 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Crowd-Aware Robot Navigation for Pedestrians with Multiple Collision Avoidance Strategies via Map-based Deep Reinforcement Learning
Sep 06, 2021
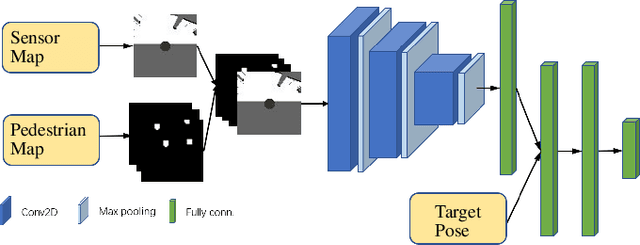
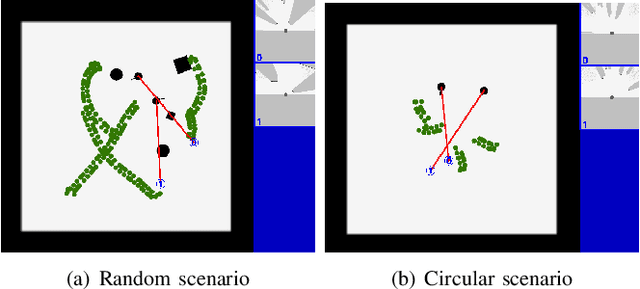
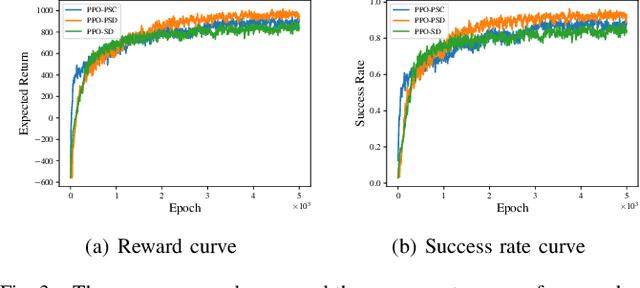
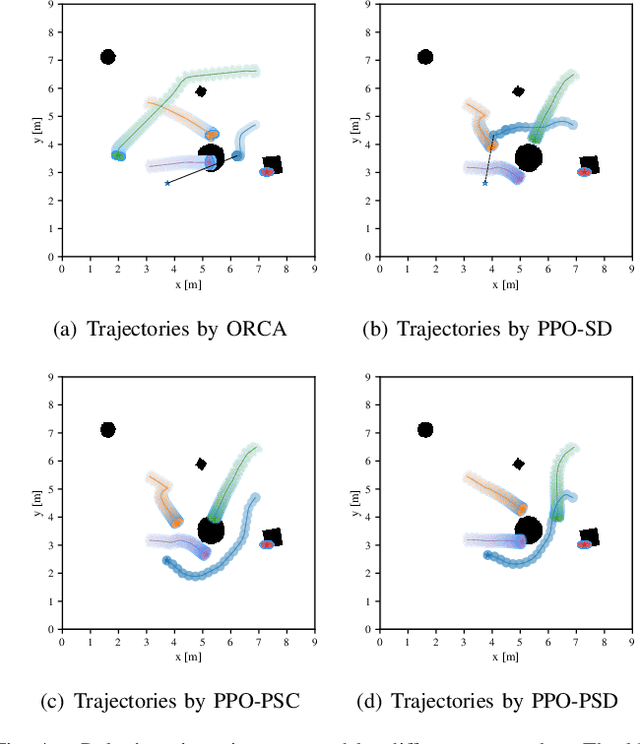
It is challenging for a mobile robot to navigate through human crowds. Existing approaches usually assume that pedestrians follow a predefined collision avoidance strategy, like social force model (SFM) or optimal reciprocal collision avoidance (ORCA). However, their performances commonly need to be further improved for practical applications, where pedestrians follow multiple different collision avoidance strategies. In this paper, we propose a map-based deep reinforcement learning approach for crowd-aware robot navigation with various pedestrians. We use the sensor map to represent the environmental information around the robot, including its shape and observable appearances of obstacles. We also introduce the pedestrian map that specifies the movements of pedestrians around the robot. By applying both maps as inputs of the neural network, we show that a navigation policy can be trained to better interact with pedestrians following different collision avoidance strategies. We evaluate our approach under multiple scenarios both in the simulator and on an actual robot. The results show that our approach allows the robot to successfully interact with various pedestrians and outperforms compared methods in terms of the success rate.
