 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Alignment for Cross-Domain Face Anti-Spoofing
Mar 12, 2024



Recent advancements in domain generalization (DG) for face anti-spoofing (FAS) have garnered considerable attention. Traditional methods have focused on designing learning objectives and additional modules to isolate domain-specific features while retaining domain-invariant characteristics in their representations. However, such approaches often lack guarantees of consistent maintenance of domain-invariant features or the complete removal of domain-specific features. Furthermore, most prior works of DG for FAS do not ensure convergence to a local flat minimum, which has been shown to be advantageous for DG. In this paper, we introduce GAC-FAS, a novel learning objective that encourages the model to converge towards an optimal flat minimum without necessitating additional learning modules. Unlike conventional sharpness-aware minimizers, GAC-FAS identifies ascending points for each domain and regulates the generalization gradient updates at these points to align coherently with empirical risk minimization (ERM) gradient updates. This unique approach specifically guides the model to be robust against domain shifts. We demonstrate the efficacy of GAC-FAS through rigorous testing on challenging cross-domain FAS datasets, where it establishes state-of-the-art performance. The code is available at https://github.com/leminhbinh0209/CVPR24-FAS.
SoK: Facial Deepfake Detectors
Jan 09, 2024



Deepfakes have rapidly emerged as a profound and serious threat to society, primarily due to their ease of creation and dissemination. This situation has triggered an accelerated development of deepfake detection technologies. However, many existing detectors rely heavily on lab-generated datasets for validation, which may not effectively prepare them for novel, emerging, and real-world deepfake techniques. In this paper, we conduct an extensive and comprehensive review and analysis of the latest state-of-the-art deepfake detectors, evaluating them against several critical criteria. These criteria facilitate the categorization of these detectors into 4 high-level groups and 13 fine-grained sub-groups, all aligned with a unified standard conceptual framework. This classification and framework offer deep and practical insights into the factors that affect detector efficacy. We assess the generalizability of 16 leading detectors across various standard attack scenarios, including black-box, white-box, and gray-box settings. Our systematized analysis and experimentation lay the groundwork for a deeper understanding of deepfake detectors and their generalizability, paving the way for future research focused on creating detectors adept at countering various attack scenarios. Additionally, this work offers insights for developing more proactive defenses against deepfakes.
Quality-Agnostic Deepfake Detection with Intra-model Collaborative Learning
Sep 12, 2023Deepfake has recently raised a plethora of societal concerns over its possible security threats and dissemination of fake information. Much research on deepfake detection has been undertaken. However, detecting low quality as well as simultaneously detecting different qualities of deepfakes still remains a grave challenge. Most SOTA approaches are limited by using a single specific model for detecting certain deepfake video quality type. When constructing multiple models with prior information about video quality, this kind of strategy incurs significant computational cost, as well as model and training data overhead. Further, it cannot be scalable and practical to deploy in real-world settings. In this work, we propose a universal intra-model collaborative learning framework to enable the effective and simultaneous detection of different quality of deepfakes. That is, our approach is the quality-agnostic deepfake detection method, dubbed QAD . In particular, by observing the upper bound of general error expectation, we maximize the dependency between intermediate representations of images from different quality levels via Hilbert-Schmidt Independence Criterion. In addition, an Adversarial Weight Perturbation module is carefully devised to enable the model to be more robust against image corruption while boosting the overall model's performance. Extensive experiments over seven popular deepfake datasets demonstrate the superiority of our QAD model over prior SOTA benchmarks.
OTJR: Optimal Transport Meets Optimal Jacobian Regularization for Adversarial Robustness
Mar 21, 2023Deep neural networks are widely recognized as being vulnerable to adversarial perturbation. To overcome this challenge, developing a robust classifier is crucial. So far, two well-known defenses have been adopted to improve the learning of robust classifiers, namely adversarial training (AT) and Jacobian regularization. However, each approach behaves differently against adversarial perturbations. First, our work carefully analyzes and characterizes these two schools of approaches, both theoretically and empirically, to demonstrate how each approach impacts the robust learning of a classifier. Next, we propose our novel Optimal Transport with Jacobian regularization method, dubbed OTJR, jointly incorporating the input-output Jacobian regularization into the AT by leveraging the optimal transport theory. In particular, we employ the Sliced Wasserstein (SW) distance that can efficiently push the adversarial samples' representations closer to those of clean samples, regardless of the number of classes within the dataset. The SW distance provides the adversarial samples' movement directions, which are much more informative and powerful for the Jacobian regularization. Our extensive experiments demonstrate the effectiveness of our proposed method, which jointly incorporates Jacobian regularization into AT. Furthermore, we demonstrate that our proposed method consistently enhances the model's robustness with CIFAR-100 dataset under various adversarial attack settings, achieving up to 28.49% under AutoAttack.
