 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Learning Based Domain Adaptation for Robust Speaker Verification
Aug 31, 2021
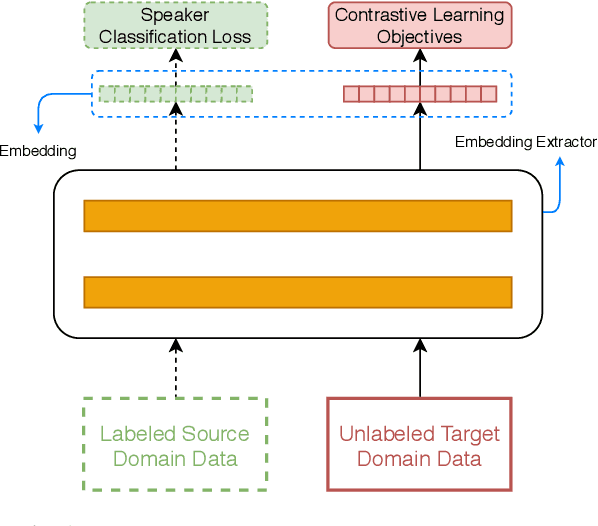

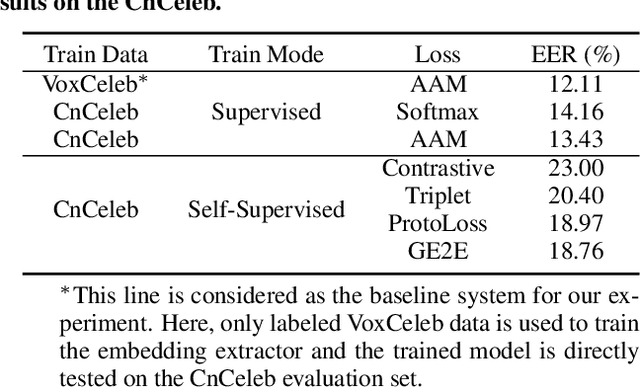
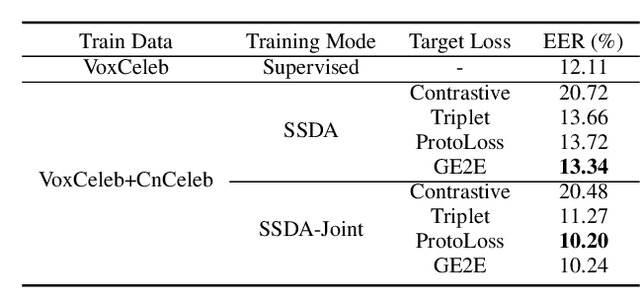
Large performance degradation is often observed for speaker ver-ification systems when applied to a new domain dataset. Givenan unlabeled target-domain dataset, unsupervised domain adaptation(UDA) methods, which usually leverage adversarial training strate-gies, are commonly used to bridge the performance gap caused bythe domain mismatch. However, such adversarial training strategyonly uses the distribution information of target domain data and cannot ensure the performance improvement on the target domain. Inthis paper, we incorporate self-supervised learning strategy to the un-supervised domain adaptation system and proposed a self-supervisedlearning based domain adaptation approach (SSDA). Compared tothe traditional UDA method, the new SSDA training strategy canfully leverage the potential label information from target domainand adapt the speaker discrimination ability from source domainsimultaneously. We evaluated the proposed approach on the Vox-Celeb (labeled source domain) and CnCeleb (unlabeled target do-main) datasets, and the best SSDA system obtains 10.2% Equal ErrorRate (EER) on the CnCeleb dataset without using any speaker labelson CnCeleb, which also can achieve the state-of-the-art results onthis corpus.
