 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
APS: Active Pretraining with Successor Features
Aug 31, 2021
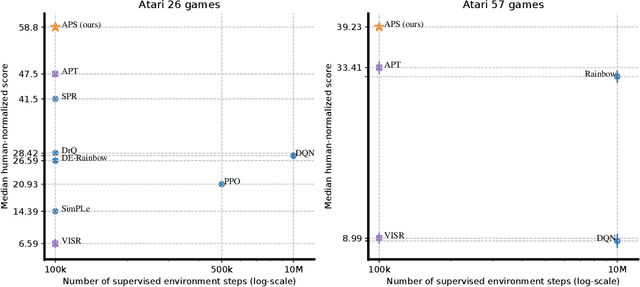
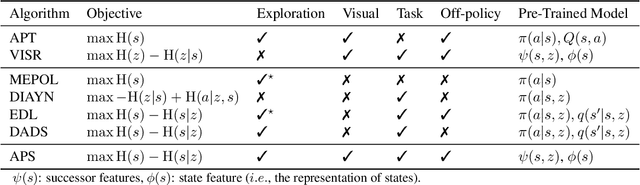
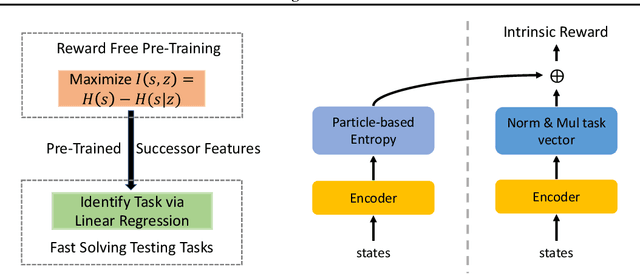
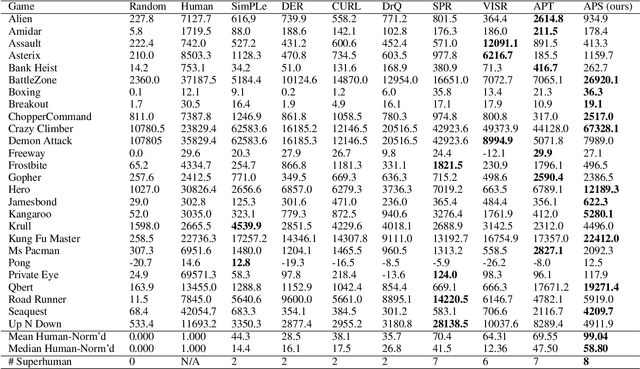
We introduce a new unsupervised pretraining objective for reinforcement learning. During the unsupervised reward-free pretraining phase, the agent maximizes mutual information between tasks and states induced by the policy. Our key contribution is a novel lower bound of this intractable quantity. We show that by reinterpreting and combining variational successor features~\citep{Hansen2020Fast} with nonparametric entropy maximization~\citep{liu2021behavior}, the intractable mutual information can be efficiently optimized. The proposed method Active Pretraining with Successor Feature (APS) explores the environment via nonparametric entropy maximization, and the explored data can be efficiently leveraged to learn behavior by variational successor features. APS addresses the limitations of existing mutual information maximization based and entropy maximization based unsupervised RL, and combines the best of both worlds. When evaluated on the Atari 100k data-efficiency benchmark, our approach significantly outperforms previous methods combining unsupervised pretraining with task-specific finetuning.
Neural Network Adversarial Attack Method Based on Improved Genetic Algorithm
Oct 05, 2021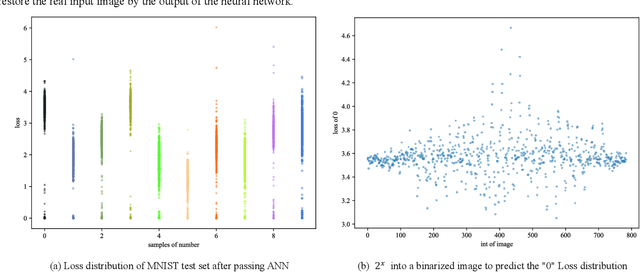
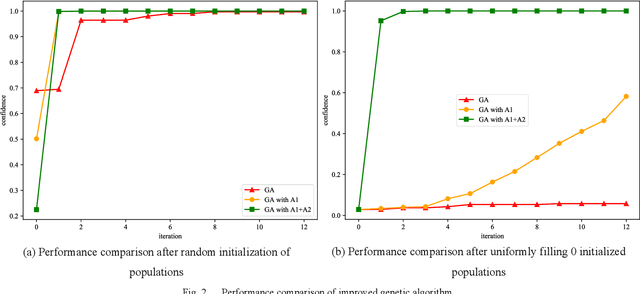
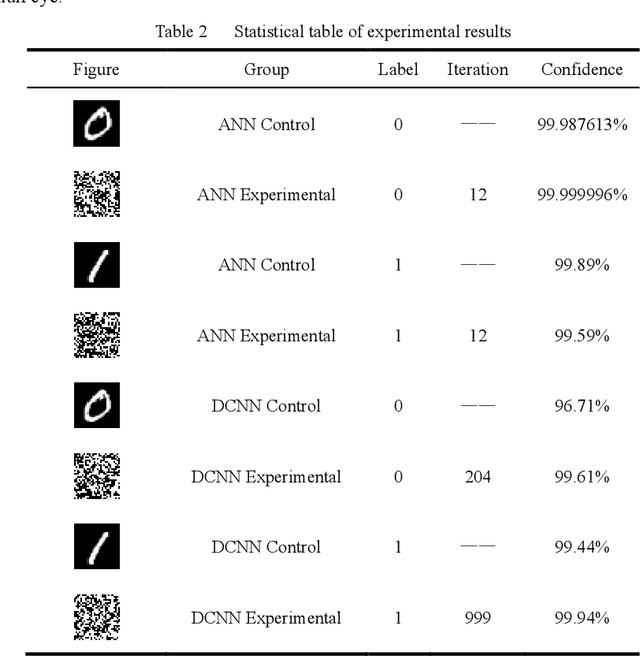
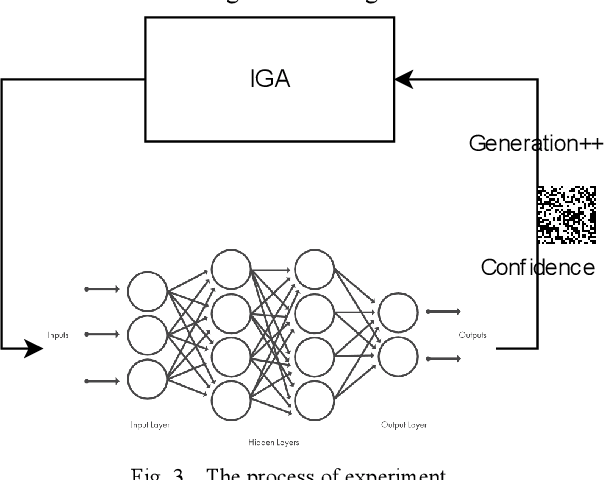
Deep learning algorithms are widely used in fields such as computer vision and natural language processing, but they are vulnerable to security threats from adversarial attacks because of their internal presence of a large number of nonlinear functions and parameters leading to their uninterpretability. In this paper, we propose a neural network adversarial attack method based on an improved genetic algorithm. The improved