 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IITP at WAT 2021: System description for English-Hindi Multimodal Translation Task
Jul 04, 2021



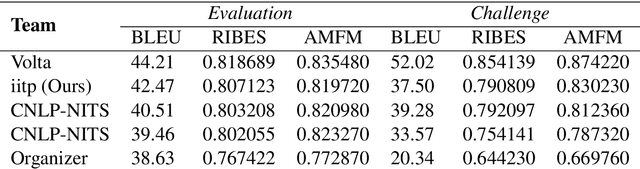
Neural Machine Translation (NMT) is a predominant machine translation technology nowadays because of its end-to-end trainable flexibility. However, NMT still struggles to translate properly in low-resource settings specifically on distant language pairs. One way to overcome this is to use the information from other modalities if available. The idea is that despite differences in languages, both the source and target language speakers see the same thing and the visual representation of both the source and target is the same, which can positively assist the system. Multimodal information can help the NMT system to improve the translation by removing ambiguity on some phrases or words. We participate in the 8th Workshop on Asian Translation (WAT - 2021) for English-Hindi multimodal translation task and achieve 42.47 and 37.50 BLEU points for Evaluation and Challenge subset, respectively.
TDEFSI: Theory Guided Deep Learning Based Epidemic Forecasting with Synthetic Information
Jan 28, 2020
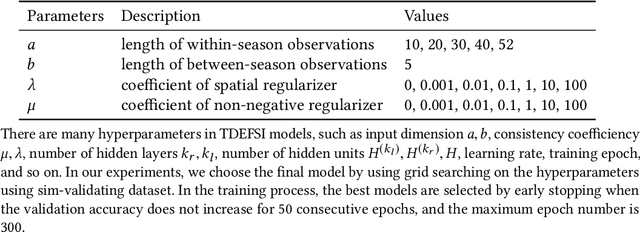
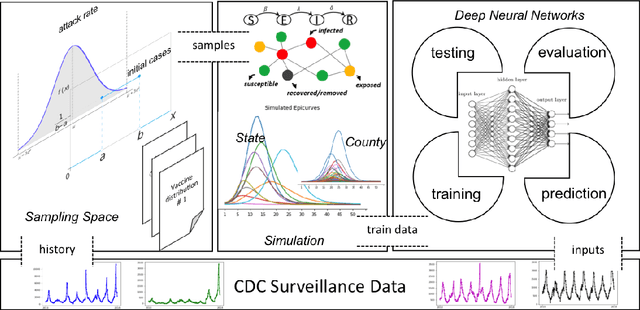
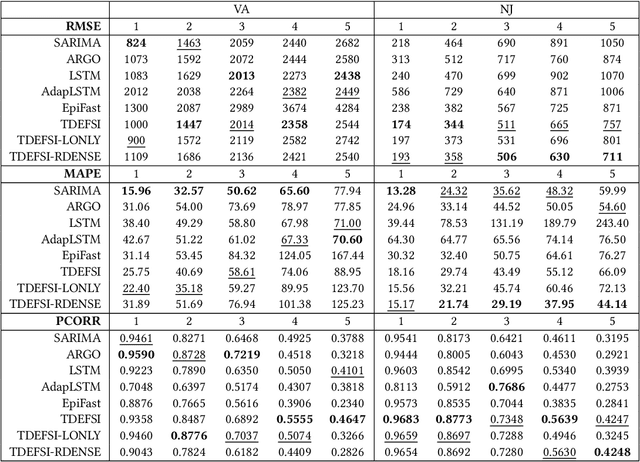
Influenza-like illness (ILI) places a heavy social and economic burden on our society. Traditionally, ILI surveillance data is updated weekly and provided at a spatially coarse resolution. Producing timely and reliable high-resolution spatiotemporal forecasts for ILI is crucial for local preparedness and optimal interventions. We present TDEFSI (Theory Guided Deep Learning Based Epidemic Forecasting with Synthetic Information), an epidemic forecasting framework that integrates the strengths of deep neural networks and high-resolution simulations of epidemic processes over networks. TDEFSI yields accurate high-resolution spatiotemporal forecasts using low-resolution time series data. During the training phase, TDEFSI uses high-resolution simulations of epidemics that explicitly model spatial and social heterogeneity inherent in urban regions as one component of training data. We train a two-branch recurrent neural network model to take both within-season and between-season low-resolution observations as features, and output high-resolution detailed forecasts. The resulting forecasts are not just driven by observed data but also capture the intricate social, demographic and geographic attributes of specific urban regions and mathematical theories of disease propagation over networks. We focus on forecasting the incidence of ILI and evaluate TDEFSI's performance using synthetic and real-world testing datasets at the state and county levels in the USA. The results show that, at the state level, our method achieves comparable/better performance than several state-of-the-art methods. At the county level, TDEFSI outperforms the other methods. The proposed method can be applied to other infectious diseases as well.