Towards an Awareness of Time Series Anomaly Detection Models' Adversarial Vulnerability
Aug 24, 2022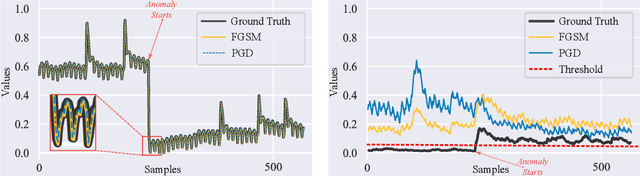
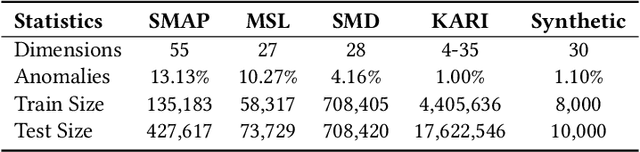
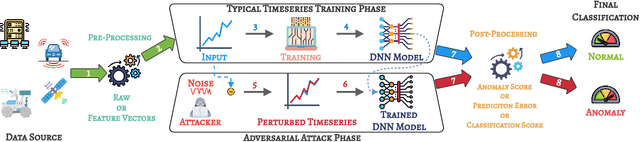
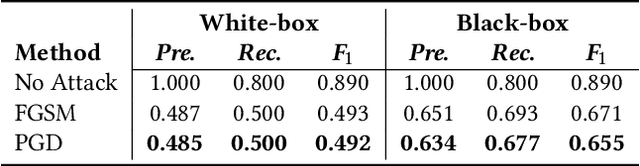
Time series anomaly detection is extensively studied in statistics, economics, and computer science. Over the years, numerous methods have been proposed for time series anomaly detection using deep learning-based methods. Many of these methods demonstrate state-of-the-art performance on benchmark datasets, giving the false impression that these systems are robust and deployable in many practical and industrial real-world scenarios. In this paper, we demonstrate that the performance of state-of-the-art anomaly detection methods is degraded substantially by adding only small adversarial perturbations to the sensor data. We use different scoring metrics such as prediction errors, anomaly, and classification scores over several public and private datasets ranging from aerospace applications, server machines, to cyber-physical systems in power plants. Under well-known adversarial attacks from Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) methods, we demonstrate that state-of-the-art deep neural networks (DNNs) and graph neural networks (GNNs) methods, which claim to be robust against anomalies and have been possibly integrated in real-life systems, have their performance drop to as low as 0%. To the best of our understanding, we demonstrate, for the first time, the vulnerabilities of anomaly detection systems against adversarial attacks. The overarching goal of this research is to raise awareness towards the adversarial vulnerabilities of time series anomaly detectors.
