 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Combine the Modalities of Language and Video for Temporal Moment Localization
Paper and Code
Sep 07, 2021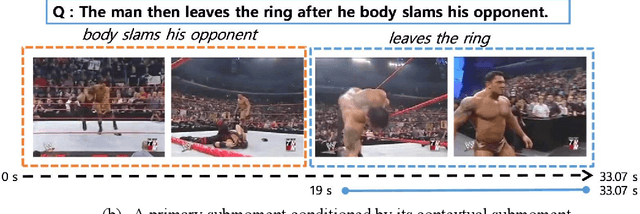

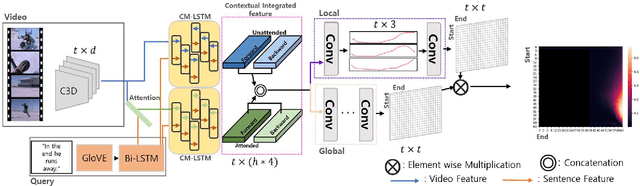
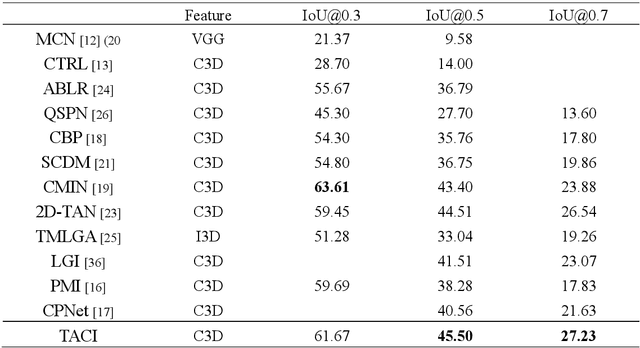
Temporal moment localization aims to retrieve the best video segment matching a moment specified by a query. The existing methods generate the visual and semantic embeddings independently and fuse them without full consideration of the long-term temporal relationship between them. To address these shortcomings, we introduce a novel recurrent unit, cross-modal long short-term memory (CM-LSTM), by mimicking the human cognitive process of localizing temporal moments that focuses on the part of a video segment related to the part of a query, and accumulates the contextual information across the entire video recurrently. In addition, we devise a two-stream attention mechanism for both attended and unattended video features by the input query to prevent necessary visual information from being neglected. To obtain more precise boundaries, we propose a two-stream attentive cross-modal interaction network (TACI) that generates two 2D proposal maps obtained globally from the integrated contextual features, which are generated by using CM-LSTM, and locally from boundary score sequences and then combines them into a final 2D map in an end-to-end manner. On the TML benchmark dataset, ActivityNet-Captions, the TACI outperform state-of-the-art TML methods with R@1 of 45.50% and 27.23% for IoU@0.5 and IoU@0.7, respectively. In addition, we show that the revised state-of-the-arts methods by replacing the original LSTM with our CM-LSTM achieve performance gains.