Generalization in Reinforcement Learning with Selective Noise Injection and Information Bottleneck
Oct 28, 2019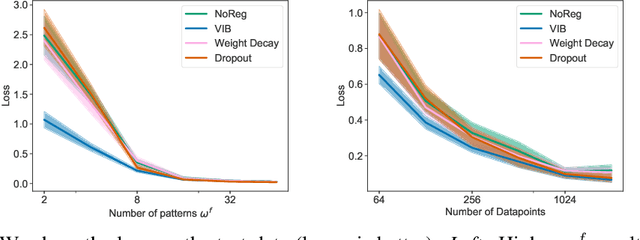
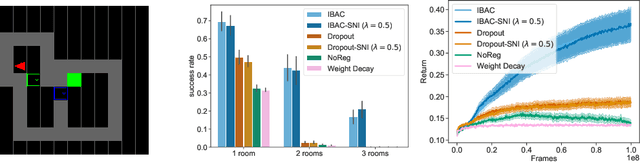
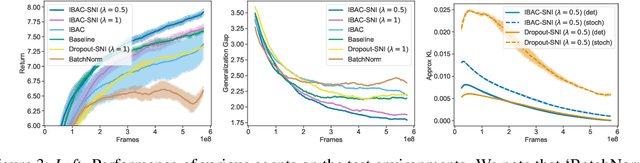
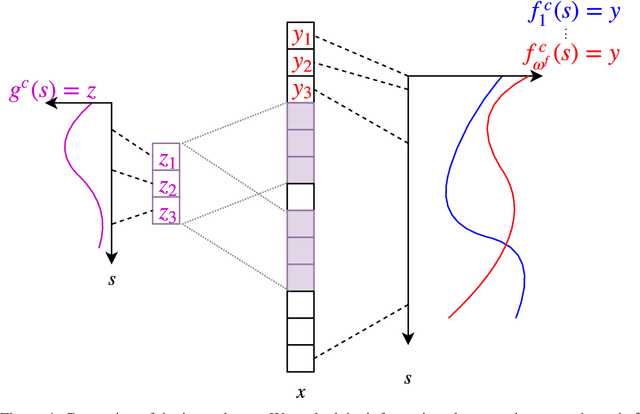
The ability for policies to generalize to new environments is key to the broad application of RL agents. A promising approach to prevent an agent's policy from overfitting to a limited set of training environments is to apply regularization techniques originally developed for supervised learning. However, there are stark differences between supervised learning and RL. We discuss those differences and propose modifications to existing regularization techniques in order to better adapt them to RL. In particular, we focus on regularization techniques relying on the injection of noise into the learned function, a family that includes some of the most widely used approaches such as Dropout and Batch Normalization. To adapt them to RL, we propose Selective Noise Injection (SNI), which maintains the regularizing effect the injected noise has, while mitigating the adverse effects it has on the gradient quality. Furthermore, we demonstrate that the Information Bottleneck (IB) is a particularly well suited regularization technique for RL as it is effective in the low-data regime encountered early on in training RL agents. Combining the IB with SNI, we significantly outperform current state of the art results, including on the recently proposed generalization benchmark Coinrun.