Demystifying Deep Learning Models for Retinal OCT Disease Classification using Explainable AI
Nov 06, 2021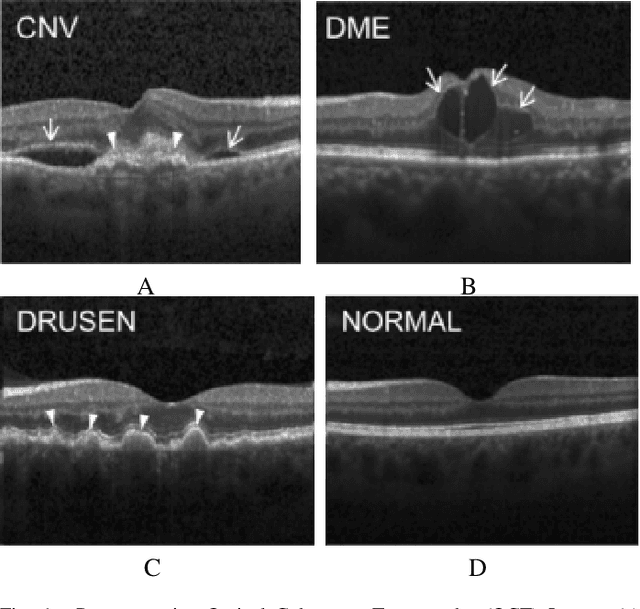
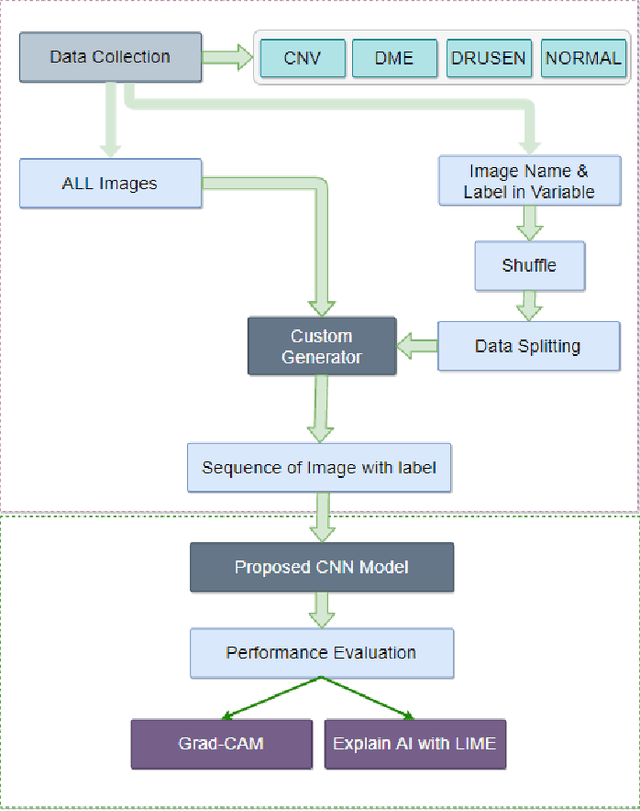
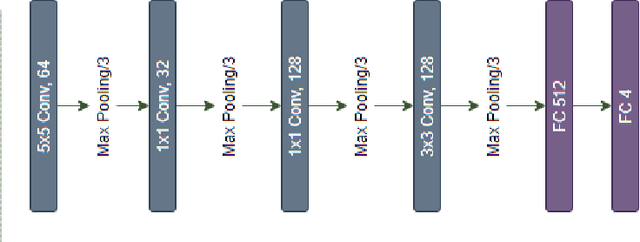
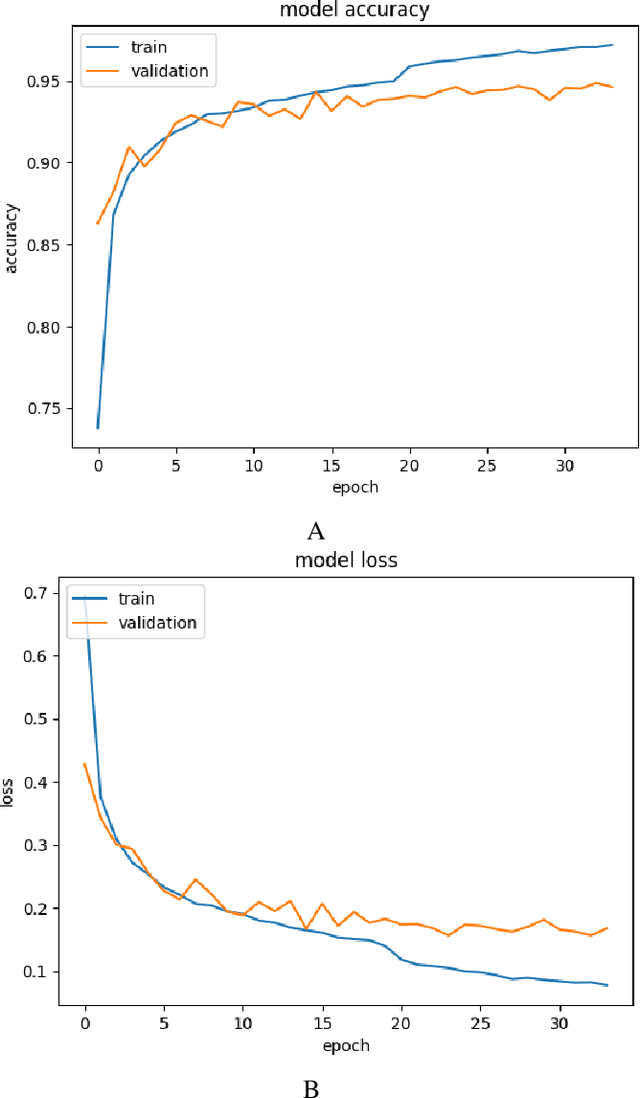
In the world of medical diagnostics, the adoption of various deep learning techniques is quite common as well as effective, and its statement is equally true when it comes to implementing it into the retina Optical Coherence Tomography (OCT) sector, but (i)These techniques have the black box characteristics that prevent the medical professionals to completely trust the results generated from them (ii)Lack of precision of these methods restricts their implementation in clinical and complex cases (iii)The existing works and models on the OCT classification are substantially large and complicated and they require a considerable amount of memory and computational power, reducing the quality of classifiers in real-time applications. To meet these problems, in this paper a self-developed CNN model has been proposed which is comparatively smaller and simpler along with the use of Lime that introduces Explainable AI to the study and helps to increase the interpretability of the model. This addition will be an asset to the medical experts for getting major and detailed information and will help them in making final decisions and will also reduce the opacity and vulnerability of the conventional deep learning models.