Self-appearance-aided Differential Evolution for Motion Transfer
Oct 09, 2021
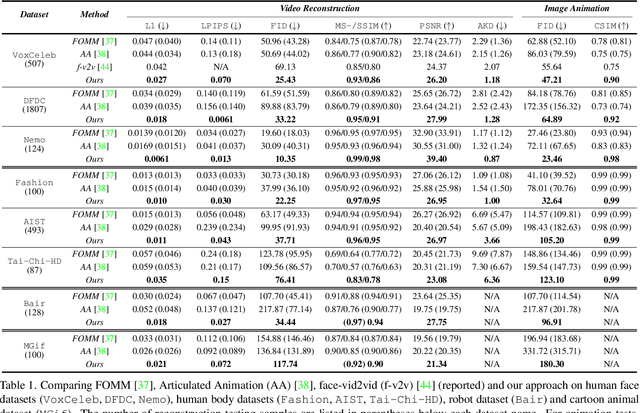
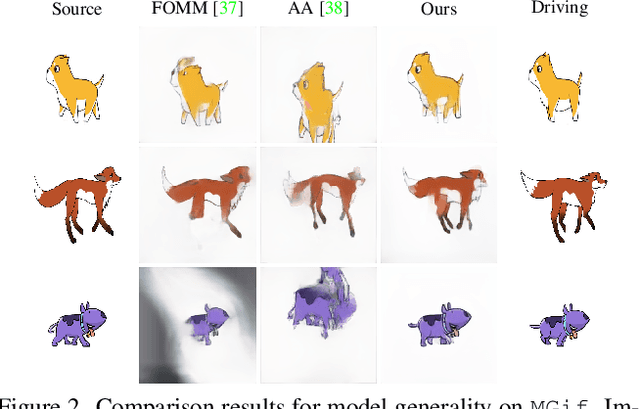
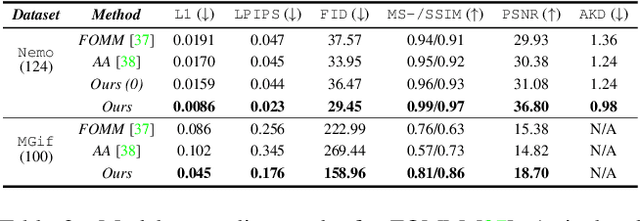
Image animation transfers the motion of a driving video to a static object in a source image, while keeping the source identity unchanged. Great progress has been made in unsupervised motion transfer recently, where no labelled data or ground truth domain priors are needed. However, current unsupervised approaches still struggle when there are large motion or viewpoint discrepancies between the source and driving images. In this paper, we introduce three measures that we found to be effective for overcoming such large viewpoint changes. Firstly, to achieve more fine-grained motion deformation fields, we propose to apply Neural-ODEs for parametrizing the evolution dynamics of the motion transfer from source to driving. Secondly, to handle occlusions caused by large viewpoint and motion changes, we take advantage of the appearance flow obtained from the source image itself ("self-appearance"), which essentially "borrows" similar structures from other regions of an image to inpaint missing regions. Finally, our framework is also able to leverage the information from additional reference views which help to drive the source identity in spite of varying motion state. Extensive experiments demonstrate that our approach outperforms the state-of-the-arts by a significant margin (~40%), across six benchmarks varying from human faces, human bodies to robots and cartoon characters. Model generality analysis indicates that our approach generalises the best across different object categories as well.