PC-DAN: Point Cloud based Deep Affinity Network for 3D Multi-Object Tracking (Accepted as an extended abstract in JRDB-ACT Workshop at CVPR21)
Jun 03, 2021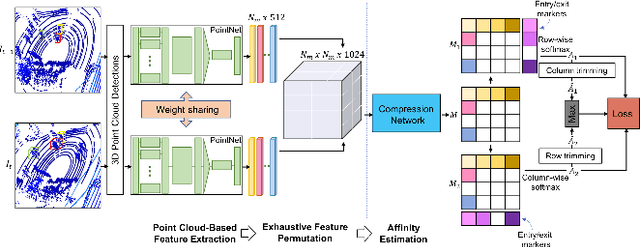
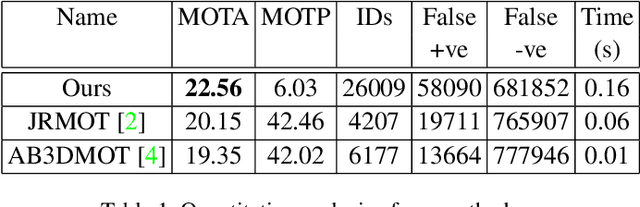
In recent times, the scope of LIDAR (Light Detection and Ranging) sensor-based technology has spread across numerous fields. It is popularly used to map terrain and navigation information into reliable 3D point cloud data, potentially revolutionizing the autonomous vehicles and assistive robotic industry. A point cloud is a dense compilation of spatial data in 3D coordinates. It plays a vital role in modeling complex real-world scenes since it preserves structural information and avoids perspective distortion, unlike image data, which is the projection of a 3D structure on a 2D plane. In order to leverage the intrinsic capabilities of the LIDAR data, we propose a PointNet-based approach for 3D Multi-Object Tracking (MOT).
Training Automatic View Planner for Cardiac MR Imaging via Self-Supervision by Spatial Relationship between Views
Sep 24, 2021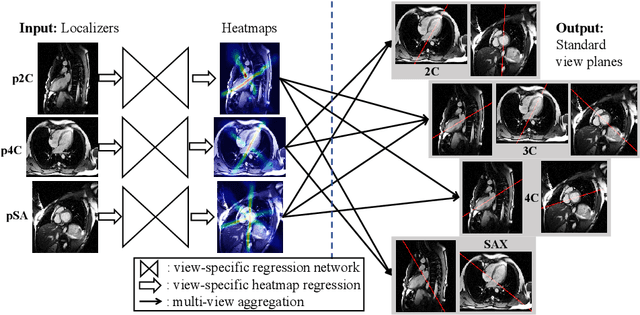
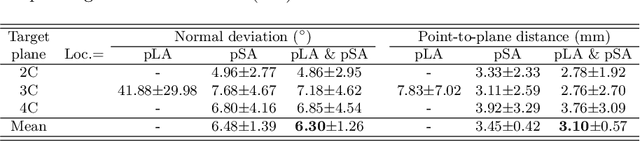
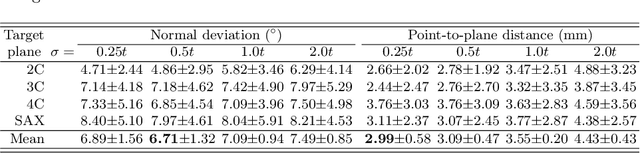
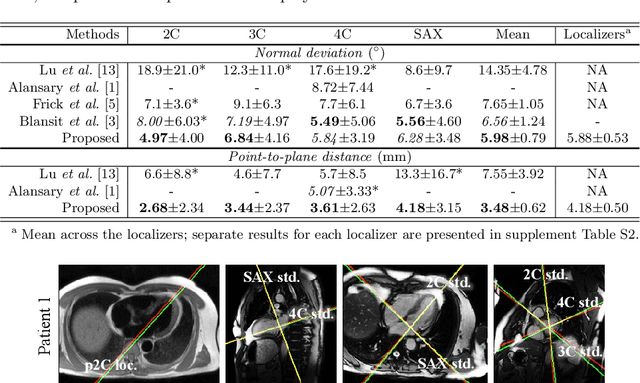
View planning for the acquisition of cardiac magnetic resonance imaging (CMR) requires acquaintance with the cardiac anatomy and remains a challenging task in clinical practice. Existing approaches to its automation relied either on an additional volumetric image not typically acquired in clinic routine, or on laborious manual annotations of cardiac structural landmarks. This work presents a clinic-compatible and annotation-free system for automatic CMR view planning. The system mines the spatial relationship -- more specifically, locates and exploits the intersecting lines -- between the source and target views, and trains deep networks to regress heatmaps defined by these intersecting lines. As the spatial relationship is self-contained in properly stored data, e.g., in the DICOM format, the need for manual annotation is eliminated. Then, a multi-view planning strategy is proposed to aggregate information from the predicted heatmaps for all the source views of a target view, for a globally optimal prescription. The multi-view aggregation mimics the similar strategy practiced by skilled human prescribers. Experimental results on 181 clinical CMR exams show that our system achieves superior accuracy to existing approaches including conventional atlas-based and newer deep learning based ones, in prescribing four standard CMR views. The mean angle difference and point-to-plane distance evaluated against the ground truth planes are 5.98 degrees and 3.48 mm, respectively.
