 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Superpixel Graph Transformer with Metadata for Skin Lesion Classification
Jun 18, 2026Automated skin cancer classification from dermoscopic images remains challenging due to heterogeneous lesion structure, strong intra-class variability, and subtle visual differences between benign and malignant cases. Existing CNN/ViT pipelines typically rely on global or patch-level features and often combine patient metadata via late fusion, which limits spatially grounded multimodal reasoning. We present a novel region-based graph learning framework that explicitly models lesions as graphs of spatially coherent superpixel regions represented as frozen CNN features. To capture fine-grained lesion arrangements, we encode inter-regional geometry as edge attributes and introduce a dedicated metadata context node connected to all regions, providing structured integration of demographic/clinical variables within the same relational space. Node representations are updated using our edge-aware graph transformer followed by attention-driven propagation, and a final graph-level embedding for benign-malignant classification. Experiments on four public benchmarks demonstrate that explicit region-level relational modeling and graph-native multimodal fusion yield consistent gains over the state-of-the-art. Consequently, we establish a new graph-centric perspective in which CNN features are modeled as relational nodes and improved through contextual integration, yielding more expressive and robust classifications.
Towards Label-Free Single-Cell Phenotyping Using Multi-Task Learning
May 14, 2026Label-free single-cell imaging offers a scalable, non-invasive alternative to fluorescence-based cytometry, yet inferring molecular phenotypes directly from bright-field morphology remains challenging. We present a unified Deep Learning (DL) framework that jointly performs White Blood Cell (WBC) classification and continuous protein-expression regression from label-free Differential Phase Contrast (DPC) images. Our model employs a Hybrid architecture that fuses convolutional fine-grained texture features with transformer-based global representations through a learnable cross-branch gating module, enabling robust morpho-molecular inference from DPC images. To support downstream interpretability, we further incorporate a Large Language Model (LLM) that generates concise, biologically grounded summaries of the predicted cell states. Experiments on the Berkeley Single Cell Computational Microscopy (BSCCM) and Blood Cells Image benchmarks demonstrate strong performance, achieving a 91.3% WBC classification accuracy and a 0.72 Pearson correlation for CD16 expression regression on BSCCM. These results underscore the promise of label-free single-cell imaging for cost-effective hematological profiling, enabling simultaneous phenotype identification and quantitative biomarker estimation without fluorescent staining. The source code is available at https://github.com/saqibnaziir/Single-Cell-Phenotyping.
TAG-Head: Time-Aligned Graph Head for Plug-and-Play Fine-grained Action Recognition
Apr 13, 2026Fine-grained human action recognition (FHAR) is challenging because visually similar actions differ by subtle spatio-temporal cues. Many recent systems enhance discriminability with extra modalities (e.g., pose, text, optical flow), but this increases annotation burden and computational cost. We introduce TAG-Head, a lightweight spatio-temporal graph head that upgrades standard 3D backbones (SlowFast, R(2+1)D-34, I3D, etc.) for FHAR using RGB only. Our pipeline first applies a Transformer encoder with learnable 3D positional encodings to the backbone tokens, capturing long-range dependencies across space and time. The resulting features are then refined by a graph in which (i) fully-connected intra-frame edges to resolve subtle appearance differences within frames, and (ii) time-aligned temporal edges that connect features at the same spatial location across frames to stabilise motion cues without over-smoothing. The head is compact (little parameter/FLOP overhead), plug-and-play across backbones, and trained end-to-end with the backbone. Extensive evaluations on FineGym (Gym99 and Gym288) and HAA500 show that TAG-Head sets a new state-of-the-art among RGB-only models and surpasses many recent multimodal approaches (video + pose + text) that rely on privileged information. Ablations disentangle the contributions of the Transformer and the graph topology, and complexity analyses confirm low latency. TAG-Head advances FHAR by explicitly coupling global context with high-resolution spatial interactions and low-variance temporal continuity inside a slim, composable graph head. The simplicity of the design enables straightforward adoption in practical systems that favour RGB-only sensors, while delivering performance gains typically associated with heavier or multimodal models. Code will be released on GitHub.