Recurrent Neural Network Controllers Synthesis with Stability Guarantees for Partially Observed Systems
Sep 08, 2021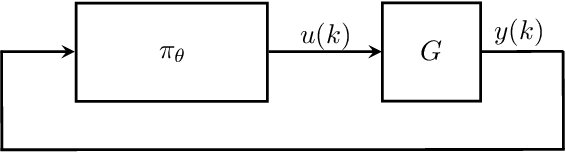
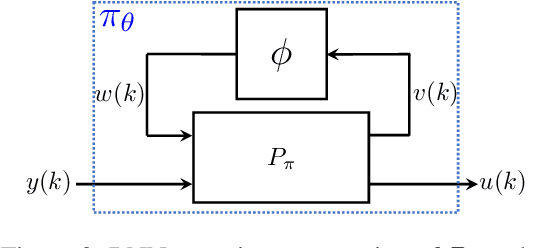
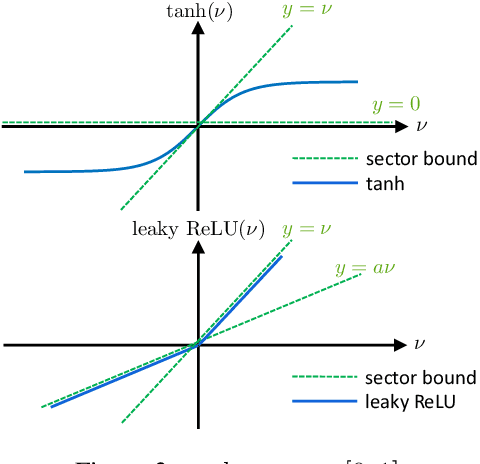
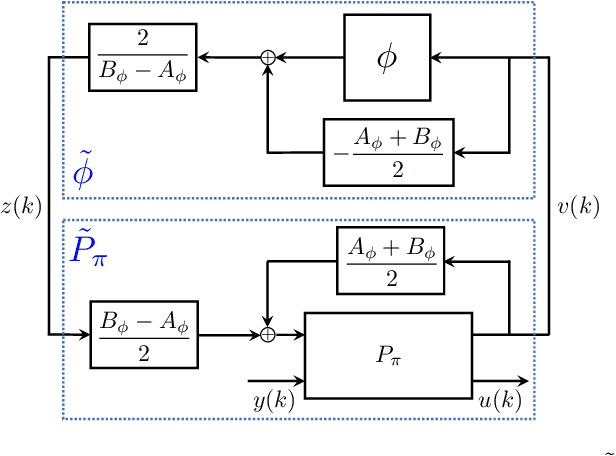
Neural network controllers have become popular in control tasks thanks to their flexibility and expressivity. Stability is a crucial property for safety-critical dynamical systems, while stabilization of partially observed systems, in many cases, requires controllers to retain and process long-term memories of the past. We consider the important class of recurrent neural networks (RNN) as dynamic controllers for nonlinear uncertain partially-observed systems, and derive convex stability conditions based on integral quadratic constraints, S-lemma and sequential convexification. To ensure stability during the learning and control process, we propose a projected policy gradient method that iteratively enforces the stability conditions in the reparametrized space taking advantage of mild additional information on system dynamics. Numerical experiments show that our method learns stabilizing controllers while using fewer samples and achieving higher final performance compared with policy gradient.
