supporting SHM systems. The current paper presents a risk-based formulation of active learning, in which the querying of class-label information is guided by the expected value of said information for each incipient data point. When applied to structural health monitoring, the querying of class labels can be mapped onto the inspection of a structure of interest in order to determine its health state. In the current paper, the risk-based active learning process is explained and visualised via a representative numerical example and subsequently applied to the Z24 Bridge benchmark. The results of the case studies indicate that a decision-maker's performance can be improved via the risk-based active learning of a statistical classifier, such that the decision process itself is taken into account.