HRFormer: High-Resolution Transformer for Dense Prediction
Oct 18, 2021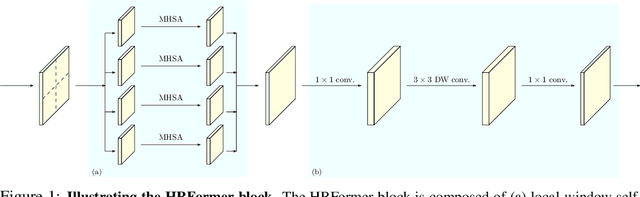
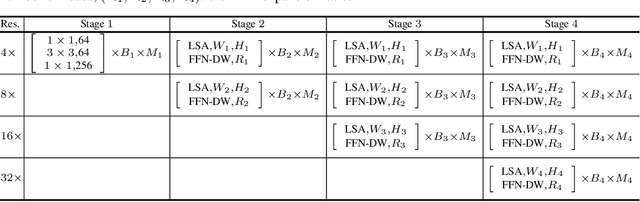


We present a High-Resolution Transformer (HRT) that learns high-resolution representations for dense prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations and has high memory and computational cost. We take advantage of the multi-resolution parallel design introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention that performs self-attention over small non-overlapping image windows, for improving the memory and computation efficiency. In addition, we introduce a convolution into the FFN to exchange information across the disconnected image windows. We demonstrate the effectiveness of the High-Resolution Transformer on both human pose estimation and semantic segmentation tasks, e.g., HRT outperforms Swin transformer by $1.3$ AP on COCO pose estimation with $50\%$ fewer parameters and $30\%$ fewer FLOPs. Code is available at: https://github.com/HRNet/HRFormer.
End to end hyperspectral imaging system with coded compression imaging process
Sep 06, 2021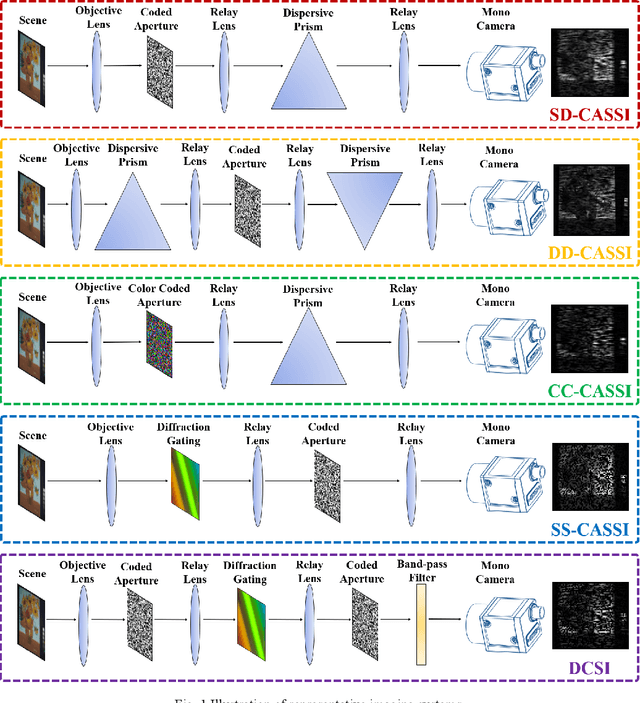
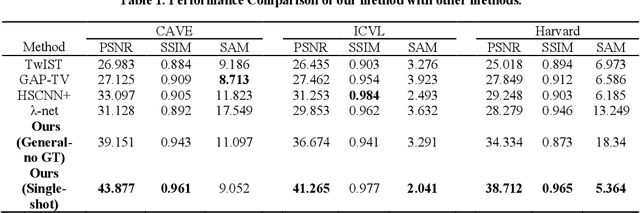
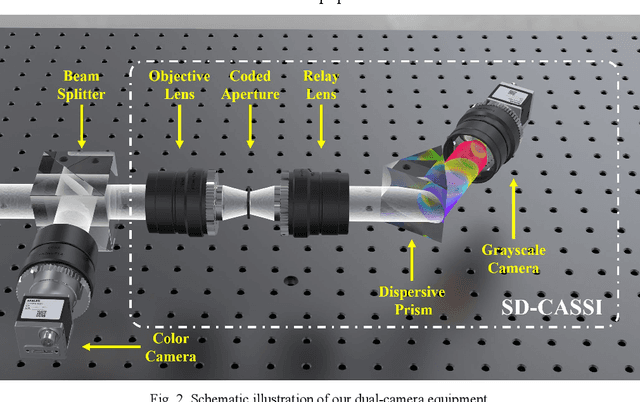

Hyperspectral images (HSIs) can provide rich spatial and spectral information with extensive application prospects. Recently, several methods using convolutional neural networks (CNNs) to reconstruct HSIs have been developed. However, most deep learning methods fit a brute-force mapping relationship between the compressive and standard HSIs. Thus, the learned mapping would be invalid when the observation data deviate from the training data. To recover the three-dimensional HSIs from two-dimensional compressive images, we present dual-camera equipment with a physics-informed self-supervising CNN method based on a coded aperture snapshot spectral imaging system. Our method effectively exploits the spatial-spectral