Near optimal sample complexity for matrix and tensor normal models via geodesic convexity
Oct 14, 2021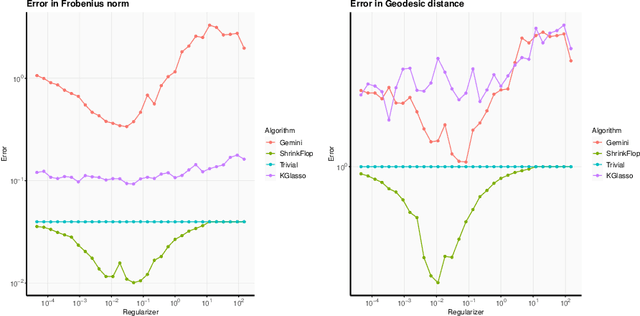
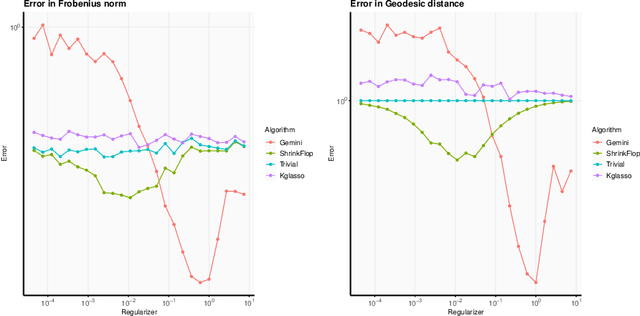
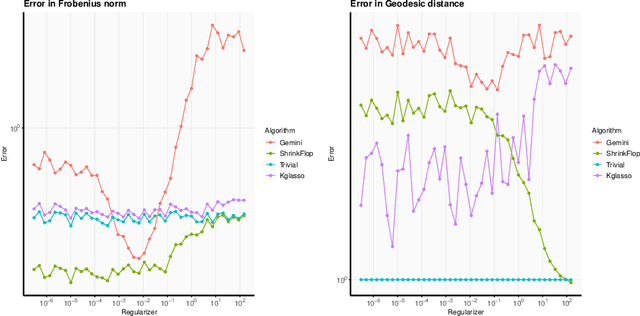
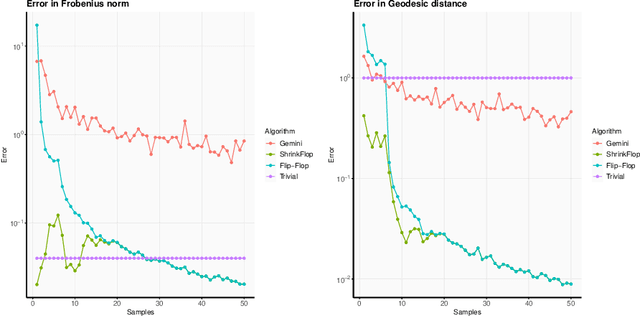
The matrix normal model, the family of Gaussian matrix-variate distributions whose covariance matrix is the Kronecker product of two lower dimensional factors, is frequently used to model matrix-variate data. The tensor normal model generalizes this family to Kronecker products of three or more factors. We study the estimation of the Kronecker factors of the covariance matrix in the matrix and tensor models. We show nonasymptotic bounds for the error achieved by the maximum likelihood estimator (MLE) in several natural metrics. In contrast to existing bounds, our results do not rely on the factors being well-conditioned or sparse. For the matrix normal model, all our bounds are minimax optimal up to logarithmic factors, and for the tensor normal model our bound for the largest factor and overall covariance matrix are minimax optimal up to constant factors provided there are enough samples for any estimator to obtain constant Frobenius error. In the same regimes as our sample complexity bounds, we show that an iterative procedure to compute the MLE known as the flip-flop algorithm converges linearly with high probability. Our main tool is geodesic strong convexity in the geometry on positive-definite matrices induced by the Fisher information metric. This strong convexity is determined by the expansion of certain random quantum channels. We also provide numerical evidence that combining the flip-flop algorithm with a simple shrinkage estimator can improve performance in the undersampled regime.
