 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighlight All the Phrases: Enhancing LLM Transparency through Visual Factuality Indicators
Aug 09, 2025Large language models (LLMs) are susceptible to generating inaccurate or false information, often referred to as "hallucinations" or "confabulations." While several technical advancements have been made to detect hallucinated content by assessing the factuality of the model's responses, there is still limited research on how to effectively communicate this information to users. To address this gap, we conducted two scenario-based experiments with a total of 208 participants to systematically compare the effects of various design strategies for communicating factuality scores by assessing participants' ratings of trust, ease in validating response accuracy, and preference. Our findings reveal that participants preferred and trusted a design in which all phrases within a response were color-coded based on factuality scores. Participants also found it easier to validate accuracy of the response in this style compared to a baseline with no style applied. Our study offers practical design guidelines for LLM application developers and designers, aimed at calibrating user trust, aligning with user preferences, and enhancing users' ability to scrutinize LLM outputs.
AutoDS: Towards Human-Centered Automation of Data Science
Jan 13, 2021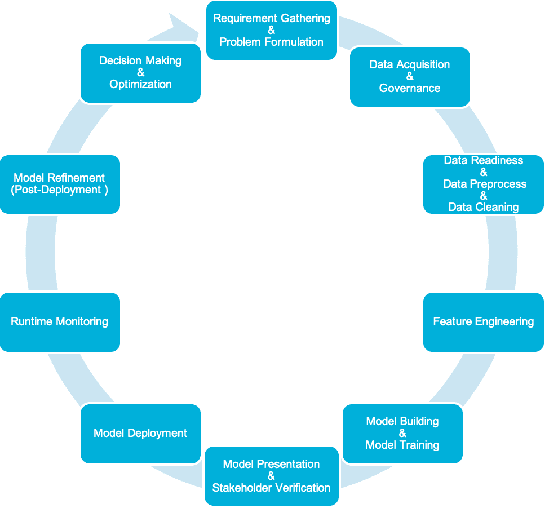
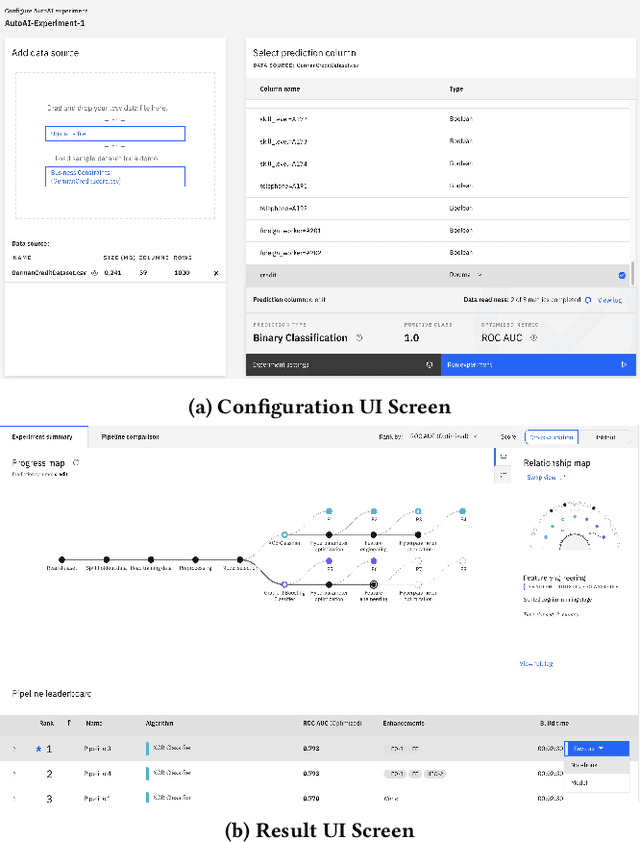
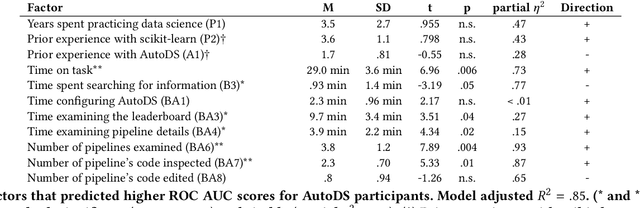
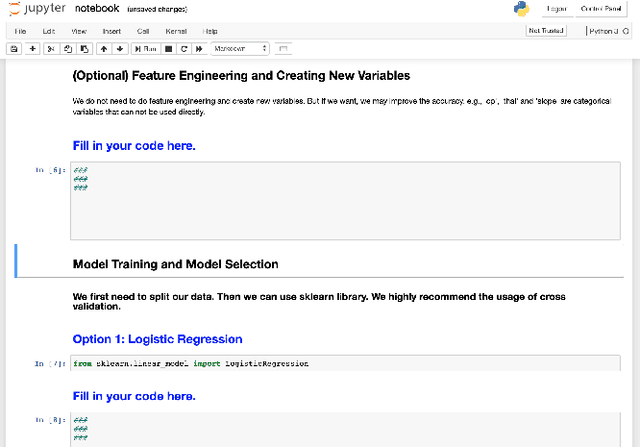