WeClick: Weakly-Supervised Video Semantic Segmentation with Click Annotations
Jul 07, 2021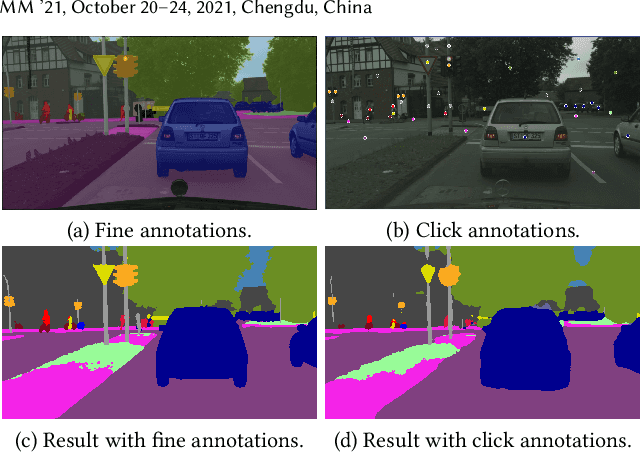
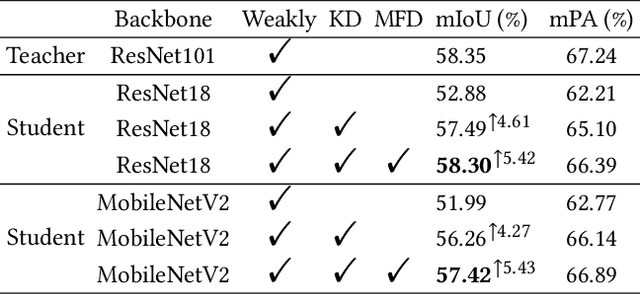
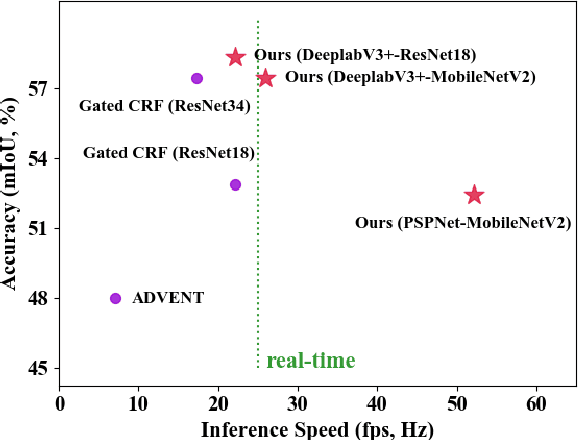
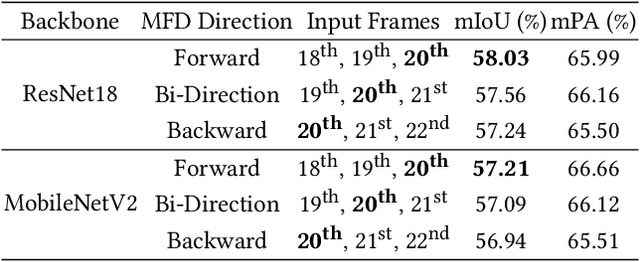
Compared with tedious per-pixel mask annotating, it is much easier to annotate data by clicks, which costs only several seconds for an image. However, applying clicks to learn video semantic segmentation model has not been explored before. In this work, we propose an effective weakly-supervised video semantic segmentation pipeline with click annotations, called WeClick, for saving laborious annotating effort by segmenting an instance of the semantic class with only a single click. Since detailed semantic information is not captured by clicks, directly training with click labels leads to poor segmentation predictions. To mitigate this problem, we design a novel memory flow knowledge distillation strategy to exploit temporal information (named memory flow) in abundant unlabeled video frames, by distilling the neighboring predictions to the target frame via estimated motion. Moreover, we adopt vanilla knowledge distillation for model compression. In this case, WeClick learns compact video semantic segmentation models with the low-cost click annotations during the training phase yet achieves real-time and accurate models during the inference period. Experimental results on Cityscapes and Camvid show that WeClick outperforms the state-of-the-art methods, increases performance by 10.24% mIoU than baseline, and achieves real-time execution.
