 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Machine Learning-Based Soft Sensors for Vacuum Distillation Unit
Nov 19, 2021

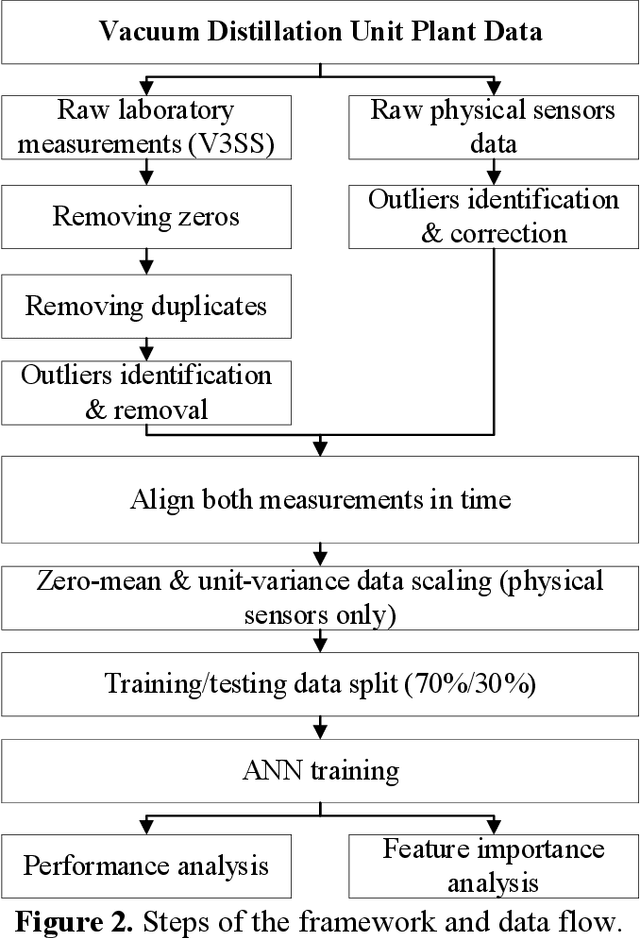
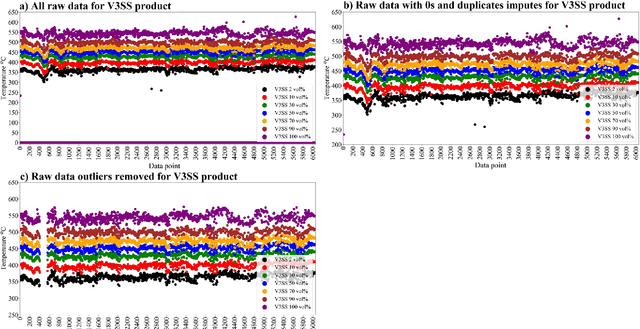
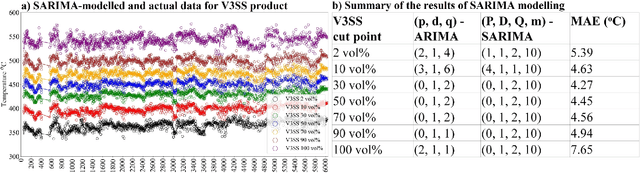
Product quality assessment in the petroleum processing industry can be difficult and time-consuming, e.g. due to a manual collection of liquid samples from the plant and subsequent chemical laboratory analysis of the samples. The product quality is an important property that informs whether the products of the process are within the specifications. In particular, the delays caused by sample processing (collection, laboratory measurements, results analysis, reporting) can lead to detrimental economic effects. One of the strategies to deal with this problem is soft sensors. Soft sensors are a collection of models that can be used to predict and forecast some infrequently measured properties (such as laboratory measurements of petroleum products) based on more frequent measurements of quantities like temperature, pressure and flow rate provided by physical sensors. Soft sensors short-cut the pathway to obtain relevant information about the product quality, often providing measurements as frequently as every minute. One of the applications of soft sensors is for the real-time optimization of a chemical process by a targeted adaptation of operating parameters. Models used for soft sensors can have various forms, however, among the most common are those based on artificial neural networks (ANNs). While soft sensors can deal with some of the issues in the refinery processes, their development and deployment can pose other challenges that are addressed in this paper. Firstly, it is important to enhance the quality of both sets of data (laboratory measurements and physical sensors) in a data pre-processing stage (as described in Methodology section). Secondly, once the data sets are pre-processed, different models need to be tested against prediction error and the model's interpretability. In this work, we present a framework for soft sensor development from raw data to ready-to-use models.