relativization from the coded spectral information and forms a self-supervising system based on the camera quantum effect model. The experimental results show that our method can be adapted to a wide imaging environment with good performance. In addition, compared with most of the network-based methods, our system does not require a dedicated dataset for pre-training. Therefore, it has greater scenario adaptability and better generalization ability. Meanwhile, our system can be constantly fine-tuned and self-improved in real-life scenarios.
Exposing Length Divergence Bias of Textual Matching Models
Sep 06, 2021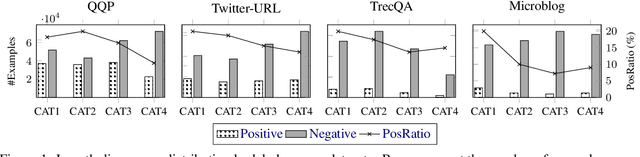

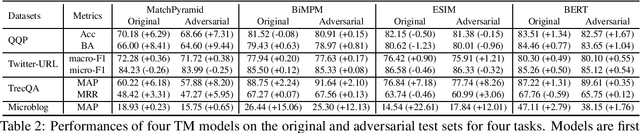
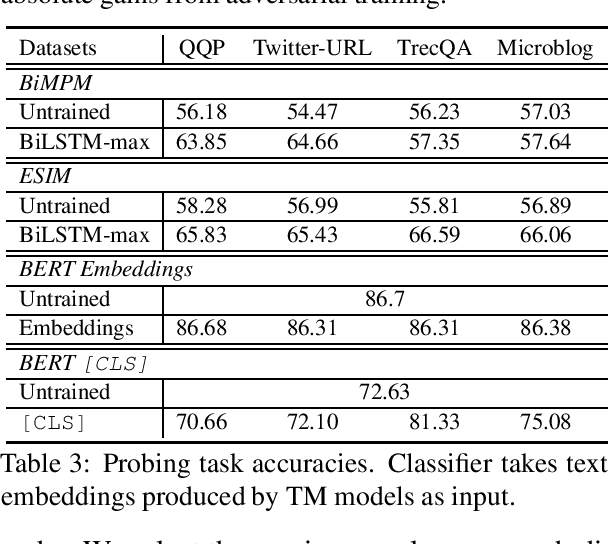
Despite the remarkable success deep models have achieved in Textual Matching (TM), their robustness issue is still a topic of concern. In this work, we propose a new perspective to study this issue -- via the length divergence bias of TM models. We conclude that this bias stems from two parts: the label bias of existing TM datasets and the sensitivity of TM models to superficial information. We critically examine widely used TM datasets, and find that all of them follow specific length divergence distributions by labels, providing direct cues for predictions. As for the TM models, we conduct adversarial evaluation and show that all models' performances drop on the out-of-distribution adversarial test sets we construct, which demonstrates that they are all misled by biased training sets. This is also confirmed by the \textit{SentLen} probing task that all models capture rich length information during training to facilitate their performances. Finally, to alleviate the length divergence bias in TM models, we propose a practical adversarial training method using bias-free training data. Our experiments indicate that we successfully improve the robustness and generalization ability of models at the same time.