Image Fusion Transformer
Jul 19, 2021
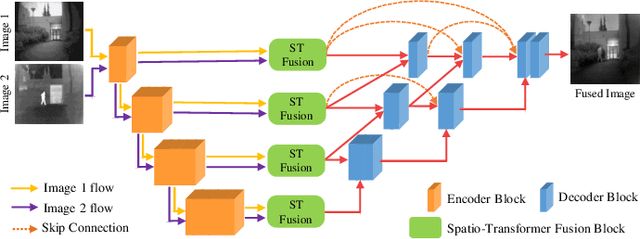
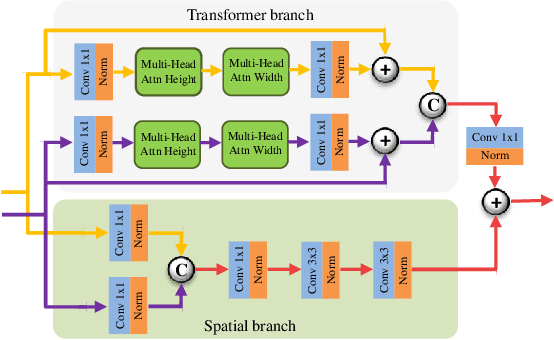
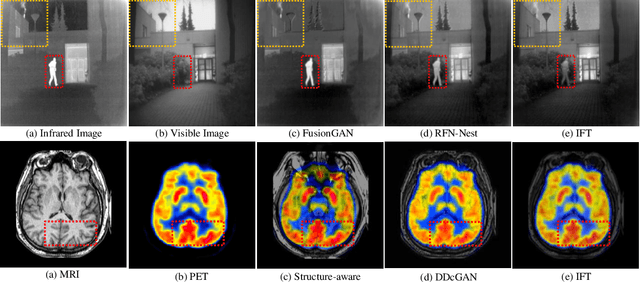
In image fusion, images obtained from different sensors are fused to generate a single image with enhanced information. In recent years, state-of-the-art methods have adopted Convolution Neural Networks (CNNs) to encode meaningful features for image fusion. Specifically, CNN-based methods perform image fusion by fusing local features. However, they do not consider long-range dependencies that are present in the image. Transformer-based models are designed to overcome this by modeling the long-range dependencies with the help of self-attention mechanism. This motivates us to propose a novel Image Fusion Transformer (IFT) where we develop a transformer-based multi-scale fusion strategy that attends to both local and long-range information (or global context). The proposed method follows a two-stage training approach. In the first stage, we train an auto-encoder to extract deep features at multiple scales. In the second stage, multi-scale features are fused using a Spatio-Transformer (ST) fusion strategy. The ST fusion blocks are comprised of a CNN and a transformer branch which capture local and long-range features, respectively. Extensive experiments on multiple benchmark datasets show that the proposed method performs better than many competitive fusion algorithms. Furthermore, we show the effectiveness of the proposed ST fusion strategy with an ablation analysis. The source code is available at: https://github.com/Vibashan/Image-Fusion-Transformer}{https://github.com/Vibashan/Image-Fusion-Transformer.