A framework for information extraction from tables in biomedical literature
Feb 26, 2019
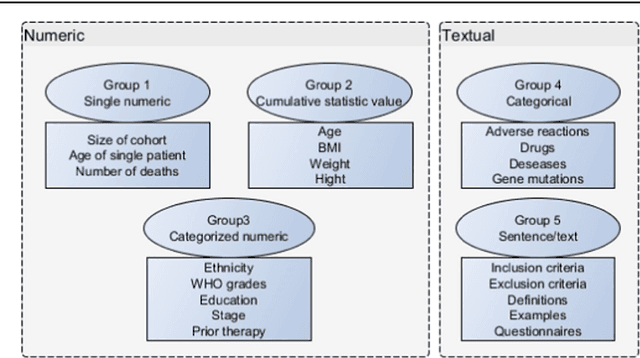
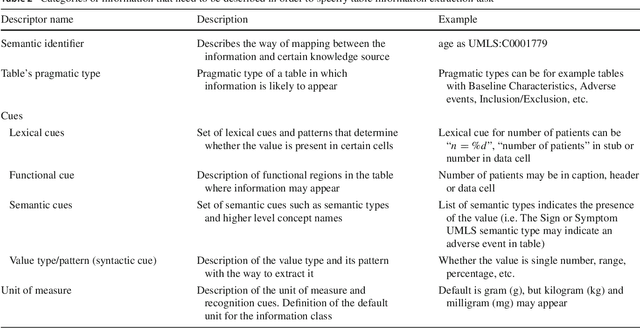

The scientific literature is growing exponentially, and professionals are no more able to cope with the current amount of publications. Text mining provided in the past methods to retrieve and extract information from text; however, most of these approaches ignored tables and figures. The research done in mining table data still does not have an integrated approach for mining that would consider all complexities and challenges of a table. Our research is examining the methods for extracting numerical (number of patients, age, gender distribution) and textual (adverse reactions) information from tables in the clinical literature. We present a requirement analysis template and an integral methodology for information extraction from tables in clinical domain that contains 7 steps: (1) table detection, (2) functional processing, (3) structural processing, (4) semantic tagging, (5) pragmatic processing, (6) cell selection and (7) syntactic processing and extraction. Our approach performed with the F-measure ranged between 82 and 92%, depending on the variable, task and its complexity.
* 24 pages
RPT++: Customized Feature Representation for Siamese Visual Tracking
Oct 23, 2021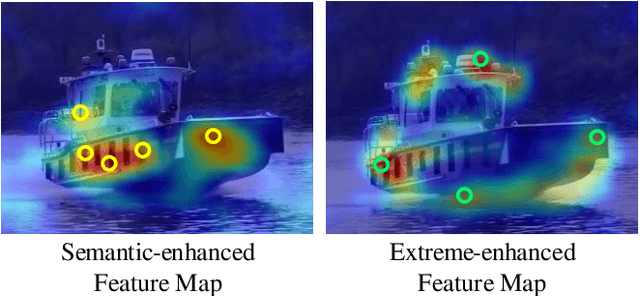

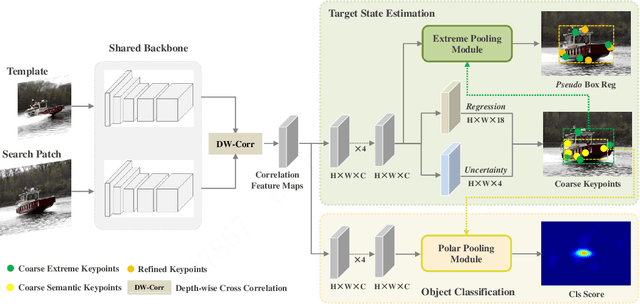

While recent years have witnessed remarkable progress in the feature representation of visual tracking, the problem of feature misalignment between the classification and regression tasks is largely overlooked. The approaches of feature extraction make no difference for these two tasks in most of advanced trackers. We argue that the performance gain of visual tracking is limited since features extracted from the salient area provide more recognizable visual patterns for classification, while these around the boundaries contribute to accurately estimating the target state. We address this problem by proposing two customized feature extractors, named polar pooling and extreme pooling to capture task-specific visual patterns. Polar pooling plays the role of enriching information collected from the semantic keypoints for stronger classification, while extreme pooling facilitates explicit visual patterns of the object boundary for accurate target state estimation. We demonstrate the effectiveness of the task-specific feature representation by integrating it into the recent and advanced tracker RPT. Extensive experiments on several benchmarks show that our Customized Features based RPT (RPT++) achieves new state-of-the-art performances on OTB-100, VOT2018, VOT2019, GOT-10k, TrackingNet and LaSOT.