Assessing glaucoma in retinal fundus photographs using Deep Feature Consistent Variational Autoencoders
Oct 04, 2021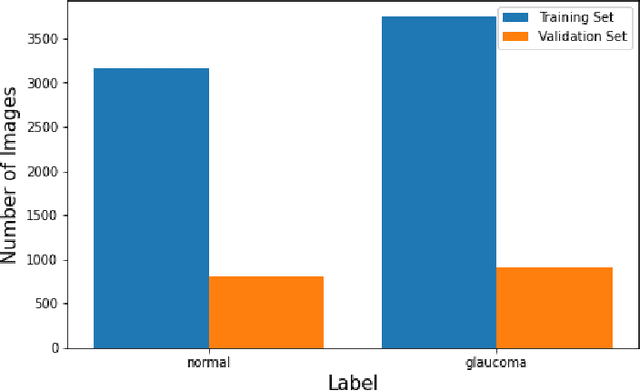
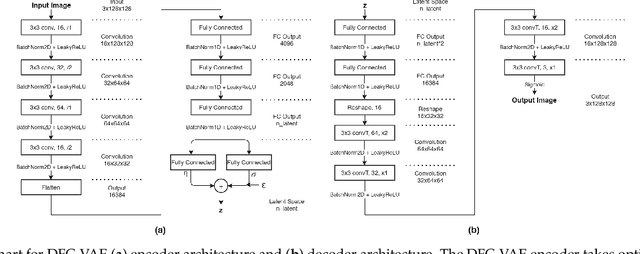
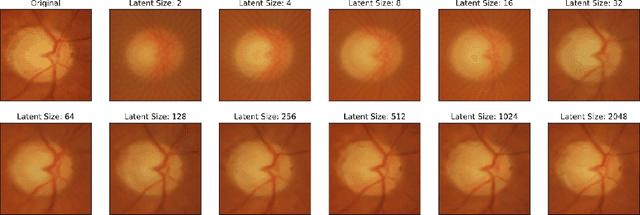
One of the leading causes of blindness is glaucoma, which is challenging to detect since it remains asymptomatic until the symptoms are severe. Thus, diagnosis is usually possible until the markers are easy to identify, i.e., the damage has already occurred. Early identification of glaucoma is generally made based on functional, structural, and clinical assessments. However, due to the nature of the disease, researchers still debate which markers qualify as a consistent glaucoma metric. Deep learning methods have partially solved this dilemma by bypassing the marker identification stage and analyzing high-level information directly to classify the data. Although favorable, these methods make expert analysis difficult as they provide no insight into the model discrimination process. In this paper, we overcome this using deep generative networks, a deep learning model that learns complicated, high-dimensional probability distributions. We train a Deep Feature consistent Variational Autoencoder (DFC-VAE) to reconstruct optic disc images. We show that a small-sized latent space obtained from the DFC-VAE can learn the high-dimensional glaucoma data distribution and provide discriminatory evidence between normal and glaucoma eyes. Latent representations of size as low as 128 from our model got a 0.885 area under the receiver operating characteristic curve when trained with Support Vector Classifier.
SWIPT with Intelligent Reflecting Surfaces under Spatial Correlation
Jun 01, 2021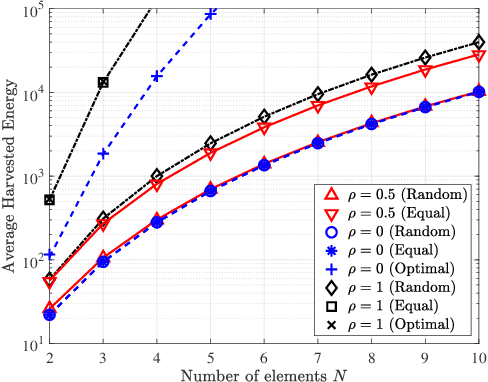
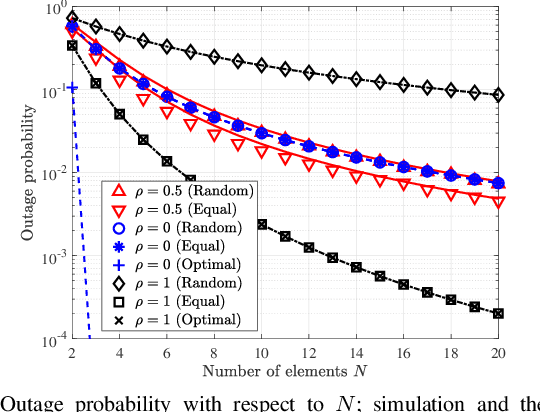
Intelligent reflecting surfaces (IRSs) can be beneficial to both information and energy transfer, due to the gains achieved by their multiple elements. In this work, we deal with the impact of spatial correlation between the IRS elements, in the context of simultaneous wireless information and power transfer. The performance is evaluated in terms of the average harvested energy and the outage probability for random and equal phase shifts. Closed-form analytical expressions for both metrics under spatial correlation are derived. Moreover, the optimal case is considered when the elements are uncorrelated and fully correlated. In the uncorrelated case, random and equal phase shifts provide the same performance. However, the performance of correlated elements attains significant gains when there are equal phase shifts. Finally, we show that correlation is always beneficial to energy transfer, whereas it is a degrading factor for information transfer under random and optimal configurations.