Learning to Navigate Sidewalks in Outdoor Environments
Sep 12, 2021
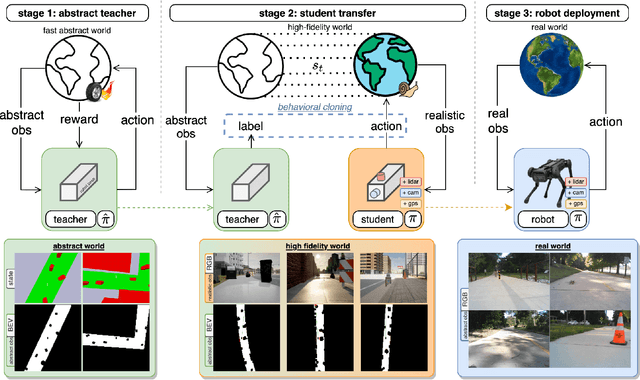
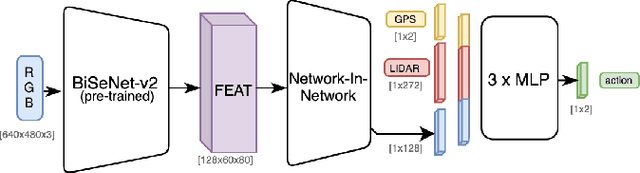
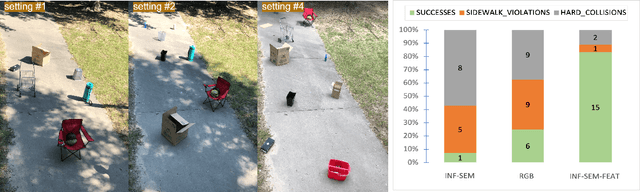
Outdoor navigation on sidewalks in urban environments is the key technology behind important human assistive applications, such as last-mile delivery or neighborhood patrol. This paper aims to develop a quadruped robot that follows a route plan generated by public map services, while remaining on sidewalks and avoiding collisions with obstacles and pedestrians. We devise a two-staged learning framework, which first trains a teacher agent in an abstract world with privileged ground-truth information, and then applies Behavior Cloning to teach the skills to a student agent who only has access to realistic sensors. The main research effort of this paper focuses on overcoming challenges when deploying the student policy on a quadruped robot in the real world. We propose methodologies for designing sensing modalities, network architectures, and training procedures to enable zero-shot policy transfer to unstructured and dynamic real outdoor environments. We evaluate our learning framework on a quadrupedal robot navigating sidewalks in the city of Atlanta, USA. Using the learned navigation policy and its onboard sensors, the robot is able to walk 3.2 kilometers with a limited number of human interventions.
Denoising ECG by Adaptive Filter with Empirical Mode Decomposition
Aug 18, 2021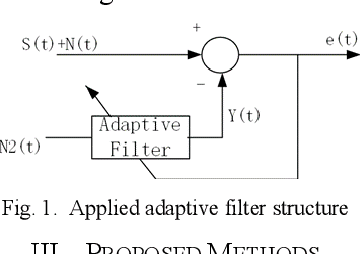
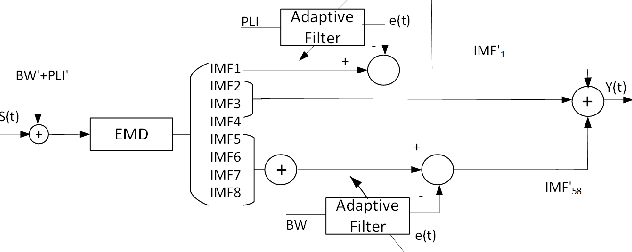
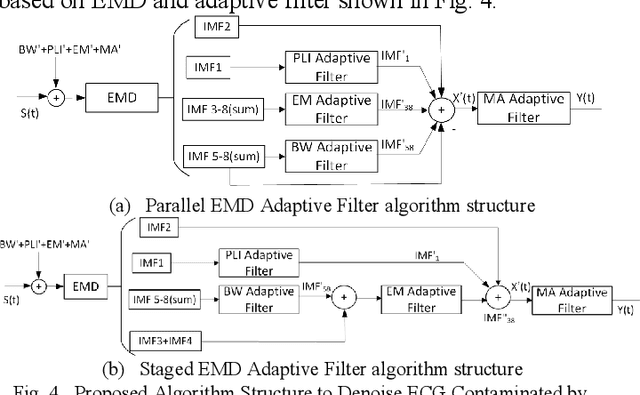
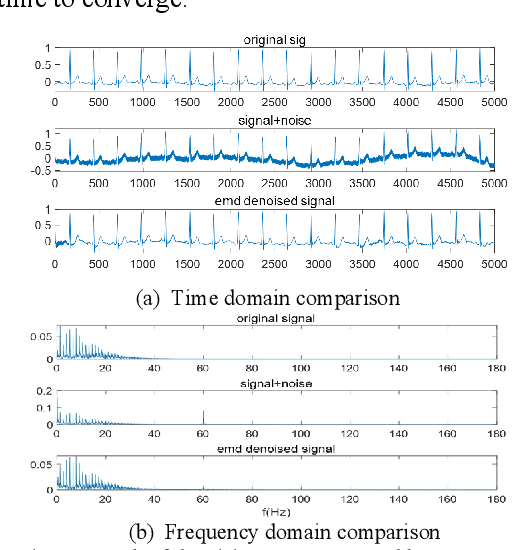