HistDiT: A Structure-Aware Latent Conditional Diffusion Model for High-Fidelity Virtual Staining in Histopathology
Apr 09, 2026Immunohistochemistry (IHC) is essential for assessing specific immune biomarkers like Human Epidermal growth-factor Receptor 2 (HER2) in breast cancer. However, the traditional protocols of obtaining IHC stains are resource-intensive, time-consuming, and prone to structural damages. Virtual staining has emerged as a scalable alternative, but it faces significant challenges in preserving fine-grained cellular structures while accurately translating biochemical expressions. Current state-of-the-art methods still rely on Generative Adversarial Networks (GANs) or standard convolutional U-Net diffusion models that often struggle with "structure and staining trade-offs". The generated samples are either structurally relevant but blurry, or texturally realistic but have artifacts that compromise their diagnostic use. In this paper, we introduce HistDiT, a novel latent conditional Diffusion Transformer (DiT) architecture that establishes a new benchmark for visual fidelity in virtual histological staining. The novelty introduced in this work is, a) the Dual-Stream Conditioning strategy that explicitly maintains a balance between spatial constraints via VAE-encoded latents and semantic phenotype guidance via UNI embeddings; b) the multi-objective loss function that contributes to sharper images with clear morphological structure; and c) the use of the Structural Correlation Metric (SCM) to focus on the core morphological structure for precise assessment of sample quality. Consequently, our model outperforms existing baselines, as demonstrated through rigorous quantitative and qualitative evaluations.
Training-Only Heterogeneous Image-Patch-Text Graph Supervision for Advancing Few-Shot Learning Adapters
Mar 18, 2026Recent adapter-based CLIP tuning (e.g., Tip-Adapter) is a strong few-shot learner, achieving efficiency by caching support features for fast prototype matching. However, these methods rely on global uni-modal feature vectors, overlooking fine-grained patch relations and their structural alignment with class text. To bridge this gap without incurring inference costs, we introduce a novel asymmetric training-only framework. Instead of altering the lightweight adapter, we construct a high-capacity auxiliary Heterogeneous Graph Teacher that operates solely during training. This teacher (i) integrates multi-scale visual patches and text prompts into a unified graph, (ii) performs deep cross-modal reasoning via a Modality-aware Graph Transformer (MGT), and (iii) applies discriminative node filtering to extract high-fidelity class features. Crucially, we employ a cache-aware dual-objective strategy to supervise this relational knowledge directly into the Tip-Adapter's key-value cache, effectively upgrading the prototypes while the graph teacher is discarded at test time. Thus, inference remains identical to Tip-Adapter with zero extra latency or memory. Across standard 1-16-shot benchmarks, our method consistently establishes a new state-of-the-art. Ablations confirm that the auxiliary graph supervision, text-guided reasoning, and node filtering are the essential ingredients for robust few-shot adaptation. Code is available at https://github.com/MR-Sherif/TOGA.git.
Advancing Cache-Based Few-Shot Classification via Patch-Driven Relational Gated Graph Attention
Dec 13, 2025Few-shot image classification remains difficult under limited supervision and visual domain shift. Recent cache-based adaptation approaches (e.g., Tip-Adapter) address this challenge to some extent by learning lightweight residual adapters over frozen features, yet they still inherit CLIP's tendency to encode global, general-purpose representations that are not optimally discriminative to adapt the generalist to the specialist's domain in low-data regimes. We address this limitation with a novel patch-driven relational refinement that learns cache adapter weights from intra-image patch dependencies rather than treating an image embedding as a monolithic vector. Specifically, we introduce a relational gated graph attention network that constructs a patch graph and performs edge-aware attention to emphasize informative inter-patch interactions, producing context-enriched patch embeddings. A learnable multi-aggregation pooling then composes these into compact, task-discriminative representations that better align cache keys with the target few-shot classes. Crucially, the proposed graph refinement is used only during training to distil relational structure into the cache, incurring no additional inference cost beyond standard cache lookup. Final predictions are obtained by a residual fusion of cache similarity scores with CLIP zero-shot logits. Extensive evaluations on 11 benchmarks show consistent gains over state-of-the-art CLIP adapter and cache-based baselines while preserving zero-shot efficiency. We further validate battlefield relevance by introducing an Injured vs. Uninjured Soldier dataset for casualty recognition. It is motivated by the operational need to support triage decisions within the "platinum minutes" and the broader "golden hour" window in time-critical UAV-driven search-and-rescue and combat casualty care.