Updating Embeddings for Dynamic Knowledge Graphs
Sep 22, 2021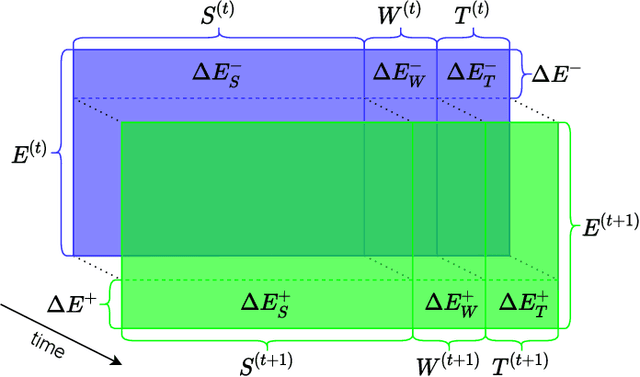
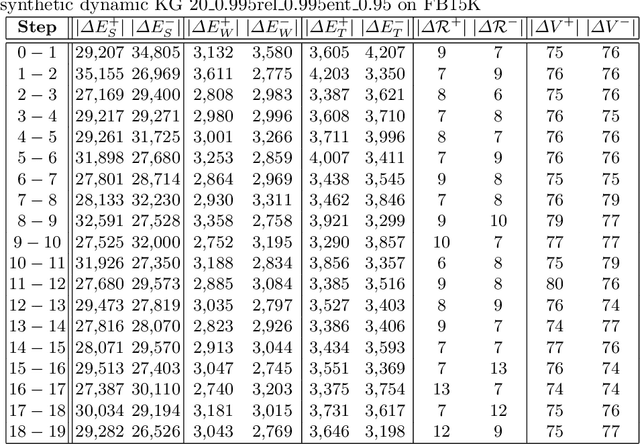
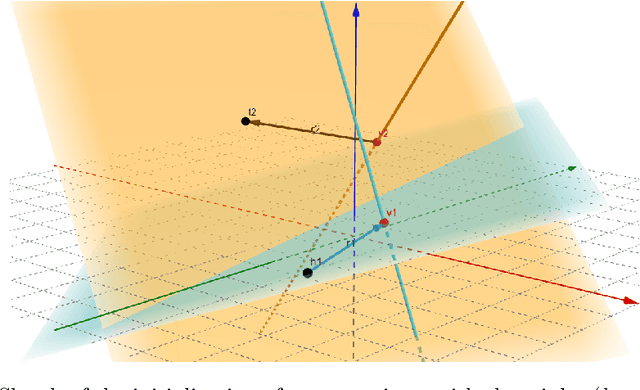
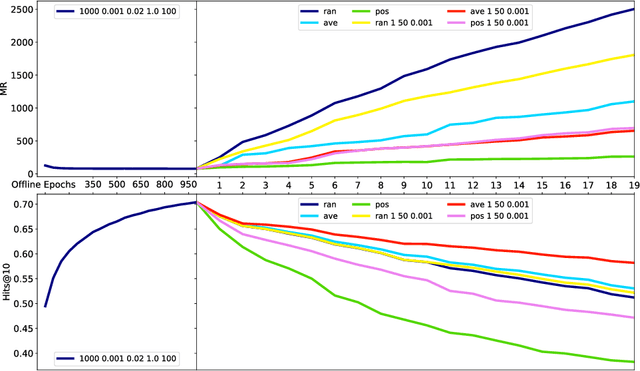
Data in Knowledge Graphs often represents part of the current state of the real world. Thus, to stay up-to-date the graph data needs to be updated frequently. To utilize information from Knowledge Graphs, many state-of-the-art machine learning approaches use embedding techniques. These techniques typically compute an embedding, i.e., vector representations of the nodes as input for the main machine learning algorithm. If a graph update occurs later on -- specifically when nodes are added or removed -- the training has to be done all over again. This is undesirable, because of the time it takes and also because downstream models which were trained with these embeddings have to be retrained if they change significantly. In this paper, we investigate embedding updates that do not require full retraining and evaluate them in combination with various embedding models on real dynamic Knowledge Graphs covering multiple use cases. We study approaches that place newly appearing nodes optimally according to local information, but notice that this does not work well. However, we find that if we continue the training of the old embedding, interleaved with epochs during which we only optimize for the added and removed parts, we obtain good results in terms of typical metrics used in link prediction. This performance is obtained much faster than with a complete retraining and hence makes it possible to maintain embeddings for dynamic Knowledge Graphs.