Risk Averse Bayesian Reward Learning for Autonomous Navigation from Human Demonstration
Jul 31, 2021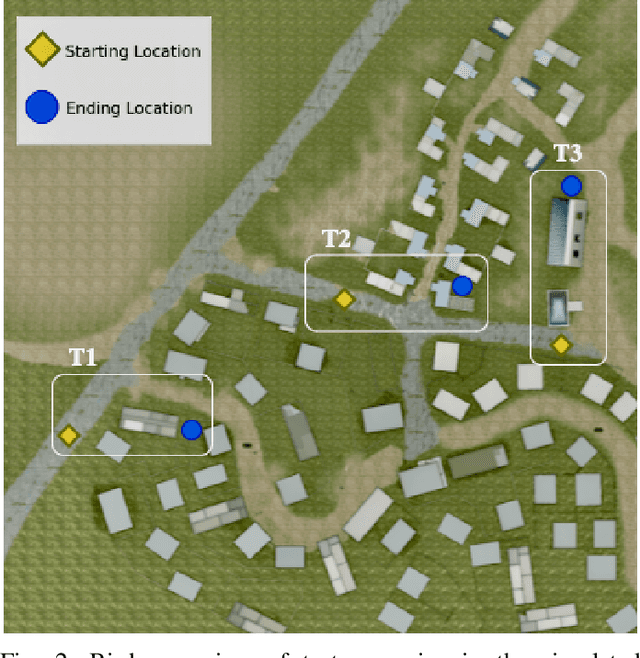

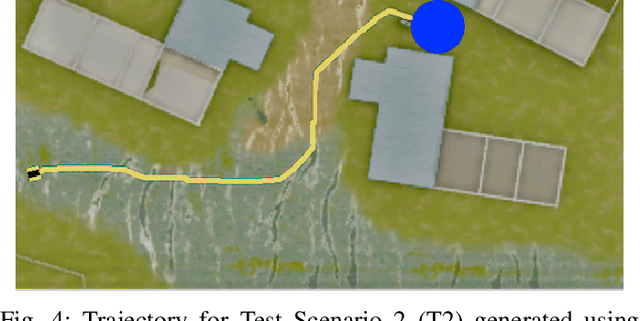
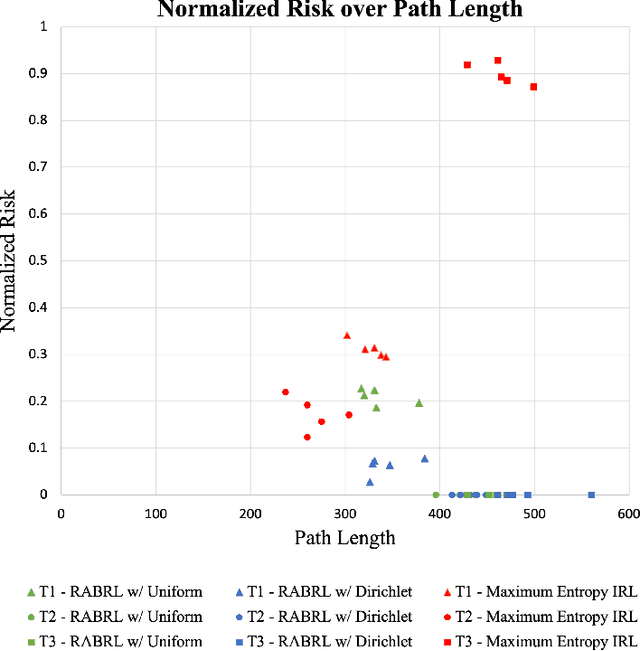
Traditional imitation learning provides a set of methods and algorithms to learn a reward function or policy from expert demonstrations. Learning from demonstration has been shown to be advantageous for navigation tasks as it allows for machine learning non-experts to quickly provide information needed to learn complex traversal behaviors. However, a minimal set of demonstrations is unlikely to capture all relevant information needed to achieve the desired behavior in every possible future operational environment. Due to distributional shift among environments, a robot may encounter features that were rarely or never observed during training for which the appropriate reward value is uncertain, leading to undesired outcomes. This paper proposes a Bayesian technique which quantifies uncertainty over the weights of a linear reward function given a dataset of minimal human demonstrations to operate safely in dynamic environments. This uncertainty is quantified and incorporated into a risk averse set of weights used to generate cost maps for planning. Experiments in a 3-D environment with a simulated robot show that our proposed algorithm enables a robot to avoid dangerous terrain completely in two out of three test scenarios and accumulates a lower amount of risk than related approaches in all scenarios without requiring any additional demonstrations.