Towards Language-guided Visual Recognition via Dynamic Convolutions
Oct 17, 2021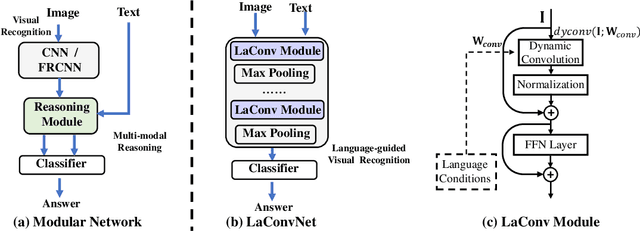
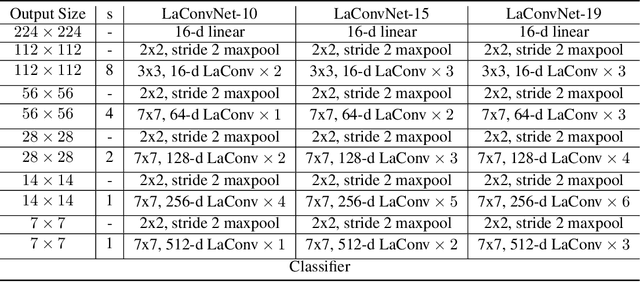
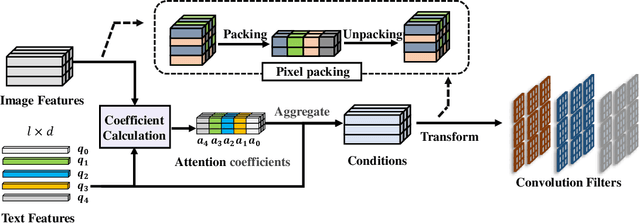
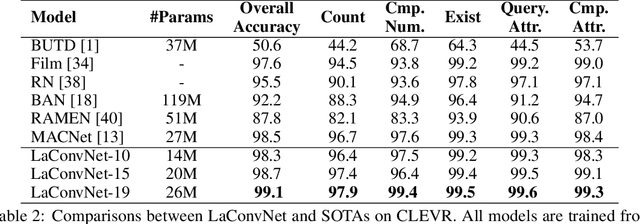
In this paper, we are committed to establishing an unified and end-to-end multi-modal network via exploring the language-guided visual recognition. To approach this target, we first propose a novel multi-modal convolution module called Language-dependent Convolution (LaConv). Its convolution kernels are dynamically generated based on natural language information, which can help extract differentiated visual features for different multi-modal examples. Based on the LaConv module, we further build the first fully language-driven convolution network, termed as LaConvNet, which can unify the visual recognition and multi-modal reasoning in one forward structure. To validate LaConv and LaConvNet, we conduct extensive experiments on four benchmark datasets of two vision-and-language tasks, i.e., visual question answering (VQA) and referring expression comprehension (REC). The experimental results not only shows the performance gains of LaConv compared to the existing multi-modal modules, but also witness the merits of LaConvNet as an unified network, including compact network, high generalization ability and excellent performance, e.g., +4.7% on RefCOCO+.