Electrocardiogram (ECG) signal is an important physiological signal which contains cardiac information and is the basis to diagnosis cardiac related diseases. In this paper, several innovative and efficient methods based on adaptive filter and empirical mode decomposition (EMD) to denoise ECG signal contaminated by various kinds of noise, including baseline wander (BW), power line interference (PLI), electrode motion artifact (EM) and muscle artifact (MA), are proposed. We first present a novel method based on EMD and adaptive filter for the removal of BW and PLI in ECG signal. We then extend the method to the complex scenario where four most common noises, PLI, BW, EM and MA are present. The proposed Parallel EMD adaptive filter structure yields the best SNR improvement on the MIT-BIH arrhythmia database, corrupted by the four types of noises.
Image-Audio Encoding to Improve C2 Decision-Making in Multi-Domain Environment
Jun 03, 2021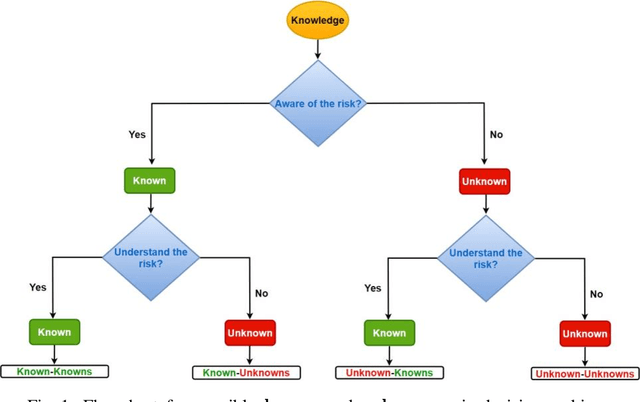

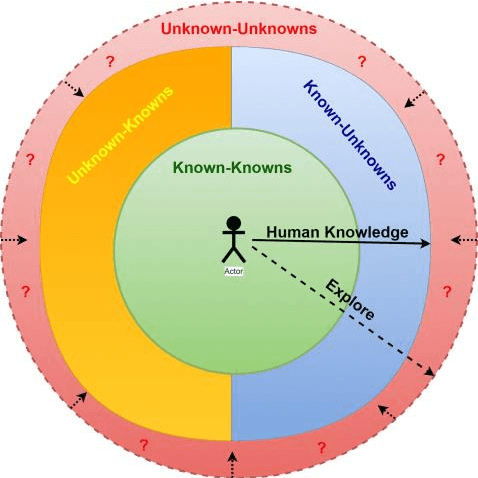

The military is investigating methods to improve communication and agility in its multi-domain operations (MDO). Nascent popularity of Internet of Things (IoT) has gained traction in public and government domains. Its usage in MDO may revolutionize future battlefields and may enable strategic advantage. While this technology offers leverage to military capabilities, it comes with challenges where one is the uncertainty and associated risk. A key question is how can these uncertainties be addressed. Recently published studies proposed information camouflage to transform information from one data domain to another. As this is comparatively a new approach, we investigate challenges of such transformations and how these associated uncertainties can be detected and addressed, specifically unknown-unknowns to improve decision-making.