GREN: Graph-Regularized Embedding Network for Weakly-Supervised Disease Localization in X-ray images
Jul 14, 2021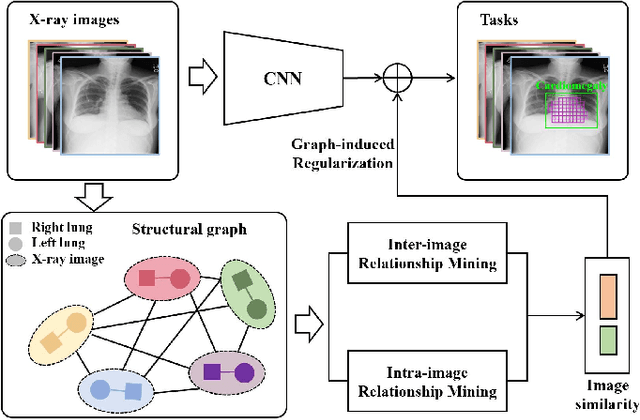
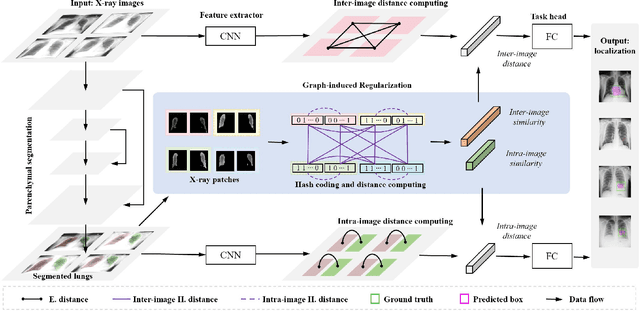
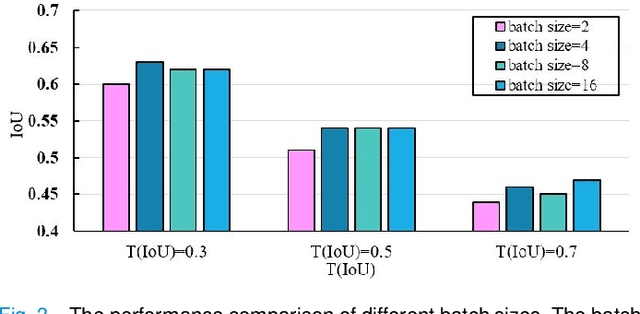
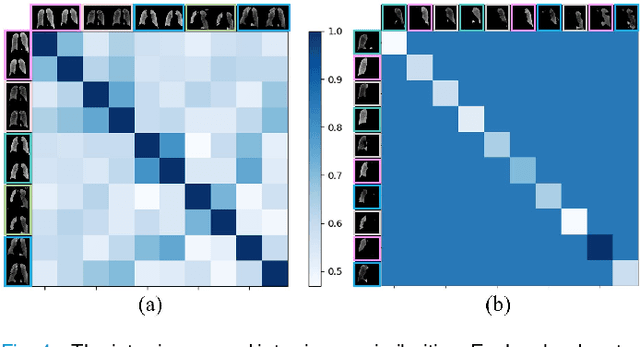
Locating diseases in chest X-ray images with few careful annotations saves large human effort. Recent works approached this task with innovative weakly-supervised algorithms such as multi-instance learning (MIL) and class activation maps (CAM), however, these methods often yield inaccurate or incomplete regions. One of the reasons is the neglection of the pathological implications hidden in the relationship across anatomical regions within each image and the relationship across images. In this paper, we argue that the cross-region and cross-image relationship, as contextual and compensating information, is vital to obtain more consistent and integral regions. To model the relationship, we propose the Graph Regularized Embedding Network (GREN), which leverages the intra-image and inter-image information to locate diseases on chest X-ray images. GREN uses a pre-trained U-Net to segment the lung lobes, and then models the intra-image relationship between the lung lobes using an intra-image graph to compare different regions. Meanwhile, the relationship between in-batch images is modeled by an inter-image graph to compare multiple images. This