genetic algorithm improves the variation and crossover links based on the original genetic optimization algorithm, which greatly improves the iteration efficiency and shortens the running time. The method does not need the internal structure and parameter information of the neural network model, and it can obtain the adversarial samples with high confidence in a short time by the classification and confidence information of the neural network. The experimental results show that the method in this paper has a wide range of applicability and high efficiency for the model, and provides a new idea for the adversarial attack.
ADD: Frequency Attention and Multi-View based Knowledge Distillation to Detect Low-Quality Compressed Deepfake Images
Dec 07, 2021
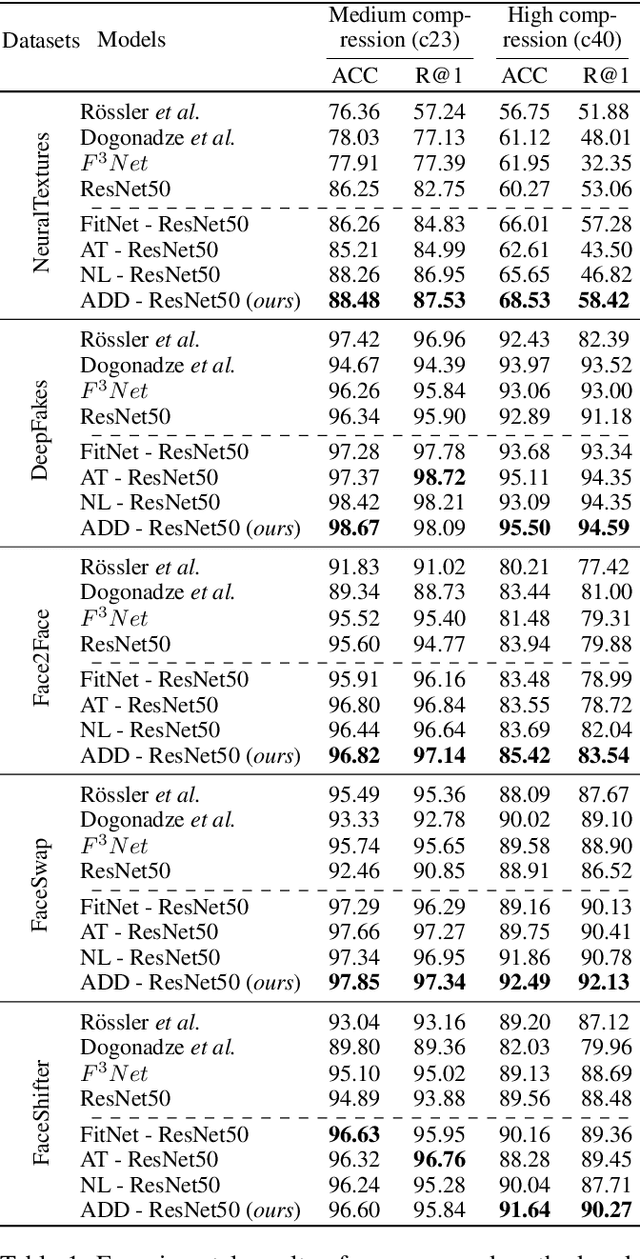
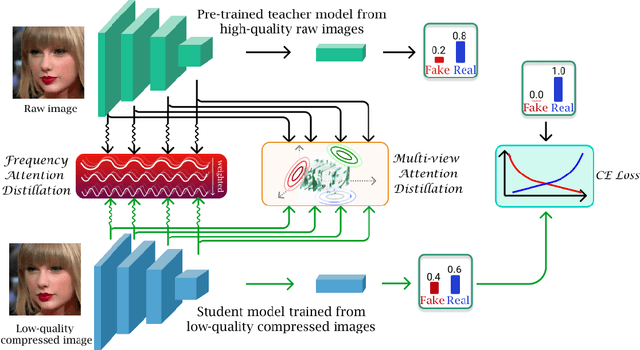

Despite significant advancements of deep learning-based forgery detectors for distinguishing manipulated deepfake images, most detection approaches suffer from moderate to significant performance degradation with low-quality compressed deepfake images. Because of the limited information in low-quality images, detecting low-quality deepfake remains an important challenge. In this work, we apply frequency domain learning and optimal transport theory in knowledge distillation (KD) to specifically improve the detection of low-quality compressed deepfake images. We explore transfer learning capability in KD to enable a student network to learn discriminative features from low-quality images effectively. In particular, we propose the Attention-based Deepfake detection Distiller (ADD), which consists of two novel distillations: 1) frequency attention distillation that effectively retrieves the removed high-frequency components in the student network, and 2) multi-view attention distillation that creates multiple attention vectors by slicing the teacher's and student's tensors under different views to transfer the teacher tensor's distribution to the student more efficiently. Our extensive experimental results demonstrate that our approach outperforms state-of-the-art baselines in detecting low-quality compressed deepfake images.