An attention-driven hierarchical multi-scale representation for visual recognition
Oct 23, 2021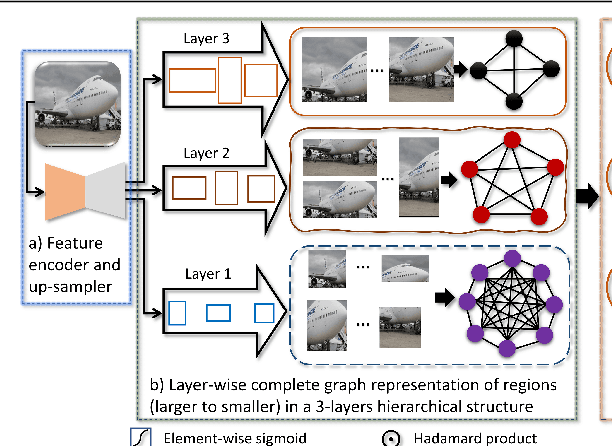
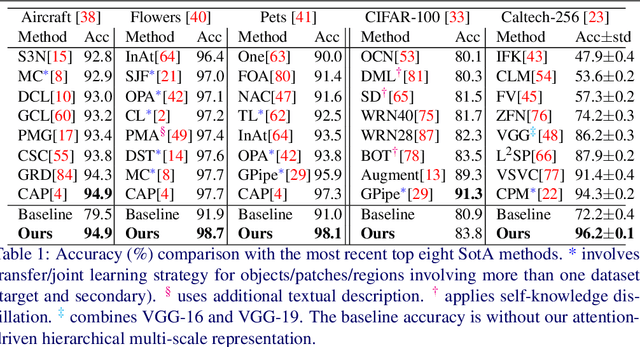
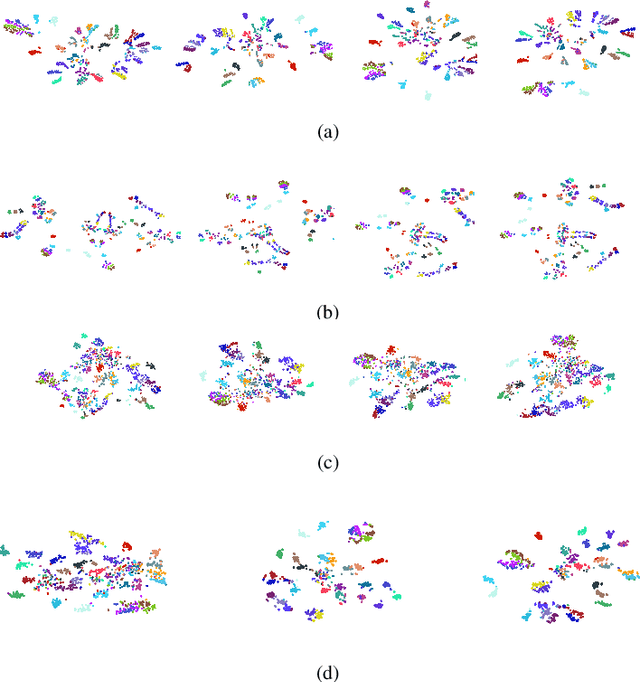

Convolutional Neural Networks (CNNs) have revolutionized the understanding of visual content. This is mainly due to their ability to break down an image into smaller pieces, extract multi-scale localized features and compose them to construct highly expressive representations for decision making. However, the convolution operation is unable to capture long-range dependencies such as arbitrary relations between pixels since it operates on a fixed-size window. Therefore, it may not be suitable for discriminating subtle changes (e.g. fine-grained visual recognition). To this end, our proposed method captures the high-level long-range dependencies by exploring Graph Convolutional Networks (GCNs), which aggregate information by establishing relationships among multi-scale hierarchical regions. These regions consist of smaller (closer look) to larger (far look), and the dependency between regions is modeled by an innovative attention-driven message propagation, guided by the graph structure to emphasize the neighborhoods of a given region. Our approach is simple yet extremely effective in solving both the fine-grained and generic visual classification problems. It outperforms the state-of-the-arts with a significant margin on three and is very competitive on other two datasets.