Revealing and Protecting Labels in Distributed Training
Oct 31, 2021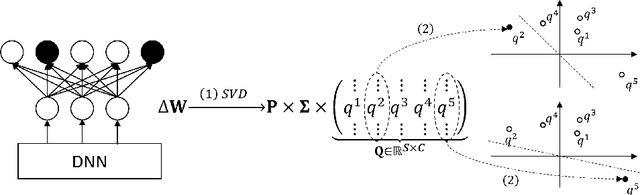
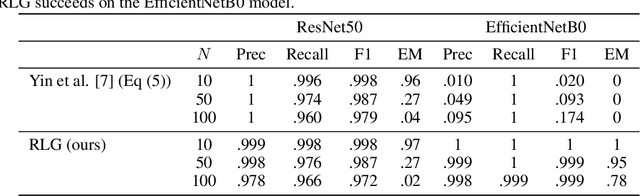
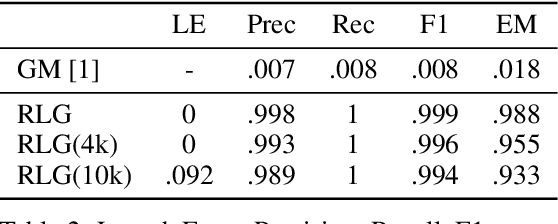
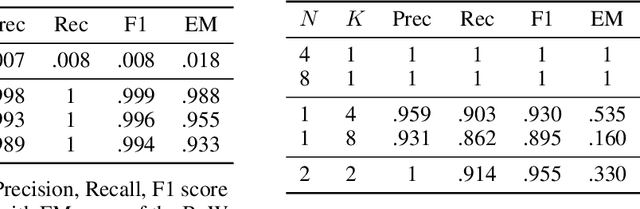
Distributed learning paradigms such as federated learning often involve transmission of model updates, or gradients, over a network, thereby avoiding transmission of private data. However, it is possible for sensitive information about the training data to be revealed from such gradients. Prior works have demonstrated that labels can be revealed analytically from the last layer of certain models (e.g., ResNet), or they can be reconstructed jointly with model inputs by using Gradients Matching [Zhu et al'19] with additional knowledge about the current state of the model. In this work, we propose a method to discover the set of labels of training samples from only the gradient of the last layer and the id to label mapping. Our method is applicable to a wide variety of model architectures across multiple domains. We demonstrate the effectiveness of our method for model training in two domains - image classification, and automatic speech recognition. Furthermore, we show that existing reconstruction techniques improve their efficacy when used in conjunction with our method. Conversely, we demonstrate that gradient quantization and sparsification can significantly reduce the success of the attack.
Efficient Federated Learning for AIoT Applications Using Knowledge Distillation
Nov 29, 2021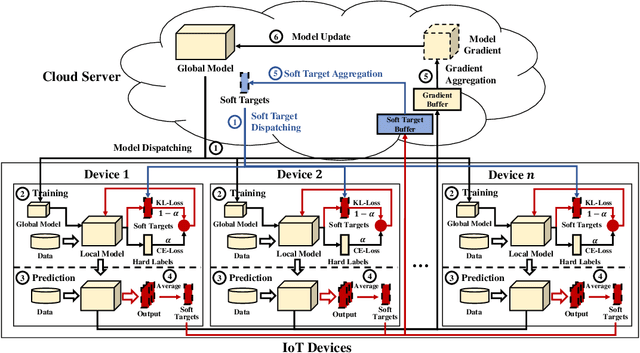
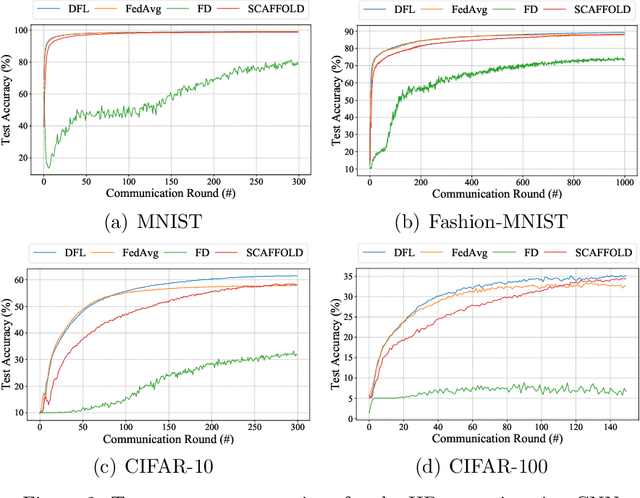
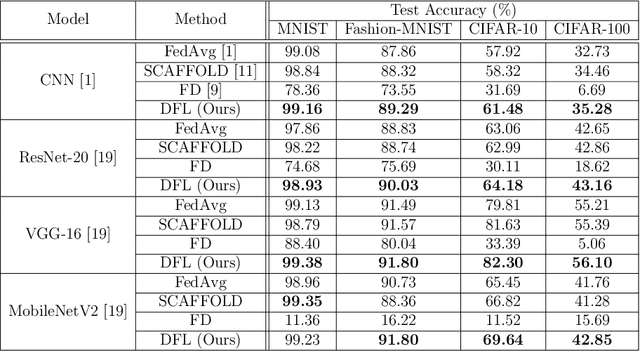
As a promising distributed machine learning paradigm, Federated Learning (FL) trains a central model with decentralized data without compromising user privacy, which has made it widely used by Artificial Intelligence Internet of Things (AIoT) applications. However, the traditional FL suffers from model inaccuracy since it trains local models using hard labels of data and ignores useful information of incorrect predictions with small probabilities. Although various solutions try to tackle the bottleneck of the traditional FL, most of them introduce significant communication and memory overhead, making the deployment of large-scale AIoT devices a great challenge. To address the above problem, this paper presents a novel Distillation-based Federated