Salient Object Detection by LTP Texture Characterization on Opposing Color Pairs under SLICO Superpixel Constraint
Jan 03, 2022
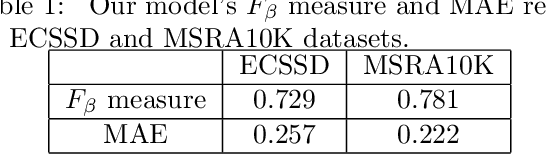
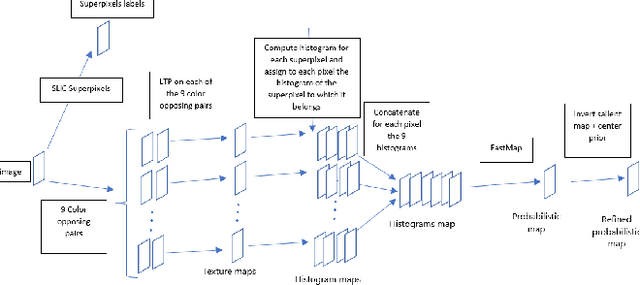

The effortless detection of salient objects by humans has been the subject of research in several fields, including computer vision as it has many applications. However, salient object detection remains a challenge for many computer models dealing with color and textured images. Herein, we propose a novel and efficient strategy, through a simple model, almost without internal parameters, which generates a robust saliency map for a natural image. This strategy consists of integrating color information into local textural patterns to characterize a color micro-texture. Most models in the literature that use the color and texture features treat them separately. In our case, it is the simple, yet powerful LTP (Local Ternary Patterns) texture descriptor applied to opposing color pairs of a color space that allows us to achieve this end. Each color micro-texture is represented by vector whose components are from a superpixel obtained by SLICO (Simple Linear Iterative Clustering with zero parameter) algorithm which is simple, fast and exhibits state-of-the-art boundary adherence. The degree of dissimilarity between each pair of color micro-texture is computed by the FastMap method, a fast version of MDS (Multi-dimensional Scaling), that considers the color micro-textures non-linearity while preserving their distances. These degrees of dissimilarity give us an intermediate saliency map for each RGB, HSL, LUV and CMY color spaces. The final saliency map is their combination to take advantage of the strength of each of them. The MAE (Mean Absolute Error) and F$_{\beta}$ measures of our saliency maps, on the complex ECSSD dataset show that our model is both simple and efficient, outperforming several state-of-the-art models.