* Accepted in the 32nd British Machine Vision Conference (BMVC) 2021
Learning to Combine the Modalities of Language and Video for Temporal Moment Localization
Sep 07, 2021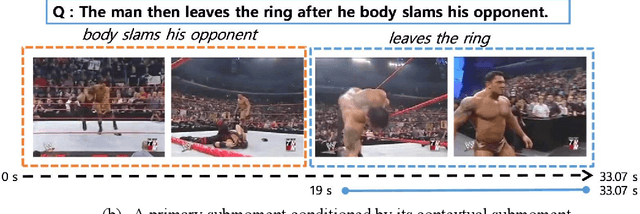

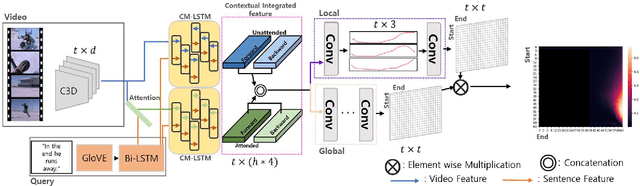
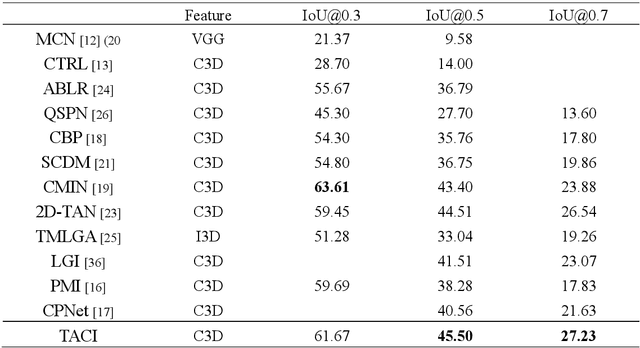
Temporal moment localization aims to retrieve the best video segment matching a moment specified by a query. The existing methods generate the visual and semantic embeddings independently and fuse them without full consideration of the long-term temporal relationship between them. To address these shortcomings, we introduce a novel recurrent unit, cross-modal long short-term memory (CM-LSTM), by mimicking the human cognitive process of localizing temporal moments that focuses on the part of a video segment related to the part of a query, and accumulates the contextual information across the entire video recurrently. In addition, we devise a two-stream attention mechanism for both attended and unattended video features by the input query to prevent necessary visual information from being neglected. To obtain more precise boundaries, we propose a two-stream attentive cross-modal interaction network (TACI) that generates two 2D proposal maps obtained globally from the integrated contextual features, which are generated by using CM-LSTM, and locally from boundary score sequences and then combines them into a final 2D map in an end-to-end manner. On the TML benchmark dataset, ActivityNet-Captions, the TACI outperform state-of-the-art TML methods with R@1 of 45.50% and 27.23% for IoU@0.5 and IoU@0.7, respectively. In addition, we show that the revised state-of-the-arts methods by replacing the original LSTM with our CM-LSTM achieve performance gains.
Uniform Information Segmentation
Nov 27, 2016

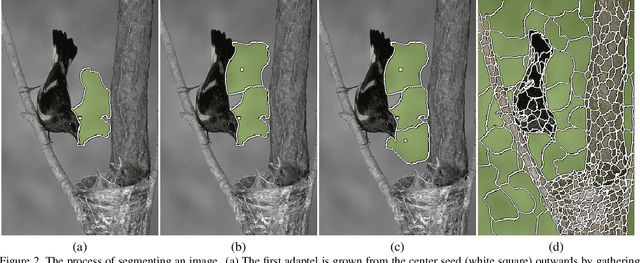
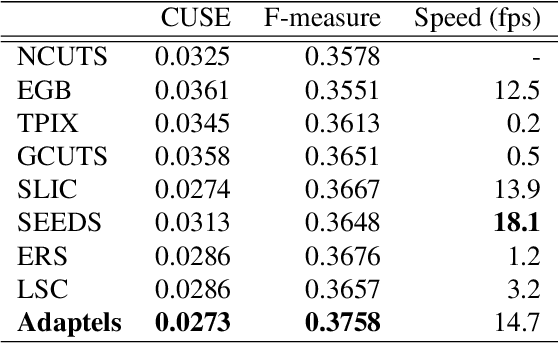
Size uniformity is one of the main criteria of superpixel methods. But size uniformity rarely conforms to the varying content of an image. The chosen size of the superpixels therefore represents a compromise - how to obtain the fewest superpixels without losing too much important detail. We propose that a more appropriate criterion for creating image segments is information uniformity. We introduce a novel method for segmenting an image based on this criterion. Since information is a natural way of measuring image complexity, our proposed algorithm leads to image segments that are smaller and denser in areas of high complexity and larger in homogeneous regions, thus simplifying the image while preserving its details. Our algorithm is simple and requires just one input parameter - a threshold on the information content. On segmentation comparison benchmarks it proves to be superior to the state-of-the-art. In addition, our method is computationally very efficient, approaching real-time performance, and is easily extensible to three-dimensional image stacks and video volumes.