process mimics the training and decision-making process of a radiologist: comparing multiple regions and images for diagnosis. In order for the deep embedding layers of the neural network to retain structural information (important in the localization task), we use the Hash coding and Hamming distance to compute the graphs, which are used as regularizers to facilitate training. By means of this, our approach achieves the state-of-the-art result on NIH chest X-ray dataset for weakly-supervised disease localization. Our codes are accessible online.
Re-determinizing Information Set Monte Carlo Tree Search in Hanabi
Feb 16, 2019

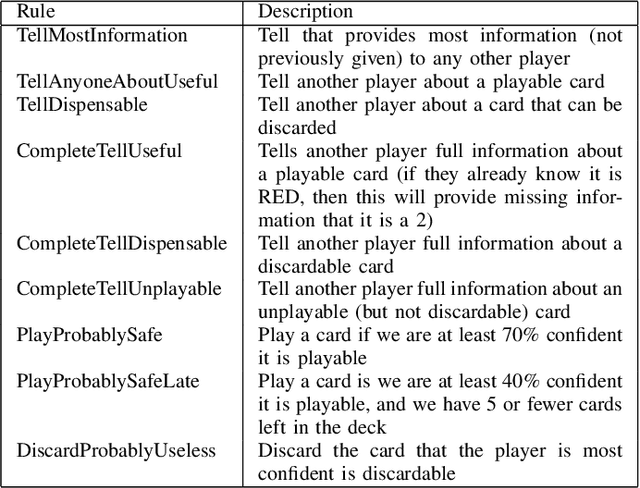
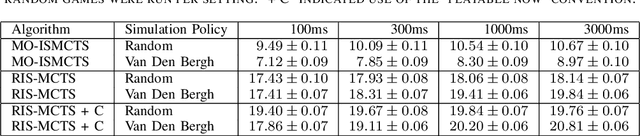
This technical report documents the winner of the Computational Intelligence in Games(CIG) 2018 Hanabi competition. We introduce Re-determinizing IS-MCTS, a novel extension of Information Set Monte Carlo Tree Search (IS-MCTS) \cite{IS-MCTS} that prevents a leakage of hidden information into opponent models that can occur in IS-MCTS, and is particularly severe in Hanabi. Re-determinizing IS-MCTS scores higher in Hanabi for 2-4 players than previously published work. Given the 40ms competition time limit per move we use a learned evaluation function to estimate leaf node values and avoid full simulations during MCTS. For the Mixed track competition, in which the identity of the other players is unknown, a simple Bayesian opponent model is used that is updated as each game proceeds.