Trust in AutoML: Exploring Information Needs for Establishing Trust in Automated Machine Learning Systems
Jan 17, 2020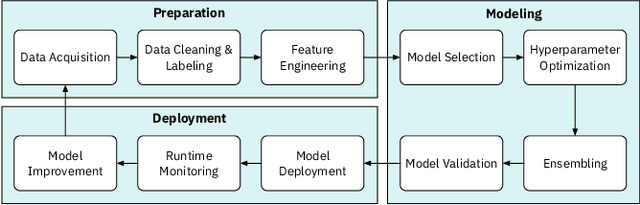

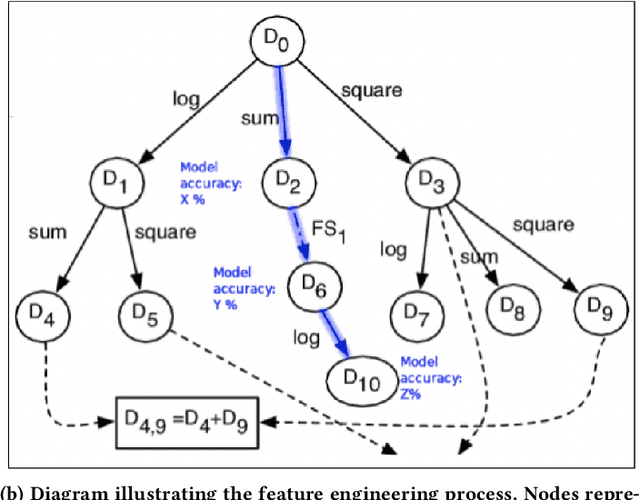
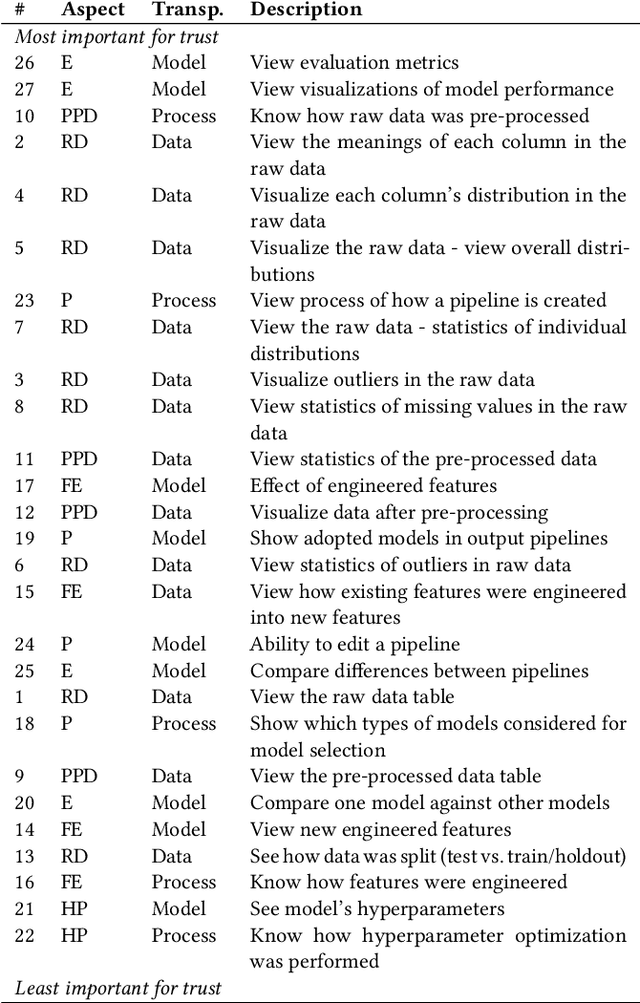
We explore trust in a relatively new area of data science: Automated Machine Learning (AutoML). In AutoML, AI methods are used to generate and optimize machine learning models by automatically engineering features, selecting models, and optimizing hyperparameters. In this paper, we seek to understand what kinds of information influence data scientists' trust in the models produced by AutoML? We operationalize trust as a willingness to deploy a model produced using automated methods. We report results from three studies -- qualitative interviews, a controlled experiment, and a card-sorting task -- to understand the information needs of data scientists for establishing trust in AutoML systems. We find that including transparency features in an AutoML tool increased user trust and understandability in the tool; and out of all proposed features, model performance metrics and visualizations are the most important information to data scientists when establishing their trust with an AutoML tool.