Discriminative Latent Semantic Graph for Video Captioning
Aug 08, 2021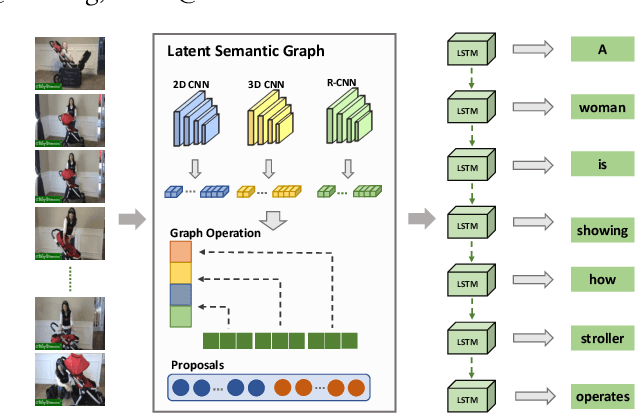
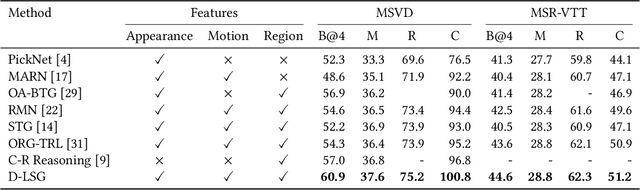
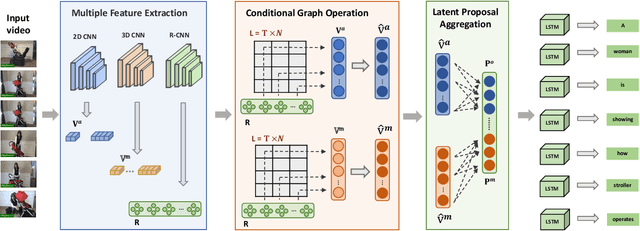
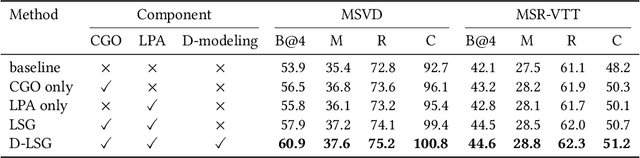
Video captioning aims to automatically generate natural language sentences that can describe the visual contents of a given video. Existing generative models like encoder-decoder frameworks cannot explicitly explore the object-level interactions and frame-level information from complex spatio-temporal data to generate semantic-rich captions. Our main contribution is to identify three key problems in a joint framework for future video summarization tasks. 1) Enhanced Object Proposal: we propose a novel Conditional Graph that can fuse spatio-temporal information into latent object proposal. 2) Visual Knowledge: Latent Proposal Aggregation is proposed to dynamically extract visual words with higher semantic levels. 3) Sentence Validation: A novel Discriminative Language Validator is proposed to verify generated captions so that key semantic concepts can be effectively preserved. Our experiments on two public datasets (MVSD and MSR-VTT) manifest significant improvements over state-of-the-art approaches on all metrics, especially for BLEU-4 and CIDEr. Our code is available at https://github.com/baiyang4/D-LSG-Video-Caption.
Nearly Optimal Algorithms for Level Set Estimation
Nov 02, 2021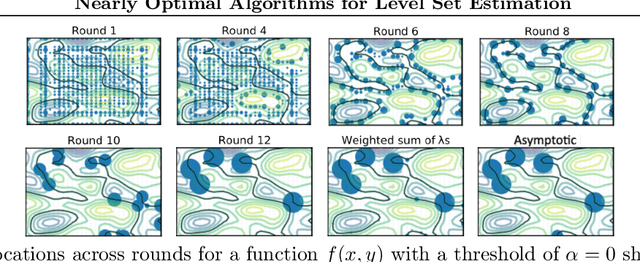

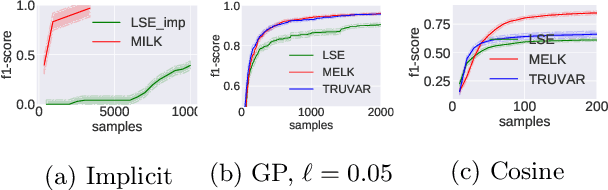
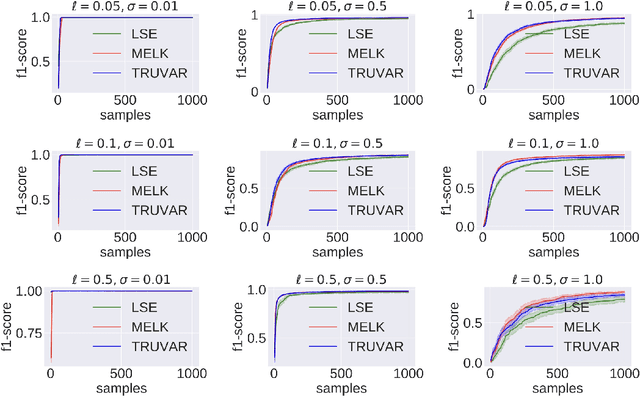
The level set estimation problem seeks to find all points in a domain ${\cal X}$ where the value of an unknown function $f:{\cal X}\rightarrow \mathbb{R}$ exceeds a threshold $\alpha$. The estimation is based on noisy function evaluations that may be acquired at sequentially and adaptively chosen locations in ${\cal X}$. The threshold value $\alpha$ can either be \emph{explicit} and provided a priori, or \emph{implicit} and defined relative to the optimal function value, i.e. $\alpha = (1-\epsilon)f(x_\ast)$ for a given $\epsilon > 0$ where $f(x_\ast)$ is the maximal function value and is unknown. In this work we provide a new approach to the level set estimation problem by relating it to recent adaptive experimental design methods for linear bandits in the Reproducing Kernel Hilbert Space (RKHS) setting. We assume that $f$ can be approximated by a function in