Learning (DFL) architecture that enables efficient and accurate FL for AIoT applications. Inspired by Knowledge Distillation (KD) that can increase the model accuracy, our approach adds the soft targets used by KD to the FL model training, which occupies negligible network resources. The soft targets are generated by local sample predictions of each AIoT device after each round of local training and used for the next round of model training. During the local training of DFL, both soft targets and hard labels are used as approximation objectives of model predictions to improve model accuracy by supplementing the knowledge of soft targets. To further improve the performance of our DFL model, we design a dynamic adjustment strategy for tuning the ratio of two loss functions used in KD, which can maximize the use of both soft targets and hard labels. Comprehensive experimental results on well-known benchmarks show that our approach can significantly improve the model accuracy of FL with both Independent and Identically Distributed (IID) and non-IID data.
A Deep Reinforcement Learning Approach for Audio-based Navigation and Audio Source Localization in Multi-speaker Environments
Oct 25, 2021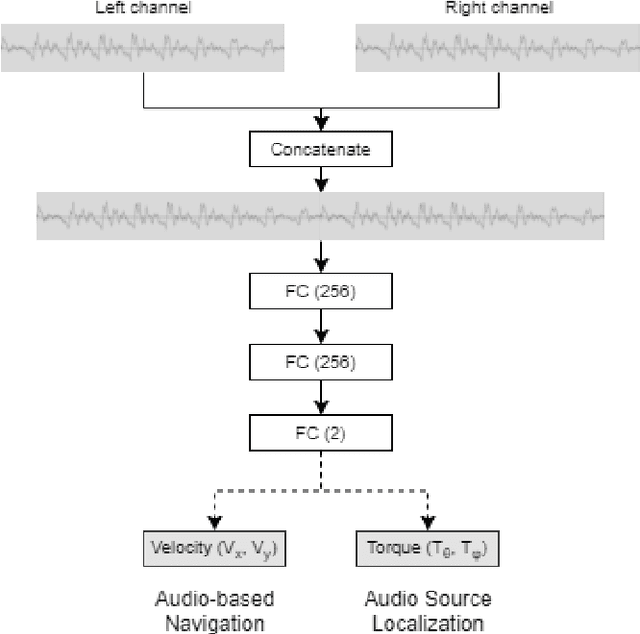
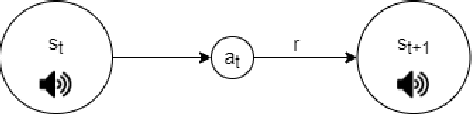
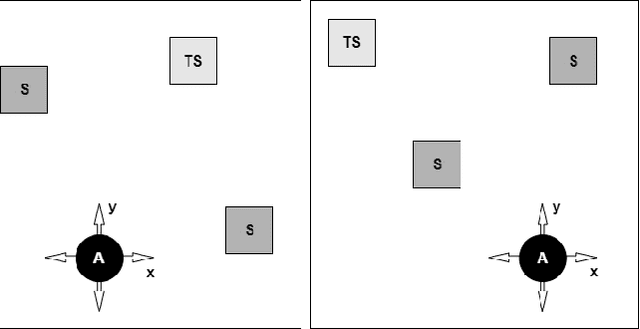
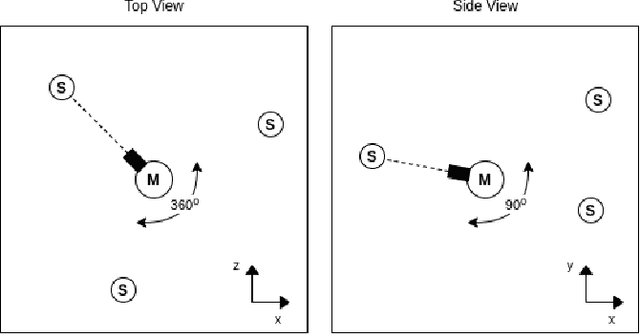
In this work we apply deep reinforcement learning to the problems of navigating a three-dimensional environment and inferring the locations of human speaker audio sources within, in the case where the only available information is the raw sound from the environment, as a simulated human listener placed in the environment would hear it. For this purpose we create two virtual environments using the Unity game engine, one presenting an audio-based navigation problem and one presenting an audio source localization problem. We also create an autonomous agent based on PPO online reinforcement learning algorithm and attempt to train it to solve these environments. Our experiments show that our agent achieves adequate performance and generalization ability in both environments, measured by quantitative metrics, even when a limited amount of training data are available or the environment parameters shift in ways not encountered during training. We also show that a degree of agent knowledge transfer is possible between the environments.