Visual Microfossil Identificationvia Deep Metric Learning
Dec 17, 2021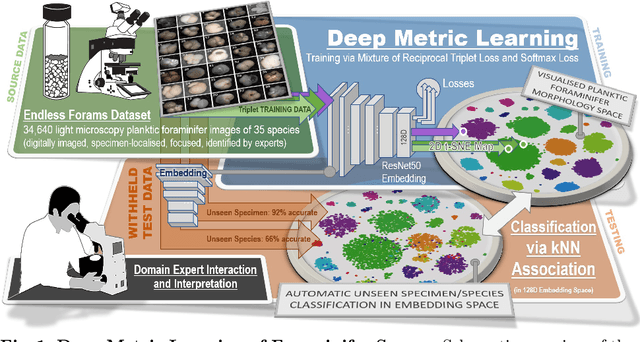
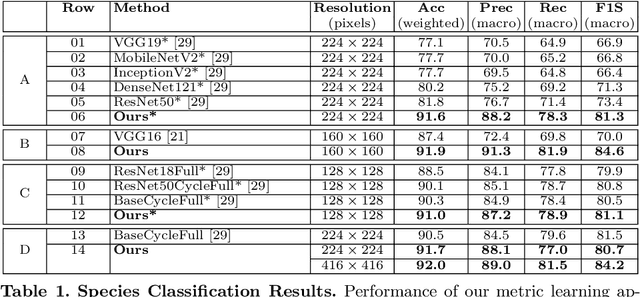
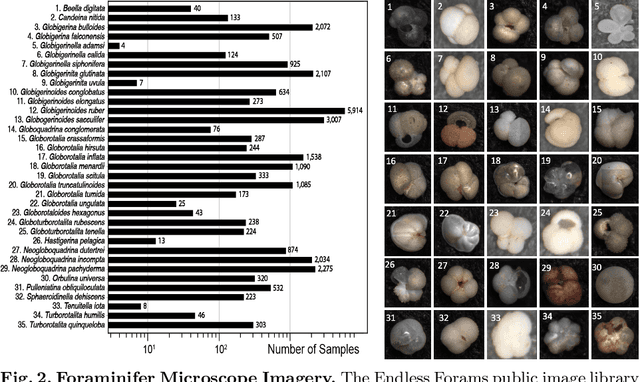
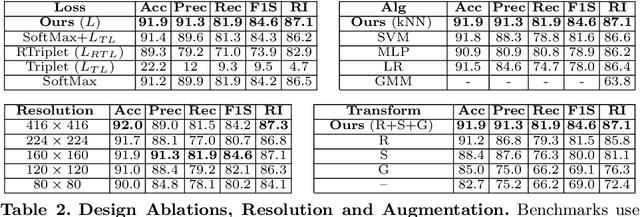
We apply deep metric learning for the first time to the prob-lem of classifying planktic foraminifer shells on microscopic images. This species recognition task is an important information source and scientific pillar for reconstructing past climates. All foraminifer CNN recognition pipelines in the literature produce black-box classifiers that lack visualisation options for human experts and cannot be applied to open set problems. Here, we benchmark metric learning against these pipelines, produce the first scientific visualisation of the phenotypic planktic foraminifer morphology space, and demonstrate that metric learning can be used to cluster species unseen during training. We show that metric learning out-performs all published CNN-based state-of-the-art benchmarks in this domain. We evaluate our approach on the 34,640 expert-annotated images of the Endless Forams public library of 35 modern planktic foraminifera species. Our results on this data show leading 92% accuracy (at 0.84 F1-score) in reproducing expert labels on withheld test data, and 66.5% accuracy (at 0.70 F1-score) when clustering species never encountered in training. We conclude that metric learning is highly effective for this domain and serves as an important tool towards expert-in-the-loop automation of microfossil identification. Key code, network weights, and data splits are published with this paper for full reproducibility.