Data science (DS) projects often follow a lifecycle that consists of laborious tasks for data scientists and domain experts (e.g., data exploration, model training, etc.). Only till recently, machine learning(ML) researchers have developed promising automation techniques to aid data workers in these tasks. This paper introduces AutoDS, an automated machine learning (AutoML) system that aims to leverage the latest ML automation techniques to support data science projects. Data workers only need to upload their dataset, then the system can automatically suggest ML configurations, preprocess data, select algorithm, and train the model. These suggestions are presented to the user via a web-based graphical user interface and a notebook-based programming user interface. We studied AutoDS with 30 professional data scientists, where one group used AutoDS, and the other did not, to complete a data science project. As expected, AutoDS improves productivity; Yet surprisingly, we find that the models produced by the AutoDS group have higher quality and less errors, but lower human confidence scores. We reflect on the findings by presenting design implications for incorporating automation techniques into human work in the data science lifecycle.
Trust in AutoML: Exploring Information Needs for Establishing Trust in Automated Machine Learning Systems
Jan 17, 2020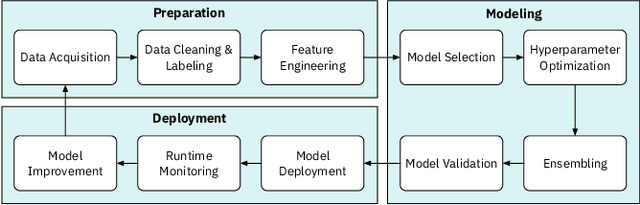

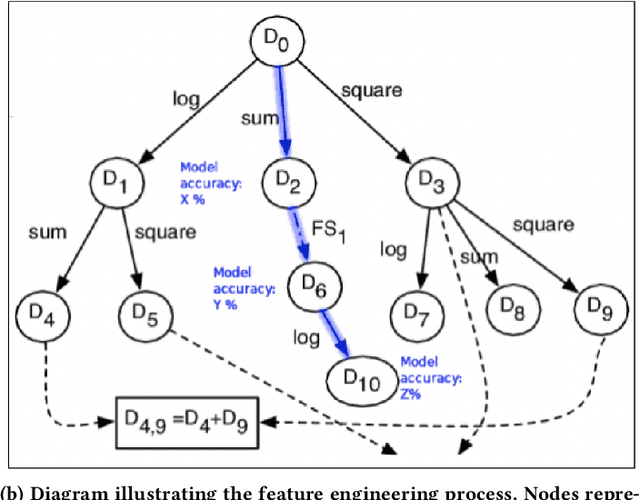
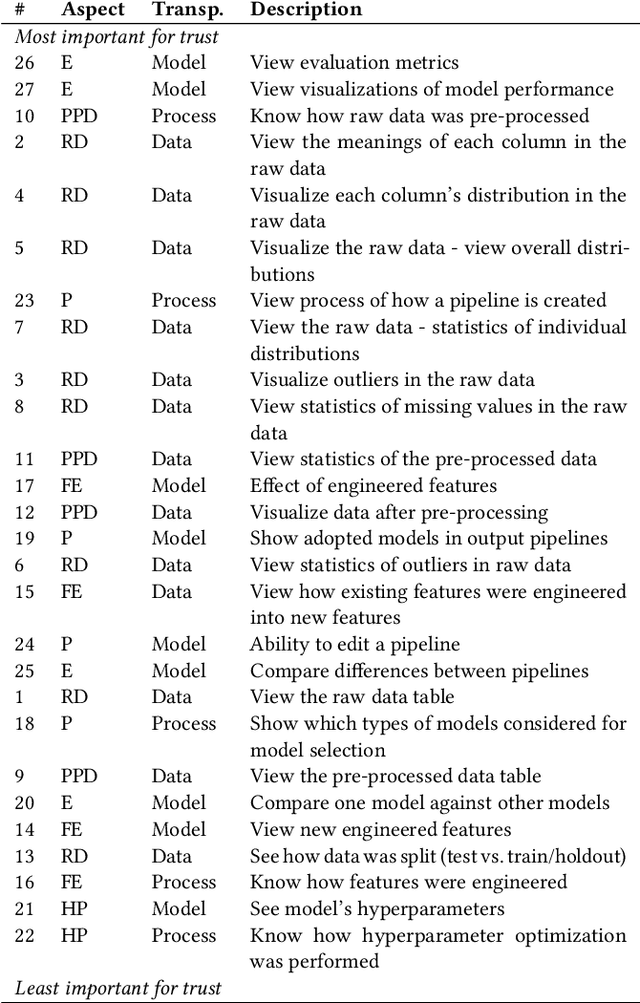
We explore trust in a relatively new area of data science: Automated Machine Learning (AutoML). In AutoML, AI methods are used to generate and optimize machine learning models by automatically engineering features, selecting models, and optimizing hyperparameters. In this paper, we seek to understand what kinds of information influence data scientists' trust in the models produced by AutoML? We operationalize trust as a willingness to deploy a model produced using automated methods. We report results from three studies -- qualitative