 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscoverPhysics: Benchmarking LLMs for Out-of-the-Box Scientific Thinking
May 25, 2026Frontier LLMs now perform strongly across a wide range of physics evaluations, but it is hard to disentangle genuine reasoning from recall of established science. We introduce DiscoverPhysics, an interactive benchmark that asks a LLM agent to discover the laws of motion of a simulated world whose physics deliberately deviates from our own. We construct 22 worlds governed by, among others, screened and fractional-power gravity, multi-species couplings, hidden dark-matter-like particles, non-coordinate-free physics, and time-varying interactions. Each world is generated on demand by an N-body simulator, for which the agent proposes several rounds of experiments, observes raw trajectory data, and ultimately submits both a natural-language explanation of the world's physics and a Python implementation of the inferred law. Because solving a world requires the agent to design informative experiments and revise its hypotheses, the benchmark probes long-horizon reasoning over an experimental history. We evaluate submissions along two complementary axes: trajectory MSE on held-out particles and an LLM-judged explanation score following an expert-written rubric assessing conceptual understanding of each world. Across eleven frontier models, we find that the strongest agents pass only half of the worlds and consistently fail on those where latent structure must be uncovered. Open-source models lag substantially behind commercial models, both in their ability to design informative experiments and in extracting conclusions from the data. We further find that good predictive accuracy does not guarantee high explanation quality and that conceptual understanding depends on hypothesis refinement through well-chosen experiments.
Large language models and the entropy of English
Dec 31, 2025We use large language models (LLMs) to uncover long-ranged structure in English texts from a variety of sources. The conditional entropy or code length in many cases continues to decrease with context length at least to $N\sim 10^4$ characters, implying that there are direct dependencies or interactions across these distances. A corollary is that there are small but significant correlations between characters at these separations, as we show from the data independent of models. The distribution of code lengths reveals an emergent certainty about an increasing fraction of characters at large $N$. Over the course of model training, we observe different dynamics at long and short context lengths, suggesting that long-ranged structure is learned only gradually. Our results constrain efforts to build statistical physics models of LLMs or language itself.