Learning Continuous Chaotic Attractors with a Reservoir Computer
Oct 16, 2021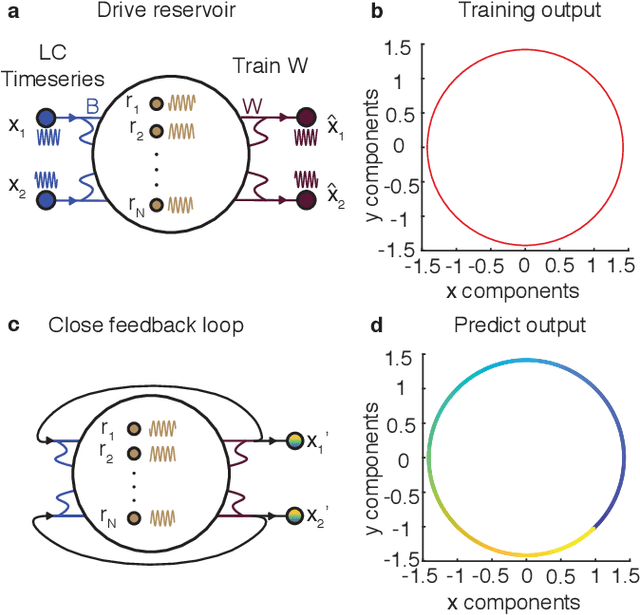
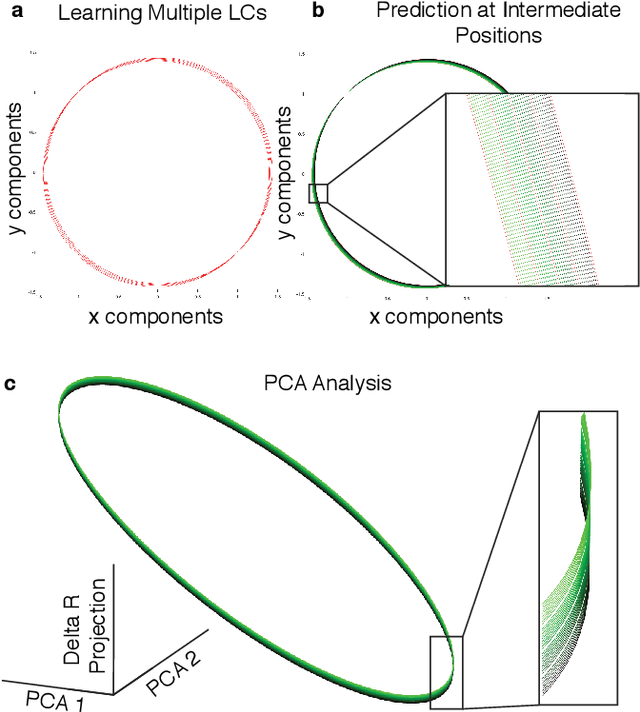
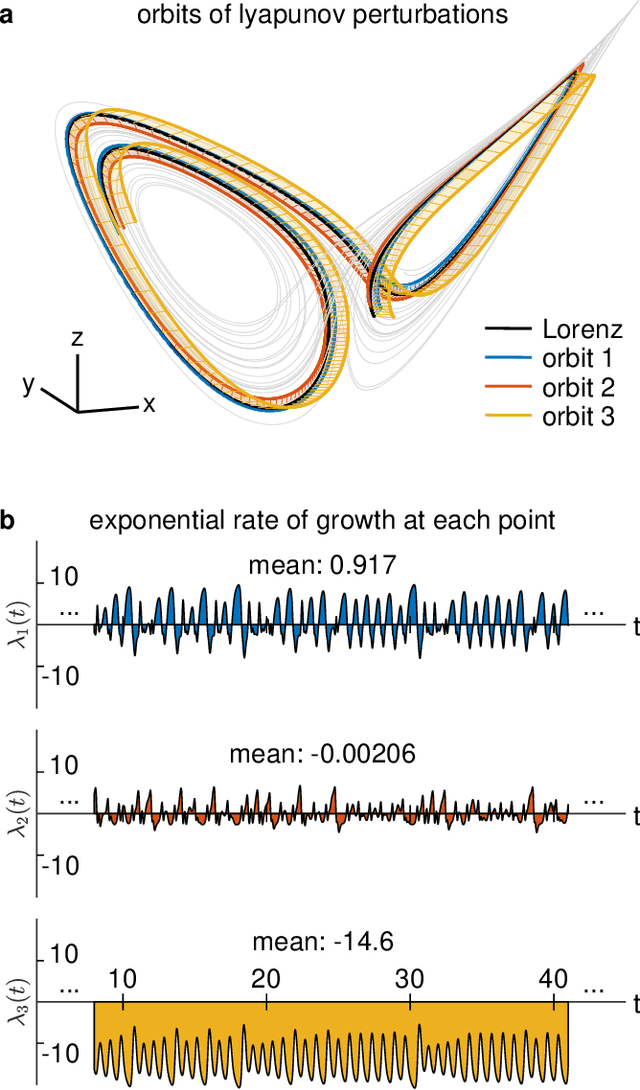
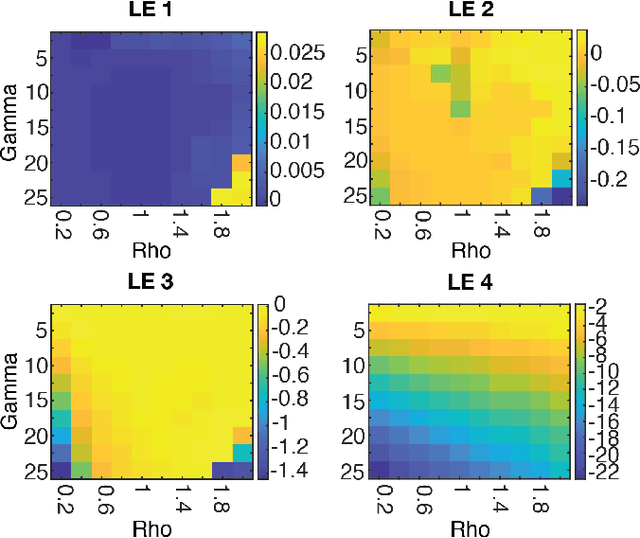
Neural systems are well known for their ability to learn and store information as memories. Even more impressive is their ability to abstract these memories to create complex internal representations, enabling advanced functions such as the spatial manipulation of mental representations. While recurrent neural networks (RNNs) are capable of representing complex information, the exact mechanisms of how dynamical neural systems perform abstraction are still not well-understood, thereby hindering the development of more advanced functions. Here, we train a 1000-neuron RNN -- a reservoir computer (RC) -- to abstract a continuous dynamical attractor memory from isolated examples of dynamical attractor memories. Further, we explain the abstraction mechanism with new theory. By training the RC on isolated and shifted examples of either stable limit cycles or chaotic Lorenz attractors, the RC learns a continuum of attractors, as quantified by an extra Lyapunov exponent equal to zero. We propose a theoretical mechanism of this abstraction by combining ideas from differentiable generalized synchronization and feedback dynamics. Our results quantify abstraction in simple neural systems, enabling us to design artificial RNNs for abstraction, and leading us towards a neural basis of abstraction.