interviews, a controlled experiment, and a card-sorting task -- to understand the information needs of data scientists for establishing trust in AutoML systems. We find that including transparency features in an AutoML tool increased user trust and understandability in the tool; and out of all proposed features, model performance metrics and visualizations are the most important information to data scientists when establishing their trust with an AutoML tool.
Designing for Democratization: Introducing Novices to Artificial Intelligence Via Maker Kits
Jul 05, 2018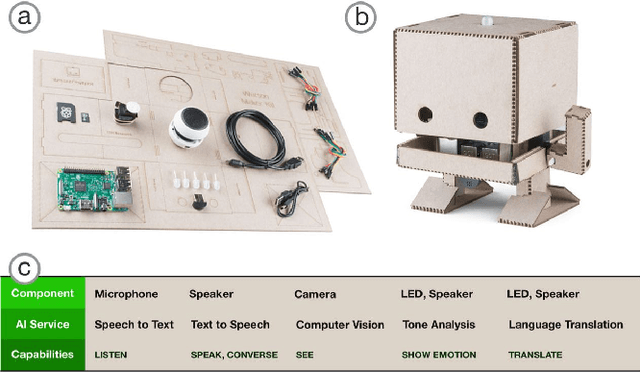

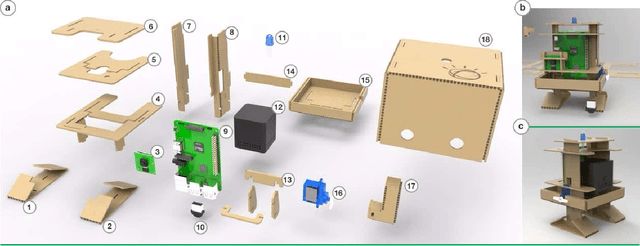
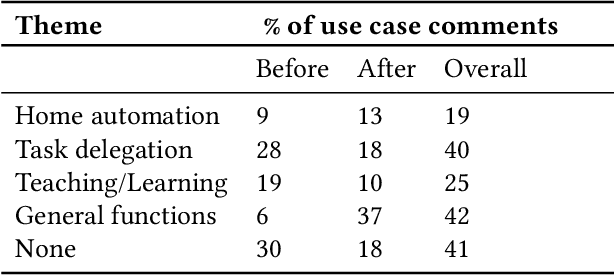
Existing research highlight the myriad of benefits realized when technology is sufficiently democratized and made accessible to non-technical or novice users. However, democratizing complex technologies such as artificial intelligence (AI) remains hard. In this work, we draw on theoretical underpinnings from the democratization of innovation, in exploring the design of maker kits that help introduce novice users to complex technologies. We report on our work designing TJBot: an open source cardboard robot that can be programmed using pre-built AI services. We highlight principles we adopted in this process (approachable design, simplicity, extensibility and accessibility), insights we learned from showing the kit at workshops (66 participants) and how users interacted with the project on GitHub over a 12-month period (Nov 2016 - Nov 2017). We find that the project succeeds in attracting novice users (40% of users who forked the project are new to GitHub) and a variety of demographics are interested in prototyping use cases such as home automation, task delegation, teaching and learning.