 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Averse Bayesian Reward Learning for Autonomous Navigation from Human Demonstration
Paper and Code
Jul 31, 2021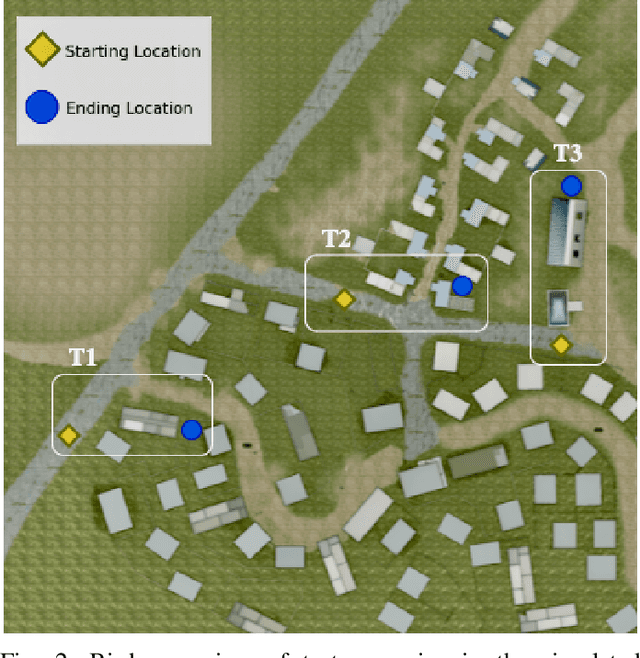

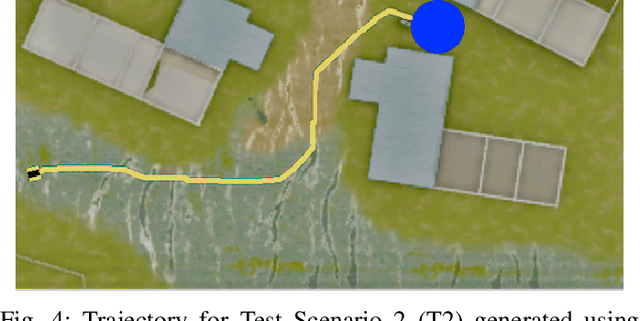
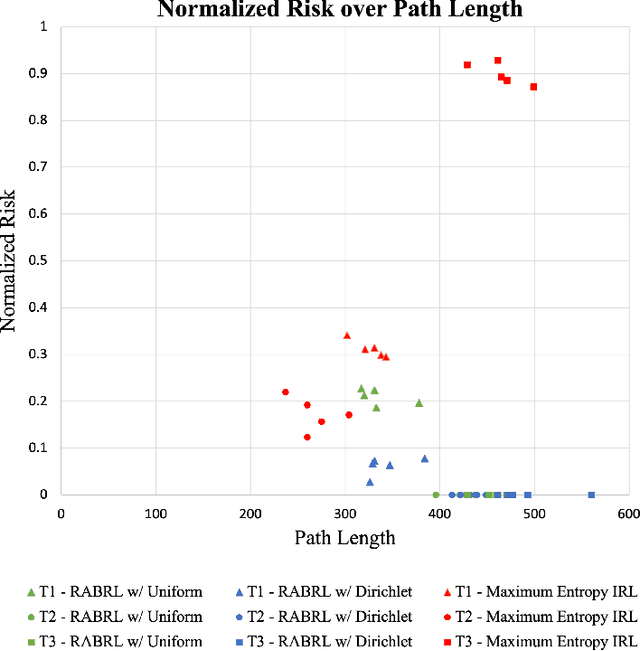
Traditional imitation learning provides a set of methods and algorithms to learn a reward function or policy from expert demonstrations. Learning from demonstration has been shown to be advantageous for navigation tasks as it allows for machine learning non-experts to quickly provide information needed to learn complex traversal behaviors. However, a minimal set of demonstrations is unlikely to capture all relevant information needed to achieve the desired behavior in every possible future operational environment. Due to distributional shift among environments, a robot may encounter features that were rarely or never observed during training for which the appropriate reward value is uncertain, leading to undesired outcomes. This paper proposes a Bayesian technique which quantifies uncertainty over the weights of a linear reward function given a dataset of minimal human demonstrations to operate safely in dynamic environments. This uncertainty is quantified and incorporated into a risk averse set of weights used to generate cost maps for planning. Experiments in a 3-D environment with a simulated robot show that our proposed algorithm enables a robot to avoid dangerous terrain completely in two out of three test scenarios and accumulates a lower amount of risk than related approaches in all scenarios without requiring any additional demonstrations.