Superpixel-Based Building Damage Detection from Post-earthquake Very High Resolution Imagery Using Deep Neural Networks
Dec 22, 2021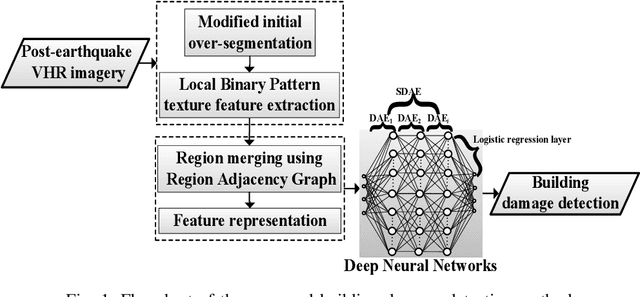
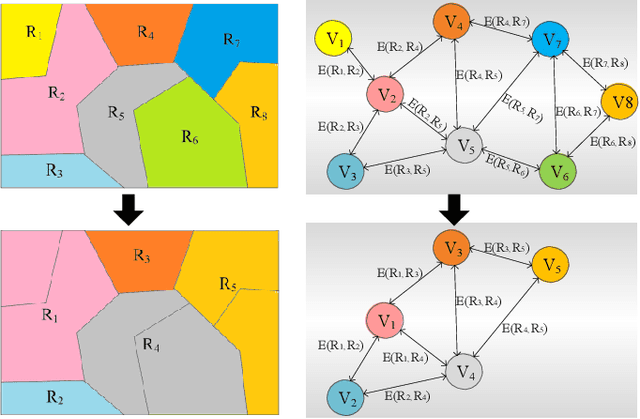
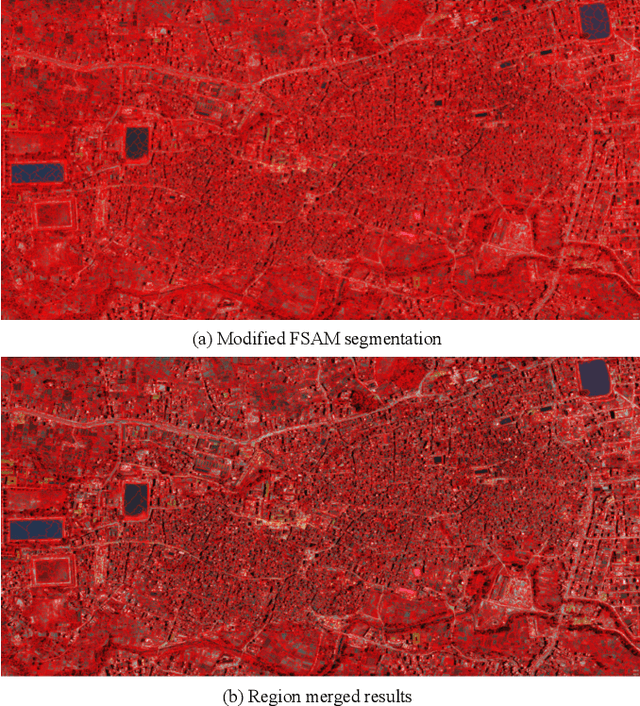
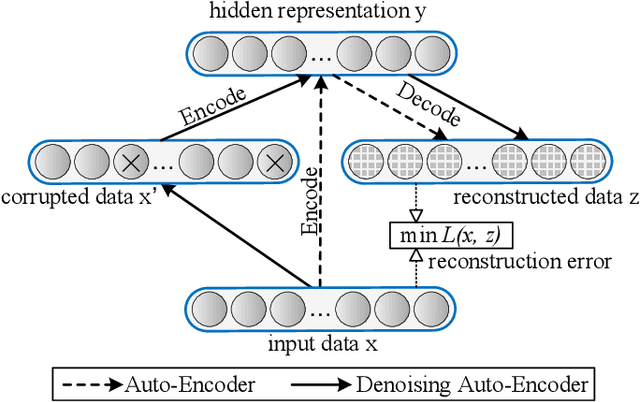
Building damage detection after natural disasters like earthquakes is crucial for initiating effective emergency response actions. Remotely sensed very high spatial resolution (VHR) imagery can provide vital information due to their ability to map the affected buildings with high geometric precision. Many approaches have been developed to detect damaged buildings due to earthquakes. However, little attention has been paid to exploiting rich features represented in VHR images using Deep Neural Networks (DNN). This paper presents a novel superpixel based approach combining DNN and a modified segmentation method, to detect damaged buildings from VHR imagery. Firstly, a modified Fast Scanning and Adaptive Merging method is extended to create initial over-segmentation. Secondly, the segments are merged based on the Region Adjacent Graph (RAG), considered an improved semantic similarity criterion composed of Local Binary Patterns (LBP) texture, spectral, and shape features. Thirdly, a pre-trained DNN using Stacked Denoising Auto-Encoders called SDAE-DNN is presented, to exploit the rich semantic features for building damage detection. Deep-layer feature abstraction of SDAE-DNN could boost detection accuracy through learning more intrinsic and discriminative features, which outperformed other methods using state-of-the-art alternative classifiers. We demonstrate the feasibility and effectiveness of our method using a subset of WorldView-2 imagery, in the complex urban areas of Bhaktapur, Nepal, which was affected by the Nepal Earthquake of April 25, 2015.