the RKHS up to an unknown misspecification and provide novel algorithms for both the implicit and explicit cases in this setting with strong theoretical guarantees. Moreover, in the linear (kernel) setting, we show that our bounds are nearly optimal, namely, our upper bounds match existing lower bounds for threshold linear bandits. To our knowledge this work provides the first instance-dependent, non-asymptotic upper bounds on sample complexity of level-set estimation that match information theoretic lower bounds.
Stereo Video Reconstruction Without Explicit Depth Maps for Endoscopic Surgery
Sep 16, 2021
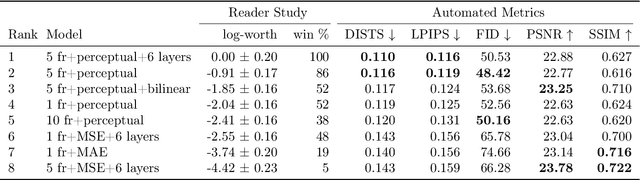
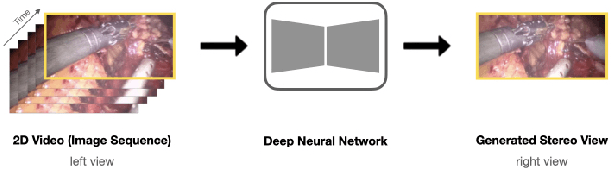
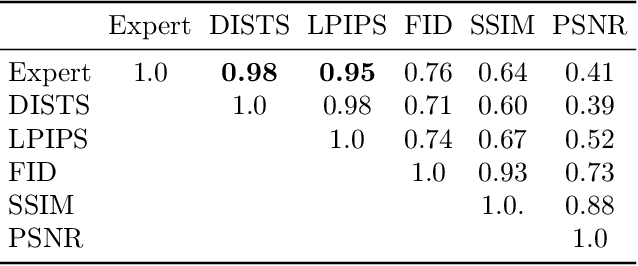
We introduce the task of stereo video reconstruction or, equivalently, 2D-to-3D video conversion for minimally invasive surgical video. We design and implement a series of end-to-end U-Net-based solutions for this task by varying the input (single frame vs. multiple consecutive frames), loss function (MSE, MAE, or perceptual losses), and network architecture. We evaluate these solutions by surveying ten experts - surgeons who routinely perform endoscopic surgery. We run two separate reader studies: one evaluating individual frames and the other evaluating fully reconstructed 3D video played on a VR headset. In the first reader study, a variant of the U-Net that takes as input multiple consecutive video frames and outputs the missing view performs best. We draw two conclusions from this outcome. First, motion information coming from multiple past frames is crucial in recreating stereo vision. Second, the proposed U-Net variant can indeed exploit such motion information for solving this task. The result from the second study further confirms the effectiveness of the proposed U-Net variant. The surgeons reported that they could successfully perceive depth from the reconstructed 3D video clips. They also expressed a clear preference for the reconstructed 3D video over the original 2D video. These two reader studies strongly support the usefulness of the proposed task of stereo reconstruction for minimally invasive surgical video and indicate that deep learning is a promising approach to this task. Finally, we identify two automatic metrics, LPIPS and DISTS, that are strongly correlated with expert judgement and that could serve as proxies for the latter in future studies.