When can in-context learning generalize out of task distribution?
Jun 05, 2025In-context learning (ICL) is a remarkable capability of pretrained transformers that allows models to generalize to unseen tasks after seeing only a few examples. We investigate empirically the conditions necessary on the pretraining distribution for ICL to emerge and generalize \emph{out-of-distribution}. Previous work has focused on the number of distinct tasks necessary in the pretraining dataset. Here, we use a different notion of task diversity to study the emergence of ICL in transformers trained on linear functions. We find that as task diversity increases, transformers undergo a transition from a specialized solution, which exhibits ICL only within the pretraining task distribution, to a solution which generalizes out of distribution to the entire task space. We also investigate the nature of the solutions learned by the transformer on both sides of the transition, and observe similar transitions in nonlinear regression problems. We construct a phase diagram to characterize how our concept of task diversity interacts with the number of pretraining tasks. In addition, we explore how factors such as the depth of the model and the dimensionality of the regression problem influence the transition.
Learning Continuous Chaotic Attractors with a Reservoir Computer
Oct 16, 2021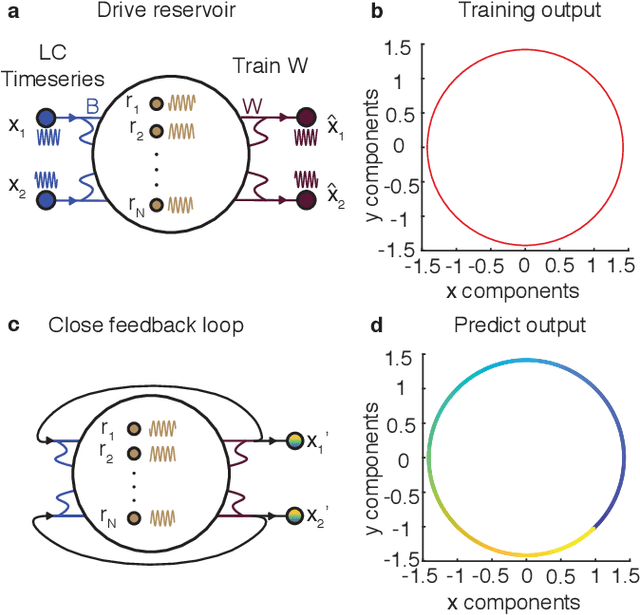
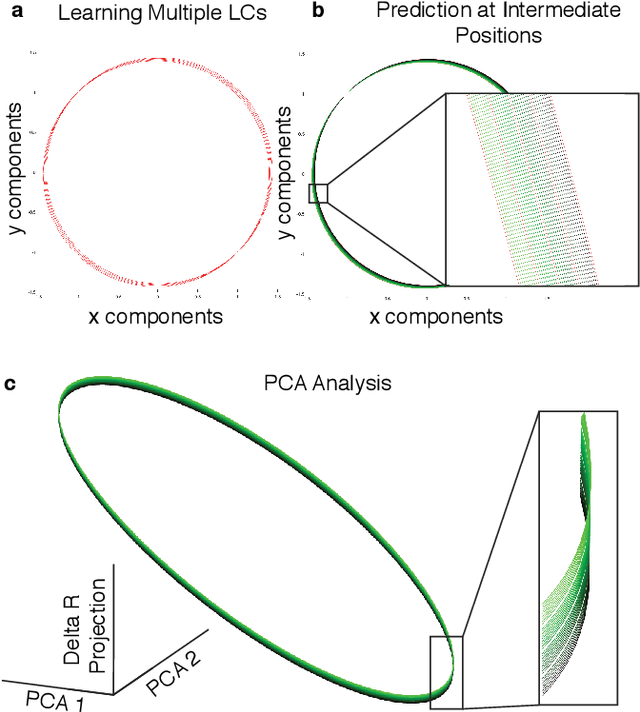
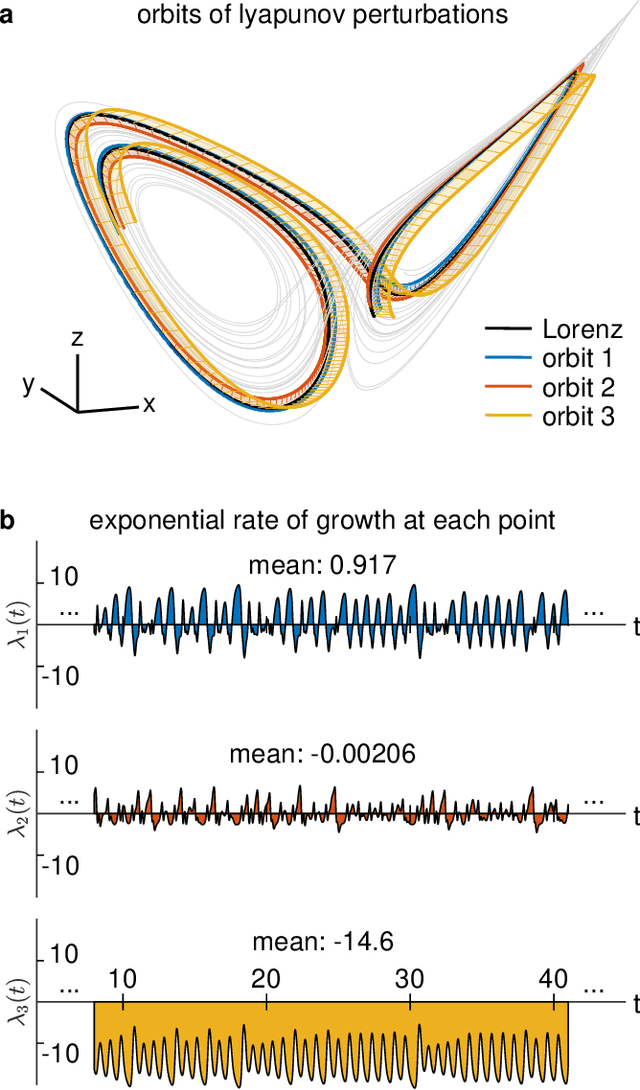
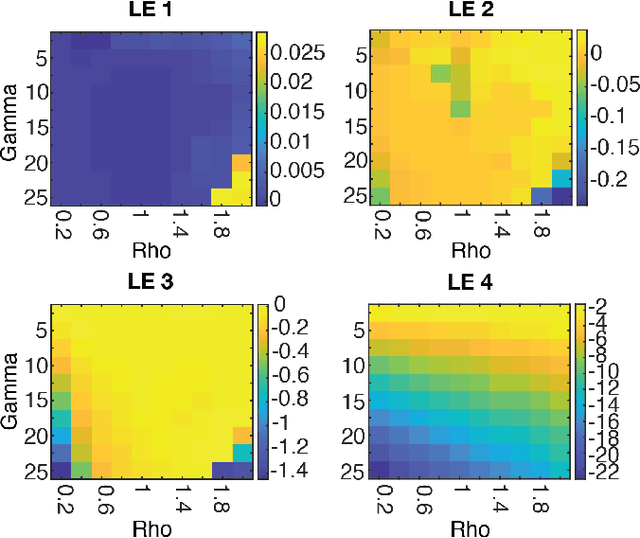
Neural systems are well known for their ability to learn and store information as memories. Even more impressive is their ability to abstract these memories to create complex internal representations, enabling advanced functions such as the spatial manipulation of mental representations. While recurrent neural networks (RNNs) are capable of representing complex information, the exact mechanisms of how dynamical neural systems perform abstraction are still not well-understood, thereby hindering the development of more advanced functions. Here, we train a 1000-neuron RNN -- a reservoir computer (RC) -- to abstract a continuous dynamical attractor memory from isolated examples of dynamical attractor memories. Further, we explain the abstraction mechanism with new theory. By training the RC on isolated and shifted examples of either stable limit cycles or chaotic Lorenz attractors, the RC learns a continuum of attractors, as quantified by an extra Lyapunov exponent equal to zero. We propose a theoretical mechanism of this abstraction by combining ideas from differentiable generalized synchronization and feedback dynamics. Our results quantify abstraction in simple neural systems, enabling us to design artificial RNNs for abstraction, and leading us towards a neural basis of abstraction.