VizExtract: Automatic Relation Extraction from Data Visualizations
Dec 07, 2021

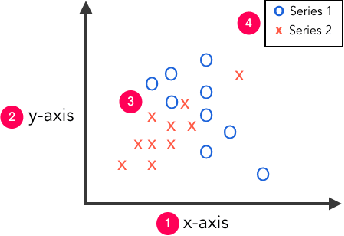
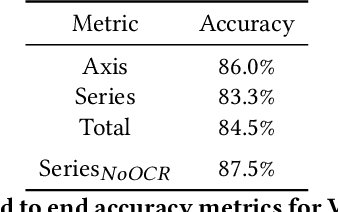
Visual graphics, such as plots, charts, and figures, are widely used to communicate statistical conclusions. Extracting information directly from such visualizations is a key sub-problem for effective search through scientific corpora, fact-checking, and data extraction. This paper presents a framework for automatically extracting compared variables from statistical charts. Due to the diversity and variation of charting styles, libraries, and tools, we leverage a computer vision based framework to automatically identify and localize visualization facets in line graphs, scatter plots, or bar graphs and can include multiple series per graph. The framework is trained on a large synthetically generated corpus of matplotlib charts and we evaluate the trained model on other chart datasets. In controlled experiments, our framework is able to classify, with 87.5% accuracy, the correlation between variables for graphs with 1-3 series per graph, varying colors, and solid line styles. When deployed on real-world graphs scraped from the internet, it achieves 72.8% accuracy (81.2% accuracy when excluding "hard" graphs). When deployed on the FigureQA dataset, it achieves 84.7% accuracy.
MHFC: Multi-Head Feature Collaboration for Few-Shot Learning
Oct 10, 2021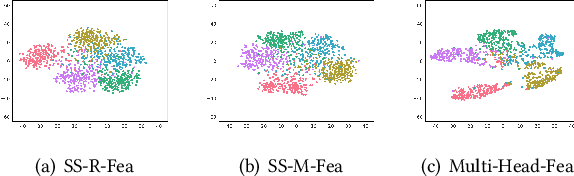
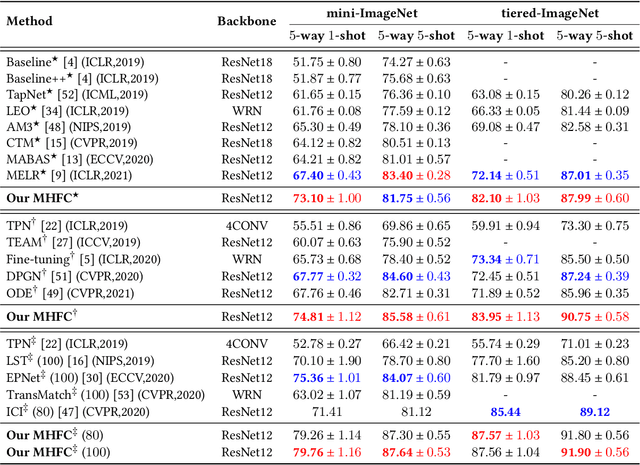
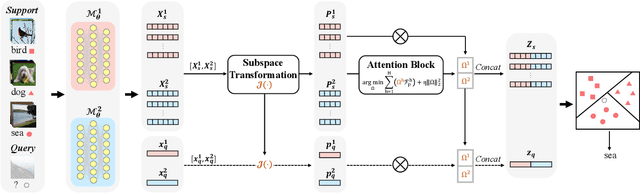
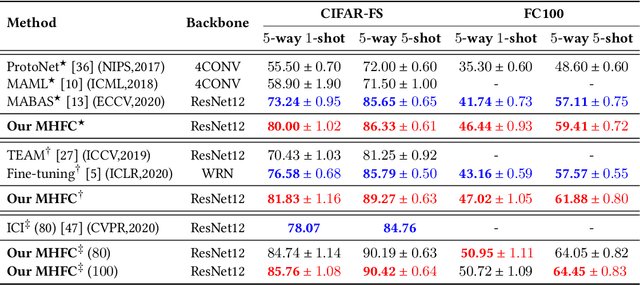
Few-shot learning (FSL) aims to address the data-scarce problem. A standard FSL framework is composed of two components: (1) Pre-train. Employ the base data to generate a CNN-based feature extraction model (FEM). (2) Meta-test. Apply the trained FEM to acquire the novel data's features and recognize them. FSL relies heavily on the design of the FEM. However, various FEMs have distinct emphases. For example, several may focus more attention on the contour information, whereas others may lay particular emphasis on the texture information. The single-head feature is only a one-sided representation of the sample. Besides the negative influence of cross-domain (e.g., the trained FEM can not adapt to the novel class flawlessly), the distribution of novel data may have a certain degree of deviation compared with the ground truth distribution, which is dubbed as distribution-shift-problem (DSP). To address the DSP, we propose Multi-Head Feature Collaboration (MHFC) algorithm, which attempts to project the multi-head features (e.g., multiple features extracted from a variety of FEMs) to a unified space and fuse them to capture more discriminative information. Typically, first, we introduce a subspace learning method to transform the multi-head features to aligned low-dimensional representations. It corrects the DSP via learning the feature with more powerful discrimination and overcomes the problem of inconsistent measurement scales from different head features. Then, we design an attention block to update combination weights for each head feature automatically. It comprehensively considers the contribution of various perspectives and further improves the discrimination of features. We evaluate the proposed method on five benchmark datasets (including cross-domain experiments) and achieve significant improvements of 2.1%-7.8% compared with state-of-the-arts.