KappaFace: Adaptive Additive Angular Margin Loss for Deep Face Recognition
Jan 19, 2022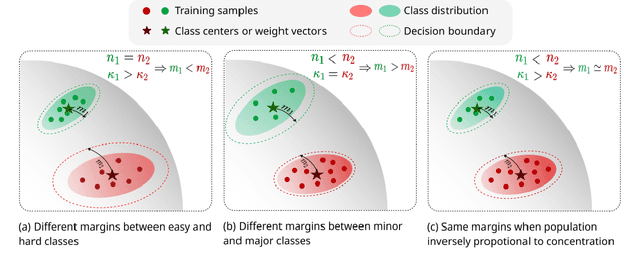
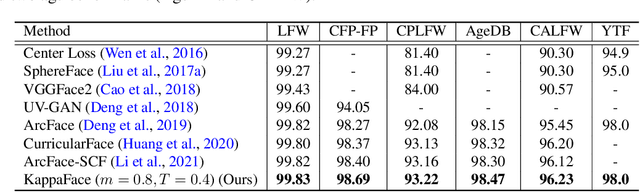
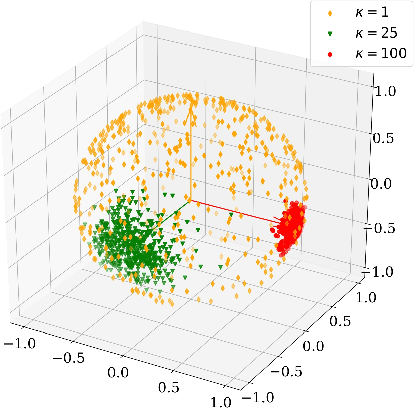
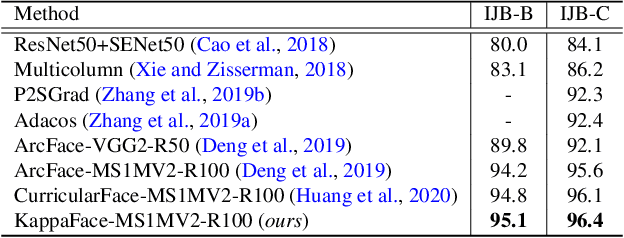
Feature learning is a widely used method employed for large-scale face recognition. Recently, large-margin softmax loss methods have demonstrated significant enhancements on deep face recognition. These methods propose fixed positive margins in order to enforce intra-class compactness and inter-class diversity. However, the majority of the proposed methods do not consider the class imbalance issue, which is a major challenge in practice for developing deep face recognition models. We hypothesize that it significantly affects the generalization ability of the deep face models. Inspired by this observation, we introduce a novel adaptive strategy, called KappaFace, to modulate the relative importance based on class difficultness and imbalance. With the support of the von Mises-Fisher distribution, our proposed KappaFace loss can intensify the margin's magnitude for hard learning or low concentration classes while relaxing it for counter classes. Experiments conducted on popular facial benchmarks demonstrate that our proposed method achieves superior performance to the state-of-the-art.
Exploring the Asynchronous of the Frequency Spectra of GAN-generated Facial Images
Dec 15, 2021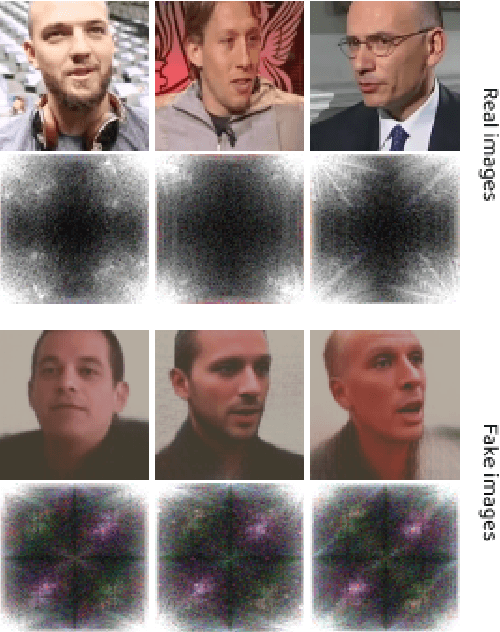
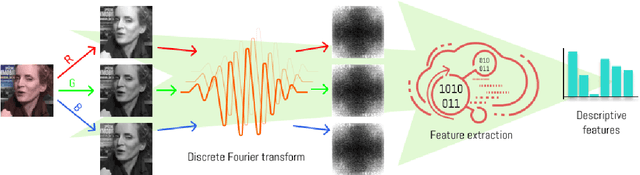

The rapid progression of Generative Adversarial Networks (GANs) has raised a concern of their misuse for malicious purposes, especially in creating fake face images. Although many proposed methods succeed in detecting GAN-based synthetic images, they are still limited by the need for large quantities of the training fake image dataset and challenges for the detector's generalizability to unknown facial images. In this paper, we propose a new approach that explores the asynchronous frequency spectra of color channels, which is simple but effective for training both unsupervised and supervised learning models to distinguish GAN-based synthetic images. We further investigate the transferability of a training model that learns from our suggested features in one source domain and validates on another target domains with prior knowledge of the features' distribution. Our experimental results show that the discrepancy of spectra in the frequency domain is a practical artifact to effectively detect various types of GAN-based generated images.