High-Order Evolving Graphs for Enhanced Representation of Traffic Dynamics
Sep 18, 2024



We present an innovative framework for traffic dynamics analysis using High-Order Evolving Graphs, designed to improve spatio-temporal representations in autonomous driving contexts. Our approach constructs temporal bidirectional bipartite graphs that effectively model the complex interactions within traffic scenes in real-time. By integrating Graph Neural Networks (GNNs) with high-order multi-aggregation strategies, we significantly enhance the modeling of traffic scene dynamics, providing a more accurate and detailed analysis of these interactions. Additionally, we incorporate inductive learning techniques inspired by the GraphSAGE framework, enabling our model to adapt to new and unseen traffic scenarios without the need for retraining, thus ensuring robust generalization. Through extensive experiments on the ROAD and ROAD Waymo datasets, we establish a comprehensive baseline for further developments, demonstrating the potential of our method in accurately capturing traffic behavior. Our results emphasize the value of high-order statistical moments and feature-gated attention mechanisms in improving traffic behavior analysis, laying the groundwork for advancing autonomous driving technologies. Our source code is available at: https://github.com/Addy-1998/High_Order_Graphs
SR-GNN: Spatial Relation-aware Graph Neural Network for Fine-Grained Image Categorization
Sep 05, 2022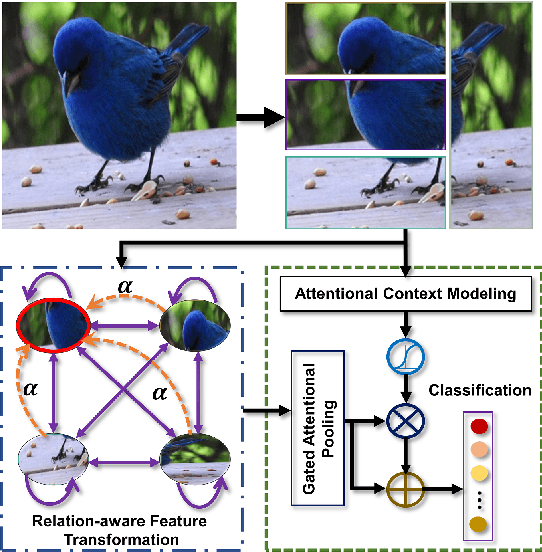
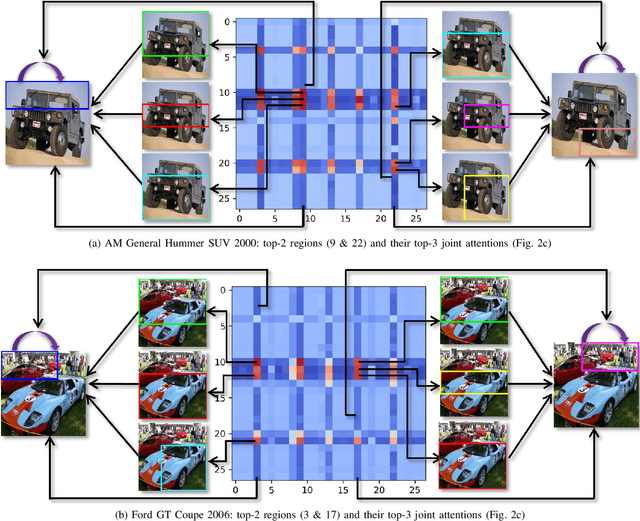
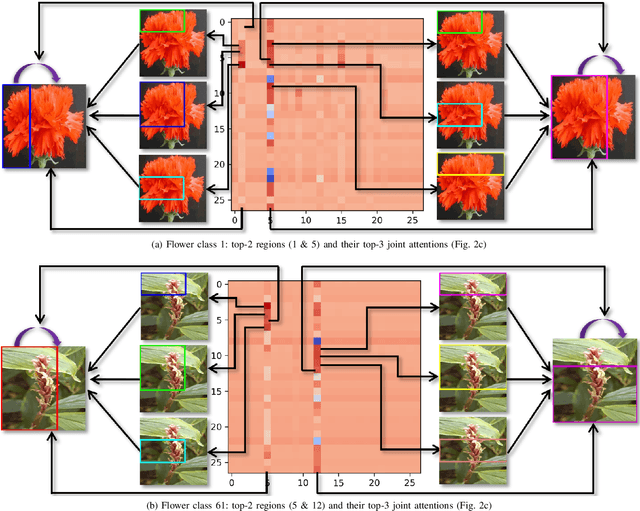
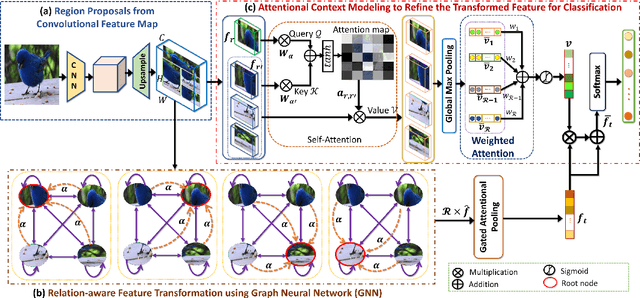
Over the past few years, a significant progress has been made in deep convolutional neural networks (CNNs)-based image recognition. This is mainly due to the strong ability of such networks in mining discriminative object pose and parts information from texture and shape. This is often inappropriate for fine-grained visual classification (FGVC) since it exhibits high intra-class and low inter-class variances due to occlusions, deformation, illuminations, etc. Thus, an expressive feature representation describing global structural information is a key to characterize an object/ scene. To this end, we propose a method that effectively captures subtle changes by aggregating context-aware features from most relevant image-regions and their importance in discriminating fine-grained categories avoiding the bounding-box and/or distinguishable part annotations. Our approach is inspired by the recent advancement in self-attention and graph neural networks (GNNs) approaches to include a simple yet effective relation-aware feature transformation and its refinement using a context-aware attention mechanism to boost the discriminability of the transformed feature in an end-to-end learning process. Our model is evaluated on eight benchmark datasets consisting of fine-grained objects and human-object interactions. It outperforms the state-of-the-art approaches by a significant margin in recognition accuracy.