Heterogeneous Graph Neural Network with Multi-view Representation Learning
Aug 31, 2021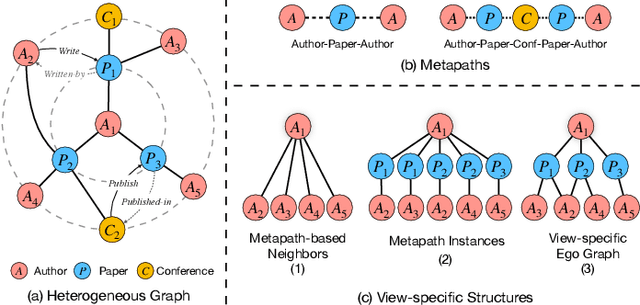
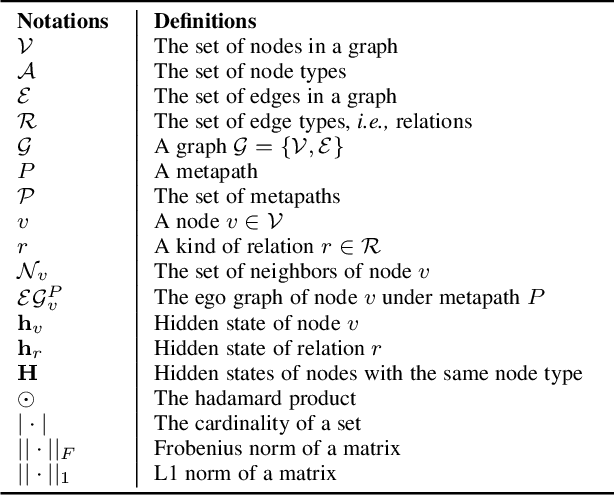
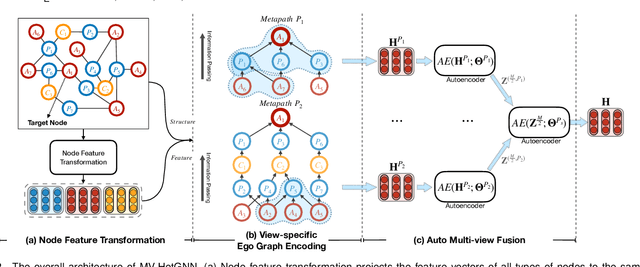
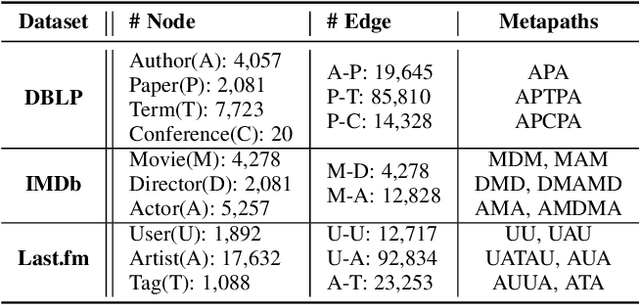
Graph neural networks for heterogeneous graph embedding is to project nodes into a low-dimensional space by exploring the heterogeneity and semantics of the heterogeneous graph. However, on the one hand, most of existing heterogeneous graph embedding methods either insufficiently model the local structure under specific semantic, or neglect the heterogeneity when aggregating information from it. On the other hand, representations from multiple semantics are not comprehensively integrated to obtain versatile node embeddings. To address the problem, we propose a Heterogeneous Graph Neural Network with Multi-View Representation Learning (named MV-HetGNN) for heterogeneous graph embedding by introducing the idea of multi-view representation learning. The proposed model consists of node feature transformation, view-specific ego graph encoding and auto multi-view fusion to thoroughly learn complex structural and semantic information for generating comprehensive node representations. Extensive experiments on three real-world heterogeneous graph datasets show that the proposed MV-HetGNN model consistently outperforms all the state-of-the-art GNN baselines in various downstream tasks, e.g., node classification, node clustering, and link prediction.