ADD: Frequency Attention and Multi-View based Knowledge Distillation to Detect Low-Quality Compressed Deepfake Images
Dec 07, 2021
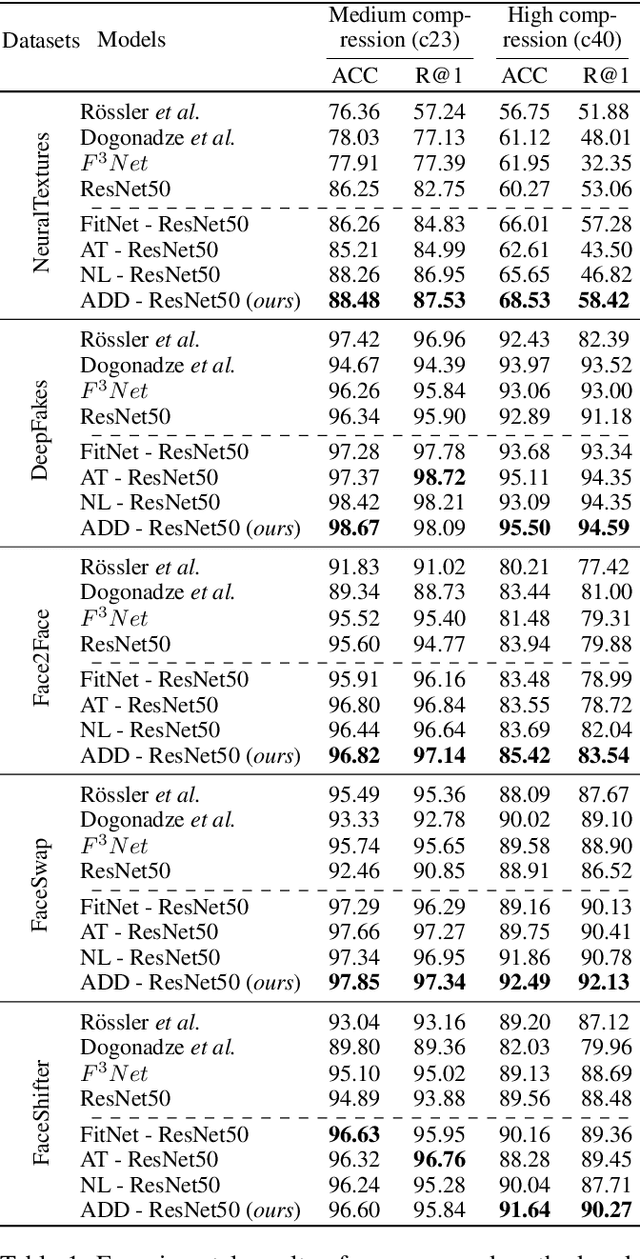
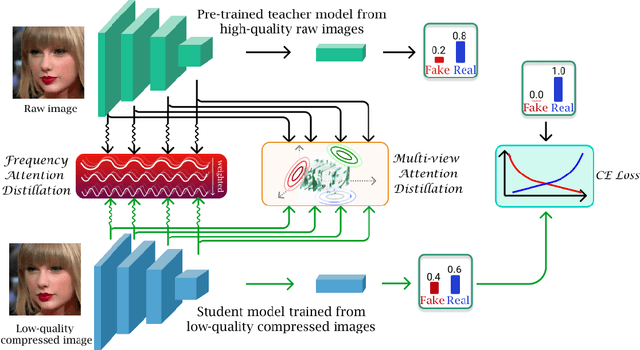

Despite significant advancements of deep learning-based forgery detectors for distinguishing manipulated deepfake images, most detection approaches suffer from moderate to significant performance degradation with low-quality compressed deepfake images. Because of the limited information in low-quality images, detecting low-quality deepfake remains an important challenge. In this work, we apply frequency domain learning and optimal transport theory in knowledge distillation (KD) to specifically improve the detection of low-quality compressed deepfake images. We explore transfer learning capability in KD to enable a student network to learn discriminative features from low-quality images effectively. In particular, we propose the Attention-based Deepfake detection Distiller (ADD), which consists of two novel distillations: 1) frequency attention distillation that effectively retrieves the removed high-frequency components in the student network, and 2) multi-view attention distillation that creates multiple attention vectors by slicing the teacher's and student's tensors under different views to transfer the teacher tensor's distribution to the student more efficiently. Our extensive experimental results demonstrate that our approach outperforms state-of-the-art baselines in detecting low-quality compressed deepfake images.