Retinal Structure Detection in OCTA Image via Voting-based Multi-task Learning
Aug 23, 2022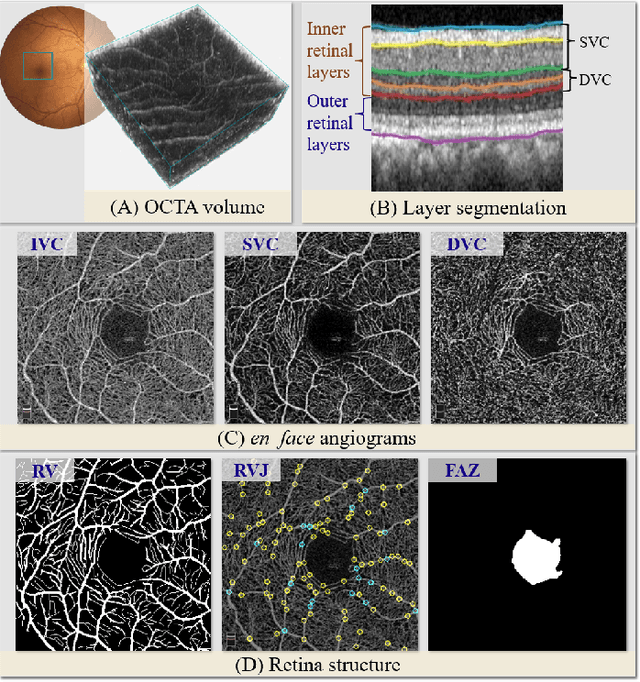
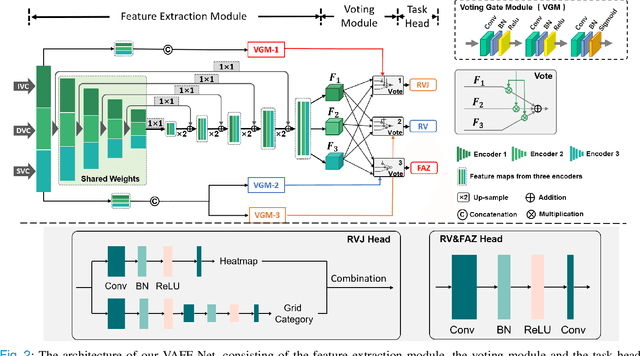
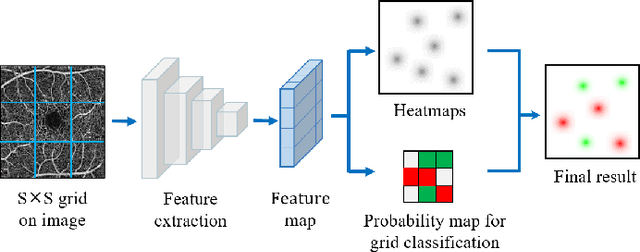
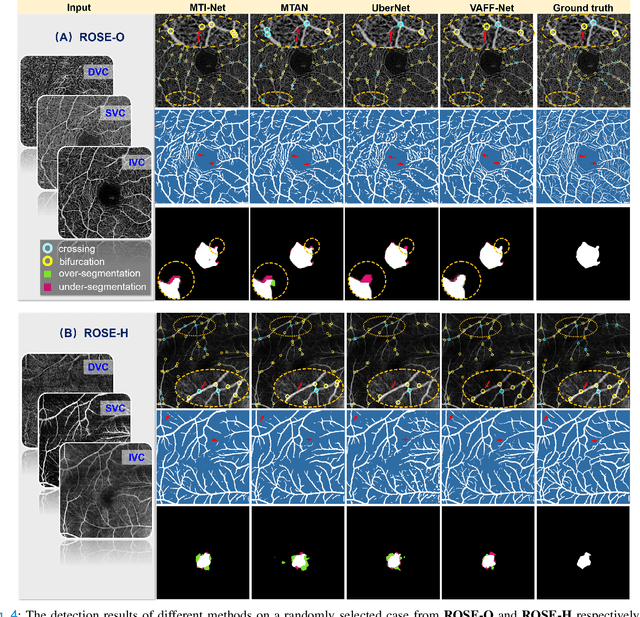
Automated detection of retinal structures, such as retinal vessels (RV), the foveal avascular zone (FAZ), and retinal vascular junctions (RVJ), are of great importance for understanding diseases of the eye and clinical decision-making. In this paper, we propose a novel Voting-based Adaptive Feature Fusion multi-task network (VAFF-Net) for joint segmentation, detection, and classification of RV, FAZ, and RVJ in optical coherence tomography angiography (OCTA). A task-specific voting gate module is proposed to adaptively extract and fuse different features for specific tasks at two levels: features at different spatial positions from a single encoder, and features from multiple encoders. In particular, since the complexity of the microvasculature in OCTA images makes simultaneous precise localization and classification of retinal vascular junctions into bifurcation/crossing a challenging task, we specifically design a task head by combining the heatmap regression and grid classification. We take advantage of three different \textit{en face} angiograms from various retinal layers, rather than following existing methods that use only a single \textit{en face}. To facilitate further research, part of these datasets with the source code and evaluation benchmark have been released for public access:https://github.com/iMED-Lab/VAFF-Net.