* Published in: The 25th International Command and Control Research and Technology Symposium (ICCRTS - 2020)
U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition
Jul 07, 2021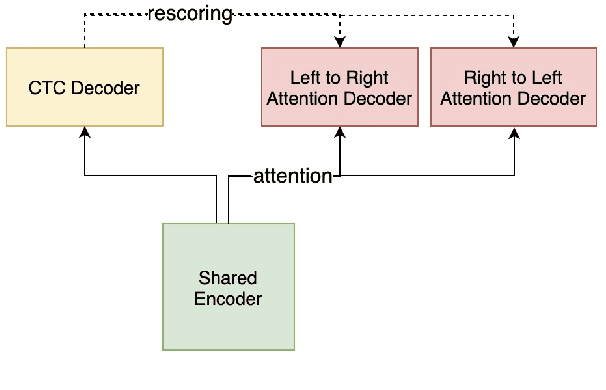
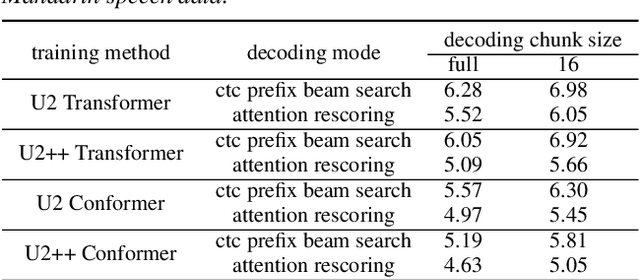
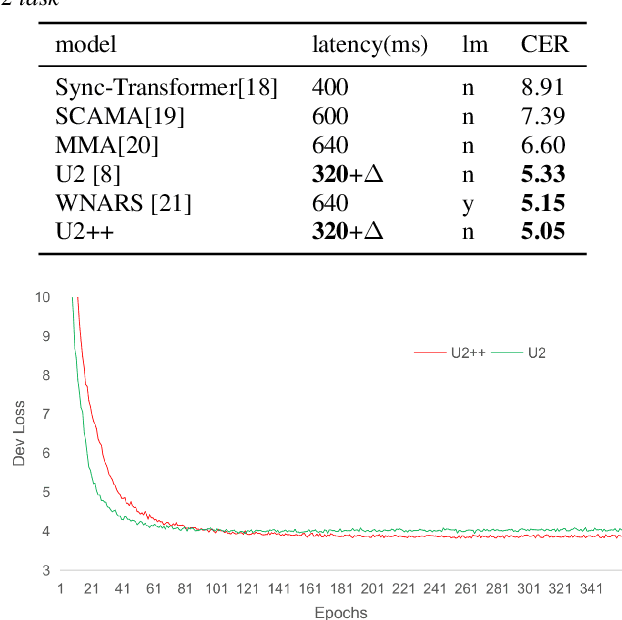
The unified streaming and non-streaming two-pass (U2) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy, real-time factor (RTF), and latency. In this paper, we present U2++, an enhanced version of U2 to further improve the accuracy. The core idea of U2++ is to use the forward and the backward information of the labeling sequences at the same time at training to learn richer information, and combine the forward and backward prediction at decoding to give more accurate recognition results. We also proposed a new data augmentation method called SpecSub to help the U2++ model to be more accurate and robust. Our experiments show that, compared with U2, U2++ shows faster convergence at training, better robustness to the decoding method, as well as consistent 5\% - 8\% word error rate reduction gain over U2. On the experiment of AISHELL-1, we achieve a 4.63\% character error rate (CER) with a non-streaming setup and 5.05\% with a streaming setup with 320ms latency by U2++. To the best of our knowledge, 5.05\% is the best-published streaming result on the AISHELL-1 test set.