Benchmarking Deep Reinforcement Learning Algorithms for Vision-based Robotics
Jan 11, 2022
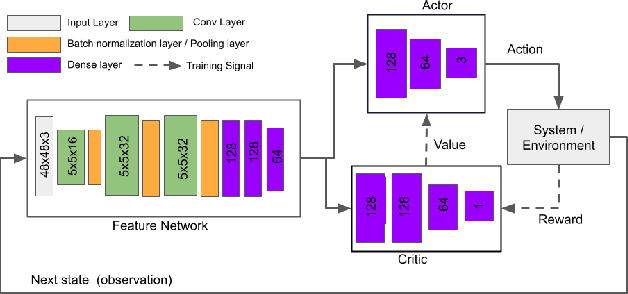
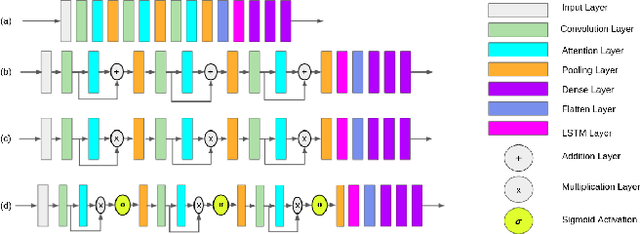
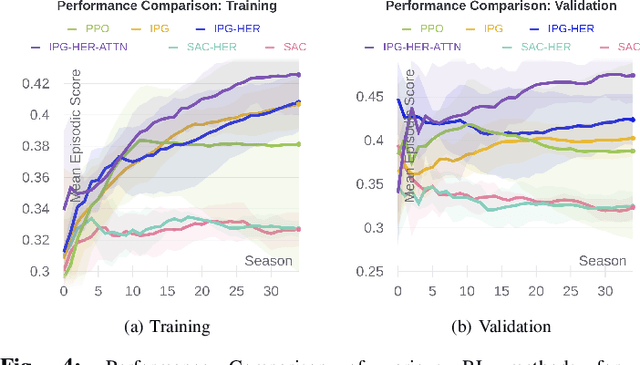
This paper presents a benchmarking study of some of the state-of-the-art reinforcement learning algorithms used for solving two simulated vision-based robotics problems. The algorithms considered in this study include soft actor-critic (SAC), proximal policy optimization (PPO), interpolated policy gradients (IPG), and their variants with Hindsight Experience replay (HER). The performances of these algorithms are compared against PyBullet's two simulation environments known as KukaDiverseObjectEnv and RacecarZEDGymEnv respectively. The state observations in these environments are available in the form of RGB images and the action space is continuous, making them difficult to solve. A number of strategies are suggested to provide intermediate hindsight goals required for implementing HER algorithm on these problems which are essentially single-goal environments. In addition, a number of feature extraction architectures are proposed to incorporate spatial and temporal attention in the learning process. Through rigorous simulation experiments, the improvement achieved with these components are established. To the best of our knowledge, such a benchmarking study is not available for the above two vision-based robotics problems making it a novel contribution in the field.